
머신 러닝에서의 F1 점수 : 효과적으로 계산, 적용 및 사용 방법
게시 됨: 2025-02-10F1 점수는 이진 또는 멀티 클래스 분류를 수행하도록 설계된 머신 러닝 (ML) 모델을 평가하기위한 강력한 메트릭입니다. 이 기사에서는 F1 점수가 무엇인지, 중요한 이유, 계산 방법, 응용 프로그램, 혜택 및 제한 사항을 설명합니다.
목차
- F1 점수는 무엇입니까?
- F1 점수를 계산하는 방법
- F1 점수 대 정확도
- F1 점수의 응용 프로그램
- F1 점수의 이점
- F1 점수의 한계
F1 점수는 무엇입니까?
ML 실무자들은 분류 모델을 구축 할 때 일반적인 도전에 직면합니다. 오 탐지를 피하면서 모든 사례를 잡도록 모델을 훈련시킵니다. 이는 금융 사기 탐지 및 의료 진단과 같은 중요한 응용 프로그램에서 특히 중요합니다. 허위 경보와 중요한 분류가 심각한 결과를 초래합니다. 사기 거래와 같은 범주가 다른 범주보다 훨씬 드물어있는 불균형 데이터 세트를 처리 할 때 올바른 잔액을 달성하는 것이 특히 중요합니다 (합법적 인 거래).
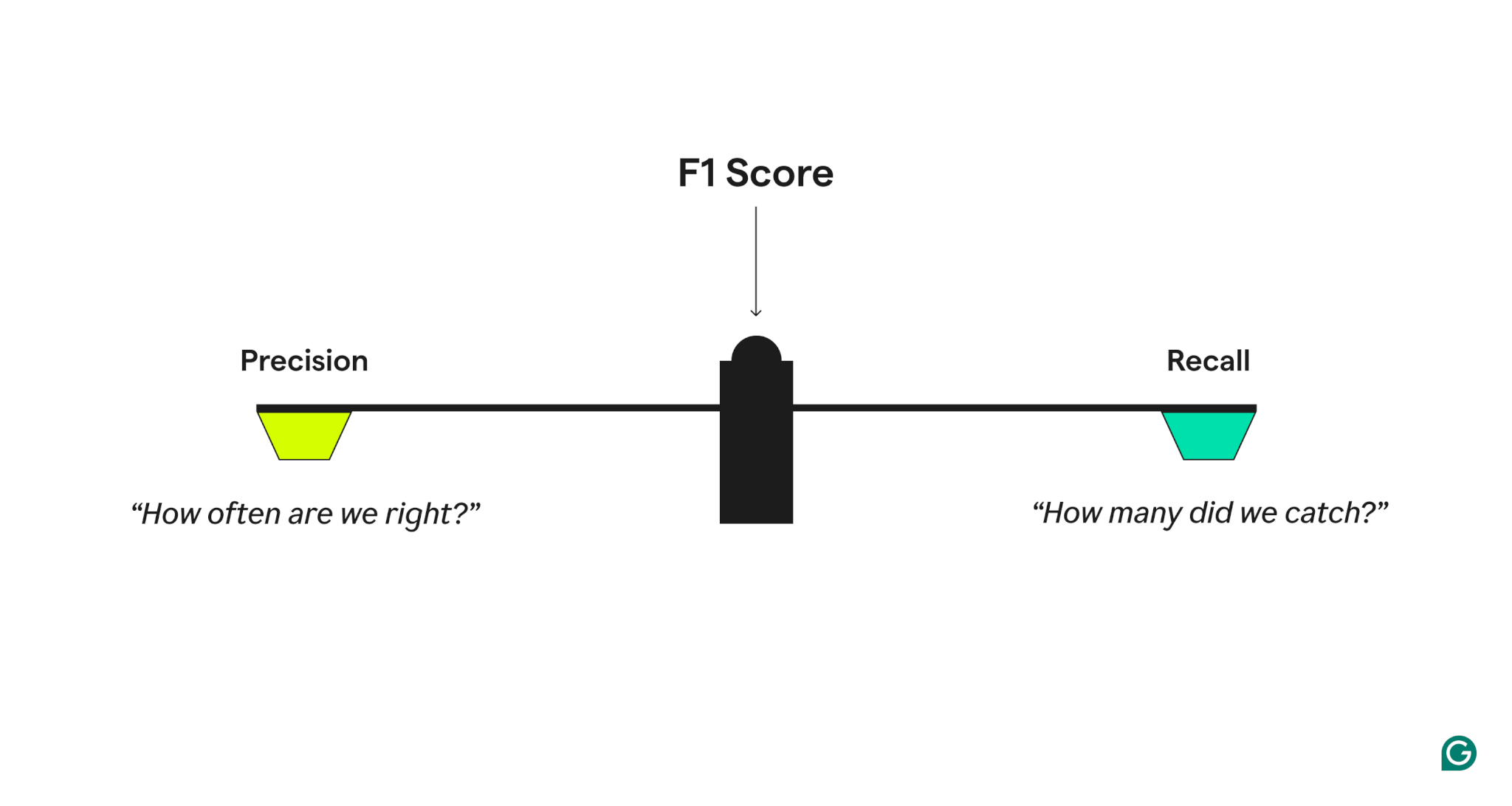
정밀도와 리콜
모델 성능 품질을 측정하기 위해 F1 점수는 두 가지 관련 메트릭을 결합합니다.
- "모델이 긍정적 인 사례를 예측할 때 얼마나 자주 맞습니까?"
- “실제 긍정적 인 경우 중에서 모델은 얼마나 많은 사람들이 올바르게 식별 했습니까?”
정밀도가 높지만 리콜이 낮은 모델은 지나치게 조심스럽고 많은 진정한 긍정적 인 모습을 누락하는 반면, 리콜이 많지만 정밀도가 낮은 사람은 지나치게 공격적이며 많은 오 탐지를 생성합니다. F1 점수는 고조파 정밀도와 리콜의 고조파 평균을 취함으로써 균형을 맞 춥니 다. 이는 더 낮은 값에 더 많은 가중치를 부여하고 모델이 단지 하나의 우수성보다는 두 가지 메트릭에서 잘 수행되도록합니다.
