
Podstawy generatywnej sieci przeciwstawnej: co musisz wiedzieć
Opublikowany: 2024-10-08Generacyjne sieci kontradyktoryjne (GAN) to potężne narzędzie sztucznej inteligencji (AI) z licznymi zastosowaniami w uczeniu maszynowym (ML). W tym przewodniku omówiono sieci GAN, sposób ich działania, zastosowania oraz zalety i wady.
Spis treści
- Co to jest GAN?
- Sieci GAN kontra CNN
- Jak działają sieci GAN
- Rodzaje sieci GAN
- Zastosowania GAN
- Zalety sieci GAN
- Wady sieci GAN
Co to jest generatywna sieć kontradyktoryjna?
Generatywna sieć kontradyktoryjna (GAN) to rodzaj modelu głębokiego uczenia się zwykle stosowanego w uczeniu maszynowym bez nadzoru, ale można go również dostosować do uczenia się częściowo nadzorowanego i nadzorowanego. Sieci GAN służą do generowania wysokiej jakości danych podobnych do zbioru danych szkoleniowych. Jako podzbiór generatywnej sztucznej inteligencji sieci GAN składają się z dwóch podmodeli: generatora i dyskryminatora.
1 Generator:Generator tworzy dane syntetyczne.
2 Dyskryminator:Dyskryminator ocenia wyjście generatora, rozróżniając rzeczywiste dane ze zbioru uczącego i dane syntetyczne utworzone przez generator.
Obydwa modele rywalizują ze sobą: generator próbuje oszukać dyskryminator, aby zaklasyfikował wygenerowane dane jako rzeczywiste, podczas gdy dyskryminator stale doskonali swoją zdolność do wykrywania danych syntetycznych. Ten proces kontradyktoryjny trwa do chwili, gdy dyskryminator nie będzie już w stanie odróżnić danych rzeczywistych od wygenerowanych. W tym momencie sieć GAN jest w stanie generować realistyczne obrazy, filmy i inne typy danych.
Sieci GAN kontra CNN
Sieci GAN i splotowe sieci neuronowe (CNN) to potężne typy sieci neuronowych wykorzystywanych w głębokim uczeniu się, ale różnią się znacznie pod względem przypadków użycia i architektury.
Przypadki użycia
- Sieci GAN:specjalizują się w generowaniu realistycznych danych syntetycznych na podstawie danych szkoleniowych. Dzięki temu sieci GAN dobrze nadają się do zadań takich jak generowanie obrazów, przesyłanie stylów obrazów i powiększanie danych. Sieci GAN nie podlegają nadzorowi, co oznacza, że można je zastosować w scenariuszach, w których oznakowane dane są rzadkie lub niedostępne.
- Sieci CNN:używane głównie do zadań klasyfikacji danych strukturalnych, takich jak analiza nastrojów, kategoryzacja tematów i tłumaczenie językowe. Ze względu na swoje możliwości klasyfikacyjne sieci CNN służą również jako dobre dyskryminatory w sieciach GAN. Ponieważ jednak sieci CNN wymagają ustrukturyzowanych danych szkoleniowych z komentarzami ludzkimi, ograniczają się do scenariuszy uczenia się pod nadzorem.
Architektura
- Sieci GAN:składają się z dwóch modeli — dyskryminatora i generatora — które angażują się w proces konkurencyjny. Generator tworzy obrazy, podczas gdy dyskryminator je ocenia, zmuszając generator do tworzenia coraz bardziej realistycznych obrazów w miarę upływu czasu.
- Sieci CNN:wykorzystuj warstwy operacji splotowych i łączenia w celu wyodrębniania i analizowania cech z obrazów. Ta architektura oparta na jednym modelu koncentruje się na rozpoznawaniu wzorców i struktur w danych.
Ogólnie rzecz biorąc, podczas gdy CNN skupiają się na analizie istniejących danych strukturalnych, sieci GAN są nastawione na tworzenie nowych, realistycznych danych.
Jak działają sieci GAN
Na wysokim poziomie sieć GAN działa poprzez zestawienie ze sobą dwóch sieci neuronowych – generatora i dyskryminatora. Sieci GAN nie wymagają szczególnego rodzaju architektury sieci neuronowej dla żadnego ze swoich dwóch komponentów, o ile wybrane architektury wzajemnie się uzupełniają. Na przykład, jeśli CNN jest używany jako dyskryminator do generowania obrazu, wówczas generatorem może być dekonwolucyjna sieć neuronowa (deCNN), która wykonuje proces CNN w odwrotnej kolejności. Każdy komponent ma inny cel:
- Generator:Aby wygenerować dane o tak wysokiej jakości, że dyskryminator da się oszukać i zaklasyfikuje je jako rzeczywiste.
