
オートエンコーダーとは何ですか?初心者向けガイド
公開: 2024-10-28オートエンコーダーは、特に教師なし機械学習タスクにおいて、深層学習の重要なコンポーネントです。この記事では、オートエンコーダーの機能、そのアーキテクチャ、利用可能なさまざまなタイプについて説明します。また、それらの実際のアプリケーションと、それらを使用する際の利点とトレードオフについても説明します。
目次
- オートエンコーダーとは何ですか?
- オートエンコーダのアーキテクチャ
- オートエンコーダーの種類
- 応用
- 利点
- 短所
オートエンコーダーとは何ですか?
オートエンコーダーは、入力データの効率的な低次元表現を学習するために深層学習で使用されるニューラル ネットワークの一種で、その後、元のデータを再構築するために使用されます。そうすることで、このネットワークはトレーニング中に明示的なラベルを必要とせずにデータの最も重要な特徴を学習し、自己教師あり学習の一部となります。オートエンコーダは、画像のノイズ除去、異常検出、データ圧縮などのタスクに広く適用されており、データを圧縮および再構築する機能が重要です。
オートエンコーダのアーキテクチャ
オートエンコーダは、エンコーダ、ボトルネック (潜在空間またはコードとも呼ばれます)、およびデコーダの 3 つの部分で構成されます。これらのコンポーネントは連携して入力データの主要な特徴をキャプチャし、それらを使用して正確な再構成を生成します。
オートエンコーダーは、重要な特徴を保持した入力の圧縮表現を生成することを目的として、エンコーダーとデコーダーの両方の重みを調整することで出力を最適化します。この最適化により、入力データと出力データの差を表す再構成誤差が最小限に抑えられます。
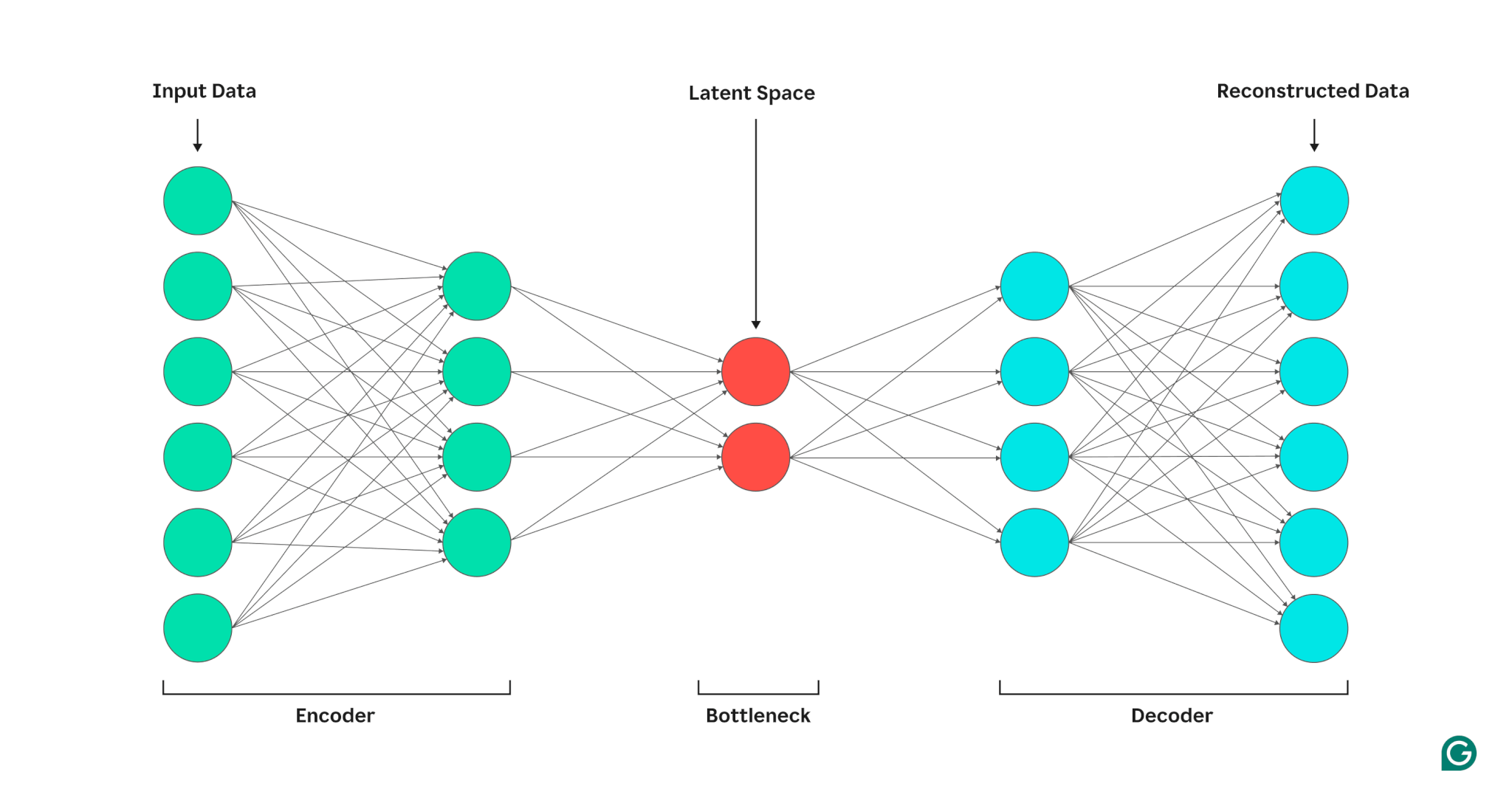
エンコーダ
まず、エンコーダーは入力データをより効率的な表現に圧縮します。エンコーダは通常、各層のノードが少ない複数の層で構成されます。データが各層で処理されると、ノード数が減り、ネットワークはデータの最も重要な特徴を学習して、各層に保存できる表現を作成するようになります。次元削減として知られるこのプロセスは、入力をデータの主要な特性のコンパクトな概要に変換します。エンコーダーの主要なハイパーパラメータには、圧縮の深さと粒度を決定するレイヤーとレイヤーごとのニューロンの数、および各レイヤーでデータ特徴がどのように表現および変換されるかを決定するアクティベーション関数が含まれます。
ボトルネック
潜在スペースまたはコードとも呼ばれるボトルネックは、入力データの圧縮表現が処理中に保存される場所です。ボトルネックのノード数は少ないです。これにより、保存できるデータの量が制限され、圧縮レベルが決まります。ボトルネック内のノードの数は調整可能なハイパーパラメータであり、ユーザーは圧縮とデータ保持の間のトレードオフを制御できます。ボトルネックが小さすぎる場合、重要な詳細が失われるため、オートエンコーダーがデータを誤って再構築する可能性があります。一方、ボトルネックが大きすぎる場合、オートエンコーダーは意味のある一般的な表現を学習する代わりに、単に入力データをコピーする可能性があります。
デコーダ
この最後のステップでは、デコーダは、エンコード プロセス中に学習した主要な特徴を使用して、圧縮形式から元のデータを再作成します。この解凍の品質は、再構成誤差を使用して定量化されます。これは、基本的に、再構成されたデータが入力とどの程度異なるかを示す尺度です。再構成誤差は通常、平均二乗誤差 (MSE) を使用して計算されます。 MSE は元のデータと再構築されたデータ間の二乗差を測定するため、大きな再構築エラーに対してより重くペナルティを与える数学的に簡単な方法を提供します。
