
Cos'è l'underfitting nel machine learning?
Pubblicato: 2024-10-16L'underfitting è un problema comune riscontrato durante lo sviluppo di modelli di machine learning (ML). Si verifica quando un modello non è in grado di apprendere in modo efficace dai dati di addestramento, con conseguenti prestazioni inferiori alla media. In questo articolo esploreremo cos'è l'underfitting, come si verifica e le strategie per evitarlo.
Sommario
- Cos'è l'underfitting?
- Come si verifica l'underfitting
- Sottoadattamento vs. eccessivo adattamento
- Cause comuni di sottoadattamento
- Come rilevare l'underfitting
- Tecniche per prevenire l'underfitting
- Esempi pratici di underfitting
Cos'è l'underfitting?
L'underfitting si verifica quando un modello di machine learning non riesce a catturare i modelli sottostanti nei dati di training, portando a scarse prestazioni sia sui dati di training che su quelli di test. Quando ciò accade significa che il modello è troppo semplice e non fa un buon lavoro nel rappresentare le relazioni più importanti dei dati. Di conseguenza, il modello fatica a fare previsioni accurate su tutti i dati, sia quelli visualizzati durante l'addestramento sia eventuali dati nuovi e invisibili.
Come avviene l'underfitting?
L'underfitting si verifica quando un algoritmo di machine learning produce un modello che non riesce a catturare le proprietà più importanti dei dati di addestramento; i modelli che falliscono in questo modo sono considerati troppo semplici. Ad esempio, immagina di utilizzare la regressione lineare per prevedere le vendite in base alla spesa di marketing, ai dati demografici dei clienti e alla stagionalità. La regressione lineare presuppone che la relazione tra questi fattori e le vendite possano essere rappresentate come un mix di linee rette.
Sebbene la relazione effettiva tra la spesa di marketing e le vendite possa essere curva o includere molteplici interazioni (ad esempio, le vendite inizialmente aumentano rapidamente, poi si stabilizzano), il modello lineare si semplificherà eccessivamente tracciando una linea retta. Questa semplificazione non tiene conto di importanti sfumature, portando a previsioni e prestazioni complessive inadeguate.
Questo problema è comune in molti modelli ML in cui un bias elevato (presupposti rigidi) impedisce al modello di apprendere modelli essenziali, causandone scarse prestazioni sia sui dati di training che di test. L'underfitting si riscontra tipicamente quando il modello è troppo semplice per rappresentare la reale complessità dei dati.
Sottoadattamento vs. eccessivo adattamento
In ML, l'underfitting e l'overfitting sono problemi comuni che possono influire negativamente sulla capacità di un modello di effettuare previsioni accurate. Comprendere la differenza tra i due è fondamentale per costruire modelli che si generalizzino bene ai nuovi dati.
- L’underfittingsi verifica quando un modello è troppo semplice e non riesce a catturare i modelli chiave nei dati. Ciò porta a previsioni imprecise sia per i dati di training che per i nuovi dati.
- L'overfittingsi verifica quando un modello diventa eccessivamente complesso, adattandosi non solo ai modelli reali ma anche al rumore nei dati di addestramento. Ciò fa sì che il modello funzioni bene sul set di addestramento ma male su dati nuovi e invisibili.
Per illustrare meglio questi concetti, si consideri un modello che prevede la prestazione atletica in base ai livelli di stress. I punti blu nel grafico rappresentano i punti dati del set di addestramento, mentre le linee mostrano le previsioni del modello dopo essere stato addestrato su tali dati. 
1 Underfitting:in questo caso, il modello utilizza una semplice linea retta per prevedere le prestazioni, anche se la relazione effettiva è curva. Poiché la linea non si adatta bene ai dati, il modello è troppo semplice e non riesce a catturare modelli importanti, dando luogo a previsioni inadeguate. Si tratta di un adattamento inadeguato, in cui il modello non riesce ad apprendere le proprietà più utili dei dati.
2 Adattamento ottimale:in questo caso il modello si adatta alla curva dei dati in modo sufficientemente appropriato. Cattura la tendenza sottostante senza essere eccessivamente sensibile a dati o rumore specifici. Questo è lo scenario desiderato, in cui il modello si generalizza ragionevolmente bene e può fare previsioni accurate su dati nuovi e simili. Tuttavia, la generalizzazione può ancora essere difficile quando si affrontano set di dati molto diversi o più complessi.
