
機械学習における過学習とは何ですか?
公開: 2024-10-15過学習は、機械学習 (ML) モデルをトレーニングするときに発生する一般的な問題です。これは、トレーニング データを超えて一般化するモデルの能力に悪影響を及ぼし、現実世界のシナリオで不正確な予測につながる可能性があります。この記事では、過剰適合とは何か、それがどのように発生するか、その背後にある一般的な原因、およびそれを検出して防止する効果的な方法について説明します。
目次
- 過学習とは何ですか?
- 過学習が起こる仕組み
- 過学習と過小学習
- 過学習の原因は何ですか?
- 過学習を検出する方法
- 過剰適合を避ける方法
- 過学習の例
過学習とは何ですか?
過剰適合とは、機械学習モデルがトレーニング データ内の基礎となるパターンとノイズを学習し、その特定のデータセットに過度に特化されることです。このようにトレーニング データの詳細に過度に焦点を当てると、モデルがまだ見たことのない新しいデータに適用されるときに、トレーニングに使用されたデータを超えて一般化できないため、パフォーマンスが低下します。
過剰適合はどのようにして起こるのでしょうか?
過学習は、モデルがトレーニング データ内の特定の詳細とノイズから学習しすぎて、一般化に意味のないパターンに過度に敏感になるときに発生します。たとえば、過去の評価に基づいて従業員のパフォーマンスを予測するために構築されたモデルを考えてみましょう。モデルが過剰適合している場合、元マネージャーの独自の評価スタイルや過去のレビュー サイクル中の特定の状況など、一般化できない特定の詳細に焦点を当てすぎている可能性があります。このモデルは、スキル、経験、プロジェクトの成果など、パフォーマンスに寄与するより広範で有意義な要素を学習するのではなく、その知識を新入社員に適用したり、評価基準を進化させたりするのに苦労する可能性があります。これにより、モデルがトレーニング セットとは異なるデータに適用される場合、予測の精度が低下します。
過学習と過小学習
過学習とは対照的に、過小学習は、モデルが単純すぎてデータ内の基礎となるパターンを捉えることができない場合に発生します。その結果、トレーニングや新しいデータのパフォーマンスが低下し、正確な予測ができなくなります。
過小適合と過適合の違いを視覚化するには、人のストレス レベルに基づいて運動パフォーマンスを予測しようとしていると想像してください。データをプロットして、この関係を予測しようとする 3 つのモデルを示すことができます。

1アンダーフィッティング:最初の例では、モデルは直線を使用して予測を行っていますが、実際のデータは曲線に従います。このモデルは単純すぎるため、ストレスレベルと運動パフォーマンスの関係の複雑さを捉えることができません。その結果、トレーニング データであっても、予測はほとんど不正確になります。これは適合不足です。
2最適なフィット: 2 番目の例は、適切なバランスをとったモデルを示しています。データを過度に複雑にすることなく、データの根本的な傾向を捉えます。このモデルは、トレーニング データのすべての小さな変化に適合しようとするのではなく、コア パターンのみを適合しようとするため、新しいデータに対して適切に一般化されます。
