
Podstawy nawracających sieci neuronowych: co musisz wiedzieć
Opublikowany: 2024-09-19Rekurencyjne sieci neuronowe (RNN) to podstawowe metody w dziedzinie analizy danych, uczenia maszynowego (ML) i głębokiego uczenia się. Celem tego artykułu jest zbadanie sieci RNN i szczegółowe omówienie ich funkcjonalności, zastosowań oraz zalet i wad w szerszym kontekście głębokiego uczenia się.
Spis treści
Co to jest RNN?
Jak działają RNN
Rodzaje RNN
RNN a transformatory i CNN
Zastosowania RNN
Zalety
Wady
Co to jest rekurencyjna sieć neuronowa?
Rekurencyjna sieć neuronowa to głęboka sieć neuronowa, która może przetwarzać dane sekwencyjne, utrzymując pamięć wewnętrzną, co pozwala jej śledzić przeszłe dane wejściowe w celu generowania wyników. Sieci RNN są podstawowym elementem głębokiego uczenia się i szczególnie nadają się do zadań obejmujących dane sekwencyjne.
Termin „rekurencyjny” w „rekurencyjnej sieci neuronowej” odnosi się do sposobu, w jaki model łączy informacje z wcześniejszych danych wejściowych z bieżącymi danymi wejściowymi. Informacje ze starych wejść są przechowywane w swego rodzaju pamięci wewnętrznej, zwanej „stanem ukrytym”. Powtarza się — zasilając z powrotem poprzednie obliczenia, tworząc ciągły przepływ informacji.
Zademonstrujmy to na przykładzie: załóżmy, że chcemy użyć RNN do wykrycia nastrojów (pozytywnych lub negatywnych) związanych ze zdaniem „Zjadł ciasto szczęśliwie”. RNN przetworzy słowohe, zaktualizuje jego ukryty stan, aby uwzględnić to słowo, a następnie przejdzie dojedzenia, połączy je z tym, czego się odniegonauczył i tak dalej z każdym słowem, aż do zakończenia zdania. Mówiąc inaczej, człowiek czytający to zdanie aktualizowałby swoje zrozumienie z każdym słowem. Po przeczytaniu i zrozumieniu całego zdania człowiek może stwierdzić, że zdanie jest pozytywne lub negatywne. Ten ludzki proces rozumienia jest tym, co próbuje przybliżyć stan ukryty.
RNN są jednym z podstawowych modeli głębokiego uczenia się. Bardzo dobrze radzą sobie z zadaniami związanymi z przetwarzaniem języka naturalnego (NLP), chociaż wyparły je transformatory. Transformatory to zaawansowane architektury sieci neuronowych, które poprawiają wydajność RNN, na przykład poprzez równoległe przetwarzanie danych i możliwość odkrywania relacji między słowami, które są daleko od siebie w tekście źródłowym (przy użyciu mechanizmów uwagi). Jednak sieci RNN są nadal przydatne w przypadku danych szeregów czasowych i w sytuacjach, w których wystarczą prostsze modele.
Jak działają RNN
Aby szczegółowo opisać działanie RNN, wróćmy do wcześniejszego przykładowego zadania: Klasyfikuj tonację zdania „On zjadł ciasto szczęśliwie”.
Zaczynamy od wyszkolonego RNN, który akceptuje dane wejściowe tekstowe i zwraca dane wyjściowe binarne (1 oznacza wartość dodatnią, a 0 oznacza wartość ujemną). Zanim dane wejściowe zostaną przekazane do modelu, stan ukryty jest ogólny — został wyuczony w procesie uczenia, ale nie jest jeszcze specyficzny dla danych wejściowych.
Pierwsze słowo,On, jest przekazywane do modelu. Wewnątrz RNN jego stan ukryty jest następnie aktualizowany (do stanu ukrytego h1), aby uwzględnić słowoHe. Następnie słowoatejest przekazywane do RNN, a h1 jest aktualizowane (do h2), aby uwzględnić to nowe słowo. Proces ten powtarza się aż do przekazania ostatniego słowa. Stan ukryty (h4) jest aktualizowany w celu uwzględnienia ostatniego słowa. Następnie zaktualizowany stan ukryty jest używany do wygenerowania 0 lub 1.
