
Co to jest drzewo decyzyjne w uczeniu maszynowym?
Opublikowany: 2024-08-14Drzewa decyzyjne to jedno z najpopularniejszych narzędzi w zestawie narzędzi do uczenia maszynowego analityków danych. W tym przewodniku dowiesz się, czym są drzewa decyzyjne, jak są zbudowane, jakie są ich zastosowania, korzyści i nie tylko.
Spis treści
- Co to jest drzewo decyzyjne?
- Terminologia drzewa decyzyjnego
- Rodzaje drzew decyzyjnych
- Jak działają drzewa decyzyjne
- Aplikacje
- Zalety
- Wady
Co to jest drzewo decyzyjne?
W uczeniu maszynowym (ML) drzewo decyzyjne to algorytm uczenia się nadzorowanego, który przypomina schemat blokowy lub schemat decyzyjny. W przeciwieństwie do wielu innych algorytmów uczenia się nadzorowanego, drzewa decyzyjne mogą być wykorzystywane zarówno do zadań klasyfikacji, jak i regresji. Analitycy i analitycy danych często korzystają z drzew decyzyjnych podczas eksploracji nowych zbiorów danych, ponieważ są łatwe w konstrukcji i interpretacji. Ponadto drzewa decyzyjne mogą pomóc w identyfikacji ważnych cech danych, które mogą być przydatne przy stosowaniu bardziej złożonych algorytmów uczenia maszynowego.
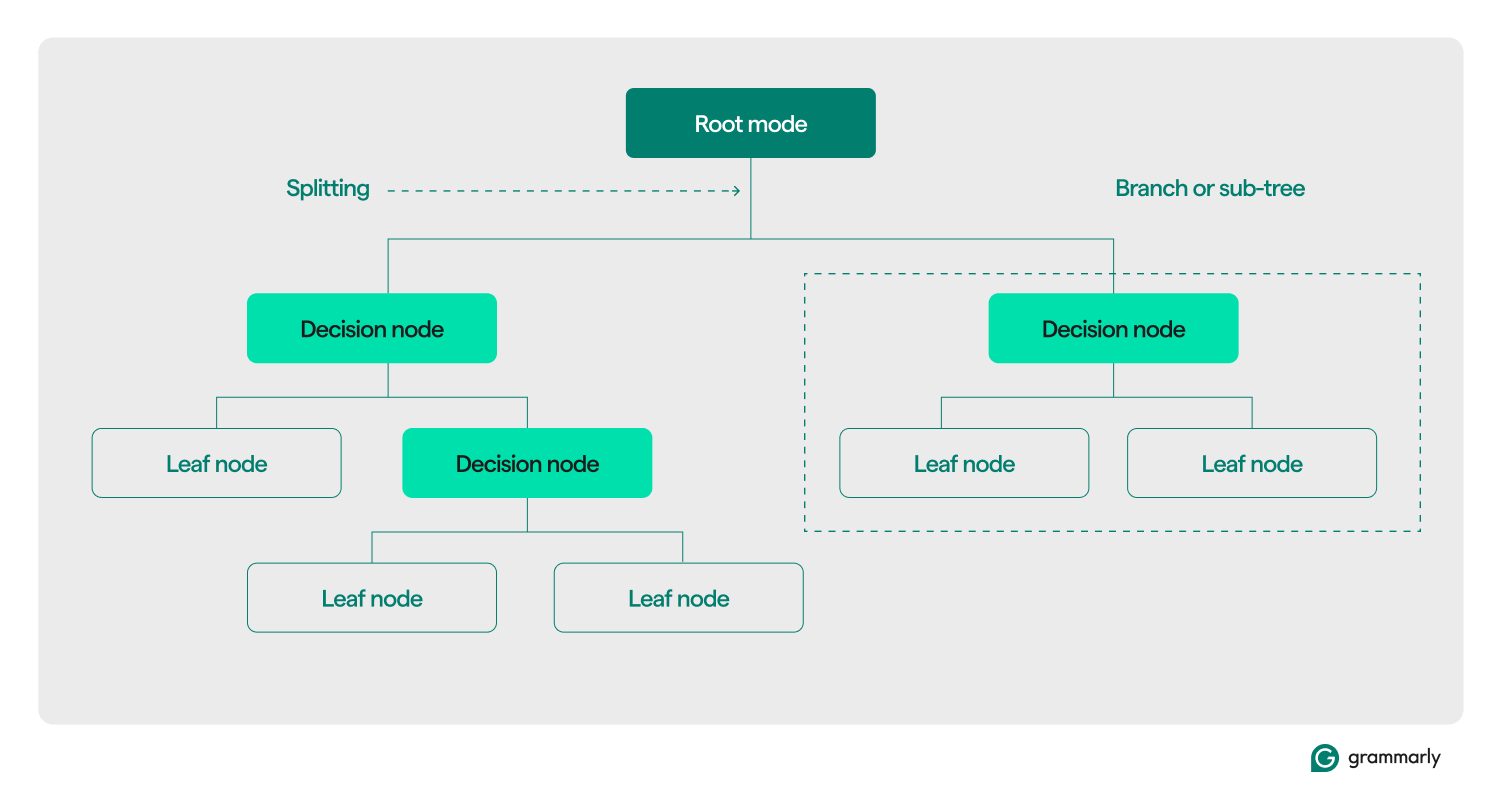
Terminologia drzewa decyzyjnego
Strukturalnie drzewo decyzyjne składa się zazwyczaj z trzech elementów: węzła głównego, węzłów liściowych i węzłów decyzyjnych (lub wewnętrznych). Podobnie jak schematy blokowe lub drzewa w innych domenach, decyzje w drzewie zwykle poruszają się w jednym kierunku (w dół lub w górę), zaczynając od węzła głównego, przechodząc przez niektóre węzły decyzyjne, a kończąc na określonym węźle-liście. Każdy węzeł liścia łączy podzbiór danych szkoleniowych z etykietą. Drzewo jest składane w procesie szkolenia i optymalizacji uczenia maszynowego, a po zbudowaniu można je zastosować do różnych zbiorów danych.
