
ニューラルネットワークとは何ですか?
公開: 2024-06-26ニューラルネットワークとは何ですか?
ニューラル ネットワークは、人間の脳をシミュレートする、機械学習 (ML) のより広範な分野内の深層学習モデルの一種です。 入力、非表示、出力の層に配置された相互接続されたノードまたはニューロンを通じてデータを処理します。 各ノードは単純な計算を実行し、パターンを認識して予測を行うモデルの機能に貢献します。
ディープラーニング ニューラル ネットワークは、画像や音声認識などの複雑なタスクの処理に特に効果的であり、多くの AI アプリケーションの重要なコンポーネントを形成しています。 ニューラル ネットワーク アーキテクチャとトレーニング技術の最近の進歩により、AI システムの機能が大幅に強化されました。
ニューラルネットワークの構造
その名前が示すように、ニューラル ネットワーク モデルは、脳の構成要素であるニューロンからインスピレーションを得ています。 成人には約 850 億個のニューロンがあり、それぞれが約 1,000 個の他のニューロンと接続しています。 ある脳細胞は、神経伝達物質と呼ばれる化学物質を送ることによって他の脳細胞と対話します。 受信細胞がこれらの化学物質を十分に受け取ると、興奮して自身の化学物質を別の細胞に送ります。
人工ニューラル ネットワーク (ANN) と呼ばれることもあるものの基本単位はノードであり、セルではなく数学関数です。 ニューロンと同様に、十分な入力があれば他のノードと通信します。
類似点はここまでです。 ニューラル ネットワークは脳よりもはるかに単純な構造で、入力層、隠れ層、出力層がきちんと定義されています。 これらのレイヤーの集合をモデルと呼びます。 彼らは、望ましい結果に最もよく似た出力を人工的に生成することを繰り返し試みることによって学習または訓練します。 (これについては後ほど詳しく説明します。)
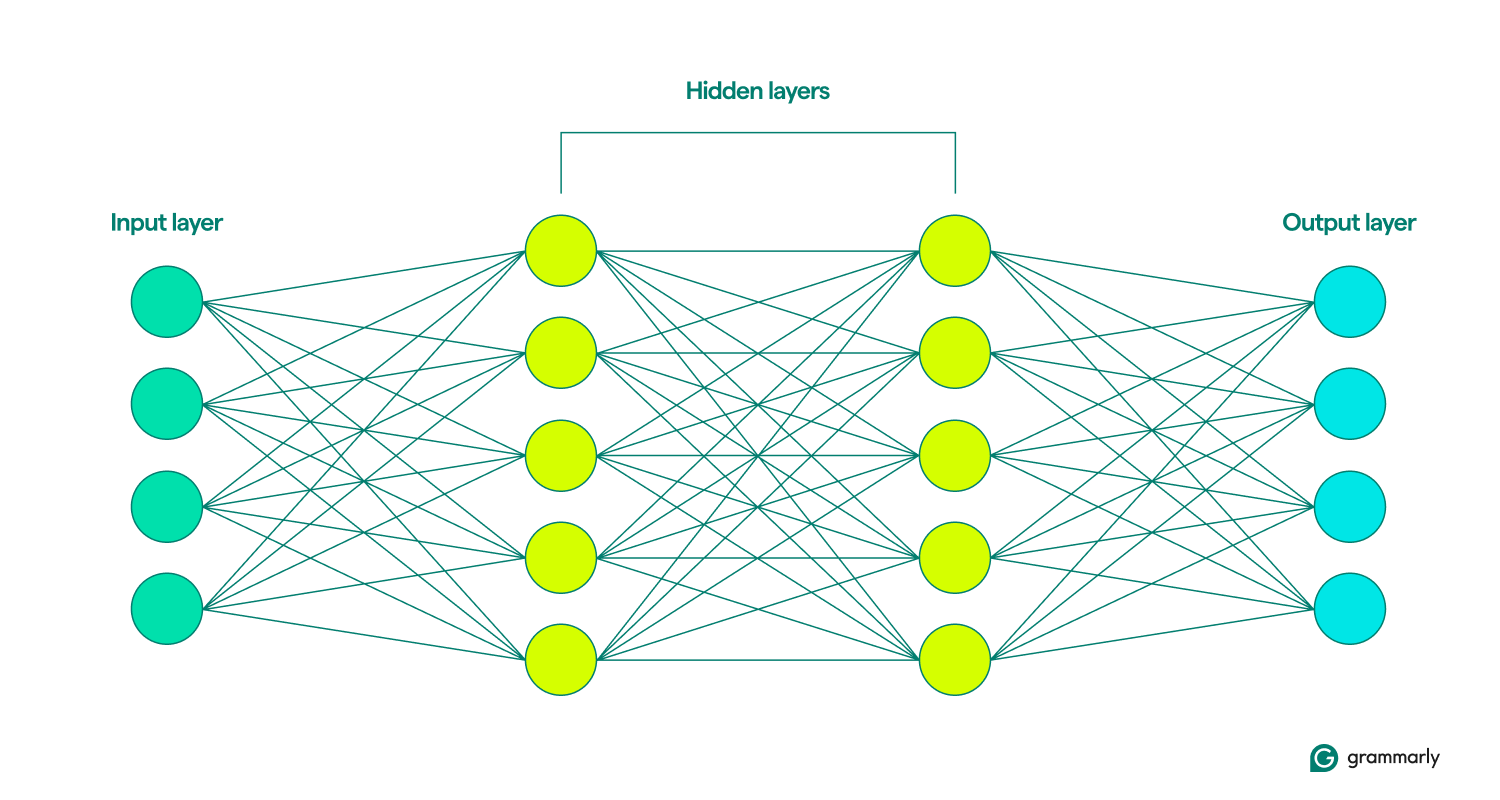
入力層と出力層は一目瞭然です。 ニューラル ネットワークの動作のほとんどは隠れ層で行われます。 ノードが前の層からの入力によってアクティブ化されると、ノードは計算を実行し、出力を次の層のノードに渡すかどうかを決定します。 これらの層は、その操作がエンド ユーザーには見えないためそのように名付けられていますが、いわゆる隠れ層で何が起こっているかをエンジニアが確認するための技術があります。
ニューラル ネットワークに複数の隠れ層が含まれる場合、それらは深層学習ネットワークと呼ばれます。 最新のディープ ニューラル ネットワークには、通常、異なる機能を実行する特殊なサブレイヤーを含む多くのレイヤーがあります。 たとえば、一部のサブレイヤーは、分析対象の直接の入力を超えたコンテキスト情報を考慮するネットワークの能力を強化します。
ニューラルネットワークの仕組み
赤ちゃんがどのように学習するかを考えてみましょう。 彼らは何かを試みては失敗し、別の方法で再試行します。 動作が完璧になるまで、ループが何度も続きます。 ニューラル ネットワークも多かれ少なかれこれと同じように学習します。