3 Overfitting:nello scenario di overfitting, il modello segue da vicino quasi ogni punto dati, inclusi il rumore e le fluttuazioni casuali nei dati di addestramento. Anche se il modello funziona molto bene sul set di addestramento, è troppo specifico per i dati di addestramento e quindi sarà meno efficace nella previsione di nuovi dati. Fatica a generalizzare e probabilmente farà previsioni imprecise se applicato a scenari invisibili.
Cause comuni di sottoadattamento
Esistono molte potenziali cause di sottoadattamento. I quattro più comuni sono:
- L'architettura del modello è troppo semplice.
- Scarsa selezione di funzionalità
- Dati di addestramento insufficienti
- Formazione insufficiente
Esaminiamoli un po' più a fondo per capirli.
L'architettura del modello è troppo semplice
L'architettura del modello si riferisce alla combinazione dell'algoritmo utilizzato per addestrare il modello e la struttura del modello. Se l'architettura è troppo semplice, potrebbe avere difficoltà a catturare le proprietà di alto livello dei dati di addestramento, portando a previsioni imprecise.
Ad esempio, se un modello tenta di utilizzare una singola linea retta per modellare dati che seguono uno schema curvo, risulterà costantemente inadeguato. Questo perché una linea retta non può rappresentare accuratamente la relazione di alto livello nei dati curvi, rendendo l'architettura del modello inadeguata al compito.
Scarsa selezione di funzionalità
La selezione delle funzionalità implica la scelta delle variabili giuste per il modello ML durante l'addestramento. Ad esempio, potresti chiedere a un algoritmo ML di considerare l'anno di nascita, il colore degli occhi, l'età o tutti e tre i dati di una persona per prevedere se una persona premerà il pulsante Acquista su un sito di e-commerce.
Se sono presenti troppe funzionalità o le funzionalità selezionate non sono fortemente correlate alla variabile target, il modello non disporrà di informazioni pertinenti sufficienti per effettuare previsioni accurate. Il colore degli occhi potrebbe essere irrilevante per la conversione e l'età cattura molte delle stesse informazioni dell'anno di nascita.
Dati di addestramento insufficienti
Quando i punti dati sono troppo pochi, il modello potrebbe non adattarsi perché i dati non catturano le proprietà più importanti del problema. Ciò può accadere a causa della mancanza di dati o a causa di errori di campionamento, per cui alcune fonti di dati sono escluse o sottorappresentate, impedendo al modello di apprendere modelli importanti.

Formazione insufficiente
L'addestramento di un modello ML comporta la regolazione dei suoi parametri interni (pesi) in base alla differenza tra le sue previsioni e i risultati effettivi. Maggiore è il numero di iterazioni di training a cui viene sottoposto il modello, migliore sarà la sua capacità di adattarsi ai dati. Se il modello viene addestrato con un numero troppo basso di iterazioni, potrebbe non avere sufficienti opportunità di apprendere dai dati, con conseguente sottoadattamento.
Come rilevare l'underfitting
Un modo per rilevare l'underfitting è analizzare le curve di apprendimento, che tracciano le prestazioni del modello (tipicamente perdita o errore) rispetto al numero di iterazioni di training. Una curva di apprendimento mostra come il modello migliora (o non riesce a migliorare) nel tempo sia sui set di dati di training che su quelli di convalida.
La perdita è l'entità dell'errore del modello per un dato insieme di dati. La perdita di addestramento misura questo per i dati di addestramento e la perdita di convalida per i dati di convalida. I dati di convalida sono un set di dati separato utilizzato per testare le prestazioni del modello. Di solito viene prodotto suddividendo in modo casuale un set di dati più ampio in dati di training e convalida.
In caso di underfitting, noterai i seguenti schemi chiave:
- Perdita di addestramento elevata:se la perdita di addestramento del modello rimane elevata e piatta nelle prime fasi del processo, ciò suggerisce che il modello non sta imparando dai dati di addestramento. Questo è un chiaro segno di insufficiente adattamento, poiché il modello è troppo semplice per adattarsi alla complessità dei dati.
- Perdita simile di formazione e convalida:se sia la perdita di formazione che quella di convalida sono elevate e rimangono vicine l'una all'altra durante tutto il processo di formazione, significa che il modello ha prestazioni inferiori su entrambi i set di dati. Ciò indica che il modello non sta acquisendo informazioni sufficienti dai dati per fare previsioni accurate, il che indica un adattamento insufficiente.