Oto głębsze omówienie pozostałej terminologii:
- Węzeł główny:węzeł przechowujący pierwsze z serii pytań, które drzewo decyzyjne zadaje na temat danych. Węzeł będzie połączony z co najmniej jednym (ale zwykle dwoma lub więcej) węzłami decyzyjnymi lub liśćmi.
- Węzły decyzyjne (lub węzły wewnętrzne):dodatkowe węzły zawierające pytania. Węzeł decyzyjny będzie zawierał dokładnie jedno pytanie dotyczące danych i na podstawie odpowiedzi skieruje przepływ danych do jednego ze swoich elementów podrzędnych.
- Elementy podrzędne:jeden lub więcej węzłów, na które wskazuje węzeł główny lub decyzyjny. Stanowią one listę kolejnych opcji, jakie może podjąć proces decyzyjny podczas analizy danych.
- Węzły liści (lub węzły końcowe):węzły wskazujące, że proces decyzyjny został zakończony. Gdy proces decyzyjny dotrze do węzła liścia, zwróci wartości z węzła liścia jako swoje dane wyjściowe.
- Etykieta (klasa, kategoria):Ogólnie rzecz biorąc, ciąg znaków powiązany przez węzeł liścia z niektórymi danymi szkoleniowymi. Na przykład liść może skojarzyć etykietę „Zadowolony klient” z zestawem konkretnych klientów, którym został przedstawiony algorytm uczenia drzewa decyzyjnego ML.
- Gałąź (lub poddrzewo):Jest to zbiór węzłów składający się z węzła decyzyjnego w dowolnym punkcie drzewa, wraz ze wszystkimi jego dziećmi i ich dziećmi, aż do węzłów liści.