トレーニングの最初に、ニューラル ネットワークはランダムな推測を行います。 入力層のノードは、最初の隠れ層のどのノードをアクティブ化するかをランダムに決定し、その後、それらのノードが次の層のノードをランダムにアクティブ化するというように、このランダム プロセスが出力層に到達するまで繰り返されます。 (GPT-4 などの大規模な言語モデルには約 100 の層があり、各層に数万から数十万のノードがあります。)
すべてのランダム性を考慮して、モデルはその出力 (おそらくひどいものです) を比較し、それがどの程度間違っていたかを判断します。 次に、各ノードの他のノードへの接続を調整し、特定の入力に基づいてノードがアクティブになる傾向を多少なりとも変更します。 出力が望ましい答えに近づくまで、これを繰り返し実行します。
では、ニューラル ネットワークはどのようにして自分たちが何をすべきかを知るのでしょうか? 機械学習 (ML) は、教師あり学習と教師なし学習など、さまざまなアプローチに分類できます。 教師あり学習では、説明テキストと組み合わせた画像など、明示的なラベルや回答を含むデータでモデルがトレーニングされます。 ただし、教師なし学習では、モデルにラベルのないデータを提供することで、モデルがパターンと関係を独立して識別できるようにします。
このトレーニングの一般的な補足は強化学習であり、フィードバックに応じてモデルが改善されます。 多くの場合、これは人間の評価者によって提供されます (コンピューターの提案に賛成または反対をクリックしたことがあれば、あなたは強化学習に貢献したことになります)。 それでも、モデルが独立して反復学習する方法もあります。
ニューラル ネットワークの出力を予測として考えることは正確で有益です。 信用度の評価でも、曲の生成でも、AI モデルは何が最も正しいかを推測することで機能します。 ChatGPT などの生成 AI は、予測をさらに一歩進めます。 これは順番に動作し、作成したばかりの出力の後に何が来るかを推測します。 (これが問題となる理由については後ほど説明します。)
ニューラルネットワークが答えを生成する仕組み
ネットワークが訓練されると、正しい応答を予測するために、ネットワークは見た情報をどのように処理するのでしょうか? ChatGPT インターフェイスに「妖精についての話をしてください」のようなプロンプトを入力すると、ChatGPT は応答方法をどのように決定するのでしょうか?
最初のステップは、ニューラル ネットワークの入力層がプロンプトをトークンと呼ばれる小さな情報の塊に分割することです。 画像認識ネットワークの場合、トークンはピクセルである可能性があります。 ChatGPT などの自然言語処理 (NLP) を使用するネットワークの場合、トークンは通常、単語、単語の一部、または非常に短いフレーズです。
ネットワークが入力にトークンを登録すると、その情報は以前にトレーニングされた隠れ層を介して渡されます。 ある層から次の層に渡されるノードは、入力のより大きなセクションを分析します。 このようにして、NLP ネットワークは最終的に、単語や文字だけでなく、文全体や段落全体を解釈できるようになります。
これで、ネットワークは応答の作成を開始できるようになります。これは、トレーニングされたすべての内容に基づいて、次に何が来るかを一連の単語ごとに予測することによって行われます。
