
機械学習におけるアンダーフィッティングとは何ですか?
公開: 2024-10-16アンダーフィッティングは、機械学習 (ML) モデルの開発中に遭遇する一般的な問題です。これは、モデルがトレーニング データから効果的に学習できず、パフォーマンスが標準以下になる場合に発生します。この記事では、アンダーフィッティングとは何か、それがどのように起こるのか、そしてそれを回避する戦略について説明します。
目次
- アンダーフィッティングとは何ですか?
- アンダーフィッティングがどのように発生するか
- 過小適合と過大適合
- アンダーフィッティングの一般的な原因
- アンダーフィッティングを検出する方法
- アンダーフィッティングを防ぐテクニック
- アンダーフィッティングの実例
アンダーフィッティングとは何ですか?
アンダーフィッティングとは、機械学習モデルがトレーニング データの基礎となるパターンを捕捉できず、トレーニング データとテスト データの両方でパフォーマンスの低下につながる場合です。これが発生した場合は、モデルが単純すぎて、データの最も重要な関係を適切に表現できていないことを意味します。その結果、モデルは、トレーニング中に表示されたデータと新しい未表示のデータの両方を含む、すべてのデータに対して正確な予測を行うのに苦労します。
アンダーフィッティングはどのようにして起こるのでしょうか?
アンダーフィッティングは、機械学習アルゴリズムがトレーニング データの最も重要なプロパティをキャプチャできないモデルを生成した場合に発生します。このように失敗するモデルは、単純すぎると考えられます。たとえば、線形回帰を使用して、マーケティング支出、顧客人口統計、季節性に基づいて売上を予測していると想像してください。線形回帰は、これらの要因と売上高の関係が直線の組み合わせとして表現できることを前提としています。
マーケティング支出と売上の実際の関係は曲線になったり、複数の相互作用が含まれたりする場合がありますが(たとえば、売上は最初は急速に増加し、その後頭打ちになります)、線形モデルは直線を描くことで過度に単純化されます。この単純化では重要なニュアンスが失われ、予測と全体的なパフォーマンスが低下します。
この問題は、多くの ML モデルで共通であり、高いバイアス (厳格な仮定) によりモデルが重要なパターンを学習できなくなり、トレーニング データとテスト データの両方でパフォーマンスが低下します。アンダーフィッティングは通常、モデルが単純すぎてデータの実際の複雑さを表現できない場合に発生します。
過小適合と過大適合
ML では、過小適合と過適合は、正確な予測を行うモデルの能力に悪影響を与える可能性がある一般的な問題です。新しいデータに適切に一般化するモデルを構築するには、2 つの違いを理解することが重要です。
- モデルが単純すぎてデータ内の主要なパターンを捕捉できない場合、アンダーフィッティングが発生します。これにより、トレーニング データと新しいデータの両方について予測が不正確になります。
- 過学習は、モデルが過度に複雑になると発生し、真のパターンだけでなくトレーニング データ内のノイズも当てはめます。これにより、モデルはトレーニング セットでは良好にパフォーマンスしますが、新しい未確認のデータではパフォーマンスが低下します。
