
Czym jest nadmierne dopasowanie w uczeniu maszynowym?
Opublikowany: 2024-10-15Nadmierne dopasowanie to częsty problem pojawiający się podczas uczenia modeli uczenia maszynowego (ML). Może to negatywnie wpłynąć na zdolność modelu do uogólniania danych wykraczających poza dane szkoleniowe, prowadząc do niedokładnych przewidywań w rzeczywistych scenariuszach. W tym artykule przyjrzymy się, czym jest nadmierne dopasowanie, jak do niego dochodzi, jakie są jego najczęstsze przyczyny oraz jakie są skuteczne sposoby jego wykrywania i zapobiegania.
Spis treści
- Co to jest nadmierne dopasowanie?
- Jak dochodzi do nadmiernego dopasowania
- Nadmierne dopasowanie a niedostateczne dopasowanie
- Co powoduje nadmierne dopasowanie?
- Jak wykryć nadmierne dopasowanie
- Jak uniknąć przetrenowania
- Przykłady nadmiernego dopasowania
Co to jest nadmierne dopasowanie?
Nadmierne dopasowanie ma miejsce, gdy model uczenia maszynowego uczy się podstawowych wzorców i szumów w danych szkoleniowych, stając się nadmiernie wyspecjalizowanym w tym konkretnym zbiorze danych. To nadmierne skupienie się na szczegółach danych uczących skutkuje słabą wydajnością, gdy model jest stosowany do nowych, niewidocznych danych, ponieważ nie pozwala na uogólnianie wykraczające poza dane, na których był szkolony.
Jak dochodzi do nadmiernego dopasowania?
Do nadmiernego dopasowania dochodzi, gdy model uczy się zbyt wiele na podstawie konkretnych szczegółów i szumu danych uczących, przez co staje się zbyt wrażliwy na wzorce, które nie mają znaczenia dla uogólnienia. Rozważmy na przykład model zbudowany w celu przewidywania wydajności pracowników na podstawie ocen historycznych. Jeśli model będzie nadmiernie dopasowany, może zbytnio skupiać się na konkretnych, niemożliwych do uogólnienia szczegółach, takich jak unikalny styl oceniania byłego menedżera lub szczególne okoliczności podczas poprzedniego cyklu przeglądu. Zamiast uczyć się szerszych, znaczących czynników wpływających na wyniki – takich jak umiejętności, doświadczenie czy wyniki projektu – model może mieć trudności z zastosowaniem swojej wiedzy w przypadku nowych pracowników lub ewolucją kryteriów oceny. Prowadzi to do mniej dokładnych przewidywań, gdy model jest stosowany do danych różniących się od zbioru uczącego.
Nadmierne dopasowanie a niedostateczne dopasowanie
W przeciwieństwie do nadmiernego dopasowania, niedopasowanie występuje, gdy model jest zbyt prosty, aby uchwycić podstawowe wzorce w danych. W rezultacie słabo radzi sobie ze szkoleniem i nowymi danymi, przez co nie pozwala na dokładne przewidywanie.
Aby zobrazować różnicę między niedostatecznym a nadmiernym dopasowaniem, wyobraźmy sobie, że próbujemy przewidzieć wyniki sportowe na podstawie poziomu stresu danej osoby. Możemy wykreślić dane i pokazać trzy modele, które próbują przewidzieć tę zależność:

1 Niedopasowanie:W pierwszym przykładzie model wykorzystuje linię prostą do tworzenia prognoz, podczas gdy rzeczywiste dane przebiegają według krzywej. Model jest zbyt prosty i nie oddaje złożoności związku pomiędzy poziomem stresu a wynikami sportowymi. W rezultacie przewidywania są w większości niedokładne, nawet w przypadku danych uczących. To jest niedopasowane.
2Optymalne dopasowanie:drugi przykład pokazuje model, który zapewnia właściwą równowagę. Pozwala uchwycić podstawowy trend danych bez nadmiernego ich komplikowania. Model ten dobrze uogólnia nowe dane, ponieważ nie próbuje dopasować każdej najmniejszej zmiany w danych uczących – jedynie podstawowy wzorzec.
