
Uczenie maszynowe 101: co to jest i jak działa
Opublikowany: 2024-05-23Uczenie maszynowe (ML) szybko stało się jedną z najważniejszych technologii naszych czasów. Jest podstawą produktów takich jak ChatGPT, rekomendacje Netflix, samochody autonomiczne i filtry spamu e-mailowego. Aby pomóc Ci zrozumieć tę wszechobecną technologię, w tym przewodniku omówiono, czym jest ML (a czym nie jest), jak działa i jaki ma wpływ.
Spis treści
- Co to jest uczenie maszynowe?
- Jak działa uczenie maszynowe
- Rodzaj uczenia maszynowego
- Aplikacje
- Zalety
- Niedogodności
- Przyszłość ML
- Wniosek
Co to jest uczenie maszynowe?
Aby zrozumieć uczenie maszynowe, musimy najpierw zrozumieć sztuczną inteligencję (AI). Chociaż te dwa słowa są używane zamiennie, nie są tym samym. Sztuczna inteligencja jest zarówno celem, jak i kierunkiem badań. Celem jest zbudowanie systemów komputerowych zdolnych do myślenia i rozumowania na poziomie ludzkim (a nawet nadludzkim). Sztuczna inteligencja obejmuje również wiele różnych metod osiągnięcia tego celu. Uczenie maszynowe jest jedną z tych metod, co czyni je podzbiorem sztucznej inteligencji.
Uczenie maszynowe skupia się w szczególności na wykorzystaniu danych i statystyk w dążeniu do sztucznej inteligencji. Celem jest stworzenie inteligentnych systemów, które mogą się uczyć na podstawie licznych przykładów (danych) i które nie wymagają bezpośredniego programowania. Mając wystarczającą ilość danych i dobry algorytm uczenia się, komputer wychwytuje wzorce zawarte w danych i poprawia swoją wydajność.
W przeciwieństwie do tego, podejścia do sztucznej inteligencji inne niż ML nie zależą od danych i mają wpisaną na stałe logikę. Można na przykład stworzyć bota AI grającego w kółko i krzyżyk o nadludzkiej wydajności, po prostu kodując wszystkie optymalne ruchy (istnieją 255 168 możliwych gier w kółko i krzyżyk, więc zajęłoby to trochę czasu, ale nadal jest możliwe). Niemożliwe byłoby jednak zakodowanie szachowego bota AI – istnieje więcej możliwych partii szachowych niż atomów we wszechświecie. W takich przypadkach ML sprawdzi się lepiej.
Rozsądnym pytaniem w tym miejscu jest, w jaki sposób komputer poprawia się, jeśli podasz mu przykłady?
Jak działa uczenie maszynowe
W każdym systemie ML potrzebne są trzy rzeczy: zbiór danych, model ML (przykładem jest GPT) i algorytm uczący. Najpierw przekazujesz przykłady ze zbioru danych. Następnie model przewiduje właściwy wynik dla tego przykładu. Jeśli model jest błędny, stosuje się algorytm uczący, aby zwiększyć prawdopodobieństwo, że model będzie poprawny w przypadku podobnych przykładów w przyszłości. Powtarzasz ten proces, aż skończą Ci się dane lub będziesz zadowolony z wyników. Po zakończeniu tego procesu możesz użyć swojego modelu do przewidywania przyszłych danych.
Podstawowym przykładem tego procesu jest nauczenie komputera rozpoznawania cyfr pisanych odręcznie, takich jak te poniżej.