「妖精についての話をしてください」というプロンプトを考えてみましょう。 応答を生成するために、ニューラル ネットワークはプロンプトを分析して、最も可能性の高い最初の単語を予測します。 たとえば、「The」が最良の選択肢である確率は 80%、「A」については 10%、「Once」については 10% の確率であると判断できます。 次に、ランダムに数字を選択します。数字が 1 ~ 8 の場合、「The」を選択します。 9 の場合は「A」を選択します。 10 の場合は「1 回」を選択します。 乱数が「The」に相当する 4 であるとします。 その後、ネットワークはプロンプトを更新して「妖精についての話をしてください。 「The」に続く次の単語を予測するプロセスを繰り返します。 このサイクルは、更新されたプロンプトに基づいて新しい単語が予測されるたびに、完全なストーリーが生成されるまで続きます。
ネットワークが異なれば、この予測も異なります。 たとえば、画像認識モデルは、犬の画像にどのラベルを付けるかを予測し、正しいラベルが「チョコレート ラボ」である確率は 70%、「イングリッシュ スパニエル」である確率は 20%、そして「イングリッシュ スパニエル」である確率は 10% であると判断する場合があります。 「ゴールデンレトリバー」の場合。 分類の場合、一般に、ネットワークは確率的な推測ではなく、最も可能性の高い選択を採用します。
ニューラルネットワークの種類
ここでは、さまざまな種類のニューラル ネットワークとその動作の概要を説明します。
- フィードフォワード ニューラル ネットワーク (FNN):これらのモデルでは、情報は一方向に流れます: 入力層から隠れ層を通って、最後に出力層に流れます。このモデル タイプは、クレジット カード詐欺の検出など、より単純な予測タスクに最適です。
- リカレント ニューラル ネットワーク (RNN): FNN とは対照的に、RNN は予測を生成するときに以前の入力を考慮します。プロンプトに応じて生成される文の終わりは文の始まりに依存するため、言語処理タスクに適しています。
- 長短期記憶ネットワーク (LSTM): LSTM は情報を選択的に忘れるため、より効率的に機能します。これは、大量のテキストを処理する場合に非常に重要です。 たとえば、Google 翻訳の 2016 年のニューラル機械翻訳へのアップグレードは LSTM に依存していました。
- 畳み込みニューラル ネットワーク (CNN): CNN は画像を処理するときに最もよく機能します。畳み込みレイヤーを使用して画像全体をスキャンし、線や形状などの特徴を探します。 これにより、CNN は、オブジェクトが画像の上半分にあるか下半分にあるかを判断するなど、空間的な位置を考慮したり、位置に関係なく形状やオブジェクトのタイプを識別したりすることができます。
- 敵対的生成ネットワーク (GAN): GAN は、説明または既存の画像に基づいて新しい画像を生成するためによく使用されます。これらは 2 つのニューラル ネットワーク間の競合として構造化されています。ジェネレーターネットワークは、ディスクリミネーターネットワークを騙して偽の入力が本物であると信じ込ませようとします。