- Przycinanie:operacja optymalizacji zwykle wykonywana na drzewie, aby je zmniejszyć i przyspieszyć zwracanie wyników. Przycinanie zwykle odnosi się do „przycinania końcowego”, które polega na algorytmicznym usuwaniu węzłów lub gałęzi po zbudowaniu drzewa przez proces uczenia ML. „Przycinanie wstępne” odnosi się do ustalenia dowolnego limitu głębokości i wielkości drzewa decyzyjnego podczas szkolenia. Obydwa procesy wymuszają maksymalną złożoność drzewa decyzyjnego, zwykle mierzoną jego maksymalną głębokością lub wysokością. Mniej powszechne optymalizacje obejmują ograniczenie maksymalnej liczby węzłów decyzyjnych lub węzłów liściowych.
- Dzielenie:Podstawowy etap transformacji wykonywany na drzewie decyzyjnym podczas uczenia. Polega na podzieleniu węzła głównego lub decyzyjnego na dwa lub więcej podwęzłów.
- Klasyfikacja:algorytm uczenia maszynowego, który próbuje ustalić, który (ze stałej i dyskretnej listy klas, kategorii lub etykiet) najprawdopodobniej zostanie zastosowany do fragmentu danych. Może próbować odpowiedzieć na pytania takie jak „Który dzień tygodnia jest najlepszy na rezerwację lotu?” Więcej o klasyfikacji poniżej.
- Regresja:algorytm ML, który próbuje przewidzieć wartość ciągłą, która nie zawsze ma granice. Może próbować odpowiedzieć (lub przewidzieć odpowiedź) na pytania takie jak „Ile osób prawdopodobnie zarezerwuje lot w przyszły wtorek?” Więcej o drzewach regresji porozmawiamy w następnej sekcji.
Rodzaje drzew decyzyjnych
Drzewa decyzyjne są zazwyczaj podzielone na dwie kategorie: drzewa klasyfikacyjne i drzewa regresji. Można zbudować określone drzewo, które będzie miało zastosowanie do klasyfikacji, regresji lub obu przypadków użycia. Większość współczesnych drzew decyzyjnych wykorzystuje algorytm CART (Drzewa Klasyfikacji i Regresji), który może wykonywać oba typy zadań.
Drzewa klasyfikacyjne
Drzewa klasyfikacyjne, najpopularniejszy typ drzew decyzyjnych, próbują rozwiązać problem klasyfikacji. Z listy możliwych odpowiedzi na pytanie (często tak prostych, jak „tak” lub „nie”) drzewo klasyfikacyjne wybierze najbardziej prawdopodobną odpowiedź po zadaniu kilku pytań na temat prezentowanych danych. Zazwyczaj są one implementowane jako drzewa binarne, co oznacza, że każdy węzeł decyzyjny ma dokładnie dwoje dzieci.
Drzewa klasyfikacyjne mogą próbować odpowiedzieć na pytania wielokrotnego wyboru, takie jak „Czy ten klient jest zadowolony?” lub „Jaki sklep fizyczny prawdopodobnie odwiedzi ten klient?” lub „Czy jutro będzie dobry dzień na pójście na pole golfowe?”
Dwie najpopularniejsze metody pomiaru jakości drzewa klasyfikacyjnego opierają się na wzmocnieniu informacji i entropii:
- Zysk informacji:Wydajność drzewa wzrasta, gdy zadaje mniej pytań, zanim uzyska odpowiedź. Zysk informacji mierzy, jak „szybko” drzewo może uzyskać odpowiedź, oceniając, o ile więcej informacji o fragmencie danych uzyskuje się w każdym węźle decyzyjnym. Ocenia, czy najważniejsze i przydatne pytania są zadawane jako pierwsze w drzewie.