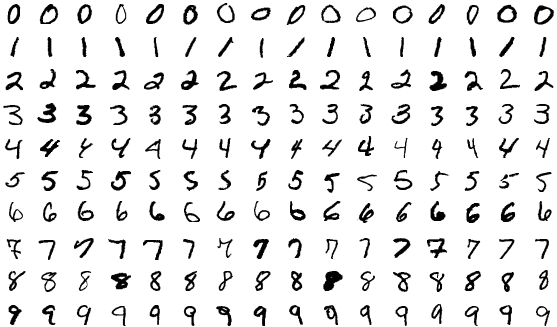
Źródło
Zbierasz tysiące lub setki tysięcy zdjęć cyfr. Zaczynasz od modelu ML, który nie widział jeszcze żadnych przykładów. Wprowadzasz obrazy do modelu i prosisz go, aby przewidział, jaka liczba według niego znajduje się na obrazie. Zwróci liczbę od zera do dziewięciu, powiedzmy jeden. Następnie w zasadzie mówisz: „Ta liczba to tak naprawdę pięć, a nie jeden”. Algorytm uczący aktualizuje model, więc następnym razem będzie bardziej prawdopodobne, że odpowie liczbą pięć. Powtarzasz ten proces dla (prawie) wszystkich dostępnych zdjęć i w idealnym przypadku masz dobrze działający model, który potrafi poprawnie rozpoznawać cyfry w 90% przypadków. Teraz możesz używać tego modelu do odczytywania milionów cyfr na dużą skalę szybciej niż byłby to w stanie zrobić człowiek. W praktyce Poczta Stanów Zjednoczonych wykorzystuje modele ML do odczytania 98% adresów pisanych odręcznie.
Możesz spędzić miesiące lub lata analizując szczegóły nawet niewielkiej części tego procesu (zobacz, ile istnieje różnych wersji algorytmów optymalizacyjnych).
Typowe typy uczenia maszynowego
W rzeczywistości istnieją cztery różne typy metod uczenia maszynowego: nadzorowane, bez nadzoru, częściowo nadzorowane i ze wzmocnieniem. Główna różnica polega na sposobie oznaczania danych (tzn. z poprawną odpowiedzią lub bez).
Nadzorowana nauka
Modele uczenia się nadzorowanego otrzymują oznaczone dane (z poprawnymi odpowiedziami). Przykład odręcznie zapisanych cyfr należy do tej kategorii: Możemy powiedzieć modelowi: „Pięć to właściwa odpowiedź”. Model ma na celu poznanie wyraźnych powiązań między wejściami i wyjściami. Modele te mogą generować albo oddzielne etykiety (np. przewidywać „kot” lub „pies” na podstawie zdjęcia zwierzaka), albo liczby (np. przewidywaną cenę domu na podstawie liczby łóżek, łazienek, lokalizacji itp.). .
Uczenie się bez nadzoru
Modele uczenia się bez nadzoru otrzymują dane bez etykiet (bez poprawnych odpowiedzi). Modele te identyfikują wzorce w danych wejściowych w celu sensownego grupowania danych. Na przykład, biorąc pod uwagę wiele obrazów kotów i psów bez prawidłowej odpowiedzi, model ML bez nadzoru będzie sprawdzał podobieństwa i różnice w obrazach, aby pogrupować obrazy psów i kotów. Klastrowanie, reguły asocjacji i redukcja wymiarowości to podstawowe metody w nienadzorowanym uczeniu maszynowym.
Uczenie się częściowo nadzorowane
Uczenie się częściowo nadzorowane to podejście do uczenia maszynowego, które leży pomiędzy uczeniem się nadzorowanym i bez nadzoru. Ta metoda zapewnia znaczną ilość danych bez etykiet i mniejszy zestaw danych z etykietami do szkolenia modelu. Najpierw model jest szkolony na danych oznaczonych etykietami, a następnie przypisuje etykiety do danych bez etykiet, porównując ich podobieństwo z danymi oznaczonymi etykietami.
Uczenie się przez wzmacnianie
Uczenie się przez wzmacnianie nie ma określonego zestawu przykładów i etykiet. Zamiast tego model otrzymuje środowisko (np. gry są popularne), funkcję nagrody i cel. Model uczy się osiągać cel metodą prób i błędów. Wykona akcję, a funkcja nagrody powie mu, czy akcja ta pomoże osiągnąć nadrzędny cel. Następnie model aktualizuje się, aby wykonać mniej więcej tę czynność. Model może nauczyć się osiągać cel, robiąc to wielokrotnie.
