
リカレント ニューラル ネットワークの基礎: 知っておくべきこと
公開: 2024-09-19リカレント ニューラル ネットワーク (RNN) は、データ分析、機械学習 (ML)、ディープ ラーニングの分野で不可欠な手法です。この記事は、深層学習のより広範なコンテキスト内で RNN を調査し、その機能、用途、利点と欠点を詳しく説明することを目的としています。
目次
RNNとは何ですか?
RNN の仕組み
RNN の種類
RNN とトランスフォーマーおよび CNN の比較
RNN の応用
利点
短所
リカレント ニューラル ネットワークとは何ですか?
リカレント ニューラル ネットワークは、内部メモリを維持することで順次データを処理できるディープ ニューラル ネットワークで、過去の入力を追跡して出力を生成できます。 RNN は深層学習の基本コンポーネントであり、シーケンシャル データを含むタスクに特に適しています。
「リカレント ニューラル ネットワーク」の「リカレント」は、モデルが過去の入力からの情報を現在の入力とどのように組み合わせるかを指します。古い入力からの情報は、「隠し状態」と呼ばれる一種の内部メモリに保存されます。これは繰り返し行われ、以前の計算をそれ自体にフィードバックして、継続的な情報の流れを作成します。
例で説明しましょう。RNN を使用して、「彼はパイを幸せに食べました。」という文の感情 (肯定的または否定的) を検出したいとします。 RNN は単語heを処理し、隠れた状態を更新してその単語を組み込んでから、 ateに進み、それをheから学習した内容と組み合わせるなど、文が完成するまで各単語に対して繰り返します。客観的に見ると、この文を読んだ人間は、単語ごとに理解を更新することになります。人間は文全体を読んで理解すると、その文が肯定的であるか否定的であるかを判断できます。この人間の理解プロセスは、隠れた状態が近似しようとするものです。
RNN は、基本的な深層学習モデルの 1 つです。自然言語処理 (NLP) タスクでは非常にうまく機能しましたが、トランスフォーマーがそれに取って代わりました。トランスフォーマーは、たとえばデータを並列処理し、ソース テキスト内で遠く離れた単語間の関係を (アテンション メカニズムを使用して) 検出できるようにすることで、RNN のパフォーマンスを向上させる高度なニューラル ネットワーク アーキテクチャです。ただし、時系列データや、より単純なモデルで十分な状況では、RNN は依然として役立ちます。
RNN の仕組み
RNN がどのように機能するかを詳しく説明するために、前のタスク例に戻ってみましょう。「彼は喜んでパイを食べました。」という文の感情を分類します。
まず、テキスト入力を受け入れ、バイナリ出力 (正を表す 1、負を表す 0) を返すトレーニング済み RNN から始めます。入力がモデルに与えられる前の隠れ状態は汎用的なものであり、トレーニング プロセスから学習されましたが、まだ入力に固有ではありません。
最初の単語Heがモデルに渡されます。 RNN 内では、単語Heを組み込むために、その隠れ状態が (隠れ状態 h1 に) 更新されます。次に、単語ateがRNNに渡され、この新しい単語を含めるようにh1が(h2に)更新されます。このプロセスは、最後の単語が渡されるまで繰り返されます。最後の単語を含むように非表示状態 (h4) が更新されます。次に、更新された非表示状態を使用して 0 または 1 が生成されます。
RNN プロセスがどのように機能するかを視覚的に表現したものが次のとおりです。
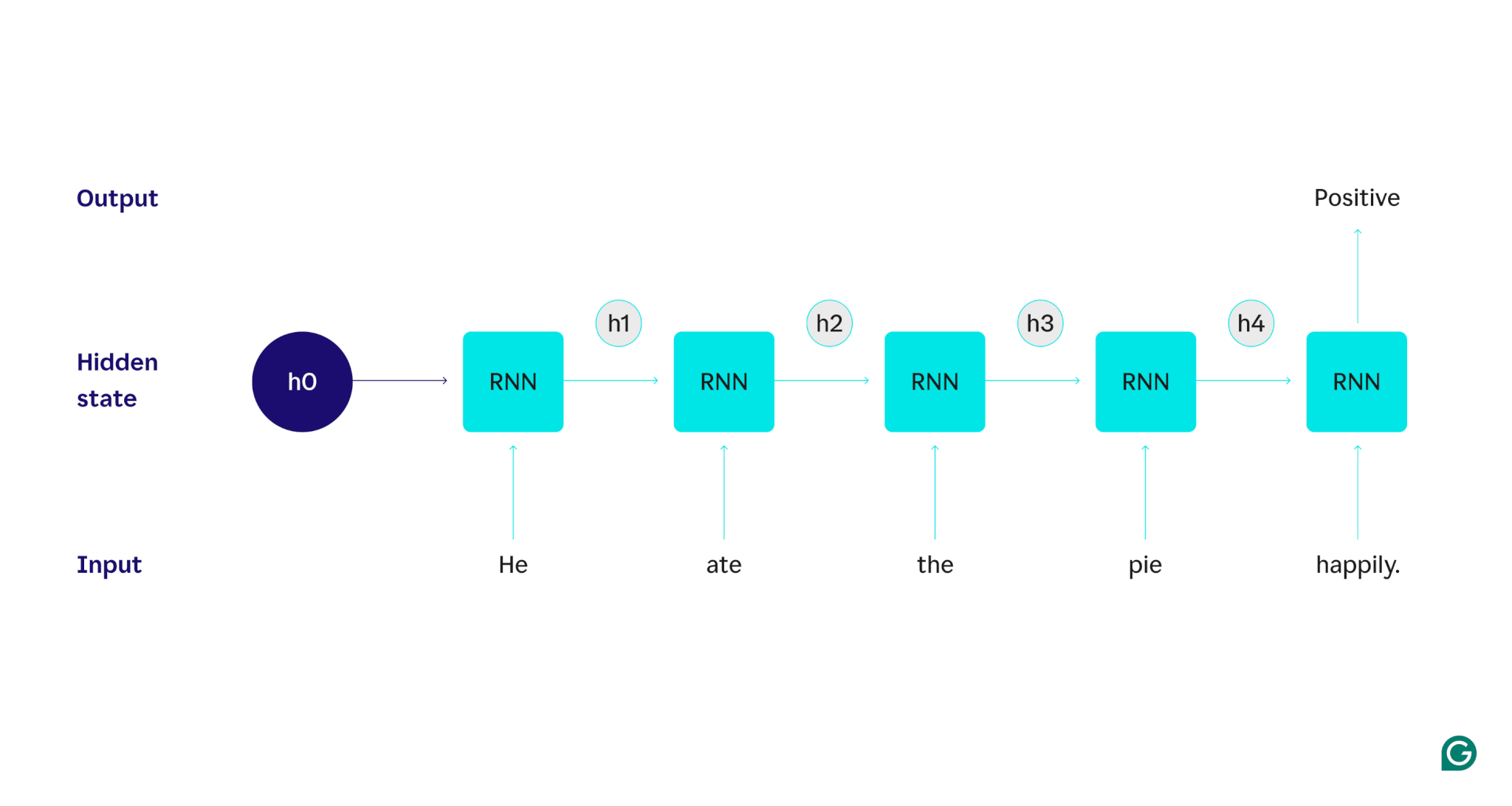
この繰り返しは RNN の中核ですが、他にも考慮すべき点がいくつかあります。