3Nadmierne dopasowanie:W ostatnim przykładzie model wykorzystuje bardzo złożoną, falistą krzywą, aby dopasować ją do danych uczących. Chociaż ta krzywa jest bardzo dokładna w przypadku danych szkoleniowych, wychwytuje również losowy szum i wartości odstające, które nie reprezentują rzeczywistej zależności. Model ten jest nadmiernie dopasowany, ponieważ jest tak dobrze dostrojony do danych uczących, że prawdopodobnie będzie formułował słabe przewidywania na podstawie nowych, niewidocznych danych.
Najczęstsze przyczyny nadmiernego dopasowania
Teraz, gdy wiemy, czym jest nadmierne dopasowanie i dlaczego tak się dzieje, przyjrzyjmy się bardziej szczegółowo niektórym typowym przyczynom:
- Niewystarczające dane szkoleniowe
- Niedokładne, błędne lub nieistotne dane
- Duże ciężary
- Przetrenowanie
- Architektura modelu jest zbyt wyrafinowana
Niewystarczające dane szkoleniowe
Jeśli zbiór danych szkoleniowych jest zbyt mały, może reprezentować tylko niektóre scenariusze, z którymi model spotka się w świecie rzeczywistym. Podczas uczenia model może dobrze pasować do danych. Jednak po przetestowaniu go na innych danych możesz zauważyć znaczne niedokładności. Mały zbiór danych ogranicza zdolność modelu do uogólniania niewidocznych sytuacji, co czyni go podatnym na nadmierne dopasowanie.
Niedokładne, błędne lub nieistotne dane
Nawet jeśli zbiór danych szkoleniowych jest duży, może zawierać błędy. Błędy te mogą wynikać z różnych źródeł, takich jak podanie przez uczestników fałszywych informacji w ankietach lub błędne odczyty czujników. Jeśli model będzie próbował uczyć się na tych niedokładnościach, dostosuje się do wzorców, które nie odzwierciedlają prawdziwych zależności leżących u jego podstaw, co prowadzi do nadmiernego dopasowania.
Duże ciężary
W modelach uczenia maszynowego wagi to wartości liczbowe, które reprezentują znaczenie przypisane konkretnym cechom danych podczas dokonywania prognoz. Kiedy wagi staną się nieproporcjonalnie duże, model może się nadmiernie dopasować, stając się nadmiernie wrażliwym na pewne cechy, w tym szum w danych. Dzieje się tak, ponieważ model staje się zbyt zależny od konkretnych cech, co szkodzi jego zdolności do uogólniania na nowe dane.
Przetrenowanie
Podczas uczenia algorytm przetwarza dane partiami, oblicza błąd dla każdej partii i dostosowuje wagi modelu, aby poprawić jego dokładność.
Czy dobrym pomysłem jest kontynuowanie treningów tak długo, jak to możliwe? Nie bardzo! Długotrwałe uczenie tych samych danych może spowodować, że model zapamiętuje określone punkty danych, ograniczając jego zdolność do uogólniania na nowe lub niewidoczne dane, co jest istotą nadmiernego dopasowania. Ten typ nadmiernego dopasowania można złagodzić, stosując techniki wczesnego zatrzymywania lub monitorując działanie modelu na zestawie walidacyjnym podczas uczenia. Jak to działa, omówimy w dalszej części artykułu.

Architektura modelu jest zbyt złożona
Architektura modelu uczenia maszynowego odnosi się do struktury jego warstw i neuronów oraz do sposobu, w jaki współdziałają one w celu przetwarzania informacji.