これらの概念をよりよく説明するために、ストレス レベルに基づいて運動能力を予測するモデルを考えてみましょう。グラフ内の青い点はトレーニング セットからのデータ ポイントを表し、線はそのデータでトレーニングされた後のモデルの予測を示します。 
1アンダーフィッティング:この場合、実際の関係は曲線であるにもかかわらず、モデルは単純な直線を使用してパフォーマンスを予測します。線がデータにうまく適合していないため、モデルが単純すぎて重要なパターンを捉えることができず、結果的に予測が不十分になります。これは過小適合であり、モデルはデータの最も有用な特性を学習できません。
2最適フィット:ここで、モデルはデータの曲線に十分に適切にフィットします。特定のデータポイントやノイズに過度に敏感になることなく、根本的な傾向を捉えます。これは望ましいシナリオであり、モデルが適切に一般化され、同様の新しいデータに対して正確な予測を行うことができます。ただし、大きく異なるデータセットやより複雑なデータセットに直面した場合、一般化は依然として困難な場合があります。
3過学習:過学習シナリオでは、モデルはトレーニング データ内のノイズやランダムな変動を含むほぼすべてのデータ ポイントを厳密に追跡します。モデルはトレーニング セットでは非常に優れたパフォーマンスを発揮しますが、トレーニング データに固有すぎるため、新しいデータを予測する際の効果は低くなります。一般化するのが難しく、まだ見ぬシナリオに適用すると不正確な予測を行う可能性があります。
アンダーフィッティングの一般的な原因
アンダーフィッティングの潜在的な原因は数多くあります。最も一般的なのは次の 4 つです。
- モデルのアーキテクチャが単純すぎます。
- 機能の選択が不十分
- トレーニングデータが不十分です
- トレーニングが足りない
これらを理解するために、もう少し掘り下げてみましょう。
モデルのアーキテクチャが単純すぎる
モデル アーキテクチャは、モデルのトレーニングに使用されるアルゴリズムとモデルの構造の組み合わせを指します。アーキテクチャが単純すぎる場合、トレーニング データの高レベルのプロパティを取得するのが困難になり、不正確な予測につながる可能性があります。
たとえば、モデルが単一の直線を使用して曲線パターンに従うデータをモデル化しようとすると、一貫してアンダーフィットが発生します。これは、直線では曲線データの上位レベルの関係を正確に表現できないため、モデルのアーキテクチャがタスクには不適切になるためです。
機能の選択が不十分
特徴の選択には、トレーニング中に ML モデルに適切な変数を選択することが含まれます。たとえば、ある人が電子商取引 Web サイトで購入ボタンを押すかどうかを予測するときに、その人の誕生年、目の色、年齢、または 3 つすべてを調べるように ML アルゴリズムに依頼できます。
特徴が多すぎる場合、または選択した特徴がターゲット変数と強く相関しない場合、モデルには正確な予測を行うのに十分な関連情報がありません。目の色は変換に無関係である可能性があり、年齢は誕生年とほぼ同じ情報を取得します。

トレーニングデータが不十分です
データ ポイントが少なすぎると、データが問題の最も重要な特性を捉えていないため、モデルがアンダーフィットする可能性があります。これは、データの不足、または特定のデータ ソースが除外されたり過小評価されたりして、モデルが重要なパターンを学習できなくなるサンプリング バイアスが原因で発生する可能性があります。
トレーニングが足りない
