
Co to jest sieć neuronowa?
Opublikowany: 2024-06-26Co to jest sieć neuronowa?
Sieć neuronowa to rodzaj modelu głębokiego uczenia się w ramach szerszej dziedziny uczenia maszynowego (ML), który symuluje ludzki mózg. Przetwarza dane poprzez połączone ze sobą węzły lub neurony ułożone w warstwy – wejściowe, ukryte i wyjściowe. Każdy węzeł wykonuje proste obliczenia, przyczyniając się do zdolności modelu do rozpoznawania wzorców i tworzenia prognoz.
Sieci neuronowe uczenia głębokiego są szczególnie skuteczne w obsłudze złożonych zadań, takich jak rozpoznawanie obrazu i mowy, stanowiąc kluczowy element wielu aplikacji AI. Niedawne postępy w architekturach sieci neuronowych i technikach szkoleniowych znacznie zwiększyły możliwości systemów sztucznej inteligencji.
Jak zbudowane są sieci neuronowe
Jak sama nazwa wskazuje, model sieci neuronowej czerpie inspirację z neuronów, elementów budulcowych mózgu. Dorosły człowiek ma około 85 miliardów neuronów, każdy połączony z około 1000 innych. Jedna komórka mózgowa komunikuje się z drugą, wysyłając substancje chemiczne zwane neuroprzekaźnikami. Jeśli komórka odbierająca otrzyma wystarczającą ilość tych substancji chemicznych, ekscytuje się i wysyła własne substancje chemiczne do innej komórki.
Podstawową jednostką tak zwanej sztucznej sieci neuronowej (ANN) jestwęzeł, który zamiast być komórką, jest funkcją matematyczną. Podobnie jak neurony komunikują się z innymi węzłami, jeśli otrzymają wystarczający sygnał wejściowy.
