
機械学習: 知っておくべきすべてのこと
公開: 2024-05-23機械学習 (ML) は急速に現代で最も重要なテクノロジーの 1 つになりました。 ChatGPT、Netflix のおすすめ、自動運転車、電子メール スパム フィルターなどの製品の基礎となっています。この普及したテクノロジーを理解するのに役立つように、このガイドでは ML とは何か (およびそうでないもの)、その仕組み、その影響について説明します。
目次
- 機械学習とは何ですか?
- 機械学習の仕組み
- 機械学習の種類
- アプリケーション
- 利点
- 短所
- ML の未来
- 結論
機械学習とは何ですか?
機械学習を理解するには、まず人工知能 (AI) について理解する必要があります。この 2 つは同じ意味で使用されますが、同じではありません。人工知能は目標であると同時に研究分野でもあります。目標は、人間 (または超人) レベルで思考および推論できるコンピューター システムを構築することです。 AI は、そこに到達するためのさまざまな方法でも構成されています。機械学習はこれらの手法の 1 つであり、人工知能のサブセットになります。
機械学習は、AI の追求におけるデータと統計の使用に特に焦点を当てています。目標は、多数の例 (データ) を入力することで学習でき、明示的にプログラムする必要のないインテリジェントなシステムを作成することです。十分なデータと優れた学習アルゴリズムがあれば、コンピューターはデータ内のパターンを認識し、パフォーマンスを向上させます。
対照的に、AI への非 ML アプローチはデータに依存せず、ハードコーディングされたロジックが組み込まれています。たとえば、すべての最適な動きをコーディングするだけで、超人的なパフォーマンスを備えた三目並べ AI ボットを作成できます。三目並べゲームは 255,168 通りあるので、少し時間がかかりますが、それでも可能です)。ただし、チェス AI ボットをハードコーディングすることは不可能です。宇宙には原子よりも多くの可能なチェス ゲームが存在します。このような場合には ML がより効果的に機能します。
現時点で当然の疑問は、例を挙げると、コンピュータは具体的にどのように改善するのか、ということです。
機械学習の仕組み
どの ML システムでも、データセット、ML モデル、トレーニング アルゴリズムの 3 つが必要です。まず、データセットからサンプルを渡します。次に、モデルはその例に対する適切な出力を予測します。モデルが間違っている場合は、トレーニング アルゴリズムを使用して、将来の同様の例に対してモデルが正しい可能性を高めます。データがなくなるか、結果に満足するまで、このプロセスを繰り返します。このプロセスを完了すると、モデルを使用して将来のデータを予測できるようになります。
このプロセスの基本的な例は、以下のような手書きの数字を認識するようにコンピューターに教えることです。
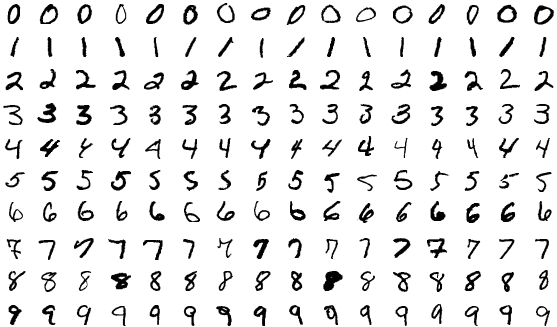
ソース
何千、何十万もの数字の写真を収集します。まだ例が見られていない ML モデルから始めます。画像をモデルにフィードし、画像内にあると思われる数値を予測するようにモデルに依頼します。 0 から 9 までの数値、たとえば 1 を返します。次に、基本的に「この数字は実際には 5 であり、1 ではありません」と伝えます。トレーニング アルゴリズムによってモデルが更新されるため、次回は 5 と応答する可能性が高くなります。利用可能な (ほぼ) すべての画像に対してこのプロセスを繰り返します。理想的には、90% の確率で数字を正しく認識できるパフォーマンスの高いモデルが完成します。このモデルを使用して、人間よりも速く大規模に数百万桁を読み取ることができるようになりました。実際、米国郵便公社は ML モデルを使用して手書き住所の 98% を読み取ります。
このプロセスのほんの一部であっても、詳細を分析するのに何か月、あるいは何年も費やすこともできます (最適化アルゴリズムの異なるバージョンがどれだけ存在するかに注目してください)。
機械学習の種類