3オーバーフィッティング:最後の例では、モデルは非常に複雑な波状曲線を使用してトレーニング データをフィッティングします。この曲線はトレーニング データに対して非常に正確ですが、実際の関係を表さないランダム ノイズや外れ値も捕捉します。このモデルはトレーニング データに合わせて非常に細かく調整されているため、新しいまだ見たことのないデータに対して不適切な予測を行う可能性が高く、過学習になっています。
過学習の一般的な原因
過剰適合とは何か、そしてそれがなぜ起こるのかがわかったので、いくつかの一般的な原因をさらに詳しく調べてみましょう。
- トレーニングデータが不十分です
- 不正確、誤り、または無関係なデータ
- 大きな重量
- オーバートレーニング
- モデルのアーキテクチャが洗練されすぎている
トレーニングデータが不十分です
トレーニング データセットが小さすぎる場合、モデルが現実世界で遭遇するシナリオの一部しか表していない可能性があります。トレーニング中に、モデルがデータによく適合する場合があります。ただし、他のデータでテストすると、重大な不正確さが見つかる可能性があります。データセットが小さいため、モデルが目に見えない状況に一般化する能力が制限され、過剰適合が起こりやすくなります。
不正確、誤り、または無関係なデータ
トレーニング データセットが大きい場合でも、エラーが含まれる可能性があります。これらのエラーは、参加者がアンケートで虚偽の情報を提供したり、センサーの読み取り値が間違っていたりするなど、さまざまな原因から発生する可能性があります。モデルがこれらの不正確さから学習しようとすると、実際の基礎となる関係を反映しないパターンに適応してしまい、過剰適合が発生します。
大きな重量
機械学習モデルでは、重みは、予測を行う際にデータ内の特定の特徴に割り当てられる重要性を表す数値です。重みが不釣り合いに大きくなると、モデルが過剰適合し、データ内のノイズなどの特定の特徴に対して過度に敏感になる可能性があります。これは、モデルが特定の特徴に依存しすぎて、新しいデータに一般化する能力が損なわれるために発生します。
オーバートレーニング
トレーニング中、アルゴリズムはデータをバッチで処理し、各バッチの誤差を計算し、モデルの重みを調整して精度を向上させます。
できるだけ長くトレーニングを続けることが良いでしょうか?あまり!同じデータに対するトレーニングが長時間続くと、モデルが特定のデータ ポイントを記憶し、新しいデータやまだ見たことのないデータに一般化する能力が制限される可能性があります。これが過学習の本質です。このタイプの過学習は、早期停止手法を使用するか、トレーニング中に検証セットでモデルのパフォーマンスを監視することによって軽減できます。これがどのように機能するかについては、この記事の後半で説明します。

モデルのアーキテクチャが複雑すぎる
機械学習モデルのアーキテクチャとは、その層とニューロンがどのように構造化され、それらが情報を処理するためにどのように相互作用するかを指します。
より複雑なアーキテクチャでは、トレーニング データの詳細なパターンをキャプチャできます。ただし、モデルは新しいデータの正確な予測に寄与しないノイズや無関係な詳細をキャプチャすることも学習する可能性があるため、この複雑さにより過学習の可能性が高まります。アーキテクチャを簡素化するか、正則化手法を使用すると、過剰適合のリスクを軽減できます。
