
Losowe lasy w uczeniu maszynowym: kim one są i jak działają
Opublikowany: 2025-02-03Losowe lasy są potężną i wszechstronną techniką uczenia maszynowego (ML). Ten przewodnik pomoże ci zrozumieć losowe lasy, sposób pracy oraz ich zastosowania, korzyści i wyzwania.
Spis treści
- Co to jest losowy las?
- Drzewa decyzyjne vs. losowe las: jaka jest różnica?
- Jak działają losowe lasy
- Praktyczne zastosowania losowych lasów
- Zalety przypadkowych lasów
- Wady przypadkowych lasów
Co to jest losowy las?
Losowy las to algorytm uczenia maszynowego, który wykorzystuje wiele drzew decyzyjnych do przewidywania. Jest to nadzorowana metoda uczenia się zaprojektowana zarówno do zadań klasyfikacyjnych, jak i regresji. Łącząc wyniki wielu drzew, losowy las poprawia dokładność, zmniejsza nadmierne dopasowanie i zapewnia bardziej stabilne prognozy w porównaniu z jednym drzewem decyzyjnym.
Drzewa decyzyjne vs. losowe las: jaka jest różnica?
Chociaż losowe lasy są budowane na drzewach decyzyjnych, dwa algorytmy różnią się znacznie strukturą i zastosowaniem:
Drzewa decyzyjne
Drzewo decyzyjne składa się z trzech głównych elementów: węzła głównego, węzłów decyzyjnych (węzłów wewnętrznych) i węzłów liściowych. Podobnie jak schemat blokowy, proces decyzyjny rozpoczyna się w węźle głównym, przepływa przez węzły decyzyjne na podstawie warunków, a kończy w węźle liściowym reprezentującym wynik. Podczas gdy drzewa decyzyjne są łatwe do interpretacji i konceptualizacji, są również podatne na nadmierne dopasowanie, szczególnie w przypadku złożonych lub hałaśliwych zestawów danych.
Losowe lasy