Znanym przykładem modelu uczenia się przez wzmacnianie jest AlphaGo Zero. Model ten został wyszkolony do wygrywania gier w Go i otrzymał jedynie stan planszy Go. Następnie rozegrał miliony gier przeciwko sobie, z czasem ucząc się, które ruchy dawały mu przewagę, a które nie. Osiągnął nadludzki poziom wydajności w ciągu 70 godzin treningu, przewyższając mistrzów świata w Go.
Samonadzorowane uczenie się
W rzeczywistości istnieje piąty rodzaj uczenia maszynowego, który stał się ostatnio ważny: uczenie się samonadzorowane. Samonadzorowane modele uczenia się otrzymują dane bez etykiet, ale uczą się tworzyć etykiety na podstawie tych danych. Leży to u podstaw modeli GPT stojących za ChatGPT. Podczas szkolenia GPT model ma na celu przewidzenie następnego słowa na podstawie wejściowego ciągu słów. Weźmy na przykład zdanie „Kot usiadł na macie”. GPT otrzymuje „The” i jest proszony o przewidzenie, jakie słowo będzie następne. Przewiduje (powiedzmy „pies”), ale ponieważ ma oryginalne zdanie, wie, jaka jest prawidłowa odpowiedź: „kot”. Następnie GPT otrzymuje „kota” i zostaje poproszony o przewidzenie następnego słowa i tak dalej. W ten sposób może nauczyć się wzorców statystycznych między słowami i nie tylko.
Zastosowania uczenia maszynowego
Każdy problem lub branża, która ma dużo danych, może skorzystać z ML. Wiele branż odnotowało dzięki temu niezwykłe rezultaty i stale pojawia się więcej przypadków użycia. Oto kilka typowych przypadków użycia ML:
Pismo
ML modeluje produkty do pisania wykorzystujące sztuczną inteligencję, takie jak Grammarly. Dzięki szkoleniu w zakresie dużej liczby świetnych tekstów Grammarly może utworzyć dla Ciebie wersję roboczą, pomóc Ci w przepisaniu i dopracowaniu oraz przeprowadzić z Tobą burzę mózgów na temat pomysłów, a wszystko to w preferowanym przez Ciebie tonie i stylu.

Rozpoznawanie mowy
Siri, Alexa i wersja głosowa ChatGPT zależą od modeli ML. Modele te są szkolone na wielu przykładach audio wraz z odpowiednimi poprawnymi transkrypcjami. Dzięki tym przykładom modele mogą przekształcić mowę w tekst. Bez ML problem ten byłby prawie niemożliwy do rozwiązania, ponieważ każdy ma inny sposób mówienia i wymowy. Nie sposób wyliczyć wszystkich możliwości.
Zalecenia
Za Twoimi kanałami na TikTok, Netflix, Instagramie i Amazonie kryją się modele rekomendacji ML. Modele te są szkolone na wielu przykładach preferencji (np. osobom takim jak Ty podobał się ten film zamiast tamtego, ten produkt zamiast tamtego), aby pokazać Ci elementy i treści, które chcesz zobaczyć. Z biegiem czasu modele mogą również uwzględniać Twoje specyficzne preferencje, aby stworzyć kanał, który będzie specjalnie dla Ciebie atrakcyjny.
Wykrywanie oszustw
Banki wykorzystują modele ML do wykrywania oszustw związanych z kartami kredytowymi. Dostawcy poczty e-mail korzystają z modeli ML do wykrywania i przekierowywania spamu. Modele oszustw ML zawierają wiele przykładów fałszywych danych; modele te następnie uczą się wzorców wśród danych, aby zidentyfikować oszustwa w przyszłości.
Samochody autonomiczne
Samochody autonomiczne wykorzystują technologię ML do interpretacji dróg i poruszania się po nich. ML pomaga samochodom identyfikować pieszych i pasy ruchu, przewidywać ruch innych samochodów i decydować o kolejnym działaniu (np. przyspieszyć, zmienić pas itp.). Samochody autonomiczne zdobywają biegłość poprzez szkolenie na miliardach przykładów z wykorzystaniem metod ML.
Zalety uczenia maszynowego
Dobrze wykonane, uczenie maszynowe może mieć charakter transformacyjny. Modele uczenia maszynowego mogą ogólnie sprawić, że procesy będą tańsze, lepsze lub jedno i drugie.