- テキストの埋め込み: RNN は数値表現でのみ機能するため、テキストを直接処理できません。テキストは、RNN で処理する前に埋め込みに変換する必要があります。
- 出力生成:出力は各ステップで RNN によって生成されます。ただし、ソース データの大部分が処理されるまで、出力はあまり正確ではない可能性があります。たとえば、文の「彼は食べました」の部分だけを処理した後、RNN はそれが肯定的な感情を表しているのか、否定的な感情を表しているのか判断できない可能性があります。つまり、「彼は食べました」が中立的な印象を与える可能性があります。 RNN の出力が正確になるのは、文全体を処理した後でのみです。
- RNN のトレーニング:感情分析を正確に実行するには、RNN をトレーニングする必要があります。トレーニングには、多くのラベル付きの例 (例: 「彼は怒ってパイを食べた」、否定的なラベルが付けられている) を使用し、それらを RNN に実行し、その予測がどれだけ外れているかに基づいてモデルを調整することが含まれます。このプロセスにより、隠れ状態のデフォルト値と変更メカニズムが設定され、RNN が入力全体の追跡にどの単語が重要であるかを学習できるようになります。
リカレント ニューラル ネットワークの種類
RNN にはいくつかの異なるタイプがあり、それぞれの構造と用途が異なります。基本的な RNN の主な違いは、入力と出力のサイズです。長短期記憶 (LSTM) ネットワークなどの高度な RNN は、基本的な RNN の制限の一部に対処します。
基本的な RNN
1 対 1 RNN:この RNN は長さ 1 の入力を受け取り、長さ 1 の出力を返します。したがって、実際には再発は起こらず、RNN ではなく標準のニューラル ネットワークになります。 1 対 1 RNN の例は、入力が単一の画像で出力がラベル (「鳥」など) である画像分類器です。
1 対多 RNN:この RNN は長さ 1 の入力を受け取り、マルチパート出力を返します。たとえば、画像キャプションタスクでは、入力は 1 つの画像で、出力は画像を説明する一連の単語になります (例: 「晴れた日に鳥が川を渡る」)。
多対 1 RNN:この RNN は、マルチパート入力 (例: 文、一連の画像、または時系列データ) を受け取り、長さ 1 の出力を返します。たとえば、文センチメント分類子 (先ほど説明したものと同様) では、入力が文で、出力が単一のセンチメント ラベル (肯定的または否定的) になります。
多対多 RNN:この RNN はマルチパート入力を受け取り、マルチパート出力を返します。例としては、入力が一連のオーディオ波形であり、出力が話された内容を表す一連の単語である音声認識モデルがあります。
高度な RNN: 長短期記憶 (LSTM)
長短期記憶ネットワークは、標準 RNN の重大な問題、つまり、長い入力が続くと情報を忘れてしまうという問題に対処するように設計されています。標準 RNN では、隠れ状態は入力の最近の部分に大きく重み付けされます。数千語の長さの入力では、RNN は冒頭の文の重要な詳細を忘れてしまいます。 LSTM には、この忘却の問題を回避するための特別なアーキテクチャがあります。これらには、明示的に記憶する情報と忘れる情報を選択するモジュールがあります。そのため、最近ではあるが役に立たない情報は忘れられ、古いが関連性のある情報は保持されます。結果として、LSTM は標準の RNN よりもはるかに一般的です。単純に、LSTM は複雑なタスクや長いタスクでより優れたパフォーマンスを発揮します。ただし、アイテムを忘れることを選択するため、完璧ではありません。

RNN とトランスフォーマーおよび CNN の比較
他の 2 つの一般的な深層学習モデルは、畳み込みニューラル ネットワーク (CNN) とトランスフォーマーです。どう違うのでしょうか?