Bardziej złożone architektury mogą przechwytywać szczegółowe wzorce w danych szkoleniowych. Jednak ta złożoność zwiększa prawdopodobieństwo nadmiernego dopasowania, ponieważ model może również nauczyć się wychwytywać szum lub nieistotne szczegóły, które nie przyczyniają się do dokładnych przewidywań na podstawie nowych danych. Uproszczenie architektury lub zastosowanie technik regularyzacji może pomóc zmniejszyć ryzyko nadmiernego dopasowania.
Jak wykryć nadmierne dopasowanie
Wykrycie nadmiernego dopasowania może być trudne, ponieważ podczas treningu może wydawać się, że wszystko idzie dobrze, nawet jeśli dochodzi do nadmiernego dopasowania. Współczynnik strat (lub błędów) – miara tego, jak często model jest błędny – będzie nadal spadać, nawet w scenariuszu nadmiernego dopasowania. Jak więc możemy sprawdzić, czy doszło do nadmiernego dopasowania? Potrzebujemy wiarygodnego testu.
Jedną ze skutecznych metod jest użycie krzywej uczenia się, czyli wykresu śledzącego miarę zwaną stratą. Strata reprezentuje wielkość błędu popełnianego przez model. Jednakże nie tylko śledzimy utratę danych szkoleniowych; mierzymy również stratę na niewidocznych danych, zwanych danymi walidacyjnymi. Właśnie dlatego krzywa uczenia się ma zazwyczaj dwie linie: utratę szkolenia i utratę walidacji.
Jeśli straty szkoleniowe nadal maleją zgodnie z oczekiwaniami, ale straty walidacyjne rosną, sugeruje to nadmierne dopasowanie. Innymi słowy, model staje się nadmiernie wyspecjalizowany w zakresie danych uczących i ma trudności z uogólnianiem go na nowe, niewidoczne dane. Krzywa uczenia się może wyglądać mniej więcej tak:
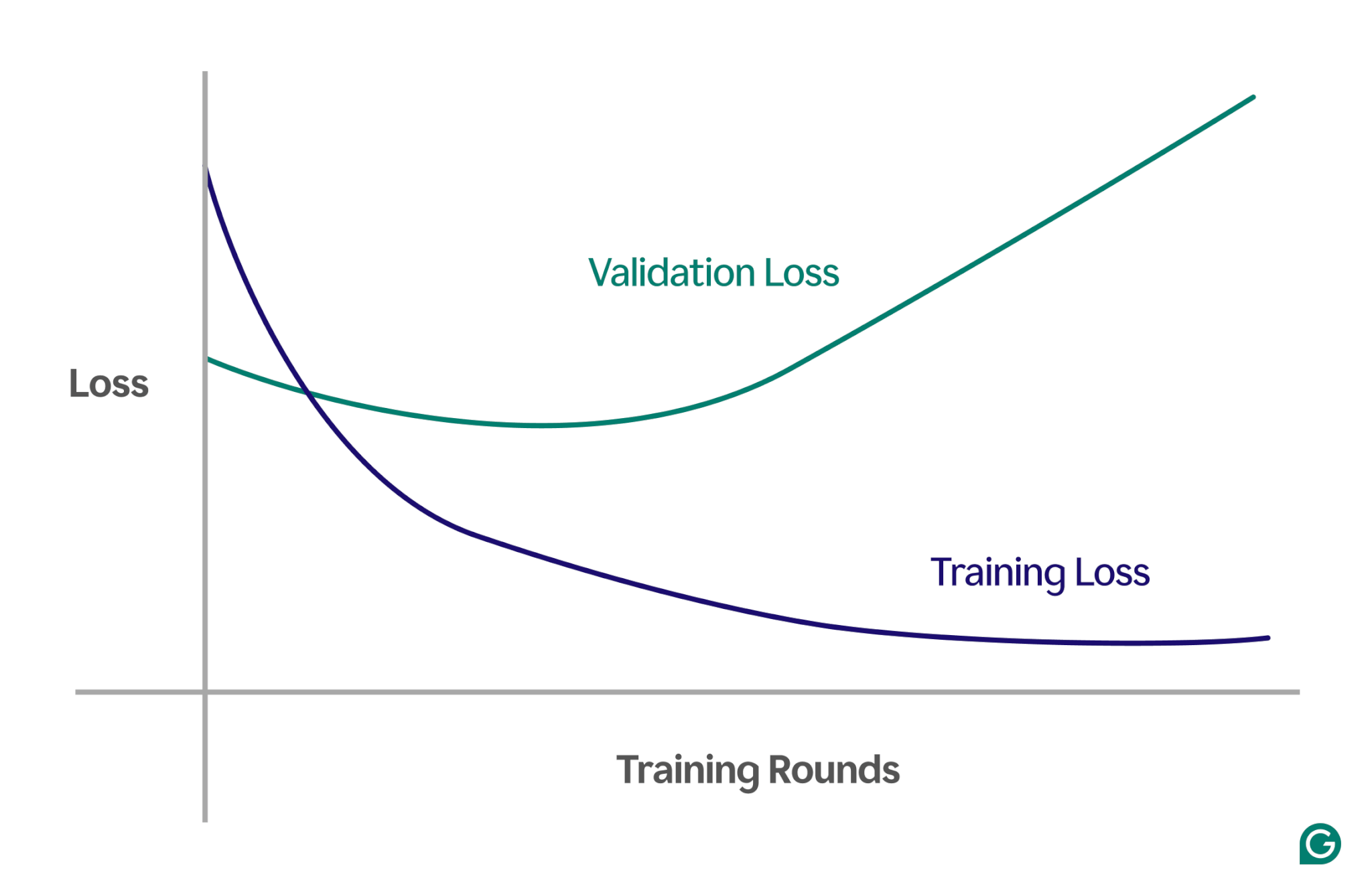