Na tym kończą się podobieństwa. Sieci neuronowe mają znacznie prostszą strukturę niż mózg i mają starannie zdefiniowane warstwy: wejściową, ukrytą i wyjściową. Zbiór tych warstw nazywany jestmodelem.Uczą się lubszkolą, wielokrotnie próbując sztucznie wygenerować wyniki najbardziej przypominające pożądane rezultaty. (Więcej o tym za minutę.)
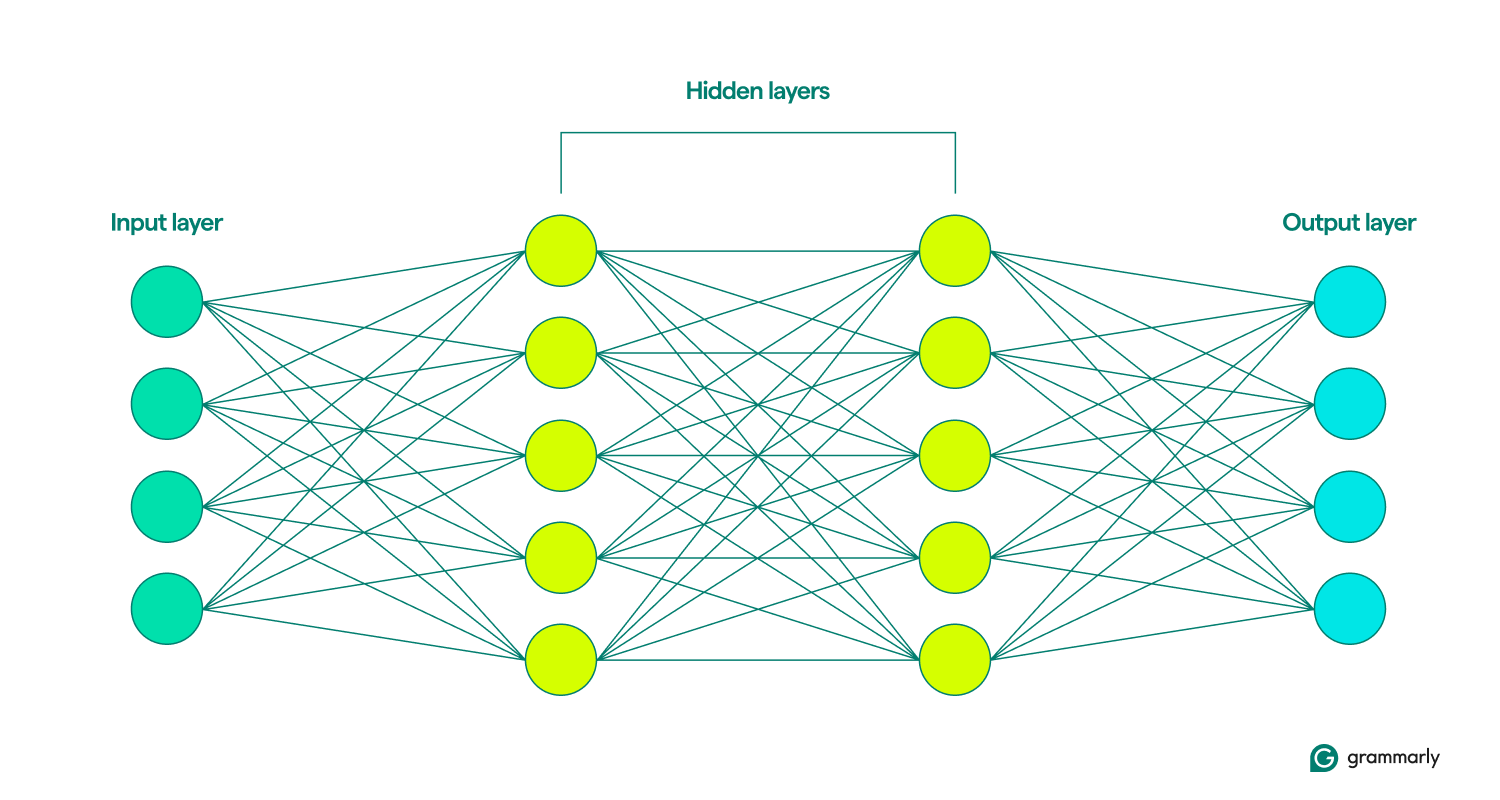
Warstwy wejściowe i wyjściowe są dość oczywiste. Większość funkcji sieci neuronowych odbywa się w warstwach ukrytych. Kiedy węzeł jest aktywowany danymi wejściowymi z poprzedniej warstwy, wykonuje obliczenia i decyduje, czy przekazać dane wyjściowe do węzłów w następnej warstwie. Warstwy te zostały tak nazwane, ponieważ ich działanie jest niewidoczne dla użytkownika końcowego, chociaż istnieją techniki umożliwiające inżynierom sprawdzenie, co dzieje się w tak zwanych warstwach ukrytych.
Kiedy sieci neuronowe zawierają wiele warstw ukrytych, nazywane są sieciami głębokiego uczenia się. Nowoczesne głębokie sieci neuronowe zwykle składają się z wielu warstw, w tym wyspecjalizowanych podwarstw realizujących odrębne funkcje. Na przykład niektóre podwarstwy zwiększają zdolność sieci do uwzględniania informacji kontekstowych wykraczających poza bezpośrednie analizowane dane wejściowe.
Jak działają sieci neuronowe
Pomyśl o tym, jak uczą się dzieci. Próbują czegoś, ponoszą porażkę i próbują ponownie w inny sposób. Pętla trwa w kółko, dopóki dziecko nie udoskonali swojego zachowania. Mniej więcej w ten sposób uczą się sieci neuronowe.