実際には、機械学習手法には、教師あり、教師なし、半教師あり、強化という 4 つの異なるタイプがあります。主な違いは、データのラベル付け方法 (つまり、正解の有無) です。
教師あり学習
教師あり学習モデルには、ラベル付きデータ (正解付き) が与えられます。手書きの数字の例はこのカテゴリに分類されます。モデルに「5 が正しい答えです」と伝えることができます。このモデルは、入力と出力の間の明示的な接続を学習することを目的としています。これらのモデルは、個別のラベル (たとえば、ペットの画像から「猫」または「犬」を予測する) または数値 (たとえば、ベッド、バスの数、場所などから予測される家の価格) を出力できます。 。
教師なし学習
教師なし学習モデルには、ラベルのないデータ (正解なし) が与えられます。これらのモデルは、入力データ内のパターンを識別して、データを有意義にグループ化します。たとえば、正解のない猫と犬の画像が多数あるとすると、教師なし ML モデルは画像内の類似点と相違点を調べて、犬と猫の画像をグループ化します。クラスタリング、相関ルール、次元削減は、教師なし ML の中核となる手法です。
半教師あり学習
半教師あり学習は、教師あり学習と教師なし学習の間にある機械学習アプローチです。この方法では、モデルをトレーニングするために、大量のラベルなしデータと少数のラベル付きデータ セットが提供されます。まず、モデルはラベル付きデータでトレーニングされ、次にラベル付きデータとの類似性を比較することによってラベルなしデータにラベルを割り当てます。
強化学習
強化学習には、特定の例とラベルのセットがありません。代わりに、モデルには環境 (たとえば、ゲームが一般的なもの)、報酬関数、および目標が与えられます。モデルは試行錯誤によって目標を達成する方法を学習します。これはアクションを実行し、そのアクションが包括的な目標の達成に役立つかどうかを報酬関数が通知します。次に、モデル自体が更新されて、多かれ少なかれそのアクションが実行されます。モデルはこれを何度も繰り返すことで目標を達成することを学習します。
強化学習モデルの有名な例は、AlphaGo Zero です。このモデルは囲碁に勝つように訓練されており、碁盤の状態のみが与えられています。その後、何百万回もの対局を繰り返し、どの手が有利になるのか、どの手が有利にならないのかを時間をかけて学習しました。 70時間の訓練で囲碁世界チャンピオンを上回る超人レベルの成績を達成した。
自己教師あり学習
実は、最近重要になっている機械学習の 5 番目のタイプである自己教師あり学習があります。自己教師あり学習モデルにはラベルのないデータが与えられますが、このデータからラベルを作成することを学習します。これは、ChatGPT の背後にある GPT モデルの基礎となっています。 GPT トレーニング中、モデルは入力された単語の文字列から次の単語を予測することを目的としています。たとえば、「猫はマットの上に座りました。」という文を考えてみましょう。 GPT には「The」が与えられ、次にどの単語が来るかを予測するように求められます。予測を行います (たとえば、「犬」) が、元の文があるため、正解が「猫」であることがわかります。次に、GPT に「猫」が与えられ、次の単語を予測するように求められます。そうすることで、単語間の統計的パターンなどを学習できます。
機械学習の応用
大量のデータを扱うあらゆる問題や業界で ML を使用できます。多くの業界でこれにより素晴らしい結果が得られており、さらに多くの使用事例が絶えず生まれています。 ML の一般的な使用例をいくつか示します。
書き込み
ML モデルは、Grammarly のような生成 AI ライティング製品を強化します。大量の優れた文章のトレーニングを受けることで、Grammarly はあなたのために下書きを作成し、あなたの好みのトーンとスタイルで、あなたが書き直して推敲するのを助け、あなたと一緒にアイデアをブレインストーミングすることができます。

音声認識
