
Wynik F1 w uczeniu maszynowym: jak skutecznie go obliczać, stosować i używać
Opublikowany: 2025-02-10Wynik F1 jest potężną metryką do oceny modeli uczenia maszynowego (ML) zaprojektowanych do wykonywania klasyfikacji binarnej lub wieloklasowej. W tym artykule wyjaśniono, jaki jest wynik F1, dlaczego jest to ważne, jak jest obliczany oraz jego zastosowania, korzyści i ograniczenia.
Spis treści
- Co to jest wynik F1?
- Jak obliczyć wynik F1
- Wynik F1 vs.
- Zastosowania wyniku F1
- Korzyści z wyniku F1
- Ograniczenia wyniku F1
Co to jest wynik F1?
Praktycy ML stają stawiającym wspólnym wyzwaniem przy budowaniu modeli klasyfikacji: szkolenie modelu w celu złapania wszystkich przypadków, unikając fałszywych alarmów. Jest to szczególnie ważne w krytycznych zastosowaniach, takich jak wykrywanie oszustw finansowych i diagnoza medyczna, w których fałszywe alarmy i brak ważnych klasyfikacji mają poważne konsekwencje. Osiągnięcie właściwej równowagi jest szczególnie ważne w przypadku niezrównoważonych zestawów danych, w których kategoria taka jak oszukańcze transakcje jest znacznie rzadsze niż inna kategoria (legalne transakcje).
Precyzja i wycofanie
Aby zmierzyć jakość wydajności modelu, wynik F1 łączy dwa powiązane wskaźniki:
- Precyzja, która odpowiada: „Gdy model przewiduje pozytywny przypadek, jak często jest to poprawne?”
- Przypomnijmy, które odpowiedzi: „Ze wszystkich rzeczywistych pozytywnych przypadków, ile model poprawnie zidentyfikował?”
Model o wysokiej precyzji, ale niskiej przywołania jest zbyt ostrożny, brakuje wielu prawdziwych pozytywów, podczas gdy jeden o wysokim wycofaniu, ale niski precyzja jest zbyt agresywna, generując wiele fałszywych pozytywów. Wynik F1 uderza w równowagę, przyjmując średnią harmoniczną precyzji i wycofania, co przynosi większą wagę niższym wartościom i zapewnia, że model osiągnie dobrze w obu wskaźnikach, a nie wyróżniając się tylko w jednym.