Oto wizualna reprezentacja działania procesu RNN:
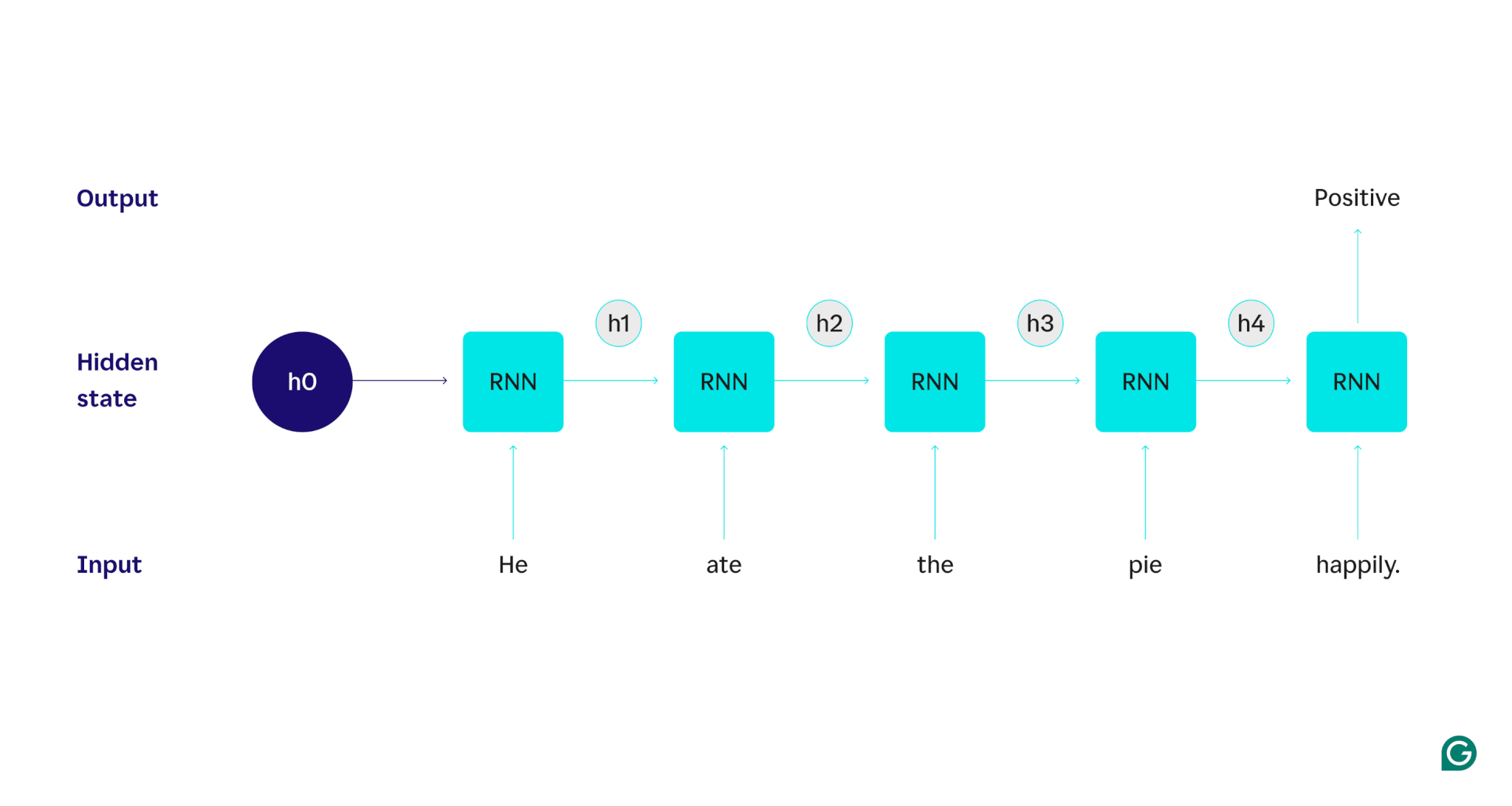
Ta powtarzalność jest podstawą RNN, ale należy wziąć pod uwagę kilka innych kwestii:
- Osadzanie tekstu:RNN nie może bezpośrednio przetwarzać tekstu, ponieważ działa tylko na reprezentacjach numerycznych. Tekst musi zostać przekonwertowany na elementy osadzone, zanim będzie mógł zostać przetworzony przez RNN.
