
Co to jest autoenkoder? Przewodnik dla początkujących
Opublikowany: 2024-10-28Autoenkodery są istotnym elementem głębokiego uczenia się, szczególnie w zadaniach uczenia maszynowego bez nadzoru. W tym artykule przyjrzymy się działaniu autoenkoderów, ich architekturze i różnym dostępnym typom. Poznasz także ich zastosowania w świecie rzeczywistym, wraz z zaletami i kompromisami związanymi z ich używaniem.
Spis treści
- Co to jest autoenkoder?
- Architektura autoenkodera
- Rodzaje autoenkoderów
- Aplikacja
- Zalety
- Wady
Co to jest autoenkoder?
Autoenkodery to rodzaj sieci neuronowej wykorzystywanej w głębokim uczeniu się do uczenia się wydajnych, niskowymiarowych reprezentacji danych wejściowych, które są następnie wykorzystywane do rekonstrukcji oryginalnych danych. W ten sposób sieć uczy się podczas szkolenia najważniejszych cech danych, nie wymagając wyraźnych etykiet, co czyni ją częścią samonadzorowanego uczenia się. Autoenkodery są szeroko stosowane w zadaniach takich jak odszumianie obrazu, wykrywanie anomalii i kompresja danych, gdzie ich zdolność do kompresji i rekonstrukcji danych jest cenna.
Architektura autoenkodera
Autoenkoder składa się z trzech części: kodera, wąskiego gardła (znanego również jako ukryta przestrzeń lub kod) i dekodera. Komponenty te współpracują ze sobą, aby uchwycić kluczowe cechy danych wejściowych i wykorzystać je do wygenerowania dokładnych rekonstrukcji.
Autoenkodery optymalizują swoje dane wyjściowe, dostosowując wagi zarówno kodera, jak i dekodera, mając na celu stworzenie skompresowanej reprezentacji sygnału wejściowego, która zachowuje najważniejsze funkcje. Optymalizacja ta minimalizuje błąd rekonstrukcji, który reprezentuje różnicę pomiędzy danymi wejściowymi i wyjściowymi.
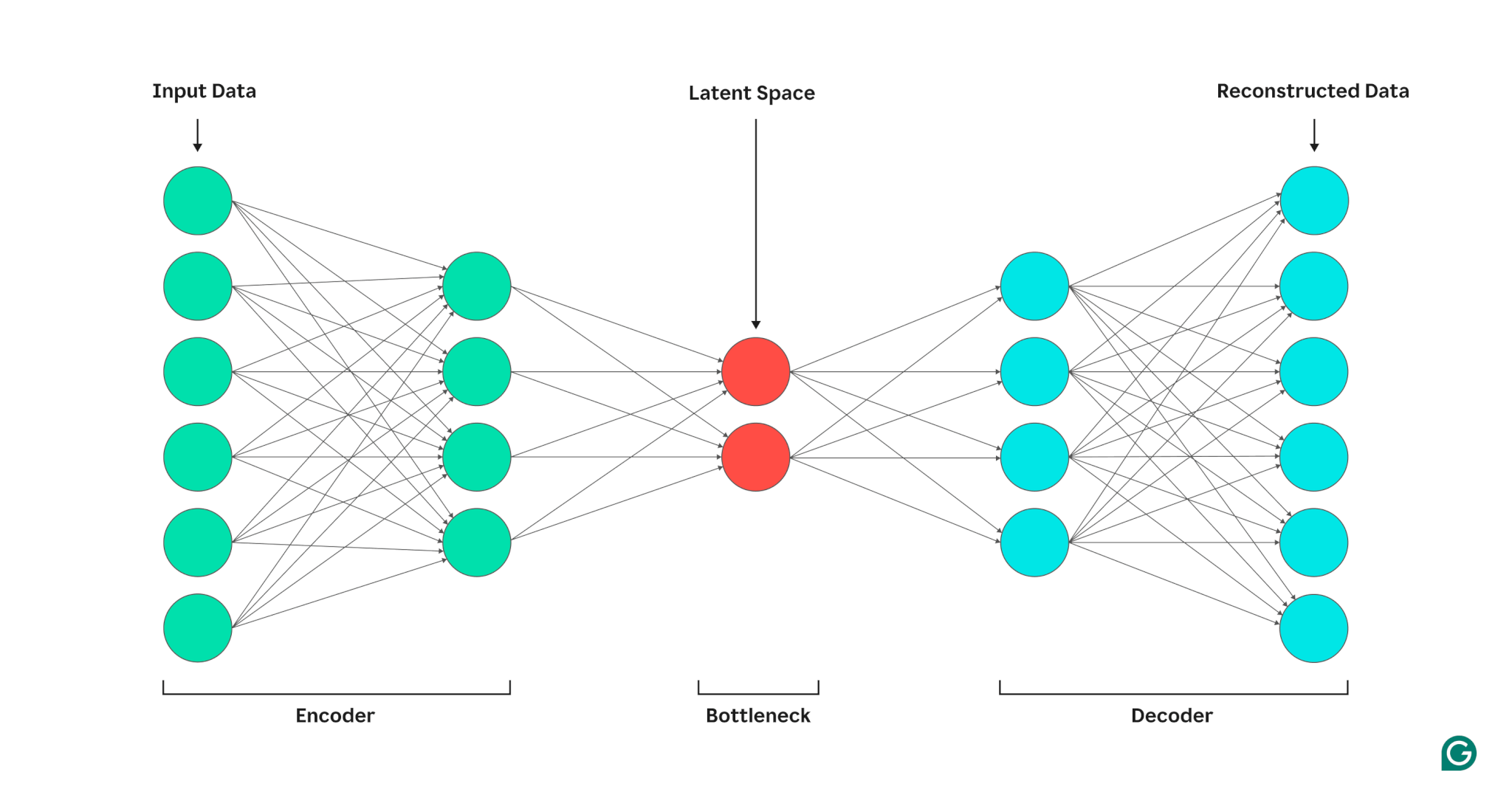
Koder