- Entropia:Dokładność ma kluczowe znaczenie w przypadku etykiet drzew decyzyjnych. Metryki entropii mierzą tę dokładność poprzez ocenę etykiet wytwarzanych przez drzewo. Oceniają, jak często losowy fragment danych otrzymuje niewłaściwą etykietę oraz podobieństwo między wszystkimi fragmentami danych szkoleniowych, które otrzymują tę samą etykietę.
Bardziej zaawansowane pomiary jakości drzewa obejmująindeks Giniego,współczynnik wzmocnienia,ocenę chi-kwadrati różne pomiary redukcji wariancji.
Drzewa regresyjne
Drzewa regresji są zwykle używane w analizie regresji do zaawansowanej analizy statystycznej lub do przewidywania danych na podstawie ciągłego, potencjalnie nieograniczonego zakresu. Biorąc pod uwagę szereg opcji ciągłych (np. od zera do nieskończoności w skali liczb rzeczywistych), drzewo regresji próbuje przewidzieć najbardziej prawdopodobne dopasowanie dla danego fragmentu danych po zadaniu serii pytań. Każde pytanie zawęża potencjalny zakres odpowiedzi. Na przykład drzewo regresji można wykorzystać do przewidywania wyników kredytowych, przychodów z branży lub liczby interakcji z marketingowym filmem wideo.
Dokładność drzew regresji jest zwykle oceniana za pomocą wskaźników, takich jakbłąd średniokwadratowylubśredni błąd bezwzględny, które obliczają, jak daleko określony zestaw przewidywań różni się od wartości rzeczywistych.
Jak działają drzewa decyzyjne
Jako przykład uczenia się pod nadzorem, drzewa decyzyjne opierają się na dobrze sformatowanych danych do szkolenia. Dane źródłowe zwykle zawierają listę wartości, których model powinien nauczyć się przewidywać lub klasyfikować. Każda wartość powinna mieć dołączoną etykietę i listę powiązanych funkcji — właściwości, które model powinien nauczyć się kojarzyć z etykietą.

Budowanie lub szkolenie
Podczas procesu uczenia węzły decyzyjne w drzewie decyzyjnym są rekurencyjnie dzielone na bardziej szczegółowe węzły zgodnie z jednym lub większą liczbą algorytmów uczących. Opis procesu na poziomie ludzkim może wyglądać następująco:
- Zacznij od węzła głównegopołączonego z całym zestawem szkoleniowym.
- Podziel węzeł główny:stosując podejście statystyczne, przypisz decyzję do węzła głównego na podstawie jednej z cech danych i rozprowadź dane szkoleniowe do co najmniej dwóch oddzielnych węzłów liściowych, połączonych z korzeniem jako dzieci.
- Zastosuj rekurencyjnie krok drugido każdego z dzieci, przekształcając je z węzłów liści w węzły decyzyjne. Zatrzymaj się, gdy zostanie osiągnięty jakiś limit (np. wysokość/głębokość drzewa, miara jakości dzieci w każdym liściu w każdym węźle itp.) lub jeśli skończą Ci się dane (tj. każdy liść zawiera dane punkty powiązane z dokładnie jedną etykietą).
Decyzja o tym, które cechy należy uwzględnić w każdym węźle, różni się w przypadku klasyfikacji, regresji i przypadków użycia klasyfikacji łączonej i regresji. Istnieje wiele algorytmów do wyboru dla każdego scenariusza. Typowe algorytmy obejmują:
- ID3 (klasyfikacja):Optymalizuje entropię i przyrost informacji
- C4.5 (klasyfikacja):Bardziej złożona wersja ID3, dodająca normalizację w celu uzyskania informacji
- CART (klasyfikacja/regresja): „Drzewo klasyfikacji i regresji”; zachłanny algorytm, który optymalizuje pod kątem minimalnej nieczystości w zestawach wyników
- CHAID (klasyfikacja/regresja): „Automatyczne wykrywanie interakcji chi-kwadrat”; wykorzystuje pomiary chi-kwadrat zamiast entropii i przyrostu informacji
- MARS (klasyfikacja/regresja): Wykorzystuje odcinkowe przybliżenia liniowe w celu uchwycenia nieliniowości
Powszechnym systemem szkoleniowym jest losowy las. Losowy las lub losowy las decyzyjny to system, który buduje wiele powiązanych drzew decyzyjnych. Wiele wersji drzewa można trenować równolegle przy użyciu kombinacji algorytmów uczących. W oparciu o różne pomiary jakości drzew, do uzyskania odpowiedzi zostanie wykorzystany podzbiór tych drzew. W przypadku przypadków użycia klasyfikacji jako odpowiedź zwracana jest klasa wybrana przez największą liczbę drzew. W przypadkach użycia regresji odpowiedź jest agregowana, zwykle jako średnia lub średnia prognoza poszczególnych drzew.