Sieci neuronowe na samym początku swojego uczenia dokonują losowych domysłów. Węzeł w warstwie wejściowej losowo decyduje, który z węzłów w pierwszej warstwie ukrytej ma zostać aktywowany, a następnie te węzły losowo aktywują węzły w następnej warstwie i tak dalej, aż ten losowy proces dotrze do warstwy wyjściowej. (Duże modele językowe, takie jak GPT-4, mają około 100 warstw, z dziesiątkami lub setkami tysięcy węzłów w każdej warstwie).
Biorąc pod uwagę całą losowość, model porównuje wyniki – co jest prawdopodobnie okropne – i ustala, jak bardzo się mylił. Następnie dostosowuje połączenie każdego węzła z innymi węzłami, zmieniając ich większą lub mniejszą skłonność do aktywacji w oparciu o dane wejściowe. Robi to wielokrotnie, aż wyniki będą jak najbardziej zbliżone do pożądanych odpowiedzi.
Skąd więc sieci neuronowe wiedzą, co mają robić? Uczenie maszynowe (ML) można podzielić na różne podejścia, w tym uczenie się nadzorowane i bez nadzoru. W uczeniu nadzorowanym model jest szkolony na danych zawierających wyraźne etykiety lub odpowiedzi, takie jak obrazy w połączeniu z tekstem opisowym. Uczenie się bez nadzoru polega jednak na dostarczeniu modelowi nieoznaczonych danych, co pozwala mu na niezależną identyfikację wzorców i relacji.
Powszechnym uzupełnieniem tego szkolenia jest uczenie się przez wzmacnianie, w przypadku którego model ulega poprawie w odpowiedzi na informację zwrotną. Często zapewniają to ludzie oceniający (jeśli kiedykolwiek kliknąłeś kciuk w górę lub w dół w odpowiedzi na sugestię komputera, przyczyniłeś się do uczenia się przez wzmacnianie). Istnieją jednak sposoby, aby modele mogły uczyć się niezależnie w sposób iteracyjny.
Traktowanie wyników sieci neuronowej jako prognozy jest dokładne i pouczające. Niezależnie od tego, czy oceniasz zdolność kredytową, czy generujesz piosenkę, modele AI działają na zasadzie zgadywania, co jest najprawdopodobniej słuszne. Generatywna sztuczna inteligencja, taka jak ChatGPT, idzie o krok dalej w przewidywaniu. Działa sekwencyjnie, domyślając się, co powinno nastąpić po właśnie utworzonym wyniku. (Później dowiemy się, dlaczego może to być problematyczne.)
Jak sieci neuronowe generują odpowiedzi
Jak sieć po przeszkoleniu przetwarza informacje, które widzi, aby przewidzieć prawidłową reakcję? Kiedy wpiszesz zachętę typu „Opowiedz mi historię o wróżkach” w interfejsie ChatGPT, w jaki sposób ChatGPT decyduje o sposobie odpowiedzi?
Pierwszym krokiem jest podzielenie przez warstwę wejściową sieci neuronowej monitu na małe fragmenty informacji, zwanetokenami. W przypadku sieci rozpoznawania obrazów tokenami mogą być piksele. W przypadku sieci korzystającej z przetwarzania języka naturalnego (NLP), takiej jak ChatGPT, token to zazwyczaj słowo, część słowa lub bardzo krótka fraza.
Gdy sieć zarejestruje tokeny na wejściu, informacje te są przekazywane przez wcześniej wytrenowane warstwy ukryte. Węzły, które przechodzi z jednej warstwy do drugiej, analizują coraz większe sekcje danych wejściowych. W ten sposób sieć NLP może ostatecznie zinterpretować całe zdanie lub akapit, a nie tylko słowo lub literę.
Teraz sieć może zacząć opracowywać swoją odpowiedź, co robi w formie serii słowo po słowie przewidywań dotyczących tego, co będzie dalej, w oparciu o wszystko, na czym została przeszkolona.