Di seguito è riportato un grafico di esempio che mostra le curve di apprendimento in uno scenario di adattamento insufficiente:
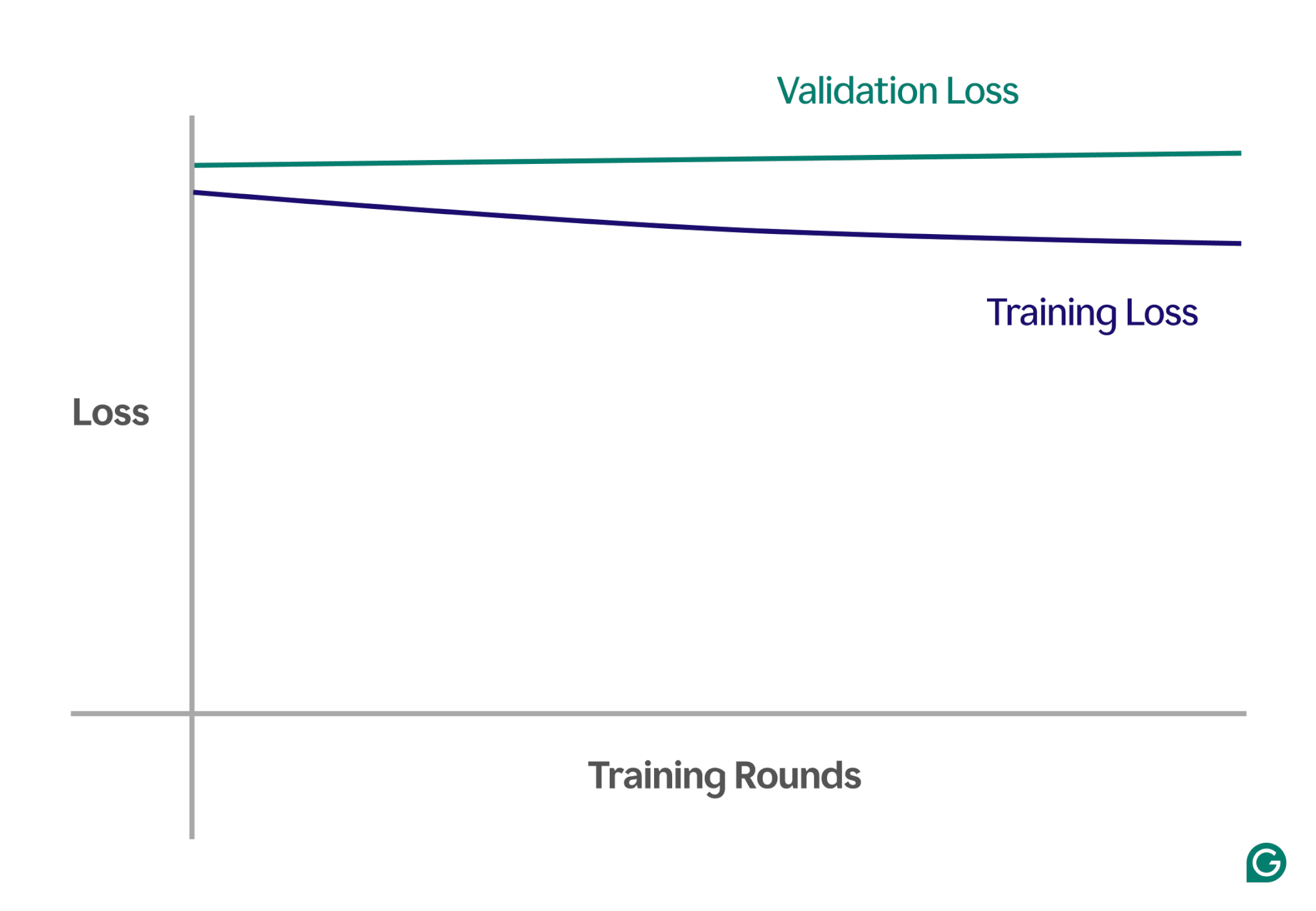
In questa rappresentazione visiva, l’underfitting è facile da individuare:
- In un modello ben adattato, la perdita di addestramento diminuisce in modo significativo mentre la perdita di convalida segue un modello simile, stabilizzandosi infine.
- In un modello sottodimensionato, sia la perdita di formazione che quella di convalida iniziano in modo elevato e rimangono elevate, senza alcun miglioramento significativo.
Osservando queste tendenze, puoi identificare rapidamente se il modello è troppo semplicistico e necessita di aggiustamenti per aumentarne la complessità.