- Generowanie wyników:Wynik będzie generowany przez RNN na każdym etapie. Jednak dane wyjściowe mogą nie być bardzo dokładne, dopóki większość danych źródłowych nie zostanie przetworzona. Na przykład po przetworzeniu tylko części zdania „Zjadł” RNN może nie być pewien, czy reprezentuje ona sentyment pozytywny, czy negatywny – „Zjadł” może wydawać się neutralne. Dopiero po przetworzeniu pełnego zdania dane wyjściowe RNN będą dokładne.
- Szkolenie RNN:RNN musi zostać przeszkolony w zakresie dokładnego przeprowadzania analizy nastrojów. Szkolenie obejmuje korzystanie z wielu oznaczonych etykietami przykładów (np. „Zjadł ciasto ze złością” – oznaczonych jako negatywne), przeglądanie ich przez RNN i dostosowywanie modelu w oparciu o to, jak daleko odbiegają jego przewidywania. Proces ten ustawia domyślną wartość i mechanizm zmiany stanu ukrytego, umożliwiając RNN nauczenie się, które słowa są istotne dla śledzenia całego sygnału wejściowego.
Rodzaje rekurencyjnych sieci neuronowych
Istnieje kilka różnych typów RNN, każdy różniący się strukturą i zastosowaniem. Podstawowe sieci RNN różnią się głównie wielkością wejść i wyjść. Zaawansowane sieci RNN, takie jak sieci pamięci długoterminowej (LSTM), rozwiązują niektóre ograniczenia podstawowych sieci RNN.
Podstawowe RNN
RNN jeden do jednego:Ten RNN pobiera dane wejściowe o długości jeden i zwraca dane wyjściowe o długości jeden. Dlatego w rzeczywistości nie ma żadnego nawrotu, co czyni ją standardową siecią neuronową, a nie RNN. Przykładem RNN typu „jeden do jednego” może być klasyfikator obrazu, którego danymi wejściowymi jest pojedynczy obraz, a wyjściem jest etykieta (np. „ptak”).
RNN jeden do wielu:ten RNN przyjmuje dane wejściowe o długości jeden i zwraca wieloczęściowe wyjście. Na przykład w zadaniu z podpisami do obrazów danymi wejściowymi jest jeden obraz, a wynikiem jest sekwencja słów opisujących obraz (np. „Ptak przepływa przez rzekę w słoneczny dzień”).
RNN typu „wiele do jednego”:ten RNN przyjmuje wieloczęściowe dane wejściowe (np. zdanie, serię obrazów lub dane szeregów czasowych) i zwraca wynik o długości jeden. Na przykład klasyfikator nastrojów zdań (taki jak ten, który omawialiśmy), gdzie danymi wejściowymi jest zdanie, a danymi wyjściowymi jest pojedyncza etykieta nastrojów (dodatnia lub ujemna).
RNN wiele do wielu:ten RNN przyjmuje wieloczęściowe dane wejściowe i zwraca wieloczęściowe dane wyjściowe. Przykładem jest model rozpoznawania mowy, w którym sygnał wejściowy stanowi seria przebiegów audio, a sygnał wyjściowy stanowi sekwencja słów reprezentujących treść mówioną.
Zaawansowane RNN: pamięć długoterminowa (LSTM)
Sieci pamięci krótkotrwałej zostały zaprojektowane w celu rozwiązania istotnego problemu standardowych sieci RNN: zapominają informacje w przypadku długich danych wejściowych. W standardowych sieciach RNN stan ukryty jest silnie zależny od ostatnich części danych wejściowych. W przypadku wpisu liczącego tysiące słów RNN zapomni ważne szczegóły ze zdań początkowych. LSTM mają specjalną architekturę, która pozwala obejść ten problem zapominania. Mają moduły, które wybierają, które informacje należy wyraźnie zapamiętać, a które zapomnieć. Zatem najnowsze, ale bezużyteczne informacje zostaną zapomniane, podczas gdy stare, ale istotne informacje zostaną zachowane. W rezultacie LSTM są znacznie bardziej powszechne niż standardowe RNN — po prostu radzą sobie lepiej w przypadku złożonych lub długich zadań. Jednak nie są doskonali, ponieważ nadal decydują się zapomnieć o przedmiotach.

RNN a transformatory i CNN
Dwa inne popularne modele głębokiego uczenia się to splotowe sieci neuronowe (CNN) i transformatory. Czym się różnią?
RNN a transformatory
Zarówno RNN, jak i transformatory są intensywnie wykorzystywane w NLP. Różnią się jednak znacznie architekturą i podejściem do przetwarzania danych wejściowych.