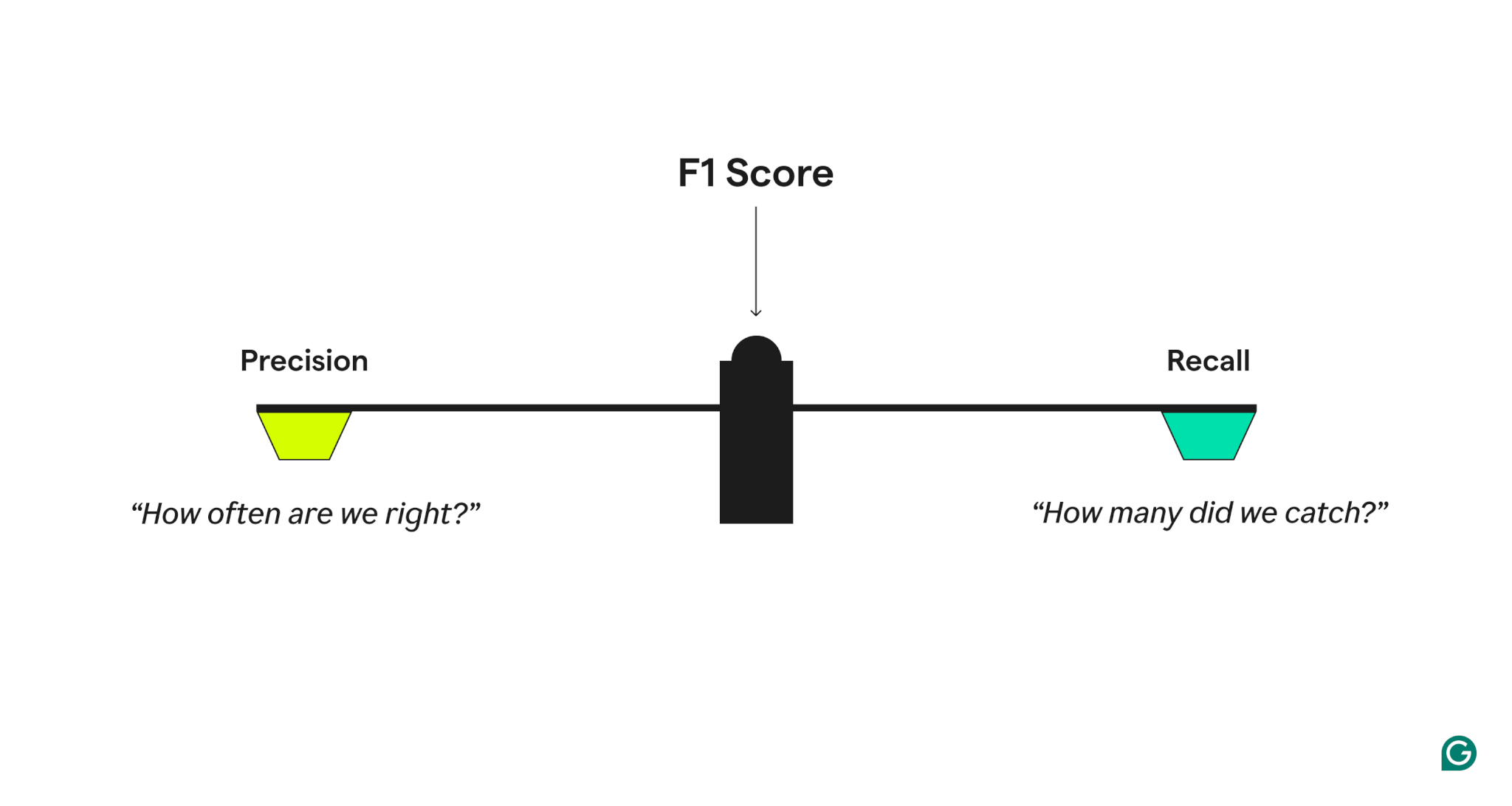
Precyzja i przywołania
Aby lepiej zrozumieć precyzję i przypomnieć, rozważ system wykrywania spamu. Jeśli system ma wysoki wskaźnik prawidłowo oznaczających e -maile jako spam, oznacza to, że ma wysoką precyzję. Na przykład, jeśli system określa 100 e -maili jako spam, a 90 z nich to faktycznie spam, precyzja wynosi 90%. Z drugiej strony wysokie wycofanie oznacza, że system łapie większość rzeczywistych e -maili spamowych. Na przykład, jeśli istnieje 200 rzeczywistych e -maili spamowych, a nasz system łapie 90 z nich, wycofanie wynosi 45%.
Warianty wyniku F1
W systemach klasyfikacji wieloklasowej lub scenariuszach o określonych potrzebach wynik F1 można obliczyć na różne sposoby, w zależności od tego, jakie czynniki są ważne:
- Macro-F1:Oblicza wynik F1 osobno dla każdej klasy i przyjmuje średnią
- Micro-F1:Oblicza przywołanie i precyzję na wszystkich prognozach
- WAVED-F1: Podobnie jak makro-f1, ale klasy są ważone na podstawie częstotliwości
Poza wynikiem F1: rodzina F-Score
Wynik F1 jest częścią większej rodziny wskaźników o nazwie F-Scores. Te wyniki oferują różne sposoby na wagę precyzji i wycofania:
- F2:kładzie większy nacisk na wycofanie, co jest przydatne, gdy fałszywe negatywy są kosztowne
- F0.5:Kładzie większy nacisk na precyzję, co jest przydatne, gdy fałszywe pozytywy są kosztowne
Jak obliczyć wynik F1
Wynik F1 jest matematycznie zdefiniowany jako średnia harmoniczna precyzji i wycofania. Chociaż może to zabrzmieć złożone, proces obliczeń jest prosty po podziwu na wyraźne kroki.