過学習を検出する方法
過学習が発生している場合でも、トレーニング中はすべてがうまくいっているように見える場合があるため、過学習の検出は難しい場合があります。損失 (またはエラー) 率 (モデルが間違っている頻度の尺度) は、過学習シナリオであっても減少し続けます。では、過学習が発生したかどうかをどのようにして知ることができるのでしょうか?信頼できるテストが必要です。
効果的な方法の 1 つは、損失と呼ばれる尺度を追跡するチャートである学習曲線を使用することです。損失は、モデルが発生する誤差の大きさを表します。ただし、トレーニング データの損失を追跡するだけではありません。また、検証データと呼ばれる目に見えないデータの損失も測定します。これが、学習曲線に通常、トレーニング損失と検証損失という 2 つの線がある理由です。
トレーニング損失が予想どおり減少し続けているにもかかわらず、検証損失が増加している場合、これは過学習を示唆しています。言い換えれば、モデルはトレーニング データに過度に特殊化されており、新しいまだ見たことのないデータに一般化するのに苦労しています。学習曲線は次のようになります。
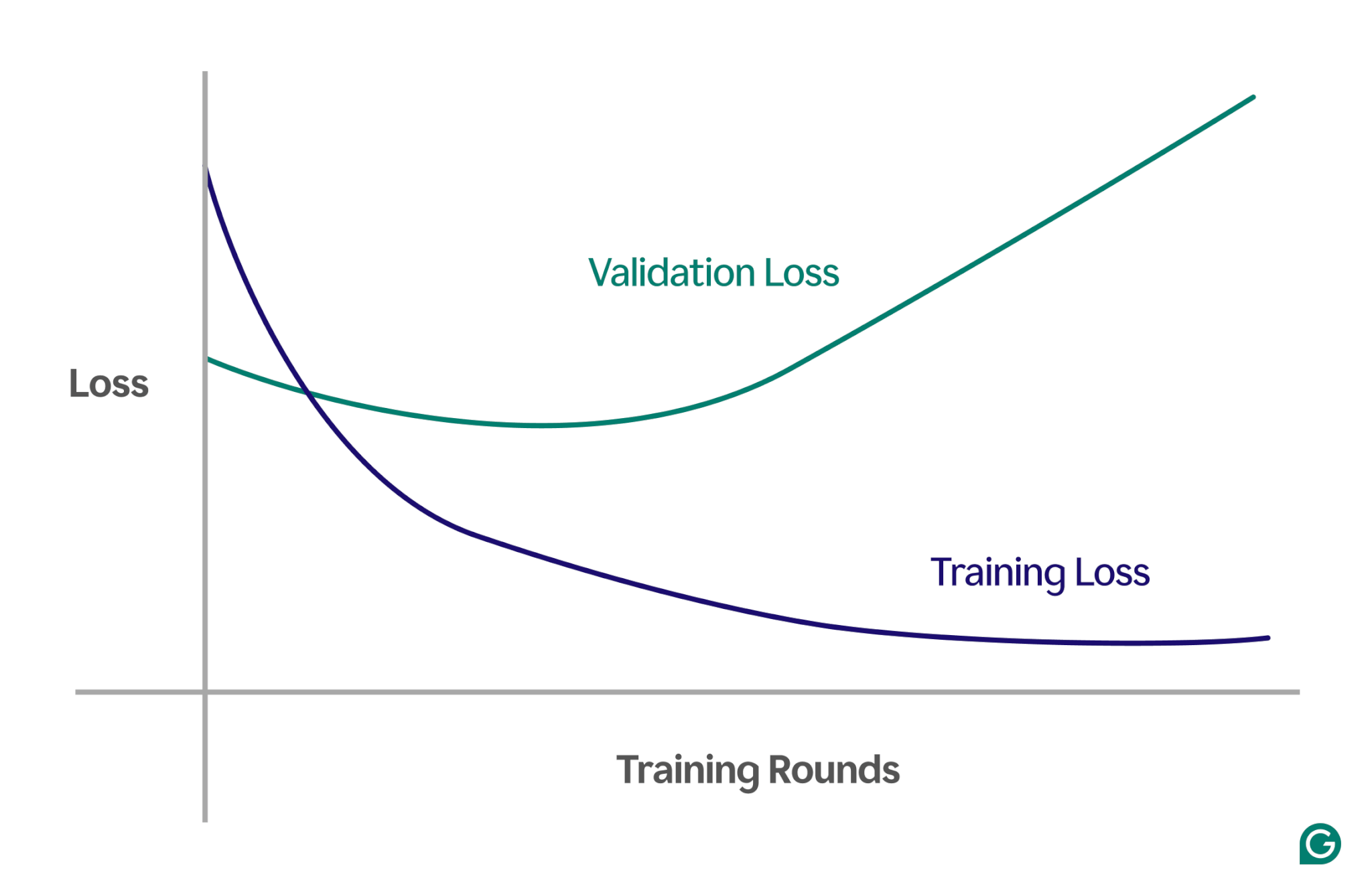
このシナリオでは、モデルはトレーニング中に向上しますが、目に見えないデータではパフォーマンスが低下します。これはおそらく、過剰適合が発生したことを意味します。
過剰適合を避ける方法
オーバーフィッティングは、いくつかの手法を使用して対処できます。最も一般的な方法のいくつかを次に示します。
モデルのサイズを小さくする
ほとんどのモデル アーキテクチャでは、レイヤーの数、レイヤー サイズ、およびハイパーパラメーターと呼ばれるその他のパラメーターを変更することで重みの数を調整できます。モデルの複雑さが過学習を引き起こしている場合は、モデルのサイズを減らすと解決することがあります。層またはニューロンの数を減らしてモデルを簡素化すると、モデルがトレーニング データを記憶する機会が少なくなるため、過剰適合のリスクを下げることができます。
モデルを正規化する
正則化には、重みが大きくならないようにモデルを変更することが含まれます。 1 つのアプローチは、誤差を測定し、重みのサイズを含めるように損失関数を調整することです。
正則化により、トレーニング アルゴリズムは重みの誤差とサイズの両方を最小限に抑え、モデルに明確な利点をもたらさない限り、大きな重みが発生する可能性を減らします。これにより、モデルをより一般化した状態に保つことができ、過剰適合を防ぐことができます。
トレーニング データをさらに追加する
トレーニング データセットのサイズを増やすことも、過剰適合の防止に役立ちます。データが増えると、モデルがデータセット内のノイズや不正確さの影響を受ける可能性が低くなります。モデルをより多様な例にさらすと、個々のデータ ポイントを記憶する傾向が薄れ、代わりにより広範なパターンを学習できるようになります。
次元削減を適用する