Rozważ zachętę: „Opowiedz mi historię o wróżkach”. Aby wygenerować odpowiedź, sieć neuronowa analizuje zachętę, aby przewidzieć najbardziej prawdopodobne pierwsze słowo. Może na przykład określić, że istnieje 80% szans, że „The” będzie najlepszym wyborem, 10% szans na „A” i 10% szans na „Raz”. Następnie losowo wybiera liczbę: Jeśli liczba mieści się w przedziale od 1 do 8, wybiera „The”; jeśli wynosi 9, wybiera „A”; a jeśli jest to 10, wybiera opcję „Raz”. Załóżmy, że losową liczbą jest 4, co odpowiada „The”. Następnie sieć aktualizuje monit do „Opowiedz mi historię o wróżkach”. The” i powtarza proces przewidywania następnego słowa po „The”. Cykl ten trwa, z przewidywaniem każdego nowego słowa na podstawie zaktualizowanego monitu, aż do wygenerowania kompletnej historii.
Różne sieci będą różnie przedstawiać tę prognozę. Na przykład model rozpoznawania obrazu może próbować przewidzieć, jaką etykietę nadać obrazowi psa i ustalić, że prawdopodobieństwo, że prawidłowa etykieta to „czekoladowe laboratorium” wynosi 70%, „spaniel angielski” – 20%, a prawdopodobieństwo 10% dla „złotego retrievera”. Ogólnie rzecz biorąc, w przypadku klasyfikacji sieć będzie opierać się na najbardziej prawdopodobnym wyborze, a nie na probabilistycznym przypuszczeniu.
Rodzaje sieci neuronowych
Oto przegląd różnych typów sieci neuronowych i sposobu ich działania.
- Sieci neuronowe ze sprzężeniem zwrotnym (FNN): W tych modelach informacja przepływa w jednym kierunku: od warstwy wejściowej, przez warstwy ukryte, aż do warstwy wyjściowej.Ten typ modelu najlepiej sprawdza się w przypadku prostszych zadań predykcyjnych, takich jak wykrywanie oszustw związanych z kartami kredytowymi.
- Rekurencyjne sieci neuronowe (RNN): W przeciwieństwie do FNN, RNN podczas generowania prognoz uwzględniają wcześniejsze dane wejściowe.To sprawia, że dobrze nadają się do zadań związanych z przetwarzaniem języka, ponieważ koniec zdania wygenerowanego w odpowiedzi na zachętę zależy od tego, jak zdanie się rozpoczęło.
- Długoterminowe sieci pamięci (LSTM): LSTM selektywnie zapominają informacje, co pozwala im pracować wydajniej.Ma to kluczowe znaczenie przy przetwarzaniu dużych ilości tekstu; na przykład aktualizacja Tłumacza Google z 2016 r. do neuronowego tłumaczenia maszynowego opierała się na LSTM.
- Konwolucyjne sieci neuronowe (CNN): sieci CNN sprawdzają się najlepiej podczas przetwarzania obrazów.Używająwarstw splotowychdo skanowania całego obrazu i szukania takich elementów, jak linie lub kształty. Dzięki temu stacje CNN mogą uwzględniać lokalizację przestrzenną, na przykład określać, czy obiekt znajduje się w górnej, czy dolnej połowie obrazu, a także identyfikować kształt lub typ obiektu niezależnie od jego lokalizacji.
- Generacyjne sieci przeciwstawne (GAN): Sieci GAN są często używane do generowania nowych obrazów na podstawie opisu lub istniejącego obrazu.Ich struktura przypomina rywalizację pomiędzy dwiema sieciami neuronowymi: sieciągeneratorów, która próbuje oszukać siećdyskryminującą, aby uwierzyła, że fałszywe dane wejściowe są prawdziwe.
- Transformatory i sieci uwagi: Transformatory są odpowiedzialne za obecną eksplozję możliwości sztucznej inteligencji.Modele te zawierają uważny reflektor, który pozwala im filtrować dane wejściowe, aby skupić się na najważniejszych elementach oraz na tym, jak te elementy są ze sobą powiązane, nawet na stronach tekstu. Transformatory mogą również trenować na ogromnych ilościach danych, dlatego modele takie jak ChatGPT i Gemini nazywane sądużymi modelami językowymi (LLM).