Formuła wyniku F1:

Przed zanurzeniem się w etapach obliczenia F1 ważne jest, aby zrozumieć kluczowe elementy tak zwanejmacierzy zamieszania, która służy do organizacji wyników klasyfikacji:
- Prawdziwe pozytywy (TP):Liczba przypadków poprawnie zidentyfikowanych jako pozytywna
- Fałszywe pozytywy (FP):Liczba przypadków niepoprawnie zidentyfikowanych jako pozytywna
- Fałszywe negatywy (FN):Liczba przypadków pominiętej (rzeczywiste pozytywne pozytywne, które nie zostały zidentyfikowane)
Ogólny proces obejmuje szkolenie modelu, testowanie prognoz i organizowanie wyników, obliczanie precyzji i wycofania oraz obliczenie wyniku F1.
Krok 1: Trenuj model klasyfikacyjny
Po pierwsze, należy wyszkolony model do tworzenia klasyfikacji binarnych lub wieloklasowych. Oznacza to, że model musi być w stanie klasyfikować przypadki jako należące do jednej z dwóch kategorii. Przykłady obejmują „spam/not spam” i „oszustwo/nie oszustwo”.
Krok 2: Prognozy testowe i zorganizuj wyniki
Następnie użyj modelu do wykonywania klasyfikacji na osobnym zestawie danych, który nie był używany w ramach szkolenia. Zorganizuj wyniki w macierzy zamieszania. Ta macierz pokazuje:
- TP: Ile prognoz było właściwych
- FP: Ile pozytywnych prognoz było nieprawidłowych
- FN: Ile pozytywnych przypadków pominięto
Matryca zamieszania zawiera przegląd działania modelu.
Krok 3: Oblicz precyzję
Za pomocą macierzy zamieszania obliczono precyzję w tym wzorze:

Na przykład, jeśli model wykrywania spamu poprawnie zidentyfikował 90 e -maili spamowych (TP), ale nieprawidłowo oznaczone 10 e -maili bezpamowych (FP), precyzja wynosi 0,90.

Krok 4: Oblicz wycofanie
Następnie oblicz przywołanie przy użyciu wzoru:

Korzystając z przykładu wykrywania spamu, jeśli było 200 e -maili spamowych, a model złapał 90 z nich (TP), brakując 110 (FN), przywołanie wynosi 0,45.

Krok 5: Oblicz wynik F1
Przy wartościach precyzji i przywołania można obliczyć wynik F1.
Wynik F1 wynosi od 0 do 1. Podczas interpretacji wyniku rozważ te ogólne punkty odniesienia:
- 0.9 lub wyższy:model działa świetnie, ale należy go sprawdzić pod kątem nadmiernego dopasowania.
- 0,7 do 0,9:Dobra wydajność dla większości aplikacji
- 0,5 do 0,7:Wydajność jest w porządku, ale model może użyć poprawy.
- 0,5 lub mniej:model działa słabo i wymaga poważnej poprawy.
Korzystając z przykładowych obliczeń detekcji spamu dla precyzji i wycofania, wynik F1 wyniósłby 0,60 lub 60%.


W tym przypadku wynik F1 wskazuje, że nawet przy wysokiej precyzji niższe wycofanie wpływa na ogólną wydajność. Sugeruje to, że istnieje miejsce na poprawę łapania większej liczby e -maili spamowych.
Wynik F1 vs.
Podczas gdy zarówno F1, jak i wydajność modelu kwantyfikowaniadokładności, wynik F1 zapewnia bardziej dopracowany miara. Dokładność po prostu oblicza procent prawidłowych prognoz. Jednak poleganie na dokładności pomiaru wydajności modelu może być problematyczne, gdy liczba instancji jednej kategorii w zestawie danych znacznie przewyższa drugą kategorię. Ten problem jest określany jakoparadoks dokładności.
