
機械学習におけるランダムフォレスト:彼らは何であり、どのように働くか
公開: 2025-02-03ランダムフォレストは、機械学習(ML)における強力で汎用性の高い技術です。このガイドは、ランダムな森林、それらがどのように機能するか、そのアプリケーション、利益、課題を理解するのに役立ちます。
目次
- ランダムフォレストとは何ですか?
- 決定ツリー対ランダムフォレスト:違いは何ですか?
- ランダムな森林がどのように機能するか
- ランダムな森林の実用的な用途
- ランダムフォレストの利点
- ランダムフォレストの短所
ランダムフォレストとは何ですか?
ランダムフォレストは、複数の決定ツリーを使用して予測を行う機械学習アルゴリズムです。これは、分類タスクと回帰タスクの両方に合わせて設計された監視された学習方法です。多くの木の出力を組み合わせることにより、ランダムな森林は精度を向上させ、過剰フィットを減らし、単一の決定ツリーと比較してより安定した予測を提供します。
決定ツリー対ランダムフォレスト:違いは何ですか?
ランダムフォレストは意思決定ツリーの上に構築されていますが、2つのアルゴリズムは構造とアプリケーションが大きく異なります。
決定木
決定ツリーは、ルートノード、決定ノード(内部ノード)、およびリーフノードの3つの主要なコンポーネントで構成されています。フローチャートのように、決定プロセスはルートノードで始まり、条件に基づいて決定ノードを流れ、結果を表す葉のノードで終了します。意思決定ツリーは解釈し、概念化するのは簡単ですが、特に複雑なまたは騒々しいデータセットでは、過剰に適合する傾向があります。
ランダムフォレスト
ランダムフォレストは、予測を改善するために出力を組み合わせた決定ツリーのアンサンブルです。各ツリーは、一意のブートストラップサンプル(元のデータセットのランダムにサンプリングされたサブセットが置換されたサブセット)でトレーニングされ、各ノードでランダムに選択された機能のサブセットを使用して決定分割を評価します。機能バグと呼ばれるこのアプローチは、木々の間に多様性を導入します。回帰の分類または平均の大多数の投票を使用する予測を集約することにより、ランダム森林は、アンサンブルの単一の決定ツリーよりも正確で安定した結果を生み出します。
ランダムな森林がどのように機能するか
ランダムフォレストは、複数の決定ツリーを組み合わせて堅牢で正確な予測モデルを作成することで動作します。
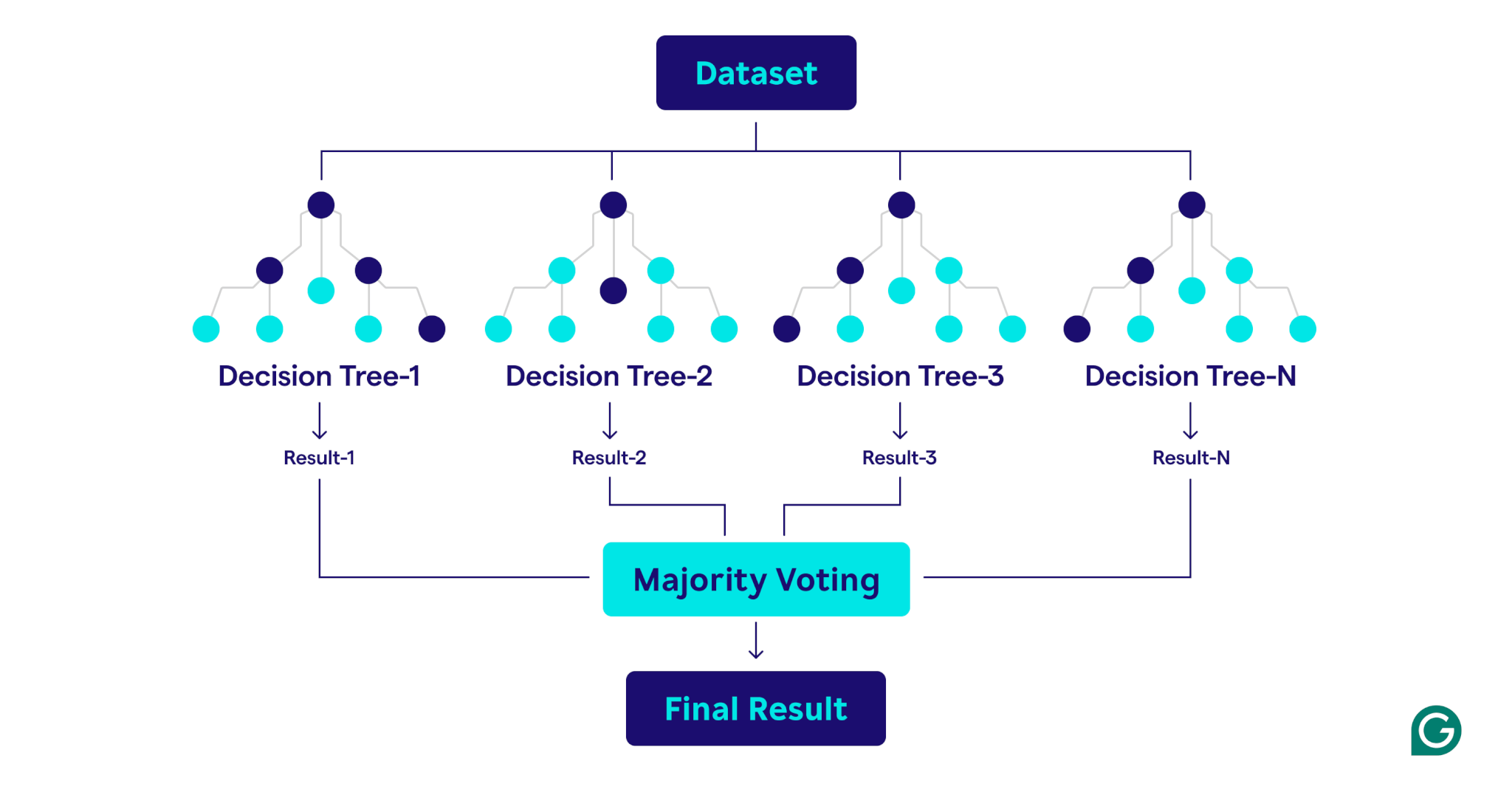
これがプロセスの段階的な説明です。
1.ハイパーパラメーターの設定
最初のステップは、モデルのハイパーパラメーターを定義することです。これらには以下が含まれます:
- 木の数:森のサイズを決定します
- 各ツリーの最大深度:各決定ツリーがどのように深く成長できるかを制御します
- 各分割で考慮される機能の数:分割を作成するときに評価される機能の数を制限します
これらのハイパーパラメーターにより、モデルの複雑さを微調整し、特定のデータセットのパフォーマンスを最適化できます。
2。ブートストラップサンプリング
ハイパーパラメーターが設定されると、トレーニングプロセスはブートストラップサンプリングから始まります。これには次のことが含まれます。
- 元のデータセットからのデータポイントは、各決定ツリーのトレーニングデータセット(ブートストラップサンプル)を作成するためにランダムに選択されます。