Ocena i wykorzystanie drzew decyzyjnych
Po skonstruowaniu drzewa decyzyjnego może ono klasyfikować nowe dane lub przewidywać wartości dla konkretnego przypadku użycia. Ważne jest, aby przechowywać metryki dotyczące wydajności drzewa i używać ich do oceny dokładności i częstotliwości błędów. Jeśli model odbiega zbytnio od oczekiwanej wydajności, może nadszedł czas, aby go ponownie przeszkolić na nowych danych lub znaleźć inne systemy uczenia maszynowego, które można zastosować w tym przypadku użycia.
Zastosowania drzew decyzyjnych w ML
Drzewa decyzyjne mają szeroki zakres zastosowań w różnych dziedzinach. Oto kilka przykładów ilustrujących ich wszechstronność:
Świadome podejmowanie decyzji osobistych
Osoba może śledzić dane na przykład o odwiedzanych restauracjach. Mogą śledzić wszelkie istotne szczegóły, takie jak czas podróży, czas oczekiwania, oferowana kuchnia, godziny otwarcia, średnia ocena, koszt i ostatnia wizyta, w połączeniu z oceną zadowolenia z wizyty danej osoby w danej restauracji. Na podstawie tych danych można wytrenować drzewo decyzyjne, aby przewidzieć prawdopodobny poziom zadowolenia nowej restauracji.
Oblicz prawdopodobieństwo dotyczące zachowania klienta
Systemy obsługi klienta mogą wykorzystywać drzewa decyzyjne do przewidywania lub klasyfikowania satysfakcji klienta. Drzewo decyzyjne można wytrenować tak, aby przewidywało satysfakcję klienta na podstawie różnych czynników, takich jak to, czy klient skontaktował się z pomocą techniczną, czy dokonał ponownego zakupu, czy też na podstawie działań wykonanych w aplikacji. Dodatkowo może uwzględniać wyniki ankiet satysfakcji lub innych opinii klientów.
Pomóż podejmować trafne decyzje biznesowe
W przypadku niektórych decyzji biznesowych opartych na dużej ilości danych historycznych drzewo decyzyjne może zapewnić szacunki lub prognozy dotyczące kolejnych kroków. Na przykład firma gromadząca informacje demograficzne i geograficzne o swoich klientach może wytrenować drzewo decyzyjne, aby ocenić, które nowe lokalizacje geograficzne będą prawdopodobnie opłacalne lub których należy unikać. Drzewa decyzyjne mogą również pomóc w określeniu najlepszych granic klasyfikacji dla istniejących danych demograficznych, na przykład w określeniu przedziałów wiekowych, które należy uwzględnić osobno podczas grupowania klientów.
Wybór funkcji dla zaawansowanego uczenia maszynowego i innych przypadków użycia
Struktury drzew decyzyjnych są czytelne i zrozumiałe dla człowieka. Po zbudowaniu drzewa można określić, które cechy są najbardziej istotne dla zbioru danych i w jakiej kolejności. Informacje te mogą pomóc w opracowaniu bardziej złożonych systemów uczenia maszynowego lub algorytmów decyzyjnych. Na przykład, jeśli firma dowie się z drzewa decyzyjnego, że klienci priorytetowo traktują koszt produktu ponad wszystko inne, może skupić się na tych spostrzeżeniach w bardziej złożonych systemach uczenia maszynowego lub zignorować koszty podczas eksplorowania bardziej zróżnicowanych funkcji.