Siri、Alexa、および ChatGPT の音声バージョンはすべて ML モデルに依存しています。これらのモデルは、対応する正しいトランスクリプトとともに、多くの音声サンプルでトレーニングされています。これらの例では、モデルは音声をテキストに変換できます。 ML がなければ、話し方や発音は人それぞれ異なるため、この問題はほとんど解決不可能でしょう。すべての可能性を列挙することは不可能でしょう。
推奨事項
TikTok、Netflix、Instagram、Amazon のフィードの背後には、ML レコメンデーション モデルがあります。これらのモデルは、ユーザーが見たいアイテムやコンテンツを表示するために、好みの多くの例 (例: あの映画よりもこの映画が好き、あの製品よりもこの製品が好きといった人) に基づいてトレーニングされています。時間が経つと、モデルにユーザーの特定の好みを組み込んで、特にユーザーにアピールするフィードを作成することもできます。
不正行為の検出
銀行は ML モデルを使用してクレジット カードの不正行為を検出します。電子メール プロバイダーは、ML モデルを使用してスパム電子メールを検出し、転送します。不正 ML モデルには、不正なデータの多くの例が与えられています。これらのモデルはデータ間のパターンを学習し、将来的に不正行為を特定します。
自動運転車
自動運転車は ML を使用して道路を解釈し、移動します。 ML は、車が歩行者や車線を識別し、他の車の動きを予測し、次の行動 (速度を上げる、車線変更など) を決定するのに役立ちます。自動運転車は、これらの ML 手法を使用して数十億の例でトレーニングすることで熟練度を高めます。
機械学習の利点
ML はうまく行えば変革をもたらす可能性があります。 ML モデルは通常、プロセスをより安く、より良く、あるいはその両方を実現できます。
人件費の効率化
トレーニングされた ML モデルは、わずかなコストで専門家の作業をシミュレートできます。たとえば、不動産業者の専門家は、家の価格について優れた直観力を持っていますが、それには何年もの訓練が必要です。専門の不動産業者 (およびあらゆる種類の専門家) を雇うのも費用がかかります。ただし、何百万もの例でトレーニングされた ML モデルは、専門の不動産業者のパフォーマンスに近づく可能性があります。このようなモデルは数日でトレーニングでき、一度トレーニングすれば使用コストははるかに低くなります。経験の浅い不動産業者でも、これらのモデルを使用して、より短い時間でより多くの作業を行うことができます。
時間効率
ML モデルは人間のように時間に制約されません。 AlphaGo Zero は3 日間のトレーニングで490 万局の囲碁をプレイしました。これには人間が数十年とは言わないまでも、数年かかります。この拡張性により、このモデルはさまざまな碁の手や局面を探索することができ、超人的なパフォーマンスを実現しました。 ML モデルは、専門家が見逃しているパターンを見つけることもできます。 AlphaGo Zero は、通常は人間が指さない手を見つけて使用することもありました。ただし、これは専門家がもはや価値がないという意味ではありません。囲碁の専門家は、AlphaGo のようなモデルを使用して新しい戦略を試すことで、はるかに上達しました。
機械学習のデメリット
もちろん、ML モデルの使用には欠点もあります。つまり、トレーニングには費用がかかり、その結果は簡単に説明できません。
高価なトレーニング
ML トレーニングには費用がかかる場合があります。たとえば、AlphaGo Zero の開発費は 2,500 万ドル、GPT-4 の開発費は 1 億ドル以上です。 ML モデルの開発にかかる主なコストは、データのラベル付け、ハードウェアの費用、従業員の給与です。
優れた教師あり ML モデルには何百万ものラベル付きサンプルが必要で、それぞれのサンプルに人間がラベルを付ける必要があります。すべてのラベルが収集されたら、モデルをトレーニングするために専用のハードウェアが必要になります。グラフィックス プロセッシング ユニット (GPU) とテンソル プロセッシング ユニット (TPU) は ML ハードウェアの標準であり、レンタルまたは購入には高価な場合があり、GPU の購入には数千ドルから数万ドルかかる場合があります。