- Dyskryminator:Aby dokładnie sklasyfikować daną próbkę danych jako prawdziwą (ze zbioru danych szkoleniowych) lub fałszywą (wygenerowaną przez generator).
Konkurs ten jest realizacją gry o sumie zerowej, w której nagroda przyznana jednemu modelowi jest jednocześnie karą dla drugiego modelu. W przypadku generatora pomyślne oszukanie dyskryminatora skutkuje aktualizacją modelu, która zwiększa jego zdolność do generowania realistycznych danych. I odwrotnie, gdy dyskryminator poprawnie zidentyfikuje fałszywe dane, otrzyma aktualizację, która poprawia jego możliwości wykrywania. Matematycznie dyskryminator ma na celu zminimalizowanie błędu klasyfikacji, podczas gdy generator stara się go maksymalizować.
Proces szkolenia GAN
Uczenie sieci GAN obejmuje naprzemienne działanie generatora i dyskryminatora w wielu epokach. Epoki to kompletne przebiegi szkoleniowe obejmujące cały zbiór danych. Proces ten trwa do momentu, gdy generator wygeneruje syntetyczne dane, które oszukują dyskryminator w około 50% przypadków. Chociaż oba modele wykorzystują podobne algorytmy do oceny i doskonalenia wydajności, ich aktualizacje odbywają się niezależnie. Aktualizacje te są przeprowadzane przy użyciu metody zwanej propagacją wsteczną, która mierzy błąd każdego modelu i dostosowuje parametry w celu poprawy wydajności. Następnie algorytm optymalizacji dostosowuje parametry każdego modelu niezależnie.
Oto wizualna reprezentacja architektury GAN, ilustrująca konkurencję pomiędzy generatorem a dyskryminatorem:
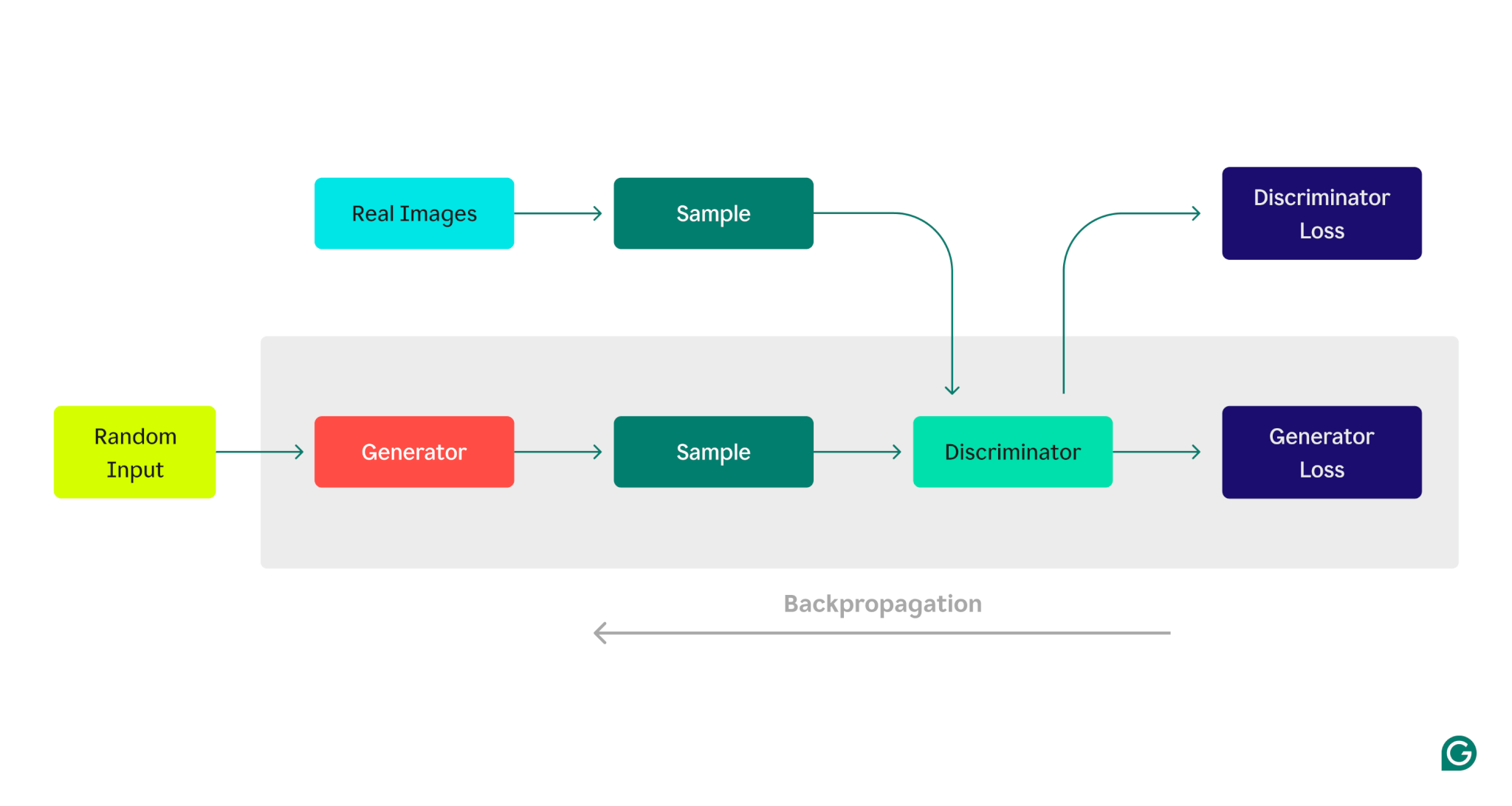
Faza szkolenia generatora:
1 Generator tworzy próbki danych, zazwyczaj zaczynając od losowego szumu jako danych wejściowych.
2 Dyskryminator klasyfikuje te próbki jako prawdziwe (ze zbioru uczącego) lub fałszywe (wygenerowane przez generator).
3 Na podstawie odpowiedzi dyskryminatora parametry generatora są aktualizowane przy użyciu propagacji wstecznej.
Faza szkolenia dyskryminatora:
1 Fałszywe dane są generowane na podstawie aktualnego stanu generatora.
2 Wygenerowane próbki przekazywane są dyskryminatorowi wraz z próbkami ze zbioru uczącego.