Tecniche per prevenire l'underfitting
Se riscontri un underfitting, esistono diverse strategie che puoi utilizzare per migliorare le prestazioni del modello:
- Ulteriori dati di addestramento:se possibile, ottenere ulteriori dati di addestramento. Una maggiore quantità di dati offre al modello ulteriori opportunità di apprendere modelli, a condizione che i dati siano di alta qualità e pertinenti al problema in questione.
- Espandi la selezione delle funzionalità:aggiungi al modello le funzionalità più rilevanti. Scegli caratteristiche che hanno una forte relazione con la variabile target, dando al modello una migliore possibilità di catturare modelli importanti che in precedenza erano sfuggiti.
- Aumentare la potenza dell'architettura:nei modelli basati su reti neurali, è possibile regolare la struttura dell'architettura modificando il numero di pesi, livelli o altri iperparametri. Ciò può consentire al modello di essere più flessibile e di trovare più facilmente modelli di alto livello nei dati.
- Scegli un modello diverso:a volte, anche dopo aver ottimizzato gli iperparametri, un modello specifico potrebbe non essere adatto all'attività. Testare più algoritmi di modello può aiutare a trovare un modello più appropriato e migliorare le prestazioni.
Esempi pratici di underfitting
Per illustrare gli effetti dell'underfitting, esaminiamo esempi reali in vari ambiti in cui i modelli non riescono a catturare la complessità dei dati, portando a previsioni imprecise.
Prevedere i prezzi delle case
Per prevedere con precisione il prezzo di una casa, è necessario considerare molti fattori, tra cui la posizione, le dimensioni, il tipo di casa, le condizioni e il numero di camere da letto.
Se utilizzi troppo poche funzionalità, ad esempio solo le dimensioni e il tipo di casa, il modello non avrà accesso a informazioni critiche. Ad esempio, il modello potrebbe presupporre che un piccolo monolocale sia poco costoso, senza sapere che si trova a Mayfair, Londra, un’area con prezzi immobiliari elevati. Ciò porta a previsioni inadeguate.
Per risolvere questo problema, i data scientist devono garantire una corretta selezione delle funzionalità. Ciò implica includere tutte le funzionalità rilevanti, escludendo quelle irrilevanti, e utilizzare dati di addestramento accurati.
Riconoscimento vocale
La tecnologia di riconoscimento vocale è diventata sempre più comune nella vita quotidiana. Ad esempio, gli assistenti smartphone, le linee di assistenza clienti e le tecnologie assistive per le disabilità utilizzano tutti il riconoscimento vocale. Durante l'addestramento di questi modelli, vengono utilizzati i dati provenienti da campioni vocali e le loro interpretazioni corrette.
Per riconoscere il parlato, il modello converte in dati le onde sonore catturate da un microfono. Se semplifichiamo il tutto fornendo solo la frequenza dominante e il volume della voce a intervalli specifici, riduciamo la quantità di dati che il modello deve elaborare.
Tuttavia, questo approccio elimina le informazioni essenziali necessarie per comprendere appieno il discorso. I dati diventano troppo semplicistici per catturare la complessità del linguaggio umano, come le variazioni di tono, tono e accento.
Di conseguenza, il modello risulterà inadeguato, faticando a riconoscere anche i comandi verbali di base, per non parlare delle frasi complete. Anche se il modello è sufficientemente complesso, la mancanza di dati esaustivi porta a un sottoadattamento.
Classificazione delle immagini
Un classificatore di immagini è progettato per prendere un'immagine come input e restituire una parola per descriverla. Supponiamo che tu stia costruendo un modello per rilevare se un'immagine contiene o meno una palla. Addestri il modello utilizzando immagini etichettate di palline e altri oggetti.
Se si utilizza erroneamente una semplice rete neurale a due strati invece di un modello più adatto come una rete neurale convoluzionale (CNN), il modello avrà difficoltà. La rete a due strati appiattisce l'immagine in un unico strato, perdendo importanti informazioni spaziali. Inoltre, con solo due livelli, il modello non ha la capacità di identificare caratteristiche complesse.
Ciò porta a un sottoadattamento, poiché il modello non riuscirà a fare previsioni accurate, anche sui dati di addestramento. Le CNN risolvono questo problema preservando la struttura spaziale delle immagini e utilizzando livelli convoluzionali con filtri che imparano automaticamente a rilevare caratteristiche importanti come bordi e forme nei primi strati e oggetti più complessi negli strati successivi.