정밀도 및 리콜 예
정밀도와 리콜을 더 잘 이해하려면 스팸 탐지 시스템을 고려하십시오. 시스템이 스팸으로 이메일을 올바르게 표시하는 비율이 높으면 정밀도가 높음을 의미합니다. 예를 들어, 시스템이 100 개의 이메일을 스팸으로 표시하고 90 개가 실제로 스팸 인 경우 정밀도는 90%입니다. 반면에 높은 리콜은 시스템이 대부분의 실제 스팸 이메일을 잡는 것을 의미합니다. 예를 들어, 실제 스팸 이메일이 200 개이고 시스템이 90 개를 잡으면 리콜은 45%입니다.
F1 점수의 변형
특정 요구가있는 멀티 클래스 분류 시스템 또는 시나리오에서 F1 점수는 중요한 요소에 따라 다른 방식으로 계산할 수 있습니다.
- MACRO-F1 :각 클래스에 대해 F1 점수를 별도로 계산하고 평균을 차지합니다.
- Micro-F1 :모든 예측에 대한 리콜과 정밀도를 계산합니다
- 가중 -F1: Macro-F1과 유사하지만 클래스는 빈도에 따라 가중치가 가중됩니다.
F1 점수를 넘어서 : F-Score 제품군
F1 점수는 F- 스코어 (F-Scores)라고 불리는 더 큰 메트릭 제품군의 일부입니다. 이 점수는 정밀도를 가중화하고 회상하는 다양한 방법을 제공합니다.
- F2 :리콜에 중점을 둔 장소는 거짓 부정적인 비용이 드는 경우 유용합니다.
- F0.5 :정밀도에 중점을 두는 곳은 오 탐지가 비용이 많이 드는 경우 유용합니다.
F1 점수를 계산하는 방법
F1 점수는 수학적으로 정밀도 및 리콜의 고조파 평균으로 정의됩니다. 이것은 복잡하게 들릴 수 있지만, 명확한 단계로 나뉘어지면 계산 프로세스가 간단합니다.