Zastosowania sieci neuronowych
Jest ich zbyt wiele, aby je wymienić, dlatego poniżej przedstawiamy wybrane sposoby dzisiejszego wykorzystania sieci neuronowych, z naciskiem na język naturalny.

Pomoc w pisaniu: Transformatory zmieniły sposób, w jaki komputery mogą pomóc ludziom lepiej pisać.Narzędzia do pisania oparte na sztucznej inteligencji, takie jak Gramatyka, umożliwiają przepisywanie na poziomie zdań i akapitów w celu poprawy tonu i przejrzystości. Ten typ modelu poprawił także szybkość i dokładność podstawowych sugestii gramatycznych. Dowiedz się więcej o tym, jak Grammarly wykorzystuje sztuczną inteligencję.
Generowanie treści: Jeśli korzystałeś z ChatGPT lub DALL-E, zetknąłeś się z generatywną sztuczną inteligencją na własnej skórze.Transformatory zrewolucjonizowały zdolność komputerów do tworzenia mediów, które rezonują z ludźmi, od bajek na dobranoc po hiperrealistyczne wizualizacje architektoniczne.
Rozpoznawanie mowy: komputery z każdym dniem coraz lepiej radzą sobie z rozpoznawaniem ludzkiej mowy.Dzięki nowszym technologiom, które pozwalają uwzględnić większy kontekst, modele stają się coraz dokładniejsze w rozpoznawaniu tego, co mówiący ma zamiar powiedzieć, nawet jeśli same dźwięki mogą mieć wiele interpretacji.
Diagnostyka i badania medyczne: Sieci neuronowe przodują w wykrywaniu wzorców i klasyfikacji, co jest coraz częściej wykorzystywane, aby pomóc badaczom i podmiotom świadczącym opiekę zdrowotną w zrozumieniu chorób i leczeniu ich.Na przykład sztuczną inteligencję możemy częściowo podziękować za szybki rozwój szczepionek przeciwko Covid-19.
Wyzwania i ograniczenia sieci neuronowych
Oto krótkie spojrzenie na niektóre, choć nie wszystkie, problemy związane z sieciami neuronowymi.
Błąd: Sieć neuronowa może uczyć się tylko na podstawie tego, co jej powiedziano.Jeśli zostanie narażony na treści seksistowskie lub rasistowskie, jego wyniki prawdopodobnie również będą seksistowskie lub rasistowskie. Może się to zdarzyć podczas tłumaczenia z języka niezwiązanego z płcią na język uwzględniający płeć, w przypadku którego utrzymują się stereotypy bez wyraźnej identyfikacji płci.
Nadmierne dopasowanie: niewłaściwie wyszkolony model może wczytać zbyt wiele danych, które otrzymał i mieć problemy z nowymi danymi wejściowymi.Na przykład oprogramowanie do rozpoznawania twarzy szkolone głównie na osobach określonej grupy etnicznej może słabo radzić sobie z twarzami innych ras. Lub filtr spamu może przeoczyć nową odmianę wiadomości-śmieci, ponieważ jest zbyt skoncentrowany na wzorcach, które widział wcześniej.
Halucynacje: większość dzisiejszej generatywnej sztucznej inteligencji w pewnym stopniu wykorzystuje prawdopodobieństwo, aby wybrać, co wyprodukować, zamiast zawsze wybierać najważniejszy wybór.Takie podejście pomaga mu być bardziej kreatywnym i tworzyć tekst, który brzmi bardziej naturalnie, ale może również prowadzić do formułowania stwierdzeń, które są po prostu fałszywe. (Z tego też powodu LLM czasami mylą się w podstawach matematyki.) Niestety, te halucynacje są trudne do wykrycia, jeśli nie wiesz lepiej lub nie sprawdzisz faktów w innych źródłach.