W tym scenariuszu, chociaż model poprawia się podczas uczenia, działa słabo w przypadku niewidocznych danych. Prawdopodobnie oznacza to, że nastąpiło nadmierne dopasowanie.
Jak uniknąć przetrenowania
Nadmiernemu dopasowaniu można zaradzić za pomocą kilku technik. Oto niektóre z najpopularniejszych metod:
Zmniejsz rozmiar modelu
Większość architektur modeli umożliwia dostosowanie liczby wag poprzez zmianę liczby warstw, rozmiarów warstw i innych parametrów znanych jako hiperparametry. Jeśli złożoność modelu powoduje nadmierne dopasowanie, pomocne może być zmniejszenie jego rozmiaru. Uproszczenie modelu poprzez zmniejszenie liczby warstw lub neuronów może zmniejszyć ryzyko nadmiernego dopasowania, ponieważ model będzie miał mniej możliwości zapamiętywania danych uczących.
Ureguluj model
Regularyzacja polega na modyfikowaniu modelu w celu zniechęcenia do stosowania dużych ciężarów. Jednym z podejść jest dostosowanie funkcji straty tak, aby mierzyła błąd i uwzględniała wielkość wag.
Dzięki regularyzacji algorytm uczący minimalizuje zarówno błąd, jak i wielkość wag, zmniejszając prawdopodobieństwo stosowania dużych wag, chyba że zapewniają one wyraźną przewagę modelowi. Pomaga to zapobiegać nadmiernemu dopasowaniu poprzez utrzymywanie bardziej uogólnionego modelu.
Dodaj więcej danych treningowych
Zwiększenie rozmiaru zbioru danych szkoleniowych może również pomóc w zapobieganiu nadmiernemu dopasowaniu. Im więcej danych, tym mniejsze jest prawdopodobieństwo, że na model będą miały wpływ szumy lub niedokładności w zbiorze danych. Wystawienie modelu na bardziej zróżnicowane przykłady sprawi, że będzie on mniej skłonny do zapamiętywania poszczególnych punktów danych i zamiast tego będzie uczył się szerszych wzorców.