F1 점수의 공식 :

F1을 계산하기위한 단계로 뛰어 들기 전에 분류 결과를 구성하는 데 사용되는혼란 매트릭스의 주요 구성 요소를 이해하는 것이 중요합니다.
- True Ponitives (TP) :긍정적으로 올바르게 식별 된 사례 수
- False Positives (FP) :긍정적으로 잘못 식별 된 사례 수
- False Negatives (FN) :누락 된 사례 수 (식별되지 않은 실제 긍정적)
일반적인 프로세스에는 모델 훈련, 예측 테스트 및 구성 결과, 정밀도 및 리콜 계산 및 F1 점수 계산이 포함됩니다.
1 단계 : 분류 모델을 훈련시킵니다
먼저, 이진 또는 멀티 클래스 분류를 만들기 위해 모델을 훈련시켜야합니다. 이는 모델이 사례를 두 범주 중 하나에 속하는 것으로 분류 할 수 있어야 함을 의미합니다. 예로는 "스팸/스팸이 아님"및 "사기/사기가 아님"이 있습니다.
2 단계 : 테스트 예측 및 결과 구성
그런 다음 모델을 사용하여 교육의 일부로 사용되지 않은 별도의 데이터 세트에서 분류를 수행하십시오. 결과를 혼동 매트릭스로 구성하십시오. 이 매트릭스는 다음을 보여줍니다.
- TP : 실제로 얼마나 많은 예측이 정확했는지
- FP : 얼마나 긍정적 인 예측이 잘못 되었습니까?
- FN : 얼마나 많은 긍정적 인 사례가 놓쳤습니까?
Confusion Matrix는 모델의 수행 방식에 대한 개요를 제공합니다.
3 단계 : 정밀도를 계산합니다
혼란 매트릭스를 사용하여 정밀도는이 공식으로 계산됩니다.

예를 들어, 스팸 탐지 모델이 90 개의 스팸 이메일 (TP)을 올바르게 식별했지만 10 개의 NONSPAM 전자 메일 (FP)을 잘못 표시 한 경우 정밀도는 0.90입니다.

4 단계 : 리콜 계산
다음으로 공식을 사용하여 리콜을 계산하십시오.

스팸 감지 예제를 사용하여 총 스팸 전자 메일이 200 개가 있고 모델이 110 (FN)이 누락 된 반면 90 개 (TP)를 잡았을 때 리콜은 0.45입니다.


5 단계 : F1 점수를 계산합니다
정밀도 및 리콜 값이 손에 든 경우 F1 점수를 계산할 수 있습니다.
F1 점수는 0에서 1까지입니다. 점수를 해석 할 때 이러한 일반 벤치 마크를 고려하십시오.
- 0.9 이상 :모델이 훌륭하게 수행되고 있지만 과적으로 확인해야합니다.
- 0.7 ~ 0.9 :대부분의 응용 분야에서 우수한 성능
- 0.5 ~ 0.7 :성능은 괜찮지 만 모델은 개선을 사용할 수 있습니다.
- 0.5 이하 :모델은 성능이 좋지 않으며 심각한 개선이 필요합니다.
정밀 및 리콜에 대한 스팸 탐지 예제 계산을 사용하면 F1 점수는 0.60 또는 60%입니다.

이 경우 F1 점수는 정밀도가 높음에도 불구하고 리콜이 낮은 것이 전반적인 성능에 영향을 미친다는 것을 나타냅니다. 이것은 더 많은 스팸 이메일을 잡을 수있는 개선의 여지가 있음을 시사합니다.
F1 점수 대 정확도
F1과정확도는모델 성능을 정량화하지만 F1 점수는보다 미묘한 측정을 제공합니다. 정확도는 단순히 올바른 예측의 백분율을 계산합니다. 그러나 데이터 세트의 한 카테고리 인스턴스 수가 다른 범주보다 크게 능가 할 때 모델 성능을 측정하기 위해 정확도에 의존하는 것만으로도 문제가 될 수 있습니다. 이 문제는정확도 역설이라고합니다.