ML モデルのトレーニングには、予測と実際の結果の差に基づいて内部パラメーター (重み) を調整することが含まれます。モデルのトレーニング反復が多ければ多いほど、データに合わせて適切に調整できます。モデルのトレーニングの反復回数が少なすぎると、データから学習する機会が十分に得られず、アンダーフィッティングが発生する可能性があります。
アンダーフィッティングを検出する方法
アンダーフィッティングを検出する 1 つの方法は、トレーニングの反復回数に対してモデルのパフォーマンス (通常は損失またはエラー) をプロットする学習曲線を分析することです。学習曲線は、トレーニング データセットと検証データセットの両方でモデルが時間の経過とともにどのように改善するか (または改善に失敗するか) を示します。
損失は、特定のデータセットに対するモデルの誤差の大きさです。トレーニング損失はトレーニング データの場合はこれを測定し、検証データの検証損失はこれを測定します。検証データは、モデルのパフォーマンスをテストするために使用される別のデータセットです。通常、より大きなデータセットをトレーニング データと検証データにランダムに分割することによって生成されます。
アンダーフィッティングの場合、次の主なパターンに気づくでしょう。
- 高いトレーニング損失:モデルのトレーニング損失が高いままで、プロセスの初期段階で平坦になる場合は、モデルがトレーニング データから学習していないことを示唆しています。モデルが単純すぎてデータの複雑さに適応できないため、これは明らかにアンダーフィッティングの兆候です。
- 同様のトレーニング損失と検証損失:トレーニング損失と検証損失の両方が高く、トレーニング プロセス全体を通じて互いに近いままである場合、それはモデルが両方のデータセットでパフォーマンスを下回っていることを意味します。これは、モデルが正確な予測を行うのに十分な情報をデータから取得していないことを示しており、アンダーフィッティングを示しています。
以下は、適合不足のシナリオにおける学習曲線を示すグラフの例です。
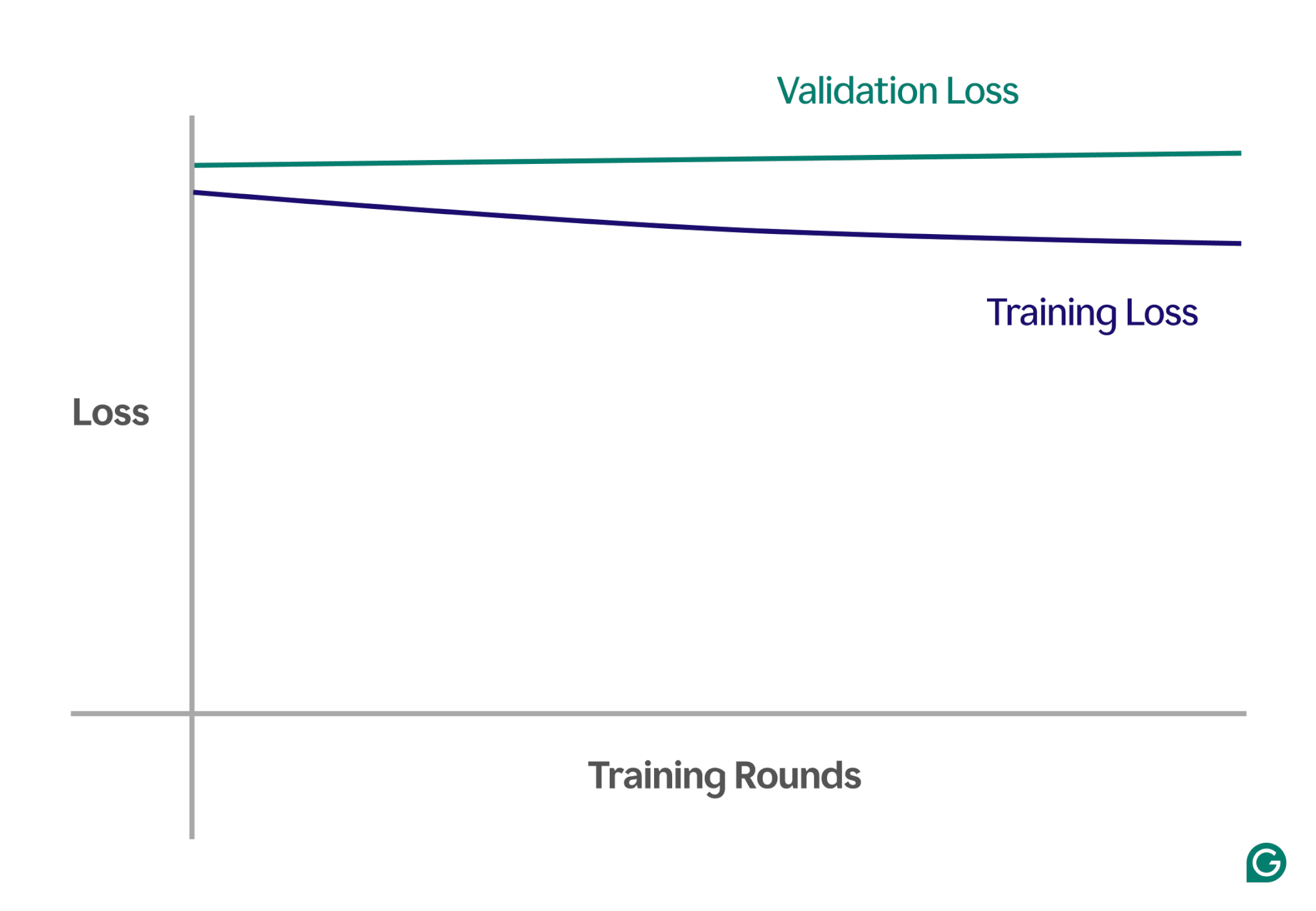
この視覚的表現では、アンダーフィッティングを簡単に見つけることができます。
- 適切に適合したモデルでは、トレーニング損失が大幅に減少する一方、検証損失は同様のパターンに従い、最終的には安定します。
- 過小適合モデルでは、トレーニング損失と検証損失の両方が高く始まり、大きな改善が見られずに高いままになります。
これらの傾向を観察することで、モデルが単純すぎるか、複雑さを増すために調整が必要かどうかをすぐに特定できます。
アンダーフィッティングを防ぐテクニック
アンダーフィッティングが発生した場合、モデルのパフォーマンスを向上させるために使用できる戦略がいくつかあります。
- 追加のトレーニング データ:可能であれば、追加のトレーニング データを取得します。データの品質が高く、当面の問題に関連している場合、データが増えると、モデルにパターンを学習する追加の機会が与えられます。
- 機能選択を拡張する:より関連性の高い機能をモデルに追加します。ターゲット変数と強い関係を持つ特徴を選択し、これまで見逃していた重要なパターンをモデルに捕捉する機会を与えます。
- アーキテクチャ能力の向上:ニューラル ネットワークに基づくモデルでは、重み、レイヤー、またはその他のハイパーパラメーターの数を変更することでアーキテクチャ構造を調整できます。これにより、モデルがより柔軟になり、データ内の高レベルのパターンをより簡単に見つけることができます。