- トランスフォーマーとアテンション ネットワーク:トランスフォーマーは、現在の AI 機能の爆発的な増加に関与しています。これらのモデルには、入力をフィルタリングして最も重要な要素に焦点を当てることができる注意的なスポットライトが組み込まれており、テキストのページ全体であっても、それらの要素が互いにどのように関連しているかがわかります。 Transformers は膨大な量のデータでトレーニングすることもできるため、ChatGPT や Gemini のようなモデルは大規模言語モデル (LLM)と呼ばれます。
ニューラルネットワークの応用
リストするには多すぎるため、ここでは自然言語に重点を置いて、今日のニューラル ネットワークの使用方法をいくつか紹介します。

執筆支援:トランスフォーマーは、コンピューターが人々の執筆を改善する方法を変革しました。Grammarly などの AI ライティング ツールは、文および段落レベルの書き直しを提供して、トーンと明瞭さを向上させます。 このモデル タイプでは、基本的な文法提案の速度と精度も向上しました。 Grammarly が AI をどのように使用するかについて詳しくは、こちらをご覧ください。
コンテンツ生成: ChatGPT または DALL-E を使用したことがある場合は、生成 AI を直接体験したことになります。 トランスフォーマーは、就寝時の物語から超現実的な建築レンダリングまで、人間の心に響くメディアを作成するコンピューターの能力に革命をもたらしました。
音声認識:コンピューターは人間の音声を認識する能力が日々向上しています。より多くのコンテキストを考慮できるようになった新しいテクノロジーにより、たとえ音だけで複数の解釈ができる場合でも、モデルは話者の意図する内容をますます正確に認識できるようになりました。
医療診断と研究:ニューラル ネットワークはパターンの検出と分類に優れており、研究者や医療提供者が病気を理解して対処できるようにするために使用されることが増えています。たとえば、新型コロナウイルス感染症ワクチンの急速な開発の一部には AI に感謝する必要があります。
ニューラルネットワークの課題と限界
ここでは、ニューラル ネットワークによって引き起こされる問題のすべてではありませんが、その一部を簡単に説明します。
バイアス:ニューラル ネットワークは、指示された内容からのみ学習できます。性差別的または人種差別的なコンテンツにさらされた場合、その出力も性差別的または人種差別的になる可能性があります。 これは、性別のない言語から性別の言語に翻訳する際に発生する可能性があり、明示的な性別の識別なしに固定観念が存続します。
過学習:モデルが不適切にトレーニングされると、与えられたデータを読み込みすぎて、新しい入力に苦戦する可能性があります。たとえば、主に特定の民族の人々を対象としてトレーニングされた顔認識ソフトウェアは、他の人種の顔ではうまく機能しない可能性があります。 あるいは、スパム フィルターは、以前に見られたパターンに重点を置きすぎるため、新しい種類のジャンク メールを見逃す可能性があります。
幻覚:今日の生成 AI の多くは、常に上位の選択肢を選択するのではなく、生成するものを選択するためにある程度確率を使用します。このアプローチは、よりクリエイティブになり、より自然に聞こえるテキストを生成するのに役立ちますが、単に虚偽の発言をする可能性もあります。 (これが、LLM が基本的な数学を間違うことがある理由でもあります。) 残念ながら、これらの幻覚は、より詳しい知識があるか、他の情報源で事実確認しない限り、検出するのが困難です。