3 Korzystając z propagacji wstecznej, parametry dyskryminatora są aktualizowane w oparciu o jego skuteczność klasyfikacji.
Ten iteracyjny proces uczenia jest kontynuowany, a parametry każdego modelu są dostosowywane w oparciu o jego wydajność, aż generator konsekwentnie generuje dane, których dyskryminator nie jest w stanie wiarygodnie odróżnić od danych rzeczywistych.
Rodzaje sieci GAN
Opierając się na podstawowej architekturze GAN, często nazywanej waniliową siecią GAN, opracowano i zoptymalizowano inne wyspecjalizowane typy sieci GAN do różnych zadań. Poniżej opisano niektóre z najczęstszych odmian, choć nie jest to lista wyczerpująca:
Warunkowy GAN (cGAN)
Warunkowe sieci GAN (cGAN) korzystają z dodatkowych informacji, zwanych warunkami, aby kierować modelem w generowaniu określonych typów danych podczas uczenia na bardziej ogólnym zbiorze danych. Warunek może być etykietą klasy, opisem tekstowym lub innym typem informacji klasyfikującej dane. Załóżmy na przykład, że chcesz wygenerować obrazy tylko kotów syjamskich, ale zbiór danych szkoleniowych zawiera obrazy wszystkich rodzajów kotów. W cGAN można oznaczyć obrazy szkoleniowe typem kota, a model może wykorzystać to do nauczenia się, jak generować wyłącznie zdjęcia kotów syjamskich.

Głęboko splotowy GAN (DCGAN)
Głęboko splotowy GAN (DCGAN) jest zoptymalizowany pod kątem generowania obrazu. W DCGAN generatorem jest głęboko osadzona splotowa sieć neuronowa (deCNN), a dyskryminatorem jest głęboka CNN. Sieci CNN lepiej nadają się do pracy z obrazami i generowania obrazów ze względu na ich zdolność do wychwytywania hierarchii i wzorców przestrzennych. Generator w DCGAN wykorzystuje upsampling i transponowane warstwy splotowe do tworzenia obrazów o wyższej jakości, niż mógłby wygenerować wielowarstwowy perceptron (prosta sieć neuronowa podejmująca decyzje na podstawie ważenia cech wejściowych). Podobnie dyskryminator wykorzystuje warstwy splotowe do wyodrębniania cech z próbek obrazu i dokładnego klasyfikowania ich jako prawdziwe lub fałszywe.