이 문제를 이해하려면 스팸 감지 시스템의 예를 고려하십시오. 전자 메일 시스템이 매일 1,000 개의 이메일을 수신하지만 그 중 10 개만 실제로 스팸이라고 가정 해 봅시다. 스팸 감지가 단순히 모든 이메일을 스팸이 아닌 것으로 분류하면 99% 정확도를 달성합니다. 스팸 감지와 관련하여 모델이 실제로 쓸모가 없지만 1,000 명 중 990 개의 예측이 정확했기 때문입니다. 분명히 정확도는 모델의 품질에 대한 정확한 그림을 제공하지 않습니다.
F1 점수는 정밀도 및 리콜 측정을 결합 하여이 문제를 피합니다. 따라서 다음 경우 정확도 대신 F1을 사용해야합니다.
- 데이터 세트는 불균형입니다.이것은 모호한 의학적 상태의 진단이나 스팸 탐지와 같은 분야에서 일반적입니다.
- FN과 FP는 둘 다 중요합니다.예를 들어, 의료 선별 검사는 잘못된 경보를 높이 지 않은 실제 문제의 균형을 잡기 위해 노력합니다.
- 이 모델은 너무 공격적이고 조심스러워하는 것 사이의 균형을 잡아야합니다.예를 들어, 스팸 필터링에서 지나치게 신중한 필터는 너무 많은 스팸 (낮은 리콜)을 통과 할 수 있지만 실수 (높은 정밀도)는 거의 없습니다. 반면에 지나치게 공격적인 필터는 모든 스팸 (높은 리콜)을 잡더라도 실제 이메일 (낮은 정밀)을 차단할 수 있습니다.
F1 점수의 응용 프로그램
F1 점수는 균형 잡힌 분류가 중요한 다양한 산업 분야에서 광범위한 응용 프로그램을 가지고 있습니다. 이러한 응용 프로그램에는 재무 사기 탐지, 의료 진단 및 내용 조정이 포함됩니다.
금융 사기 탐지
금융 사기를 감지하도록 설계된 모델은 F1 점수를 사용하여 측정에 적합한 시스템의 범주입니다. 금융 회사는 종종 매일 수백만 또는 수십억의 거래를 처리하며 실제 사기 사례는 비교적 드물다. 이러한 이유로, 사기 탐지 시스템은 가능한 많은 사기 거래를 포착하고 동시에 허위 경보의 수를 최소화하고 고객에게 불편을 겪어야합니다. F1 점수를 측정하면 금융 기관이 시스템 시스템의 쌍둥이 기둥과 사기 예방의 균형과 좋은 고객 경험의 균형을 결정하는 데 도움이 될 수 있습니다.
의학적 진단
의료 진단 및 테스트에서 FN과 FP는 모두 심각한 결과를 초래합니다. 희귀 한 형태의 암을 감지하도록 설계된 모델의 예를 고려하십시오. 건강한 환자를 잘못 진단하면 불필요한 스트레스와 치료로 이어질 수 있지만 실제 암 사례를 놓치면 환자에게 심각한 결과가 발생합니다. 다시 말해,이 모델은 높은 정밀도와 높은 리콜을 가져야하며, 이는 F1 점수가 측정 할 수있는 것입니다.
내용 조정
온라인 포럼, 소셜 미디어 플랫폼 및 온라인 마켓 플레이스에서 콘텐츠를 조정하는 것은 일반적인 과제입니다. 과도한 수정없이 플랫폼 안전을 달성하려면 이러한 시스템의 정밀도와 리콜의 균형을 유지해야합니다. F1 점수는 플랫폼이 시스템 이이 두 가지 요소의 균형을 얼마나 잘 균형을 이루는지를 결정하는 데 도움이 될 수 있습니다.
F1 점수의 이점
F1 점수는 분류 모델 성능을 평가할 때 일반적으로 정확도보다 모델 성능에 대한 미묘한보기를 제공하는 것 외에도 정확도보다 정확성보다 미묘한 모습을 제공합니다. 이러한 이점에는 더 빠른 모델 교육 및 최적화, 교육 비용 감소 및 초과 적합성을 조기에 포함시키는 것이 포함됩니다.