Losowy las jest zespołem drzew decyzyjnych, który łączy ich wyniki w celu poprawy prognoz. Każde drzewo jest szkolone na unikalnej próbce bootstrap (losowo pobrany podzbiór oryginalnego zestawu danych z wymianą) i ocenia podziały decyzyjne przy użyciu losowo wybranego podzbioru funkcji w każdym węźle. Takie podejście, znane jako worki funkcyjne, wprowadza różnorodność wśród drzew. Agregując prognozy - przez większość głosowania na klasyfikację lub średnie dla regresji - lasy Random dają dokładniejsze i stabilne wyniki niż jakiekolwiek pojedyncze drzewo decyzyjne w zespole.
Jak działają losowe lasy
Losowe lasy działają, łącząc wiele drzew decyzyjnych w celu stworzenia solidnego i dokładnego modelu prognozowania.
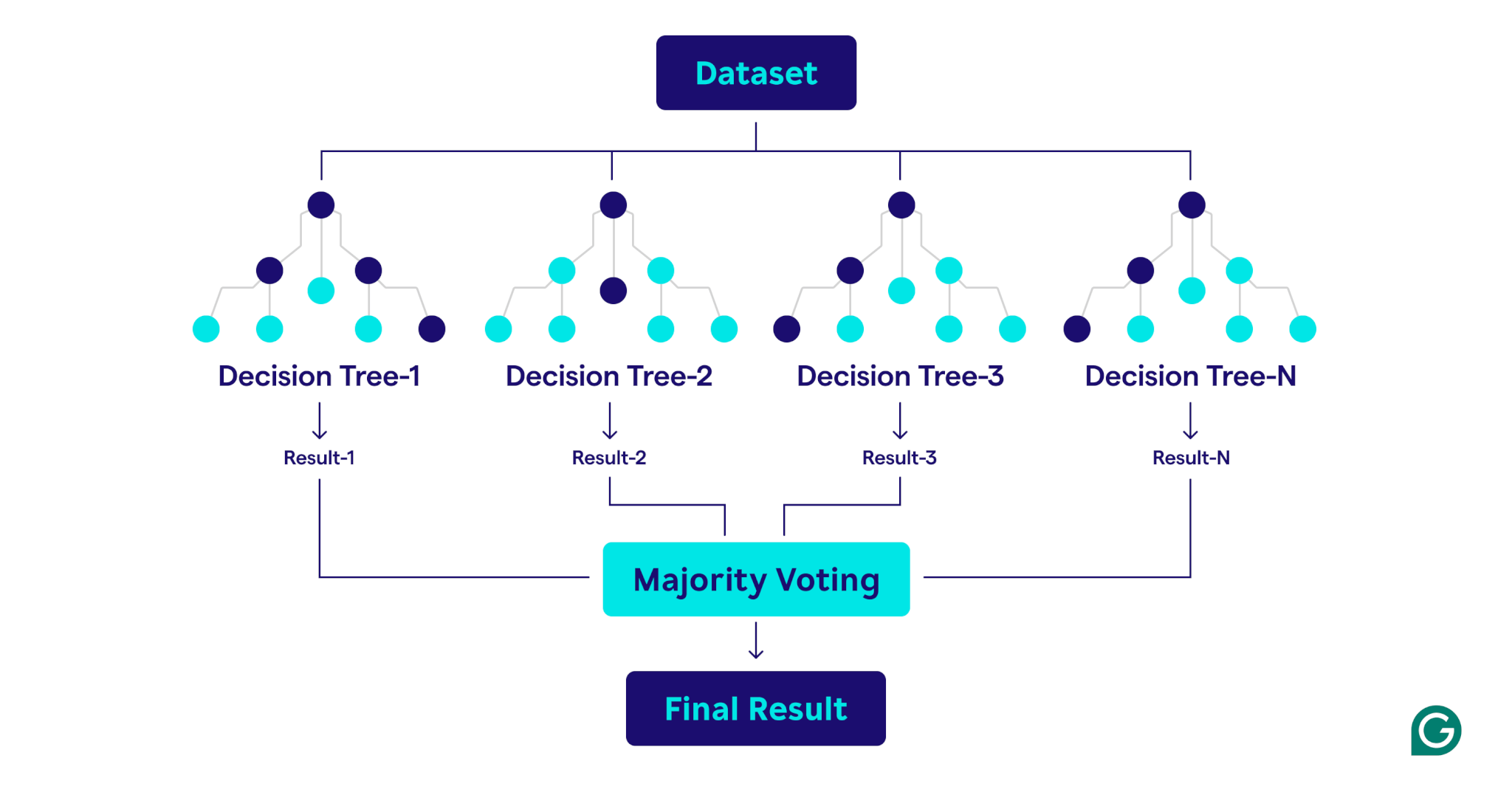
Oto krok po kroku wyjaśnienie tego procesu:
1. Ustawienie hiperparametrów
Pierwszym krokiem jest zdefiniowanie hiperparametrów modelu. Należą do nich:
- Liczba drzew:określa wielkość lasu
- Maksymalna głębokość dla każdego drzewa:kontroluje, jak głębokie każde drzewo decyzyjne może rosnąć
- Liczba funkcji uwzględnionych na każdym podziale:ogranicza liczbę funkcji ocenianych podczas tworzenia podziałów
Te hiperparametry umożliwiają dostrajanie złożoności modelu i optymalizację wydajności dla określonych zestawów danych.
2. Pobieranie próbek bootstrap
Po ustawieniu hiperparametrów proces szkolenia rozpoczyna się od próbkowania bootstrap. To obejmuje:
- Punkty danych z oryginalnego zestawu danych są losowo wybierane do tworzenia zestawów danych szkoleniowych (próbki bootstrap) dla każdego drzewa decyzyjnego.
- Każda próbka bootstrap jest zazwyczaj około dwóch trzecich rozmiarów oryginalnego zestawu danych, a niektóre punkty danych powtórzono, a inne wykluczone.
- Pozostała trzecia punkty danych, nie zawarta w próbce bootstrap, jest określana jako dane poza Bag (OOB).
3. Budowanie drzew decyzyjnych
Każde drzewo decyzyjne w losowym lesie jest szkolone w odpowiedniej próbce bootstrap przy użyciu unikalnego procesu:
- Bagowanie funkcji:przy każdym podziale wybierany jest losowy podzbiór funkcji, zapewniający różnorodność wśród drzew.