オートエンコーダーの種類
特殊なオートエンコーダーにはいくつかの種類があり、他のニューラル ネットワークと同様に、それぞれが特定のアプリケーション向けに最適化されています。
ノイズ除去オートエンコーダー
ノイズ除去オートエンコーダーは、ノイズの多い入力または破損した入力からクリーンなデータを再構築するように設計されています。トレーニング中に入力データにノイズが意図的に追加されるため、モデルはノイズにもかかわらず一貫性を保った特徴を学習できます。次に、出力は元のクリーンな入力と比較されます。このプロセスにより、ビデオ会議の背景ノイズの除去など、画像および音声のノイズ低減タスクにおいてノイズ除去オートエンコーダーが非常に効果的になります。
スパースオートエンコーダ
スパース オートエンコーダーは、常にアクティブなニューロンの数を制限し、標準のオートエンコーダーと比較してネットワークがより効率的なデータ表現を学習することを促します。このスパース性制約は、指定されたしきい値を超えるニューロンの活性化を妨げるペナルティを通じて強制されます。スパース オートエンコーダーは、重要な特徴を維持しながら高次元データを簡素化し、解釈可能な特徴の抽出や複雑なデータセットの視覚化などのタスクに価値をもたらします。

変分オートエンコーダ (VAE)
一般的なオートエンコーダとは異なり、VAE はトレーニング データの特徴を固定点ではなく確率分布にエンコードすることで新しいデータを生成します。この分布からサンプリングすることにより、VAE は入力から元のデータを再構成するのではなく、多様な新しいデータを生成できます。この機能により、VAE は合成データ生成などの生成タスクに役立ちます。たとえば、画像生成では、手書きの数字のデータセットでトレーニングされた VAE は、正確なレプリカではないトレーニング セットに基づいて、現実的に見える新しい数字を作成できます。
収縮型オートエンコーダ
収縮型オートエンコーダーは、再構成誤差の計算中に追加のペナルティ項を導入し、モデルがノイズに強い特徴表現を学習することを促します。このペナルティは、入力データの小さな変動に対して不変な特徴学習を促進することにより、過剰適合を防ぐのに役立ちます。その結果、収縮オートエンコーダは標準オートエンコーダよりもノイズに対して堅牢になります。
畳み込みオートエンコーダー (CAE)
CAE は畳み込み層を利用して、高次元データ内の空間階層とパターンをキャプチャします。畳み込み層の使用により、CAE は画像データの処理に特に適しています。 CAE は、画像圧縮や画像の異常検出などのタスクで一般的に使用されます。
AI におけるオートエンコーダーの応用
オートエンコーダには、次元削減、画像のノイズ除去、異常検出など、いくつかの用途があります。
次元削減
オートエンコーダーは、主要な特徴を維持しながら入力データの次元を削減する効果的なツールです。このプロセスは、高次元データセットの視覚化やデータの圧縮などのタスクに役立ちます。データを単純化することで次元を削減することにより、計算効率も向上し、サイズと複雑さの両方が軽減されます。
異常検知
オートエンコーダーは、ターゲット データセットの主要な特徴を学習することで、新しい入力が提供されたときに正常なデータと異常なデータを区別できます。正常からの逸脱は、再構成エラー率が正常よりも高いことで示されます。そのため、オートエンコーダーは、予知保全やコンピューター ネットワーク セキュリティなどのさまざまなドメインに適用できます。