CyklGAN
CycleGAN to typ sieci GAN zaprojektowany do generowania jednego typu obrazu na podstawie innego. Na przykład CycleGAN może przekształcić obraz myszy w szczura lub psa w kojota. CycleGAN są w stanie wykonać tę translację obrazu na obraz bez szkolenia na sparowanych zbiorach danych, to znaczy zbiorach danych zawierających zarówno obraz podstawowy, jak i pożądaną transformację. Zdolność tę osiąga się poprzez zastosowanie dwóch generatorów i dwóch dyskryminatorów zamiast pojedynczej pary stosowanej w standardowej sieci GAN. W CycleGAN jeden generator konwertuje obrazy z obrazu bazowego do wersji przekształconej, podczas gdy drugi generator wykonuje konwersję w odwrotnym kierunku. Podobnie każdy dyskryminator sprawdza konkretny typ obrazu, aby określić, czy jest on prawdziwy, czy fałszywy. Następnie CycleGAN sprawdza spójność, aby upewnić się, że konwersja obrazu na inny styl i odwrotnie daje oryginalny obraz.
Zastosowania GAN
Ze względu na swoją charakterystyczną architekturę sieci GAN znalazły zastosowanie w szeregu innowacyjnych przypadków użycia, chociaż ich wydajność w dużym stopniu zależy od konkretnych zadań i jakości danych. Niektóre z bardziej zaawansowanych aplikacji obejmują generowanie tekstu na obraz, powiększanie danych oraz generowanie i manipulowanie wideo.
Generowanie tekstu na obraz
Sieci GAN mogą generować obrazy na podstawie opisu tekstowego. Aplikacja ta jest cenna w branżach kreatywnych, umożliwiając autorom i projektantom wizualizację scen i postaci opisanych w tekście. Podczas gdy sieci GAN są często wykorzystywane do takich zadań, inne generatywne modele sztucznej inteligencji, takie jak DALL-E OpenAI, wykorzystują architektury oparte na transformatorach, aby osiągnąć podobne wyniki.
Zwiększanie danych
Sieci GAN są przydatne do powiększania danych, ponieważ mogą generować dane syntetyczne przypominające rzeczywiste dane szkoleniowe, chociaż stopień dokładności i realizmu może się różnić w zależności od konkretnego przypadku użycia i szkolenia modelu. Ta funkcja jest szczególnie cenna w uczeniu maszynowym w celu rozszerzania ograniczonych zbiorów danych i zwiększania wydajności modelu. Dodatkowo sieci GAN oferują rozwiązanie zapewniające prywatność danych. W wrażliwych dziedzinach, takich jak opieka zdrowotna i finanse, sieci GAN mogą generować syntetyczne dane, które zachowują właściwości statystyczne oryginalnego zbioru danych bez narażania poufnych informacji.
Generowanie i manipulacja wideo
Sieci GAN okazały się obiecujące w niektórych zadaniach związanych z generowaniem i manipulacją wideo. Na przykład sieci GAN można wykorzystać do generowania przyszłych klatek z początkowej sekwencji wideo, pomagając w zastosowaniach takich jak przewidywanie ruchu pieszych lub prognozowanie zagrożeń drogowych dla pojazdów autonomicznych. Jednak aplikacje te są nadal przedmiotem aktywnych badań i rozwoju. Sieci GAN można również wykorzystać do generowania całkowicie syntetycznych treści wideo i ulepszania filmów za pomocą realistycznych efektów specjalnych.
Zalety sieci GAN
Sieci GAN oferują kilka wyraźnych korzyści, w tym możliwość generowania realistycznych danych syntetycznych, uczenia się na podstawie niesparowanych danych i przeprowadzania szkolenia bez nadzoru.