- Rozdzielenie węzłów:najlepsza funkcja z podzbioru służy do podziału węzła:
- W przypadku zadań klasyfikacyjnych kryteria takie jak zanieczyszczenie Gini (miara, jak często losowo wybrany element byłby nieprawidłowo sklasyfikowany, gdyby był losowo oznaczony zgodnie z rozkładem etykiet klas w węźle), mierzą, jak dobrze podzielony oddziela klasy.
- W przypadku zadań regresji techniki takie jak redukcja wariancji (metoda, która mierzy, ile podziału węzła zmniejsza wariancję wartości docelowych, co prowadzi do bardziej precyzyjnych prognoz) oceniają, ile podzielony zmniejsza błąd prognozy.
- Drzewo rośnie rekurencyjnie, aż spełnia warunki zatrzymania, takie jak maksymalna głębokość lub minimalna liczba punktów danych na węzeł.
4. Ocena wydajności
Gdy każde drzewo jest konstruowane, wydajność modelu jest szacowana za pomocą danych OOB:
- Oszacowanie błędu OOB zapewnia bezstronną miarę wydajności modelu, eliminując potrzebę oddzielnego zestawu danych sprawdzania poprawności.
- Zagregując prognozy ze wszystkich drzew, losowy las osiąga lepszą dokładność i zmniejsza nadmierne dopasowanie w porównaniu z poszczególnymi drzewami decyzyjnymi.

Praktyczne zastosowania losowych lasów
Podobnie jak drzewa decyzyjne, na których są budowane, losowe lasy można zastosować do problemów z klasyfikacją i regresją w wielu różnych sektorach, takich jak opieka zdrowotna i finanse.
Klasyfikowanie warunków pacjenta
W opiece zdrowotnej losowe lasy są wykorzystywane do klasyfikacji warunków pacjenta w oparciu o informacje takie jak historia medyczna, dane demograficzne i wyniki testów. Na przykład, aby przewidzieć, czy pacjent prawdopodobnie opracuje określony stan, taki jak cukrzyca, każde drzewo decyzyjne klasyfikuje pacjenta jako zagrożonego lub nie na podstawie odpowiednich danych, a losowy las dokonuje ostatecznego ustalenia na podstawie głosowania większości. Takie podejście oznacza, że losowe lasy są szczególnie odpowiednie dla złożonych, bogatych w funkcje zestawy danych znalezionych w opiece zdrowotnej.
Przewidywanie niewykonania zobowiązania pożyczki
Banki i główne instytucje finansowe szeroko wykorzystują losowe lasy do ustalenia kwalifikowalności do pożyczki i lepszego zrozumienia ryzyka. Model wykorzystuje czynniki takie jak dochód i zdolność kredytowa w celu ustalenia ryzyka. Ponieważ ryzyko jest mierzone jako ciągła wartość liczbowa, losowy las wykonuje regresję zamiast klasyfikacji. Każde drzewo decyzyjne, wyszkolone na nieco innych próbkach bootstrap, wyświetla przewidywany wynik ryzyka. Następnie losowy las średnio wszystkie poszczególne prognozy, co powoduje solidne, holistyczne oszacowanie ryzyka.
Przewidywanie utraty klienta
W marketingu losowe lasy są często wykorzystywane do przewidywania prawdopodobieństwa zaprzestania korzystania z produktu lub usługi. Obejmuje to analizę wzorców zachowań klientów, takich jak częstotliwość zakupów i interakcje z obsługą klienta. Zidentyfikując te wzorce, losowe lasy mogą klasyfikować klientów zagrożonych odejściem. Dzięki tym spostrzeżeniom firmy mogą podejmować proaktywne, oparte na danych kroki w celu zatrzymania klientów, takich jak oferowanie programów lojalnościowych lub ukierunkowane promocje.