Architektura i przetwarzanie
- RNN:RNN przetwarzają dane wejściowe sekwencyjnie, jedno słowo na raz, utrzymując stan ukryty, który przenosi informacje z poprzednich słów. Ta sekwencyjna natura oznacza, że RNN mogą borykać się z długotrwałymi zależnościami z powodu tego zapominania, w wyniku którego wcześniejsze informacje mogą zostać utracone w miarę postępu sekwencji.
- Transformatory:Transformatory wykorzystują mechanizm zwany „uwagą” do przetwarzania danych wejściowych. W przeciwieństwie do RNN, transformatory patrzą na całą sekwencję jednocześnie, porównując każde słowo z każdym innym słowem. Takie podejście eliminuje problem zapominania, ponieważ każde słowo ma bezpośredni dostęp do całego kontekstu wejściowego. Dzięki tej możliwości transformatory wykazały doskonałą wydajność w zadaniach takich jak generowanie tekstu i analiza nastrojów.
Równoległość
- RNN:Sekwencyjny charakter RNN oznacza, że model musi zakończyć przetwarzanie jednej części danych wejściowych przed przejściem do następnej. Jest to bardzo czasochłonne, ponieważ każdy krok zależy od poprzedniego.
- Transformatory:Transformatory przetwarzają wszystkie części sygnału wejściowego jednocześnie, ponieważ ich architektura nie opiera się na sekwencyjnym stanie ukrytym. Dzięki temu są znacznie bardziej zrównoleglone i wydajne. Na przykład, jeśli przetwarzanie zdania zajmuje 5 sekund na słowo, RNN zajmie 25 sekund w przypadku zdania składającego się z 5 słów, podczas gdy transformator zajmie tylko 5 sekund.
Praktyczne implikacje
Ze względu na te zalety transformatory są coraz szerzej stosowane w przemyśle. Jednak sieci RNN, zwłaszcza sieci pamięci długoterminowej (LSTM), mogą nadal być skuteczne w przypadku prostszych zadań lub w przypadku krótszych sekwencji. LSTM są często używane jako moduły przechowywania pamięci krytycznej w dużych architekturach uczenia maszynowego.
RNN kontra CNN
CNN zasadniczo różnią się od RNN pod względem przetwarzanych danych i mechanizmów operacyjnych.
Typ danych
- RNN:Sieci RNN są przeznaczone do danych sekwencyjnych, takich jak tekst lub szeregi czasowe, gdzie ważna jest kolejność punktów danych.
- Sieci CNN:Sieci CNN są wykorzystywane głównie do przetwarzania danych przestrzennych, takich jak obrazy, gdzie nacisk kładzie się na relacje między sąsiednimi punktami danych (np. kolor, intensywność i inne właściwości piksela na obrazie są ściśle powiązane z właściwościami innych pobliskich punktów). pikseli).
Działanie
- RNN:Sieci RNN przechowują pamięć całej sekwencji, dzięki czemu nadają się do zadań, w których liczy się kontekst i kolejność.
- Sieci CNN:Sieci CNN działają w oparciu o analizę lokalnych obszarów sygnału wejściowego (np. sąsiednich pikseli) poprzez warstwy splotowe. Dzięki temu są bardzo skuteczne w przetwarzaniu obrazów, ale mniej w przypadku danych sekwencyjnych, gdzie ważniejsze mogą być zależności długoterminowe.
Długość wejściowa
- RNN:Sieci RNN mogą obsługiwać sekwencje wejściowe o zmiennej długości i mniej zdefiniowanej strukturze, co czyni je elastycznymi dla różnych typów danych sekwencyjnych.
- Sieci CNN:Sieci CNN zazwyczaj wymagają danych wejściowych o stałym rozmiarze, co może stanowić ograniczenie w obsłudze sekwencji o zmiennej długości.
Zastosowania RNN
Sieci RNN są szeroko stosowane w różnych dziedzinach ze względu na ich zdolność do skutecznego przetwarzania danych sekwencyjnych.
Przetwarzanie języka naturalnego
Język jest wysoce sekwencyjną formą danych, dlatego sieci RNN dobrze radzą sobie z zadaniami językowymi. RNN przodują w zadaniach takich jak generowanie tekstu, analiza nastrojów, tłumaczenie i podsumowania. Dzięki bibliotekom takim jak PyTorch ktoś mógłby stworzyć prostego chatbota, używając RNN i kilku gigabajtów przykładów tekstowych.