Po pierwsze, koder kompresuje dane wejściowe w bardziej efektywną reprezentację. Kodery zazwyczaj składają się z wielu warstw z mniejszą liczbą węzłów w każdej warstwie. Ponieważ dane są przetwarzane w każdej warstwie, zmniejszona liczba węzłów zmusza sieć do uczenia się najważniejszych cech danych w celu stworzenia reprezentacji, którą można przechowywać w każdej warstwie. Proces ten, znany jako redukcja wymiarowości, przekształca dane wejściowe w zwarte podsumowanie kluczowych cech danych. Kluczowe hiperparametry w koderze obejmują liczbę warstw i neuronów na warstwę, które określają głębokość i szczegółowość kompresji, oraz funkcję aktywacji, która decyduje o sposobie reprezentowania i przekształcania cech danych w każdej warstwie.
Szyjka
Wąskie gardło, zwane także przestrzenią ukrytą lub kodem, to miejsce, w którym podczas przetwarzania przechowywana jest skompresowana reprezentacja danych wejściowych. Wąskie gardło ma niewielką liczbę węzłów; ogranicza to ilość danych, które można przechowywać i określa poziom kompresji. Liczba węzłów w wąskim gardle to dostrajalny hiperparametr, pozwalający użytkownikom kontrolować kompromis między kompresją a przechowywaniem danych. Jeżeli wąskie gardło jest zbyt małe, autoenkoder może błędnie zrekonstruować dane z powodu utraty ważnych szczegółów. Z drugiej strony, jeśli wąskie gardło jest zbyt duże, autoenkoder może po prostu skopiować dane wejściowe, zamiast uczyć się znaczącej, ogólnej reprezentacji.
Dekoder
Na tym ostatnim etapie dekoder odtwarza oryginalne dane ze skompresowanej postaci, korzystając z kluczowych funkcji poznanych podczas procesu kodowania. Jakość tej dekompresji określa się ilościowo za pomocą błędu rekonstrukcji, który jest zasadniczo miarą tego, jak bardzo różnią się zrekonstruowane dane od danych wejściowych. Błąd rekonstrukcji jest zwykle obliczany przy użyciu błędu średniokwadratowego (MSE). Ponieważ MSE mierzy kwadrat różnicy między danymi oryginalnymi i zrekonstruowanymi, zapewnia matematycznie prosty sposób na większe karanie większych błędów rekonstrukcji.
Rodzaje autoenkoderów
Istnieje kilka typów wyspecjalizowanych autoenkoderów, każdy zoptymalizowany pod kątem konkretnych zastosowań, podobnie jak inne sieci neuronowe.