ノイズ除去
ノイズ除去オートエンコーダーは、ノイズの多いトレーニング入力からデータを再構築することを学習することで、ノイズの多いデータをクリーンアップできます。この機能により、ノイズ除去オートエンコーダーは、ぼやけた写真の品質向上など、画像の最適化などのタスクに役立ちます。ノイズ除去オートエンコーダーは信号処理にも役立ち、ノイズの多い信号を除去してより効率的な処理と分析を行うことができます。
オートエンコーダーの利点
オートエンコーダーには多くの重要な利点があります。これらには、ラベルのないデータから学習する機能、明示的な指示なしで特徴を自動的に学習する機能、および非線形特徴を抽出する機能が含まれます。
ラベルのないデータから学習できる
オートエンコーダーは教師なし機械学習モデルです。つまり、ラベルのないデータから基礎となるデータの特徴を学習できます。この機能は、ラベル付きデータが不足している、または利用できない可能性があるタスクにオートエンコーダーを適用できることを意味します。
自動特徴学習
主成分分析 (PCA) などの標準的な特徴抽出手法は、複雑なデータセットや大規模なデータセットを処理する場合には非現実的であることがよくあります。オートエンコーダーは次元削減などのタスクを念頭に置いて設計されているため、手動で特徴を設計しなくても、データ内の主要な特徴とパターンを自動的に学習できます。
非線形特徴抽出
オートエンコーダーは入力データの非線形関係を処理できるため、モデルがより複雑なデータ表現から主要な特徴をキャプチャできるようになります。この機能は、オートエンコーダーはより複雑なデータセットを処理できるため、線形データのみを処理できるモデルよりも利点があることを意味します。
オートエンコーダーの制限
他の ML モデルと同様、オートエンコーダーには独自の一連の欠点があります。これらには、解釈可能性の欠如、良好なパフォーマンスを得るには大規模なトレーニング データセットの必要性、汎化機能の制限などが含まれます。
解釈可能性の欠如
他の複雑な ML モデルと同様に、オートエンコーダーは解釈可能性の欠如に悩まされています。これは、入力データとモデル出力の関係を理解することが難しいことを意味します。オートエンコーダーでは、特徴が明示的に定義されている従来のモデルとは対照的に、オートエンコーダーが特徴を自動的に学習するため、このような解釈可能性の欠如が発生します。この機械生成された特徴表現は非常に抽象的であることが多く、人間が解釈できる特徴が欠けている傾向があるため、表現内の各コンポーネントが何を意味するかを理解することが困難になります。
大規模なトレーニング データセットが必要
オートエンコーダーは通常、主要なデータ特徴の一般化可能な表現を学習するために大規模なトレーニング データセットを必要とします。トレーニング データセットが小さい場合、オートエンコーダーは過剰適合する傾向があり、新しいデータが提示されたときに一般化が不十分になる可能性があります。一方、大規模なデータセットは、オートエンコーダーが幅広いシナリオに適用できるデータ特徴を学習するために必要な多様性を提供します。
新しいデータに対する限定的な一般化
1 つのデータセットでトレーニングされたオートエンコーダーは一般化機能が限られていることが多く、新しいデータセットに適応できないことを意味します。この制限は、オートエンコーダーが特定のデータセットの顕著な特徴に基づいてデータを再構築することを目的としているために発生します。そのため、オートエンコーダーは通常、トレーニング中にデータからより小さな詳細を破棄し、一般化された特徴表現に適合しないデータを処理できません。