Przewidywanie cen nieruchomości
Losowe lasy można wykorzystać do przewidywania cen nieruchomości, co jest zadaniem regresji. Aby dokonać prognozy, losowy las wykorzystuje dane historyczne, które obejmują czynniki takie jak położenie geograficzne, materiał kwadratowy i ostatnia sprzedaż w okolicy. Proces uśredniania losowego lasu powoduje bardziej niezawodną i stabilną prognozę cen niż indywidualne drzewo decyzyjne, co jest przydatne na wysoce niestabilnych rynkach nieruchomości.
Zalety przypadkowych lasów
Losowe lasy oferują wiele zalet, w tym dokładność, solidność, wszechstronność i zdolność do oszacowania znaczenia.
Dokładność i solidność
Losowe lasy są dokładniejsze i solidne niż indywidualne drzewa decyzyjne. Osiąga się to poprzez połączenie wyników wielu drzew decyzyjnych przeszkolonych na różnych próbkach bootstrap oryginalnego zestawu danych. Wynikająca z tego różnorodność oznacza, że losowe lasy są mniej podatne na przepełnienie niż poszczególne drzewa decyzyjne. To podejście zespołu oznacza, że losowe lasy są dobre w radzeniu sobie z głośnymi danymi, nawet w złożonych zestawach danych.
Wszechstronność
Podobnie jak drzewa decyzyjne, na których są budowane, losowe lasy są wysoce wszechstronne. Mogą obsługiwać zarówno zadania regresji, jak i klasyfikacyjne, dzięki czemu mają zastosowanie do szerokiego zakresu problemów. Losowe lasy dobrze również działają z dużymi, bogatymi w funkcje zestawy danych i mogą obsługiwać zarówno dane numeryczne, jak i kategoryczne.
Znaczenie funkcji
Losowe lasy mają wbudowaną zdolność do oszacowania znaczenia poszczególnych cech. W ramach procesu szkoleniowego losowe lasy wyświetlają wynik, który mierzy, jak bardzo zmienia się dokładność modelu, jeśli dana funkcja zostanie usunięta. Uśredniając wyniki dla każdej funkcji, losowe lasy mogą zapewnić wymierną miarę znaczenia cech. Mniej ważne funkcje można następnie usunąć, aby stworzyć bardziej wydajne drzewa i lasy.
Wady przypadkowych lasów
Podczas gdy losowe lasy oferują wiele korzyści, są one trudniejsze do interpretacji i bardziej kosztowne w szkoleniu niż jedno drzewo decyzyjne, i mogą wyprowadzać prognozy wolniej niż inne modele.
Złożoność
Podczas gdy losowe lasy i drzewa decyzyjne mają wiele wspólnego, losowe lasy są trudniejsze do interpretacji i wizualizacji. Ta złożoność powstaje, ponieważ losowe lasy wykorzystują setki lub tysiące drzew decyzyjnych. „Czarna skrzynka” losowych lasów jest poważną wadą, gdy wymogność wyjaśniająca model jest wymagana.
Koszt obliczeniowy
Szkolenie setek lub tysięcy drzew decyzyjnych wymaga znacznie większej mocy przetwarzania i pamięci niż szkolenie jednego drzewa decyzyjnego. Gdy zaangażowane są duże zestawy danych, koszt obliczeniowy może być jeszcze wyższy. To duże zapotrzebowanie na zasoby mogą powodować wyższe koszty pieniężne i dłuższy czas szkolenia. W rezultacie losowe lasy mogą nie być praktyczne w scenariuszach takich jak przetwarzanie krawędzi, w których zarówno moc obliczeniowa, jak i pamięć są rzadkie. Jednak losowe lasy mogą być równoległe, co może pomóc obniżyć koszty obliczeń.
Wolniejszy czas prognozowania
Proces przewidywania losowego lasu obejmuje przemieszczanie każdego drzewa w lesie i agregowanie ich wyników, co jest z natury wolniejsze niż użycie jednego modelu. Proces ten może powodować wolniejsze czasy prognozowania niż prostsze modele, takie jak regresja logistyczna lub sieci neuronowe, szczególnie w przypadku dużych lasów zawierających głębokie drzewa. W przypadku użycia przypadków, w których czas jest esencji, takimi jak handel o wysokiej częstotliwości lub pojazdy autonomiczne, opóźnienie to może być wygórowane.