Odszumianie autoenkoderów
Autoenkodery odszumiające służą do rekonstrukcji czystych danych z zaszumionych lub uszkodzonych danych wejściowych. Podczas uczenia do danych wejściowych celowo dodawany jest szum, dzięki czemu model może nauczyć się cech, które pozostają spójne pomimo szumu. Dane wyjściowe są następnie porównywane z oryginalnymi, czystymi wejściami. Proces ten sprawia, że autoenkodery odszumiające są bardzo skuteczne w zadaniach związanych z redukcją szumów obrazu i dźwięku, w tym w usuwaniu szumów tła podczas wideokonferencji.
Rzadkie autoenkodery
Rzadkie autoenkodery ograniczają liczbę aktywnych neuronów w danym momencie, zachęcając sieć do uczenia się bardziej wydajnych reprezentacji danych w porównaniu ze standardowymi autoenkoderami. To ograniczenie rzadkości jest wymuszane poprzez karę, która zniechęca do aktywowania większej liczby neuronów niż określony próg. Rzadkie autoenkodery upraszczają dane wielowymiarowe, zachowując jednocześnie istotne funkcje, dzięki czemu są przydatne do zadań takich jak wyodrębnianie cech możliwych do interpretacji i wizualizacja złożonych zbiorów danych.
Autoenkodery wariacyjne (VAE)
W przeciwieństwie do typowych autoenkoderów, VAE generują nowe dane poprzez kodowanie funkcji z danych szkoleniowych w rozkładzie prawdopodobieństwa, a nie w stałym punkcie. Próbkując z tego rozkładu, VAE mogą generować różnorodne nowe dane zamiast rekonstruować oryginalne dane z danych wejściowych. Dzięki tej możliwości VAE są przydatne do zadań generatywnych, w tym do generowania danych syntetycznych. Na przykład podczas generowania obrazu VAE przeszkolony na zestawie danych składającym się z odręcznie zapisanych liczb może utworzyć nowe, realistycznie wyglądające cyfry na podstawie zestawu szkoleniowego, które nie są dokładnymi replikami.

Autoenkodery kontraktowe
Autoenkodery kontraktowe wprowadzają dodatkowy element karny podczas obliczania błędu rekonstrukcji, zachęcając model do uczenia się reprezentacji cech odpornych na szum. Ta kara pomaga zapobiegać nadmiernemu dopasowaniu, promując uczenie się funkcji, które jest niezmienne w przypadku małych różnic w danych wejściowych. W rezultacie autoenkodery kontraktowe są bardziej odporne na zakłócenia niż standardowe autoenkodery.
Autoenkodery splotowe (CAE)
CAE wykorzystują warstwy splotowe do przechwytywania hierarchii przestrzennych i wzorców w danych wielowymiarowych. Zastosowanie warstw splotowych sprawia, że CAE szczególnie dobrze nadają się do przetwarzania danych obrazowych. CAE są powszechnie stosowane w zadaniach takich jak kompresja obrazu i wykrywanie anomalii w obrazach.
Zastosowanie autoenkoderów w AI
Autoenkodery mają kilka zastosowań, takich jak redukcja wymiarowości, usuwanie szumów obrazu i wykrywanie anomalii.
Redukcja wymiarowości
Autoenkodery to skuteczne narzędzia zmniejszające wymiarowość danych wejściowych przy jednoczesnym zachowaniu kluczowych funkcji. Proces ten jest przydatny w przypadku zadań takich jak wizualizacja wielowymiarowych zbiorów danych i kompresja danych. Upraszczając dane, redukcja wymiarowości zwiększa również wydajność obliczeniową, zmniejszając zarówno rozmiar, jak i złożoność.
Wykrywanie anomalii
Ucząc się kluczowych cech docelowego zbioru danych, autoenkodery mogą rozróżnić dane normalne od anomalnych, gdy otrzymają nowe dane wejściowe. Odchylenie od normy jest wskazywane przez wyższe niż normalne współczynniki błędów rekonstrukcji. W związku z tym autoenkodery można stosować w różnych dziedzinach, takich jak konserwacja predykcyjna i bezpieczeństwo sieci komputerowych.