- 各ブートストラップサンプルは通常、元のデータセットのサイズの約3分の2で、一部のデータポイントは繰り返され、他のサンプルは除外されます。
- Bootstrapサンプルに含まれていないデータポイントの残りの3分の1は、バッグ外(OOB)データと呼ばれます。
3。決定木の構築
ランダムフォレスト内の各決定ツリーは、一意のプロセスを使用して、対応するブートストラップサンプルで訓練されています。
- 機能バグ:各分割で、機能のランダムなサブセットが選択され、ツリー間の多様性が確保されます。
- ノード分割:サブセットからの最適な機能は、ノードを分割するために使用されます。
- 分類タスクの場合、Giniの不純物(ノード内のクラスラベルの分布に従ってランダムにラベル付けされている場合、ランダムに選択された要素が誤って分類される頻度の測定値の尺度)などの基準を測定します。
- 回帰タスクの場合、分散削減などの手法(ノードの分割の量がターゲット値の分散を減らし、より正確な予測につながる方法を測定する方法)を評価します。
- ツリーは、最大の深さやノードあたりのデータポイントの最小数など、停止条件を満たすまで再帰的に成長します。
4。パフォーマンスの評価
各ツリーが構築されると、OOBデータを使用してモデルのパフォーマンスが推定されます。

- OOBエラー推定により、モデルパフォーマンスの公平な測定値が提供され、個別の検証データセットが必要になります。
- すべての木からの予測を集約することにより、ランダムフォレストは精度が向上し、個々の決定木と比較して過剰適合を減らします。
ランダムな森林の実用的な用途
それらが建設された決定木と同様に、ランダムな森林は、ヘルスケアや金融など、さまざまなセクターの分類と回帰の問題に適用できます。
患者の状態を分類します
ヘルスケアでは、ランダムな森林を使用して、病歴、人口統計、テスト結果などの情報に基づいて患者の状態を分類します。たとえば、患者が糖尿病などの特定の状態を発症する可能性があるかどうかを予測するために、各決定ツリーは患者を関連データに基づいてリスクがあるかどうかを分類し、ランダムフォレストは多数決に基づいて最終決定を下します。このアプローチは、ランダムな森林が、ヘルスケアに見られる複雑で機能が豊富なデータセットに特に適していることを意味します。
ローンのデフォルトの予測
銀行と主要な金融機関は、ランダムな森林を広く使用して、ローンの適格性を判断し、リスクをよりよく理解しています。このモデルは、収入や信用スコアなどの要因を使用してリスクを決定します。リスクは連続的な数値として測定されるため、ランダムフォレストは分類の代わりに回帰を実行します。わずかに異なるブートストラップサンプルで訓練された各決定ツリーは、予測されるリスクスコアを出力します。次に、ランダムフォレストは個々の予測のすべてを平均し、堅牢で全体的なリスクの推定値をもたらします。
顧客の損失の予測
マーケティングでは、ランダムな森林が製品またはサービスの使用を中止する可能性を予測するためにしばしば使用されます。これには、購入頻度や顧客サービスとのやり取りなど、顧客の行動パターンを分析することが含まれます。これらのパターンを識別することにより、ランダムフォレストは、去るリスクのある顧客を分類できます。これらの洞察により、企業は、ロイヤルティプログラムやターゲットプロモーションを提供するなど、顧客を維持するための積極的なデータ駆動型の手順を講じることができます。
不動産価格の予測