RNN とトランスフォーマーの比較
NLP では RNN とトランスフォーマーの両方が頻繁に使用されます。ただし、入力を処理するアーキテクチャとアプローチは大きく異なります。
アーキテクチャと処理
- RNN:RNN は入力を一度に 1 単語ずつ順番に処理し、前の単語からの情報を伝える隠れた状態を維持します。この逐次的な性質は、RNN がこの忘却による長期的な依存関係に苦戦する可能性があることを意味し、シーケンスが進むにつれて以前の情報が失われる可能性があります。
- トランスフォーマー:トランスフォーマーは、「アテンション」と呼ばれるメカニズムを使用して入力を処理します。 RNN とは異なり、トランスフォーマーはシーケンス全体を同時に調べ、各単語を他のすべての単語と比較します。このアプローチでは、各単語が入力コンテキスト全体に直接アクセスできるため、忘れの問題が解消されます。 Transformers は、この機能により、テキスト生成やセンチメント分析などのタスクで優れたパフォーマンスを示しています。
並列化
- RNN: RNN の逐次的な性質は、モデルが次の部分に進む前に入力の一部の処理を完了する必要があることを意味します。各ステップは前のステップに依存するため、これには非常に時間がかかります。
- トランスフォーマー:トランスフォーマーのアーキテクチャは逐次的な隠れ状態に依存しないため、入力のすべての部分を同時に処理します。これにより、並列化がより可能になり、効率が向上します。たとえば、文の処理に 1 単語あたり 5 秒かかる場合、RNN では 5 単語の文に 25 秒かかりますが、Transformer では 5 秒しかかかりません。
実際的な意味
これらの利点により、変圧器は産業界でより広く使用されています。ただし、RNN、特に長短期記憶 (LSTM) ネットワークは、より単純なタスクや短いシーケンスを扱う場合には依然として効果的です。 LSTM は、大規模な機械学習アーキテクチャの重要なメモリ ストレージ モジュールとしてよく使用されます。
RNN 対 CNN
CNN は、扱うデータとその動作メカニズムの点で RNN とは根本的に異なります。
データ型
- RNN: RNN は、データ ポイントの順序が重要な、テキストや時系列などのシーケンシャル データ用に設計されています。
- CNN:CNN は主に画像などの空間データに使用され、隣接するデータ ポイント間の関係に焦点が当てられます (たとえば、画像内のピクセルの色、強度、その他のプロパティは、近くにある他のピクセルのプロパティと密接に関連しています)ピクセル)。
手術
- RNN: RNN はシーケンス全体のメモリを維持するため、コンテキストとシーケンスが重要なタスクに適しています。
- CNN:CNN は、畳み込み層を通じて入力の局所領域 (隣接するピクセルなど) を調べることによって動作します。これにより、画像処理では非常に効果的になりますが、長期的な依存関係がより重要になる可能性があるシーケンシャル データではそれほど効果的ではありません。
入力長さ
- RNN: RNN は、あまり定義されていない構造で可変長の入力シーケンスを処理できるため、さまざまな順次データ型に柔軟に対応できます。
- CNN:CNN は通常、固定サイズの入力を必要とするため、可変長シーケンスの処理に制限が生じる可能性があります。
RNN の応用
RNN は、逐次データを効果的に処理できるため、さまざまな分野で広く使用されています。
自然言語処理
言語は高度に逐次的な形式のデータであるため、RNN は言語タスクで適切にパフォーマンスを発揮します。 RNN は、テキスト生成、感情分析、翻訳、要約などのタスクに優れています。 PyTorch のようなライブラリを使用すると、RNN と数ギガバイトのテキスト サンプルを使用して簡単なチャットボットを作成できます。