더 빠른 모델 교육 및 최적화
F1 점수는 최적화를 안내하는 데 사용할 수있는 명확한 기준 메트릭을 제공하여 모델 교육 속도를 높이는 데 도움이 될 수 있습니다. ML 실무자들은 일반적으로 복잡한 트레이드 오프를 포함하는 리콜과 정밀도를 따로 조정하는 대신 F1 점수를 높이는 데 집중할 수 있습니다. 이 간소화 된 접근 방식을 사용하면 최적의 모델 매개 변수를 빠르게 식별 할 수 있습니다.
교육 비용 감소
F1 점수는 ML 실무자가 미묘한 단일 모델 성능 측정을 제공하여 모델이 배포 준비가 된시기에 대한 정보에 근거한 결정을 내리는 데 도움이 될 수 있습니다. 이 정보를 통해 실무자는 불필요한 교육주기, 계산 자원에 대한 투자, 추가 교육 데이터를 획득하거나 만들어야 할 수 있습니다. 전반적으로, 이는 훈련 분류 모델시 실질적인 비용 절감으로 이어질 수 있습니다.
일찍 과적으로 잡는 것
F1 점수는 정밀성과 리콜을 모두 고려하기 때문에 ML 실무자가 모델이 교육 데이터에 너무 전문화되는시기를 식별하는 데 도움이 될 수 있습니다. 오버 피팅이라고하는이 문제는 분류 모델에서 일반적인 문제입니다. F1 점수는 실무자에게 모델이 실제 데이터를 일반화 할 수없는 지점에 도달하기 전에 훈련을 조정해야한다는 조기 경고를 제공합니다.
F1 점수의 한계
많은 이점에도 불구하고 F1 점수는 실무자들이 고려해야 할 몇 가지 중요한 한계가 있습니다. 이러한 한계에는 실제 네거티브에 대한 민감도가 부족하고 일부 데이터 세트에 적합하지 않으며 멀티 클래스 문제에 대해 해석하기가 더 어려워집니다.
진정한 네거티브에 대한 민감도 부족
F1 점수는 진정한 네거티브를 설명하지 않으므로이를 측정하는 것이 중요한 응용 분야에 적합하지 않음을 의미합니다. 예를 들어, 안전한 운전 조건을 식별하도록 설계된 시스템을 고려하십시오. 이 경우, 조건이 진정으로 안전 할 때 (진정한 부정)시기를 정확하게 식별하는 것은 위험한 조건을 식별하는 것만 큼 중요합니다. FN을 추적하지 않기 때문에 F1 점수는 전체 모델 성능의 이러한 측면을 정확하게 캡처하지 않습니다.
일부 데이터 세트에 적합하지 않습니다
FP 및 FN의 영향이 상당히 다른 데이터 세트에 F1 점수가 적합하지 않을 수 있습니다. 암 선별 모델의 예를 고려하십시오. 이러한 상황에서 긍정적 인 사례 (FN)가 생명을 위협 할 수있는 반면, 긍정적 인 사례 (FP)를 잘못 찾는 것은 추가 테스트만으로 이어집니다. 따라서이 비용을 설명하기 위해 가중치를 줄 수있는 메트릭을 사용하는 것이 F1 점수보다 더 나은 선택입니다.
멀티 클래스 문제에 대해 해석하기가 더 어렵습니다
Micro-F1 및 Macro-F1 점수와 같은 변동은 F1 점수가 멀티 클래스 분류 시스템을 평가하는 데 사용될 수 있음을 의미하지만, 이러한 집계 된 메트릭을 해석하는 것은 종종 이진 F1 점수보다 더 복잡합니다. 예를 들어, Micro-F1 점수는 덜 빈번한 클래스를 분류 할 때 성능 저하가 발생하지 않을 수 있으며, Macro-F1 점수는 드문 클래스를 과체중으로 과체적으로 할 수 있습니다. 이를 감안할 때, 비즈니스는 멀티 클래스 분류 모델에 대한 올바른 F1 변형을 선택할 때 클래스의 동등한 처리 또는 전체 인스턴스 수준 성능이 더 중요한지 고려해야합니다.