Odszumianie
Odszumianie autoenkoderów może oczyścić zaszumione dane, ucząc się ich rekonstrukcji na podstawie zaszumionych wejść szkoleniowych. Dzięki tej możliwości autoenkodery odszumiające są przydatne przy zadaniach takich jak optymalizacja obrazu, w tym poprawianie jakości rozmytych zdjęć. Autoenkodery odszumiające są również przydatne w przetwarzaniu sygnałów, gdzie mogą oczyścić zaszumione sygnały w celu wydajniejszego przetwarzania i analizy.
Zalety autoenkoderów
Autoenkodery mają wiele kluczowych zalet. Obejmują one możliwość uczenia się na podstawie nieoznaczonych danych, automatycznego uczenia się funkcji bez wyraźnych instrukcji i wyodrębniania funkcji nieliniowych.
Możliwość uczenia się na podstawie nieoznaczonych danych
Autoenkodery to model uczenia maszynowego bez nadzoru, co oznacza, że mogą uczyć się podstawowych funkcji danych z danych nieoznaczonych. Ta funkcja oznacza, że autoenkodery można zastosować do zadań, w których dane oznaczone etykietami mogą być rzadkie lub niedostępne.
Automatyczne uczenie się funkcji
Standardowe techniki ekstrakcji cech, takie jak analiza głównych składowych (PCA), są często niepraktyczne, jeśli chodzi o obsługę złożonych i/lub dużych zbiorów danych. Ponieważ autoenkodery zostały zaprojektowane z myślą o takich zadaniach, jak redukcja wymiarów, mogą automatycznie uczyć się kluczowych funkcji i wzorców danych bez konieczności ręcznego projektowania funkcji.
Ekstrakcja cech nieliniowych
Autoenkodery mogą obsługiwać nieliniowe relacje w danych wejściowych, umożliwiając modelowi przechwytywanie kluczowych cech z bardziej złożonych reprezentacji danych. Ta zdolność oznacza, że autoenkodery mają przewagę nad modelami, które mogą pracować tylko z danymi liniowymi, ponieważ mogą obsługiwać bardziej złożone zbiory danych.
Ograniczenia autoenkoderów
Podobnie jak inne modele ML, autoenkodery mają swój własny zestaw wad. Należą do nich brak możliwości interpretacji, potrzeba dobrego działania dużych zbiorów danych szkoleniowych oraz ograniczone możliwości uogólniania.
Brak możliwości interpretacji
Podobnie jak inne złożone modele ML, autoenkodery cierpią na brak możliwości interpretacji, co oznacza, że trudno jest zrozumieć związek między danymi wejściowymi a wynikami modelu. W autoenkoderach ten brak możliwości interpretacji występuje, ponieważ autoenkodery automatycznie uczą się funkcji w przeciwieństwie do tradycyjnych modeli, w których funkcje są wyraźnie zdefiniowane. Ta wygenerowana maszynowo reprezentacja cech jest często wysoce abstrakcyjna i zazwyczaj brakuje jej cech możliwych do interpretacji przez człowieka, co utrudnia zrozumienie, co oznacza każdy element reprezentacji.
Wymagaj dużych zbiorów danych szkoleniowych
Autoenkodery zazwyczaj wymagają dużych zbiorów danych szkoleniowych, aby nauczyć się możliwych do uogólnienia reprezentacji kluczowych cech danych. Biorąc pod uwagę małe zestawy danych szkoleniowych, autoenkodery mogą mieć tendencję do nadmiernego dopasowania, co prowadzi do słabego uogólnienia po przedstawieniu nowych danych. Z drugiej strony duże zbiory danych zapewniają niezbędną różnorodność, aby autoenkoder mógł uczyć się funkcji danych, które można zastosować w szerokim zakresie scenariuszy.
Ograniczone uogólnianie nowych danych
Autoenkodery wytrenowane na jednym zbiorze danych często mają ograniczone możliwości uogólniania, co oznacza, że nie dostosowują się do nowych zbiorów danych. To ograniczenie występuje, ponieważ autoenkodery są nastawione na rekonstrukcję danych w oparciu o najważniejsze cechy danego zbioru danych. W związku z tym autoenkodery zazwyczaj wyrzucają mniejsze szczegóły z danych podczas uczenia i nie mogą obsłużyć danych, które nie pasują do uogólnionej reprezentacji funkcji.