Efektywność kosztów pracy
Wyszkolone modele ML mogą symulować pracę eksperta za ułamek kosztów. Na przykład doświadczony pośrednik w handlu nieruchomościami ma doskonałą intuicję, jeśli chodzi o koszt domu, ale może to wymagać lat szkolenia. Zatrudnienie wyspecjalizowanych pośredników w obrocie nieruchomościami (i wszelkiego rodzaju ekspertów) jest również drogie. Jednak model uczenia maszynowego wyszkolony na milionach przykładów mógłby zbliżyć się do wydajności doświadczonego pośrednika w handlu nieruchomościami. Taki model można wyszkolić w ciągu kilku dni, a jego użycie będzie znacznie tańsze. Mniej doświadczeni pośrednicy w handlu nieruchomościami mogą następnie wykorzystać te modele, aby wykonać więcej pracy w krótszym czasie.
Efektywność czasowa
Modele ML nie są ograniczone czasem w takim samym stopniu jak ludzie. AlphaGo Zero rozegrało4,9 miliona gierw Go w ciągu trzech dni szkolenia . Zajęłoby to ludziom lata, jeśli nie dekady. Dzięki tej skalowalności model był w stanie zbadać szeroką gamę ruchów i pozycji Go, co doprowadziło do nadludzkiej wydajności. Modele ML potrafią nawet wychwycić wzorce, które przeoczają eksperci; AlphaGo Zero nawet znalazł i wykorzystał ruchy, które zwykle nie są wykonywane przez ludzi. Nie oznacza to jednak, że eksperci nie są już wartościowi; Eksperci Go stali się znacznie lepsi, używając modeli takich jak AlphaGo do wypróbowywania nowych strategii.
Wady uczenia maszynowego
Oczywiście istnieją również wady stosowania modeli ML. Mianowicie są drogie w szkoleniu, a ich wyników nie można łatwo wytłumaczyć.
Drogie szkolenie
Szkolenia ML mogą być drogie. Na przykład opracowanie AlphaGo Zero kosztowało 25 milionów dolarów, a GPT-4 ponad 100 milionów dolarów. Główne koszty opracowywania modeli uczenia maszynowego to etykietowanie danych, wydatki na sprzęt i wynagrodzenia pracowników.
Świetnie nadzorowane modele uczenia maszynowego wymagają milionów oznaczonych przykładów, z których każdy musi zostać oznaczony przez człowieka. Po zebraniu wszystkich etykiet potrzebny jest specjalistyczny sprzęt do wytrenowania modelu. Jednostki przetwarzania grafiki (GPU) i jednostki przetwarzania tensoru (TPU) są standardem w sprzęcie ML, a ich wypożyczenie lub zakup może być drogi — zakup procesorów graficznych może kosztować od tysięcy do dziesiątków tysięcy dolarów.
Wreszcie opracowanie doskonałych modeli uczenia maszynowego wymaga zatrudniania badaczy lub inżynierów zajmujących się uczeniem maszynowym, którzy mogą wymagać wysokich wynagrodzeń ze względu na swoje umiejętności i wiedzę specjalistyczną.
Ograniczona przejrzystość w podejmowaniu decyzji
W przypadku wielu modeli ML nie jest jasne, dlaczego dają takie wyniki, jakie dają. AlphaGo Zero nie potrafi wyjaśnić powodów podjęcia decyzji; wie, że dany ruch będzie skuteczny w konkretnej sytuacji, ale nie wiedlaczego. Może to mieć istotne konsekwencje, gdy modele ML są wykorzystywane w codziennych sytuacjach. Modele uczenia maszynowego stosowane w opiece zdrowotnej mogą dawać nieprawidłowe lub stronnicze wyniki, o czym możemy nie wiedzieć, ponieważ przyczyna uzyskanych wyników jest niejasna. Ogólnie rzecz biorąc, błąd jest poważnym problemem w modelach uczenia maszynowego, a brak możliwości wyjaśnienia sprawia, że trudniej jest uporać się z problemem. Problemy te dotyczą zwłaszcza modeli głębokiego uczenia się. Modele głębokiego uczenia się to modele uczenia maszynowego, które wykorzystują wielowarstwowe sieci neuronowe do przetwarzania danych wejściowych. Są w stanie obsłużyć bardziej skomplikowane dane i pytania.