Zastosuj redukcję wymiarowości
Czasami dane mogą zawierać skorelowane cechy (lub wymiary), co oznacza, że kilka cech jest w jakiś sposób powiązanych. Modele uczenia maszynowego traktują wymiary jako niezależne, więc jeśli funkcje są skorelowane, model może zbytnio się na nich skupiać, co prowadzi do nadmiernego dopasowania.
Techniki statystyczne, takie jak analiza głównych składowych (PCA), mogą zmniejszyć te korelacje. PCA upraszcza dane, zmniejszając liczbę wymiarów i usuwając korelacje, zmniejszając prawdopodobieństwo nadmiernego dopasowania. Koncentrując się na najbardziej istotnych cechach, model lepiej radzi sobie z generalizacją na nowe dane.
Praktyczne przykłady overfittingu
Aby lepiej zrozumieć nadmierne dopasowanie, przeanalizujmy kilka praktycznych przykładów z różnych dziedzin, w których nadmierne dopasowanie może prowadzić do mylących wyników.
Klasyfikacja obrazu
Klasyfikatory obrazów służą do rozpoznawania obiektów na obrazach — na przykład tego, czy obraz przedstawia ptaka, czy psa.
Inne szczegóły mogą mieć związek z tym, co próbujesz wykryć na tych zdjęciach. Na przykład zdjęcia psów często mogą mieć w tle trawę, a zdjęcia ptaków często mogą mieć w tle niebo lub korony drzew.
Jeśli wszystkie obrazy szkoleniowe mają spójne szczegóły tła, model uczenia maszynowego może zacząć rozpoznawać zwierzę na podstawie tła, zamiast koncentrować się na rzeczywistych cechach samego zwierzęcia. W rezultacie, gdy model zostanie poproszony o sklasyfikowanie zdjęcia ptaka siedzącego na trawniku, może błędnie zaklasyfikować go jako psa, ponieważ jest nadmiernie dopasowany do informacji tła. Jest to przypadek nadmiernego dopasowania do danych uczących.
Modelowanie finansowe
Załóżmy, że w wolnym czasie handlujesz akcjami i uważasz, że można przewidzieć zmiany cen na podstawie trendów wyszukiwania określonych słów kluczowych w Google. Konfigurujesz model uczenia maszynowego, korzystając z danych Trendów Google dla tysięcy słów.
Ponieważ jest tak wiele słów, niektóre prawdopodobnie wykażą korelację z cenami akcji wyłącznie przez przypadek. Model może nadmiernie dopasować te przypadkowe korelacje, powodując słabe prognozy przyszłych danych, ponieważ słowa nie są odpowiednimi predyktorami cen akcji.
Budując modele dla aplikacji finansowych, ważne jest zrozumienie podstaw teoretycznych relacji zachodzących w danych. Wprowadzanie do modelu dużych zbiorów danych bez starannego wyboru funkcji może zwiększyć ryzyko nadmiernego dopasowania, zwłaszcza gdy model identyfikuje fałszywe korelacje, które istnieją całkowicie przypadkowo w danych uczących.
Sportowy przesąd
Chociaż przesądy sportowe nie są ściśle powiązane z uczeniem maszynowym, mogą zilustrować koncepcję nadmiernego dopasowania – szczególnie gdy wyniki są powiązane z danymi, które logicznie nie mają żadnego związku z wynikiem.
Podczas mistrzostw Europy w piłce nożnej UEFA Euro 2008 i Mistrzostw Świata FIFA 2010 ośmiornica o imieniu Paul była powszechnie wykorzystywana do przewidywania wyników meczów z udziałem Niemiec. W 2008 roku Paul trafnie sprawdził cztery z sześciu przewidywań, a w roku 2010 wszystkie siedem.
Jeśli weźmie się pod uwagę jedynie „dane szkoleniowe” z poprzednich przewidywań Paula, model zgodny z wyborami Paula wydaje się bardzo dobrze przewidywać wyniki. Jednak modelu tego nie można by dobrze uogólnić na przyszłe mecze, ponieważ wybory ośmiornicy nie są wiarygodnymi prognostykami wyników meczu.