Rozpoznawanie mowy
Rozpoznawanie mowy to rdzeń języka, dlatego też ma charakter wysoce sekwencyjny. Do tego zadania można zastosować RNN typu wiele do wielu. Na każdym etapie RNN pobiera poprzedni stan ukryty i kształt fali, wysyłając słowo powiązane z kształtem fali (w oparciu o kontekst zdania do tego momentu).
Pokolenie muzyki
Muzyka jest również bardzo sekwencyjna. Poprzednie uderzenia w piosence mają duży wpływ na przyszłe uderzenia. RNN typu „wiele do wielu” może przyjąć kilka uderzeń początkowych jako dane wejściowe, a następnie wygenerować dodatkowe uderzenia zgodnie z życzeniem użytkownika. Alternatywnie może przyjąć tekst wprowadzany na przykład „melodyczny jazz” i wygenerować najlepsze przybliżenie melodyjnych rytmów jazzowych.
Zalety RNN
Chociaż RNN nie są już de facto modelem NLP, nadal mają pewne zastosowania z powodu kilku czynników.
Dobra wydajność sekwencyjna
Sieci RNN, zwłaszcza LSTM, dobrze radzą sobie z danymi sekwencyjnymi. LSTM, dzięki swojej wyspecjalizowanej architekturze pamięci, może zarządzać długimi i złożonymi sekwencyjnymi wejściami. Na przykład Tłumacz Google działał na modelu LSTM przed erą transformatorów. LSTM można wykorzystać do dodania strategicznych modułów pamięci, gdy sieci oparte na transformatorach są łączone w bardziej zaawansowane architektury.
Mniejsze, prostsze modele
RNN mają zwykle mniej parametrów modelu niż transformatory. Warstwy uwagi i wyprzedzające w transformatorach wymagają większej liczby parametrów, aby skutecznie działać. Sieci RNN można trenować przy użyciu mniejszej liczby przebiegów i przykładów danych, co czyni je bardziej wydajnymi w prostszych przypadkach użycia. W rezultacie powstają mniejsze, tańsze i bardziej wydajne modele, które nadal są wystarczająco wydajne.
Wady RNN
Sieci RNN wypadły z łask nie bez powodu: Transformatory, pomimo większych rozmiarów i procesu uczenia, nie mają tych samych wad, co RNN.
Ograniczona pamięć
Stan ukryty w standardowych sieciach RNN w dużym stopniu zniekształca ostatnie dane wejściowe, co utrudnia zachowanie zależności dalekiego zasięgu. Zadania z długimi danymi wejściowymi nie działają tak dobrze w przypadku RNN. Chociaż LSTM mają na celu rozwiązanie tego problemu, jedynie go łagodzą, a nie rozwiązują go w pełni. Wiele zadań AI wymaga obsługi długich danych wejściowych, co sprawia, że ograniczona pamięć jest poważną wadą.
Nie można zrównoleglić
Każde uruchomienie modelu RNN zależy od wyniku poprzedniego uruchomienia, w szczególności od zaktualizowanego stanu ukrytego. W rezultacie cały model musi zostać przetworzony sekwencyjnie dla każdej części wejścia. Natomiast transformatory i CNN mogą przetwarzać cały sygnał wejściowy jednocześnie. Pozwala to na równoległe przetwarzanie na wielu procesorach graficznych, znacznie przyspieszając obliczenia. Brak możliwości równoległości sieci RNN prowadzi do wolniejszego uczenia, wolniejszego generowania danych wyjściowych i mniejszej maksymalnej ilości danych, z których można się uczyć.
Problemy z gradientem
Szkolenie sieci RNN może być trudne, ponieważ proces propagacji wstecznej musi przejść przez każdy etap wejściowy (propagacja wsteczna w czasie). Ze względu na wiele etapów czasowych gradienty – które wskazują, w jaki sposób należy dostosować każdy parametr modelu – mogą ulec degradacji i stać się nieskuteczne. Gradienty mogą zawieść, znikając, co oznacza, że stają się bardzo małe i model nie może już używać ich do nauki, lub eksplodując, co powoduje, że gradienty stają się bardzo duże, a model przekracza swoje aktualizacje, przez co model staje się bezużyteczny. Zrównoważenie tych kwestii jest trudne.