音声認識
音声認識は本質的に言語であるため、非常に逐次的です。このタスクには多対多の RNN を使用できます。各ステップで、RNN は前の隠れ状態と波形を取得し、波形に関連付けられた単語を (その時点までの文のコンテキストに基づいて) 出力します。
音楽の生成
音楽も非常に連続的です。曲の前のビートは、後のビートに強く影響します。多対多の RNN は、いくつかの開始ビートを入力として受け取り、ユーザーの希望に応じて追加のビートを生成できます。あるいは、「メロディック ジャズ」のようなテキスト入力を受け取り、メロディック ジャズのビートに最も近いものを出力することもできます。
RNN の利点
RNN はもはや事実上の NLP モデルではありませんが、いくつかの要因により依然としていくつかの用途があります。
優れたシーケンシャルパフォーマンス
RNN、特に LSTM は、順次データに対して優れた性能を発揮します。 LSTM は、特殊なメモリ アーキテクチャを備えており、長く複雑な連続入力を管理できます。たとえば、Google 翻訳は、トランスフォーマーの時代以前は LSTM モデルで実行されていました。変圧器ベースのネットワークを組み合わせてより高度なアーキテクチャを形成する場合、LSTM を使用して戦略的メモリ モジュールを追加できます。
より小型でシンプルなモデル
通常、RNN のモデル パラメーターはトランスフォーマーよりも少なくなります。トランスフォーマーのアテンション層とフィードフォワード層が効果的に機能するには、より多くのパラメーターが必要です。 RNN は、より少ない実行数とデータ例でトレーニングできるため、より単純なユースケースでより効率的になります。これにより、十分なパフォーマンスを維持しながら、より小型で、より安価で、より効率的なモデルが得られます。
RNN の欠点
RNN が人気を失ったのには理由があります。Transformer は、そのサイズとトレーニング プロセスが大きいにもかかわらず、RNN のような欠陥を持っていません。
限られたメモリ
標準 RNN の隠れた状態は、最近の入力に大きなバイアスを与えるため、長距離の依存関係を保持することが困難になります。長い入力を伴うタスクは、RNN ではそれほどパフォーマンスが良くありません。 LSTM はこの問題に対処することを目指していますが、軽減するだけで完全には解決しません。多くの AI タスクでは長い入力を処理する必要があるため、メモリの制限が大きな欠点となります。
並列化不可
RNN モデルの各実行は、前回の実行の出力、特に更新された隠れ状態に依存します。その結果、モデル全体を入力の各部分に対して順番に処理する必要があります。対照的に、トランスフォーマーと CNN は入力全体を同時に処理できます。これにより、複数の GPU にわたる並列処理が可能になり、計算が大幅に高速化されます。 RNN には並列性がないため、トレーニングが遅くなり、出力生成が遅くなり、学習できるデータの最大量が少なくなります。
勾配の問題
バックプロパゲーション プロセスは各入力ステップを通過する必要があるため (時間によるバックプロパゲーション)、RNN のトレーニングは困難な場合があります。タイム ステップが多いため、各モデル パラメーターをどのように調整するかを示す勾配が低下し、効果がなくなる可能性があります。勾配は、消滅によって失敗する可能性があります。つまり、勾配が非常に小さくなり、モデルが学習に使用できなくなることを意味します。また、爆発によって、勾配が非常に大きくなり、モデルが更新をオーバーシュートしてモデルが使用できなくなることによって失敗することがあります。これらの問題のバランスをとることは困難です。