Interpretowalność: często nie można dokładnie wiedzieć, w jaki sposób sieć neuronowa dokonuje prognoz.Chociaż może to być frustrujące z perspektywy osoby próbującej ulepszyć model, może to mieć również konsekwencje, ponieważ w coraz większym stopniu polega się na sztucznej inteligencji przy podejmowaniu decyzji, które mają ogromny wpływ na życie ludzi. Niektóre stosowane dziś modele nie opierają się na sieciach neuronowych właśnie dlatego, że ich twórcy chcą mieć możliwość sprawdzenia i zrozumienia każdego etapu procesu.
Własność intelektualna: wielu uważa, że LLM naruszają prawa autorskie, włączając teksty i inne dzieła sztuki bez pozwolenia.Chociaż modele te zwykle nie reprodukują bezpośrednio dzieł chronionych prawem autorskim, wiadomo, że modele te tworzą obrazy lub wyrażenia, które prawdopodobnie pochodzą od konkretnych artystów, a nawet tworzą dzieła w charakterystycznym stylu artysty, gdy zostanie o to poproszony.
Zużycie energii: Całe to szkolenie i obsługa modeli transformatorów zużywa ogromną energię.Tak naprawdę w ciągu kilku lat sztuczna inteligencja może zużyć tyle energii, co Szwecja czy Argentyna. Podkreśla to rosnące znaczenie uwzględniania źródeł energii i wydajności w rozwoju sztucznej inteligencji.
Przyszłość sieci neuronowych
Przewidywanie przyszłości sztucznej inteligencji jest niezwykle trudne. W 1970 roku jeden z czołowych badaczy sztucznej inteligencji przewidział, że „za trzy do ośmiu lat będziemy mieli maszynę o ogólnej inteligencji przeciętnego człowieka”. (Nadal nie jesteśmy zbyt blisko sztucznej inteligencji ogólnej (AGI). Przynajmniej większość ludzi tak nie uważa.)
Możemy jednak wskazać kilka trendów, na które warto zwrócić uwagę. Bardziej wydajne modele zmniejszyłyby zużycie energii i obsługiwały wydajniejsze sieci neuronowe bezpośrednio na urządzeniach takich jak smartfony. Nowe techniki szkoleniowe mogą pozwolić na bardziej przydatne przewidywania przy mniejszej liczbie danych szkoleniowych. Przełom w interpretowalności może zwiększyć zaufanie i utorować nowe ścieżki poprawy wydajności sieci neuronowej. Wreszcie połączenie obliczeń kwantowych i sieci neuronowych mogłoby doprowadzić do innowacji, które możemy sobie tylko wyobrazić.
Wniosek
Sieci neuronowe, inspirowane strukturą i funkcją ludzkiego mózgu, są podstawą współczesnej sztucznej inteligencji. Doskonale radzą sobie z rozpoznawaniem wzorców i zadaniami przewidywania, stanowiąc podstawę wielu współczesnych aplikacji AI, od rozpoznawania obrazów i mowy po przetwarzanie języka naturalnego. Wraz z postępem w architekturze i technikach szkoleniowych sieci neuronowe w dalszym ciągu przyczyniają się do znacznej poprawy możliwości sztucznej inteligencji.
Pomimo swojego potencjału sieci neuronowe stoją przed wyzwaniami, takimi jak stronniczość, nadmierne dopasowanie i wysokie zużycie energii. Rozwiązanie tych problemów ma kluczowe znaczenie ze względu na ciągły rozwój sztucznej inteligencji. Patrząc w przyszłość, innowacje w zakresie wydajności modeli, ich interpretacji i integracji z obliczeniami kwantowymi obiecują dalsze poszerzanie możliwości sieci neuronowych, potencjalnie prowadząc do jeszcze bardziej rewolucyjnych zastosowań.