Generowanie wysokiej jakości syntetycznych danych
Architektura sieci GAN umożliwia im wytwarzanie syntetycznych danych, które mogą przybliżać dane ze świata rzeczywistego w zastosowaniach takich jak powiększanie danych i tworzenie wideo, chociaż jakość i precyzja tych danych może w dużym stopniu zależeć od warunków szkolenia i parametrów modelu. Na przykład sieci DCGAN, które wykorzystują sieci CNN do optymalnego przetwarzania obrazu, przodują w generowaniu realistycznych obrazów.
Możliwość uczenia się na podstawie niesparowanych danych
W przeciwieństwie do niektórych modeli ML, sieci GAN mogą uczyć się na podstawie zbiorów danych bez sparowanych przykładów wejść i wyjść. Ta elastyczność pozwala na wykorzystanie sieci GAN w szerokim zakresie zadań, w których sparowane dane są ograniczone lub niedostępne. Na przykład w zadaniach tłumaczenia obrazu na obraz tradycyjne modele często wymagają zestawu danych obrazów i ich transformacji do celów szkoleniowych. Z kolei sieci GAN mogą wykorzystywać szerszą gamę potencjalnych zbiorów danych do celów szkoleniowych.
Uczenie się bez nadzoru
Sieci GAN to metoda uczenia maszynowego bez nadzoru, co oznacza, że można je szkolić na nieoznaczonych danych bez wyraźnych wskazówek. Jest to szczególnie korzystne, ponieważ etykietowanie danych jest procesem czasochłonnym i kosztownym. Zdolność sieci GAN do uczenia się na podstawie nieoznakowanych danych sprawia, że są one cenne w zastosowaniach, w których oznakowane dane są ograniczone lub trudne do uzyskania. Sieci GAN można również przystosować do uczenia się częściowo nadzorowanego i nadzorowanego, co pozwala im również na korzystanie z oznakowanych danych.
Wady sieci GAN
Chociaż sieci GAN są potężnym narzędziem uczenia maszynowego, ich architektura stwarza unikalny zestaw wad. Wady te obejmują wrażliwość na hiperparametry, wysokie koszty obliczeniowe, brak zbieżności i zjawisko zwane załamaniem modów.
Czułość hiperparametrów
Sieci GAN są wrażliwe na hiperparametry, czyli parametry ustawiane przed szkoleniem, których nie można się nauczyć z danych. Przykłady obejmują architektury sieciowe i liczbę przykładów szkoleniowych używanych w pojedynczej iteracji. Niewielkie zmiany tych parametrów mogą znacząco wpłynąć na proces uczenia i wyniki modelu, powodując konieczność obszernego dostrojenia pod kątem praktycznych zastosowań.
Wysoki koszt obliczeniowy
Ze względu na złożoną architekturę, iteracyjny proces uczenia i wrażliwość na hiperparametry, sieci GAN często wiążą się z wysokimi kosztami obliczeniowymi. Pomyślne szkolenie sieci GAN wymaga specjalistycznego i drogiego sprzętu, a także dużej ilości czasu, co może stanowić barierę dla wielu organizacji chcących korzystać z sieci GAN.
Niepowodzenie konwergencji
Inżynierowie i badacze mogą spędzić znaczną ilość czasu na eksperymentowaniu z konfiguracjami szkoleniowymi, zanim osiągną akceptowalną szybkość, przy której dane wyjściowe modelu staną się stabilne i dokładne, zwane współczynnikiem zbieżności. Konwergencja w sieciach GAN może być bardzo trudna do osiągnięcia i może nie trwać długo. Niepowodzenie zbieżności ma miejsce, gdy dyskryminator nie potrafi w wystarczającym stopniu dokonać wyboru między danymi rzeczywistymi a fałszywymi, co skutkuje dokładnością na poziomie około 50%, ponieważ nie uzyskał on możliwości identyfikowania prawdziwych danych, w przeciwieństwie do zamierzonej równowagi osiągniętej podczas udanego szkolenia. Niektóre sieci GAN mogą nigdy nie osiągnąć konwergencji i ich naprawa może wymagać specjalistycznej analizy.
Załamanie trybu
Sieci GAN są podatne na problem zwany załamaniem trybu, w którym generator tworzy ograniczony zakres wyników i nie odzwierciedla różnorodności dystrybucji danych w świecie rzeczywistym. Problem ten wynika z architektury GAN, ponieważ generator nadmiernie skupia się na wytwarzaniu danych, które mogą oszukać dyskryminator, co prowadzi do wygenerowania podobnych przykładów.