場合によっては、データに相関関係のあるフィーチャ (またはディメンション) が含まれる場合があります。これは、複数のフィーチャが何らかの形で関連していることを意味します。機械学習モデルはディメンションを独立したものとして扱うため、特徴が相関している場合、モデルはそれらに重点を置きすぎて過剰適合につながる可能性があります。
主成分分析 (PCA) などの統計手法を使用すると、これらの相関関係を減らすことができます。 PCA は、次元の数を減らし、相関を削除することでデータを単純化し、過剰適合の可能性を低くします。最も関連性の高い特徴に焦点を当てることにより、モデルは新しいデータへの一般化がより適切になります。
過学習の実際的な例
過学習をより深く理解するために、過学習が誤解を招く結果につながる可能性があるさまざまな分野にわたるいくつかの実践的な例を見てみましょう。
画像分類
画像分類器は、画像内のオブジェクト (たとえば、写真に鳥が含まれているか犬が含まれているかなど) を認識するように設計されています。
他の詳細は、これらの写真で検出しようとしているものと相関している可能性があります。たとえば、犬の写真には背景に草が含まれることが多く、鳥の写真には背景に空や梢が含まれることがよくあります。
すべてのトレーニング画像にこれらの一貫した背景の詳細がある場合、機械学習モデルは、動物自体の実際の特徴に焦点を当てるのではなく、動物を認識するために背景に依存し始める可能性があります。その結果、モデルが芝生に止まっている鳥の画像を分類するように求められた場合、背景情報に過剰適合しているため、画像を誤って犬として分類してしまう可能性があります。これは、トレーニング データへの過剰適合のケースです。
財務モデリング
余暇に株取引をしていて、特定のキーワードに対する Google 検索の傾向に基づいて値動きを予測できると考えているとします。数千の単語の Google トレンド データを使用して機械学習モデルを設定します。
非常に多くの単語があるため、一部の単語はまったく偶然に株価との相関を示す可能性があります。単語が株価の適切な予測因子ではないため、モデルはこれらの偶然の相関関係を過剰に適合させ、将来のデータについて不十分な予測を行う可能性があります。
金融アプリケーションのモデルを構築するときは、データ内の関係の理論的基礎を理解することが重要です。特徴を慎重に選択せずに大規模なデータセットをモデルにフィードすると、特にモデルがトレーニング データ内にまったく偶然に存在する偽の相関を識別した場合に、過学習のリスクが高まる可能性があります。
スポーツの迷信
厳密には機械学習とは関係ありませんが、スポーツの迷信は、特に論理的には結果に関係のないデータに結果が結び付けられている場合に、過学習の概念を説明することがあります。
2008 年の UEFA ユーロ サッカー選手権と 2010 年の FIFA ワールド カップでは、ポールという名前のタコがドイツとの試合結果を予測するために使用されたことで有名です。ポールは 2008 年には 6 つの予測のうち 4 つが的中し、2010 年には 7 つすべてが的中しました。
ポールの過去の予測の「トレーニング データ」だけを考慮すると、ポールの選択と一致するモデルは結果を非常によく予測しているように見えます。ただし、タコの選択は試合結果の信頼性が低いため、このモデルは将来の試合にはうまく一般化されません。