- 別のモデルを選択する:ハイパーパラメーターを調整した後でも、特定のモデルがタスクにあまり適していない場合があります。複数のモデル アルゴリズムをテストすると、より適切なモデルを見つけてパフォーマンスを向上させることができます。
アンダーフィッティングの実例
アンダーフィッティングの影響を説明するために、モデルがデータの複雑さを捉えることができず、不正確な予測につながるさまざまなドメインの実例を見てみましょう。
住宅価格の予測
住宅の価格を正確に予測するには、場所、広さ、家の種類、状態、寝室の数など、多くの要素を考慮する必要があります。
家のサイズと種類のみなど、使用するフィーチャが少なすぎる場合、モデルは重要な情報にアクセスできなくなります。たとえば、モデルは、小さなスタジオがロンドンのメイフェアという不動産価格の高い地域にあることを知らずに、そのスタジオが安価であると仮定する可能性があります。これは、不適切な予測につながります。
これを解決するには、データ サイエンティストは適切な機能を選択する必要があります。これには、関連するすべての特徴を含め、無関係な特徴を除外し、正確なトレーニング データを使用することが含まれます。
音声認識
音声認識技術は日常生活でますます一般的になってきています。たとえば、スマートフォン アシスタント、カスタマー サービス ヘルプライン、障害者向け支援技術はすべて音声認識を使用しています。これらのモデルをトレーニングする際には、音声サンプルからのデータとその正しい解釈が使用されます。
音声を認識するために、モデルはマイクで捉えた音波をデータに変換します。特定の間隔で音声の主な周波数と音量のみを提供することでこれを単純化すると、モデルが処理する必要があるデータの量が削減されます。
ただし、このアプローチでは、スピーチを完全に理解するために必要な重要な情報が取り除かれます。データが単純化しすぎて、トーン、ピッチ、アクセントの変化など、人間の音声の複雑さを捉えることができなくなります。
その結果、モデルは適合が不十分になり、完全な文はおろか、基本的な単語コマンドですら認識するのに苦労します。モデルが十分に複雑であっても、包括的なデータが不足すると、適合不足が生じます。
画像分類
画像分類器は、画像を入力として受け取り、それを説明する単語を出力するように設計されています。画像にボールが含まれているかどうかを検出するモデルを構築しているとします。ボールやその他のオブジェクトのラベル付き画像を使用してモデルをトレーニングします。
畳み込みニューラル ネットワーク (CNN) のようなより適切なモデルの代わりに、単純な 2 層ニューラル ネットワークを誤って使用すると、モデルが困難になります。 2 層ネットワークにより画像が 1 層に平坦化され、重要な空間情報が失われます。さらに、レイヤーが 2 つしかないため、モデルには複雑な特徴を識別する能力がありません。
これは、トレーニング データであってもモデルが正確な予測を行うことができないため、アンダーフィッティングにつながります。 CNN は、画像の空間構造を保持し、初期のレイヤーではエッジや形状などの重要な特徴を、後のレイヤーではより複雑なオブジェクトを検出するように自動的に学習するフィルターを備えた畳み込みレイヤーを使用することで、この問題を解決します。