Aby zrozumieć ten problem, rozważ przykład systemu wykrywania spamu. Załóżmy, że system e -mail odbiera 1000 e -maili dziennie, ale tylko 10 z nich to spam. Jeśli wykrywanie spamu po prostu klasyfikuje każdy e -mail jako nie spam, nadal osiągnie 99% dokładności. Wynika to z faktu, że 990 prognoz na 1000 było poprawnych, mimo że model jest w rzeczywistości bezużyteczny, jeśli chodzi o wykrywanie spamu. Oczywiście dokładność nie daje dokładnego obrazu jakości modelu.
Wynik F1 pozwala uniknąć tego problemu poprzez połączenie pomiarów precyzji i wycofania. Dlatego w następujących przypadkach należy użyć F1 zamiast dokładności:
- Zestaw danych jest niezrównoważony.Jest to powszechne w dziedzinach takich jak diagnoza niejasnych schorzeń lub wykrywanie spamu, gdzie jedna kategoria jest stosunkowo rzadka.
- Zarówno FN, jak i FP są ważne.Na przykład testy badań medycznych mają na celu zrównoważenie faktycznych problemów z nie podnoszeniem fałszywych alarmów.
- Model musi zachować równowagę między byciem zbyt agresywnym i zbyt ostrożnym.Na przykład w filtrowaniu spamu nadmiernie ostrożny filtr może pozwolić przez zbyt dużo spamu (niskie wycofanie), ale rzadko popełniają błędy (wysoka precyzja). Z drugiej strony zbyt agresywny filtr może blokować prawdziwe wiadomości e -mail (niską precyzję), nawet jeśli złapie cały spam (wysokie wycofanie).
Zastosowania wyniku F1
Wynik F1 ma szeroki zakres zastosowań w różnych branżach, w których zrównoważona klasyfikacja ma kluczowe znaczenie. Zastosowania te obejmują wykrywanie oszustw finansowych, diagnozę medyczną i moderację treści.
Wykrywanie oszustw finansowych
Modele zaprojektowane do wykrywania oszustw finansowych są kategorią systemów dobrze dostosowanych do pomiaru przy użyciu wyniku F1. Firmy finansowe często codziennie przetwarzają miliony lub miliardy transakcji, przy czym faktyczne przypadki oszustw są stosunkowo rzadkie. Z tego powodu system wykrywania oszustw musi złapać jak najwięcej fałszywych transakcji, jednocześnie minimalizując liczbę fałszywych alarmów i wynikające z tego niedogodności dla klientów. Mierzenie wyniku F1 może pomóc instytucjom finansowym w ustaleniu, jak dobrze ich systemy zrównoważyło podwójne filary zapobiegania oszustwom i dobrą obsługę klienta.
Diagnoza medyczna
W diagnozie medycznej i testowaniu zarówno FN, jak i FP mają poważne konsekwencje. Rozważ przykład modelu zaprojektowanego do wykrywania rzadkich form raka. Nieprawidłowe diagnozowanie zdrowego pacjenta może prowadzić do niepotrzebnego stresu i leczenia, podczas gdy brak faktycznego przypadku raka będzie miało straszne konsekwencje dla pacjenta. Innymi słowy, model musi mieć zarówno wysoką precyzję, jak i wysokie wycofanie, co może mierzyć wynik F1.
Moderacja treści
Moderowanie treści jest częstym wyzwaniem na forach internetowych, platformach społecznościowych i rynkach internetowych. Aby osiągnąć bezpieczeństwo platformy bez overcensoring, systemy te muszą zrównoważyć precyzję i wycofanie. Wynik F1 może pomóc platformom w określeniu, jak dobrze ich system równoważy te dwa czynniki.
Korzyści z wyniku F1
Oprócz ogólnie zapewniającego bardziej dopracowany widok wydajności modelu niż dokładność, wynik F1 zapewnia kilka kluczowych zalet przy ocenie wydajności modelu klasyfikacji. Korzyści te obejmują szybsze szkolenie i optymalizację modelu, obniżone koszty szkolenia i wczesne przełapanie.