Zalety drzew decyzyjnych w ML
Drzewa decyzyjne oferują kilka istotnych zalet, które czynią je popularnym wyborem w zastosowaniach uczenia maszynowego. Oto kilka kluczowych korzyści:
Szybki i łatwy w budowie
Drzewa decyzyjne są jednymi z najbardziej dojrzałych i dobrze poznanych algorytmów ML. Nie wymagają one szczególnie skomplikowanych obliczeń i można je zbudować szybko i łatwo. Jeśli wymagane informacje są łatwo dostępne, drzewo decyzyjne jest łatwym pierwszym krokiem do podjęcia przy rozważaniu rozwiązań problemu za pomocą uczenia maszynowego.
Łatwe do zrozumienia dla ludzi
Dane wyjściowe z drzew decyzyjnych są szczególnie łatwe do odczytania i interpretacji. Graficzna reprezentacja drzewa decyzyjnego nie zależy od zaawansowanego zrozumienia statystyk. W związku z tym drzewa decyzyjne i ich reprezentacje można wykorzystać do interpretacji, wyjaśniania i wspierania wyników bardziej złożonych analiz. Drzewa decyzyjne doskonale nadają się do znajdowania i podkreślania niektórych właściwości wysokiego poziomu danego zbioru danych.
Wymagane minimalne przetwarzanie danych
Drzewa decyzyjne można równie łatwo zbudować na niekompletnych danych, jak i na danych zawierających wartości odstające. Biorąc pod uwagę dane ozdobione interesującymi funkcjami, algorytmy drzewa decyzyjnego zwykle nie podlegają takim wpływom jak inne algorytmy ML, jeśli są zasilane danymi, które nie zostały wstępnie przetworzone.
Wady drzew decyzyjnych w ML
Chociaż drzewa decyzyjne oferują wiele korzyści, mają również kilka wad:
Podatny na przetrenowanie
Drzewa decyzyjne są podatne na nadmierne dopasowanie, które ma miejsce, gdy model uczy się szumu i szczegółów danych szkoleniowych, co zmniejsza jego wydajność w przypadku nowych danych. Na przykład, jeśli dane szkoleniowe są niekompletne lub rzadkie, niewielkie zmiany w danych mogą spowodować powstanie znacząco różnych struktur drzewiastych. Zaawansowane techniki, takie jak przycinanie lub ustawianie maksymalnej głębokości, mogą poprawić zachowanie drzewa. W praktyce drzewa decyzyjne często wymagają aktualizacji o nowe informacje, co może znacząco zmienić ich strukturę.
Słaba skalowalność
Oprócz tendencji do nadmiernego dopasowania, drzewa decyzyjne borykają się z bardziej zaawansowanymi problemami, które wymagają znacznie większej ilości danych. W porównaniu z innymi algorytmami, czas uczenia drzew decyzyjnych gwałtownie rośnie wraz ze wzrostem ilości danych. W przypadku większych zbiorów danych, które mogą mieć istotne właściwości wysokiego poziomu do wykrycia, drzewa decyzyjne nie są zbyt dobrym rozwiązaniem.
Nie tak skuteczny w przypadku regresji lub ciągłego użycia
Drzewa decyzyjne słabo uczą się złożonych rozkładów danych. Podzielili przestrzeń cech wzdłuż linii, które są łatwe do zrozumienia, ale matematycznie proste. W przypadku złożonych problemów, w których istotne są wartości odstające, regresji i ciągłych przypadków użycia, często przekłada się to na znacznie gorszą wydajność niż w przypadku innych modeli i technik uczenia maszynowego.