Z drugiej strony prostsze, bardziej „płytkie” modele uczenia maszynowego (takie jak drzewa decyzyjne i modele regresji) nie mają tych samych wad. Nadal wymagają dużej ilości danych, ale w przeciwnym razie ich szkolenie jest tanie. Są też bardziej zrozumiałe. Wadą jest to, że takie modele mogą mieć ograniczoną użyteczność; zaawansowane aplikacje, takie jak GPT, wymagają bardziej złożonych modeli.
Przyszłość uczenia maszynowego
Modele ML oparte na transformatorach cieszą się ogromną popularnością od kilku lat. Jest to specyficzny typ modelu ML obsługujący GPT (t w GPT), gramatykę i Claude AI. Zwrócono uwagę również na modele ML oparte na dyfuzji, które zasilają produkty do tworzenia obrazu, takie jak DALL-E i Midjourney.
Nie wydaje się, aby ten trend miał się szybko zmienić. Firmy ML koncentrują się na zwiększaniu rozmiaru swoich modeli — większych modeli, które mają lepsze możliwości i większe zbiory danych, na których można je szkolić. Na przykład GPT-4 miał 10 razy większą liczbę parametrów modelu niż GPT-3. Prawdopodobnie jeszcze więcej branż zastosuje generatywną sztuczną inteligencję w swoich produktach, aby zapewnić użytkownikom spersonalizowane doświadczenia.
Robotyka również nabiera tempa. Naukowcy wykorzystują uczenie maszynowe do tworzenia robotów, które mogą poruszać się i używać obiektów takich jak ludzie. Roboty te mogą eksperymentować w swoim otoczeniu i wykorzystywać uczenie się przez wzmacnianie, aby szybko dostosowywać się i osiągać swoje cele — na przykład kopać piłkę nożną.
Jednakże w miarę jak modele uczenia się maszyn stają się coraz potężniejsze i bardziej wszechobecne, pojawiają się obawy co do ich potencjalnego wpływu na społeczeństwo. Kwestie takie jak uprzedzenia, prywatność i przenoszenie stanowisk są przedmiotem gorących dyskusji, a także rośnie uznanie potrzeby opracowania wytycznych etycznych i praktyk odpowiedzialnego rozwoju.
Wniosek
Uczenie maszynowe to podzbiór sztucznej inteligencji, którego wyraźnym celem jest tworzenie inteligentnych systemów poprzez umożliwienie im uczenia się na podstawie danych. Uczenie się nadzorowane, bez nadzoru, częściowo nadzorowane i uczenie się przez wzmacnianie to główne typy uczenia się uczenia się (obok uczenia się samonadzorowanego). ML stanowi podstawę wielu nowych produktów, które pojawią się dzisiaj, takich jak ChatGPT, samochody autonomiczne i rekomendacje Netflix. Może być tańsze lub lepsze od wydajności człowieka, ale jednocześnie jest początkowo kosztowne i trudniejsze do wyjaśnienia i sterowania. W ciągu najbliższych kilku lat ML będzie jeszcze bardziej popularne.
ML ma wiele zawiłości, a możliwości uczenia się i wnoszenia wkładu w tę dziedzinę stale się poszerzają. W szczególności przewodniki Grammarly dotyczące sztucznej inteligencji, głębokiego uczenia się i ChatGPT mogą pomóc Ci dowiedzieć się więcej o innych ważnych częściach tej dziedziny. Poza tym zapoznanie się ze szczegółami ML (takimi jak gromadzenie danych, jak faktycznie wyglądają modele i algorytmy stojące za „uczeniem się”) może pomóc w skutecznym włączeniu go do swojej pracy.
Ponieważ ML stale się rozwija i oczekuje się, że dotknie niemal każdej branży, teraz jest czas, aby rozpocząć swoją przygodę z ML!