Szybsze trening i optymalizacja modelu
Wynik F1 może pomóc przyspieszyć szkolenie modelu, zapewniając wyraźną metrykę odniesienia, którą można wykorzystać do optymalizacji. Zamiast strojenia wycofanie i precyzję osobno, co ogólnie obejmuje złożone kompromisy, praktykujący ML mogą skupić się na zwiększeniu wyniku F1. Dzięki temu usprawnionym podejściu optymalne parametry modelu można szybko zidentyfikować.
Obniżone koszty szkolenia
Wynik F1 może pomóc praktykom ML w podejmowaniu świadomych decyzji o tym, kiedy model jest gotowy do wdrożenia, zapewniając dopracowaną, pojedynczą miarę wydajności modelu. Dzięki tym informacjom praktykujący mogą uniknąć niepotrzebnych cykli szkoleniowych, inwestycji w zasoby obliczeniowe oraz konieczność pozyskiwania lub tworzenia dodatkowych danych szkoleniowych. Ogólnie rzecz biorąc, może to prowadzić do znacznych redukcji kosztów podczas modeli klasyfikacji szkolenia.
Złapanie wczesnego nadmiernego dopasowania
Ponieważ wynik F1 rozważa zarówno precyzję, jak i wycofanie, może pomóc praktykom ML w określeniu, kiedy model staje się zbyt wyspecjalizowany w danych szkoleniowych. Problem ten, zwany przepełnieniem, jest powszechnym problemem z modelami klasyfikacyjnymi. Wynik F1 daje praktykom wczesne ostrzeżenie, że muszą dostosować szkolenie, zanim model osiągnie punkt, w którym nie jest w stanie uogólniać danych w świecie rzeczywistym.
Ograniczenia wyniku F1
Pomimo wielu korzyści, wynik F1 ma kilka ważnych ograniczeń, które powinni rozważyć praktykujący. Ograniczenia te obejmują brak wrażliwości na prawdziwe negatywy, nie nadaje się do niektórych zestawów danych i trudniejszy do interpretacji problemów wieloklasowych.
Brak wrażliwości na prawdziwe negatywy
Wynik F1 nie uwzględnia prawdziwych negatywów, co oznacza, że nie jest odpowiedni do zastosowań, w których mierzenie jest ważne. Rozważmy na przykład system zaprojektowany do identyfikacji bezpiecznych warunków jazdy. W takim przypadku prawidłowe określenie, kiedy warunki są naprawdę bezpieczne (prawdziwe negatywy) jest równie ważne, jak identyfikacja niebezpiecznych warunków. Ponieważ nie śledzi FN, wynik F1 nie dokonałby dokładnie tego aspektu ogólnej wydajności modelu.
Nie nadaje się do niektórych zestawów danych
Wynik F1 może nie być odpowiedni do zestawów danych, w których wpływ FP i FN jest znacząco inny. Rozważ przykład modelu przesiewowego raka. W takiej sytuacji brak pozytywnego przypadku (FN) może zagrażać życiu, jednocześnie niesłuszne znalezienie pozytywnego przypadku (FP) prowadzi jedynie do dodatkowych testów. Zatem zastosowanie metryki, którą można ważić, aby uwzględnić ten koszt, jest lepszym wyborem niż wynik F1.
Trudniejsze do interpretacji problemów wieloklasowych
Podczas gdy zmiany takie jak wyniki Micro-F1 i Macro-F1 oznaczają, że wynik F1 można wykorzystać do oceny systemów klasyfikacji wieloklasowej, interpretacja tych zagregowanych wskaźników jest często bardziej złożona niż binarny wynik F1. Na przykład wynik Micro-F1 może ukryć słabą wydajność w klasyfikacji rzadszych klas, podczas gdy wynik makro-F1 może nadważyć rzadkie klasy. Biorąc to pod uwagę, firmy muszą rozważyć, czy równe leczenie klas, czy ogólna wydajność na poziomie instancji jest ważniejsze przy wyborze odpowiedniego wariantu F1 dla modeli klasyfikacji wieloklasowej.