最後に、優れた ML モデルを開発するには、機械学習の研究者またはエンジニアを雇用する必要があり、そのスキルと専門知識により高額な給与を要求される可能性があります。
意思決定の明確性が限られている
多くの ML モデルでは、なぜそのような結果が得られるのかは不明です。 AlphaGo Zero は、その意思決定の背後にある理由を説明できません。ある動きが特定の状況で機能することはわかっていますが、その理由はわかりません。これは、ML モデルが日常的な状況で使用される場合に重大な影響を与える可能性があります。ヘルスケアで使用される ML モデルは、不正確または偏った結果をもたらす可能性がありますが、結果の背後にある理由が不透明であるため、それがわからない可能性があります。一般に、バイアスは ML モデルにとって大きな懸念事項であり、説明可能性の欠如により問題への対処が困難になります。これらの問題は、特に深層学習モデルに当てはまります。深層学習モデルは、多層のニューラル ネットワークを使用して入力を処理する ML モデルです。彼らは、より複雑なデータや質問を処理することができます。
一方、より単純でより「浅い」ML モデル (デシジョン ツリーや回帰モデルなど) には、同じ欠点はありません。それでも大量のデータが必要ですが、それ以外の場合は低コストでトレーニングできます。また、より説明しやすくなります。欠点は、このようなモデルの実用性が制限される可能性があることです。 GPT のような高度なアプリケーションには、より複雑なモデルが必要です。
機械学習の未来
Transformer ベースの ML モデルは、ここ数年で大流行しています。これは、GPT (GPT の T)、Grammarly、および Claude AI を強化する特定の ML モデル タイプです。 DALL-E や Midjourney などの画像作成製品を強化する拡散ベースの ML モデルも注目を集めています。
この傾向はすぐには変わらないようです。 ML 企業は、モデルのサイズを拡大すること、つまりより優れた機能を備えたより大きなモデルと、モデルをトレーニングするためのより大きなデータセットに焦点を当てています。たとえば、GPT-4 には GPT-3 の 10 倍のモデル パラメーターがありました。ユーザー向けにパーソナライズされたエクスペリエンスを作成するために、製品に生成 AI を使用する業界がさらに増える可能性があります。
ロボット工学も加熱しています。研究者たちは ML を使用して、人間と同じように物体を動かし、使用できるロボットを作成しています。これらのロボットは環境で実験し、強化学習を使用して迅速に適応して目標 (サッカー ボールの蹴り方など) を達成できます。
ただし、ML モデルがより強力で普及するにつれて、社会への潜在的な影響について懸念が生じています。偏見、プライバシー、離職などの問題が激しく議論されており、倫理ガイドラインや責任ある開発慣行の必要性に対する認識が高まっています。
結論
機械学習は AI のサブセットであり、データから学習させてインテリジェントなシステムを作成するという明確な目標を持っています。教師あり学習、教師なし学習、半教師あり学習、および強化学習が (自己教師あり学習とともに) ML の主なタイプです。 ML は、ChatGPT、自動運転車、Netflix のレコメンデーションなど、今日発売される多くの新製品の中核となっています。それは人間のパフォーマンスよりも安くなったり優れたりする可能性がありますが、同時に最初は高価であり、説明や操作が困難になります。 ML は、今後数年間でさらに人気が高まる見込みです。
ML には多くの複雑な点があり、この分野を学び貢献する機会は拡大しています。特に、AI、深層学習、ChatGPT に関する Grammarly のガイドは、この分野の他の重要な部分についてさらに学ぶのに役立ちます。さらに、ML の詳細 (データの収集方法、モデルの実際の様子、「学習」の背後にあるアルゴリズムなど) を理解することは、ML を自分の仕事に効果的に組み込むのに役立ちます。
ML は成長を続けており、ほぼすべての業界に影響を与えることが予想されているため、今が ML の旅を始めるときです。