ランダムフォレストを使用して、不動産価格を予測できます。これは回帰タスクです。予測を行うために、ランダムフォレストは、地理的位置、面積、およびこの地域の最近の販売などの要因を含む履歴データを使用します。ランダムフォレストの平均化プロセスは、非常に不安定な不動産市場で役立つ個々の決定ツリーのそれよりも信頼性が高く安定した価格予測をもたらします。
ランダムフォレストの利点
ランダムフォレストは、精度、堅牢性、汎用性、機能の重要性を推定する能力など、多くの利点を提供します。
精度と堅牢性
ランダムフォレストは、個々の決定ツリーよりも正確で堅牢です。これは、元のデータセットのさまざまなブートストラップサンプルで訓練された複数の決定ツリーの出力を組み合わせることで達成されます。結果として生じる多様性は、ランダムな森林が個々の決定木よりも過剰適合しやすいことを意味します。このアンサンブルアプローチは、ランダムフォレストが複雑なデータセットであっても、ノイズの多いデータの取り扱いに優れていることを意味します。
汎用性
それらが建設された決定木のように、ランダムな森は非常に用途が広いです。回帰タスクと分類タスクの両方を処理でき、幅広い問題に適用できます。ランダムフォレストは、大きな機能が豊富なデータセットでもうまく機能し、数値データとカテゴリデータの両方を処理できます。
特徴の重要性
ランダムフォレストには、特定の機能の重要性を推定する機能が組み込まれています。トレーニングプロセスの一部として、ランダムフォレストは、特定の機能が削除された場合にモデルの精度がどれだけ変化するかを測定するスコアを出力します。各機能のスコアを平均することにより、ランダムフォレストは機能の重要性の定量化可能な尺度を提供できます。その後、それほど重要ではない機能を削除して、より効率的な木や森林を作成できます。
ランダムフォレストの短所
ランダムフォレストは多くの利点を提供しますが、単一の決定ツリーよりも解釈が困難でトレーニングがよりコストがかかり、他のモデルよりもゆっくりと予測を出力することがあります。
複雑
ランダムな森林と意思決定の木には多くの共通点がありますが、ランダムな森林は解釈して視覚化するのが難しいです。ランダムな森林は数百または数千の決定木を使用しているため、この複雑さが生じます。ランダムフォレストの「ブラックボックス」の性質は、モデルの説明可能性が要件である場合、深刻な欠点です。
計算コスト
数百または数千の意思決定ツリーをトレーニングするには、単一の決定ツリーをトレーニングするよりもはるかに多くの処理能力とメモリが必要です。大規模なデータセットが関与している場合、計算コストがさらに高くなる可能性があります。この大きなリソース要件により、金銭的コストが高くなり、トレーニング時間が長くなる可能性があります。その結果、ランダムフォレストは、計算能力とメモリの両方が不足しているエッジコンピューティングなどのシナリオでは実用的ではない場合があります。ただし、ランダムな森林は並列化される可能性があり、計算コストを削減するのに役立ちます。
予測時間が遅い
ランダムフォレストの予測プロセスには、森林内のすべての木を横断し、その出力を集約することが含まれます。これは、単一のモデルを使用するよりも本質的に遅くなります。このプロセスは、特に深い木を含む大きな森林の場合、ロジスティック回帰やニューラルネットワークなどのより単純なモデルよりも、予測時間が遅くなる可能性があります。高周波取引や自律車両など、時間が重要な場合、この遅延は法外になる可能性があります。