解釈可能性:ニューラル ネットワークがどのように予測を行うかを正確に知ることは多くの場合不可能です。これは、モデルを改善しようとしている人の観点からはイライラする可能性がありますが、人々の生活に大きな影響を与える意思決定を行うために AI への依存がますます高まっているため、結果的なものになる可能性もあります。 現在使用されている一部のモデルは、作成者がプロセスのあらゆる段階を検査して理解できるようにしたいという理由から、ニューラル ネットワークに基づいていません。
知的財産: LLM は著作物やその他の芸術作品を許可なく組み込むことで著作権を侵害していると多くの人が考えています。これらのモデルは著作権で保護された作品を直接複製することはありませんが、特定のアーティストに由来する可能性が高い画像や表現を作成したり、指示に応じてアーティストの独特のスタイルで作品を作成したりすることが知られています。
電力消費:変圧器モデルのトレーニングと実行には、膨大なエネルギーが使用されます。実際、数年以内に、AI はスウェーデンやアルゼンチンと同じくらいの電力を消費する可能性があります。 これは、AI 開発におけるエネルギー源と効率を考慮することの重要性が高まっていることを浮き彫りにしています。
ニューラルネットワークの未来
AI の将来を予測することは難しいことで知られています。 1970 年、AI 研究のトップの一人は、「3 ~ 8 年以内に、平均的な人間と同等の一般的な知能を備えたマシンが登場するだろう」と予測しました。 (私たちはまだ汎用人工知能 (AGI) にそれほど近づいていません。少なくともほとんどの人はそう思っていません。)
ただし、注意すべき傾向がいくつか指摘できます。 より効率的なモデルでは、消費電力が削減され、より強力なニューラル ネットワークがスマートフォンなどのデバイス上で直接実行されます。 新しいトレーニング手法を使用すると、少ないトレーニング データでより有用な予測が可能になる可能性があります。 解釈可能性の画期的な進歩により、信頼性が高まり、ニューラル ネットワークの出力を改善するための新しい道が開かれる可能性があります。 最後に、量子コンピューティングとニューラル ネットワークを組み合わせることで、私たちが想像し始めたばかりのイノベーションがもたらされる可能性があります。
結論
人間の脳の構造と機能にヒントを得たニューラル ネットワークは、現代の人工知能の基礎です。 これらはパターン認識と予測タスクに優れており、画像や音声認識から自然言語処理に至るまで、今日の AI アプリケーションの多くを支えています。 アーキテクチャとトレーニング技術の進歩により、ニューラル ネットワークは AI 機能の大幅な向上を推進し続けています。
ニューラル ネットワークは、その可能性にもかかわらず、バイアス、過剰適合、高エネルギー消費などの課題に直面しています。 AI が進化し続ける中で、これらの問題に対処することは非常に重要です。 今後を見据えると、モデルの効率性、解釈可能性、量子コンピューティングとの統合における革新により、ニューラル ネットワークの可能性がさらに拡大し、さらに革新的なアプリケーションにつながる可能性があります。