
Czym jest niedopasowanie w uczeniu maszynowym?
Opublikowany: 2024-10-16Niedopasowanie jest częstym problemem napotykanym podczas opracowywania modeli uczenia maszynowego (ML). Występuje, gdy model nie jest w stanie efektywnie uczyć się na podstawie danych szkoleniowych, co skutkuje niską wydajnością. W tym artykule dowiemy się, czym jest niedopasowanie, jak do niego dochodzi i jakie są strategie jego uniknięcia.
Spis treści
- Co to jest niedopasowanie?
- Jak dochodzi do niedopasowania
- Niedopasowanie vs. nadmierne dopasowanie
- Najczęstsze przyczyny niedopasowania
- Jak wykryć niedopasowanie
- Techniki zapobiegania niedopasowaniu
- Praktyczne przykłady niedopasowania
Co to jest niedopasowanie?
Niedopasowanie ma miejsce, gdy model uczenia maszynowego nie uchwyci podstawowych wzorców w danych szkoleniowych, co prowadzi do słabej wydajności zarówno danych szkoleniowych, jak i testowych. Kiedy tak się dzieje, oznacza to, że model jest zbyt prosty i nie radzi sobie dobrze z reprezentowaniem najważniejszych relacji między danymi. W rezultacie model ma trudności z dokładnym przewidywaniem wszystkich danych, zarówno danych widocznych podczas uczenia, jak i wszelkich nowych, niewidocznych danych.
Jak dochodzi do niedopasowania?
Niedopasowanie ma miejsce, gdy algorytm uczenia maszynowego tworzy model, który nie przechwytuje najważniejszych właściwości danych szkoleniowych; modele, które zawodzą w ten sposób, są uważane za zbyt proste. Załóżmy na przykład, że używasz regresji liniowej do przewidywania sprzedaży na podstawie wydatków marketingowych, danych demograficznych klientów i sezonowości. Regresja liniowa zakłada, że związek między tymi czynnikami a sprzedażą można przedstawić jako kombinację linii prostych.
Chociaż rzeczywisty związek między wydatkami marketingowymi a sprzedażą może być zakrzywiony lub obejmować wiele interakcji (np. sprzedaż początkowo szybko rośnie, a następnie utrzymuje się na stałym poziomie), model liniowy będzie nadmiernie upraszczany poprzez narysowanie linii prostej. To uproszczenie pomija ważne niuanse, co prowadzi do słabych prognoz i ogólnej wydajności.
Ten problem występuje często w wielu modelach uczenia maszynowego, gdzie duże obciążenie (sztywne założenia) uniemożliwia modelowi uczenie się podstawowych wzorców, co powoduje jego słabe działanie zarówno w przypadku danych szkoleniowych, jak i testowych. Niedopasowanie występuje zwykle, gdy model jest zbyt prosty, aby odzwierciedlić prawdziwą złożoność danych.
Niedopasowanie vs. nadmierne dopasowanie
W ML niedopasowanie i nadmierne dopasowanie to częste problemy, które mogą negatywnie wpłynąć na zdolność modelu do dokonywania dokładnych przewidywań. Zrozumienie różnicy między nimi ma kluczowe znaczenie przy budowaniu modeli, które dobrze generalizują nowe dane.
- Niedopasowaniema miejsce, gdy model jest zbyt prosty i nie uwzględnia kluczowych wzorców danych. Prowadzi to do niedokładnych przewidywań zarówno w przypadku danych szkoleniowych, jak i nowych danych.
- Do nadmiernego dopasowaniadochodzi, gdy model staje się zbyt złożony i dopasowuje nie tylko prawdziwe wzorce, ale także szum w danych uczących. To powoduje, że model działa dobrze na zbiorze szkoleniowym, ale słabo na nowych, niewidocznych danych.
Aby lepiej zilustrować te koncepcje, rozważmy model prognozujący wyniki sportowe na podstawie poziomu stresu. Niebieskie kropki na wykresie reprezentują punkty danych ze zbioru uczącego, a linie przedstawiają przewidywania modelu po przeszkoleniu na tych danych. 
1 Niedopasowanie:w tym przypadku model wykorzystuje prostą linię prostą do przewidywania wydajności, mimo że rzeczywista zależność jest zakrzywiona. Ponieważ linia nie pasuje dobrze do danych, model jest zbyt prosty i nie wychwytuje ważnych wzorców, co skutkuje słabymi przewidywaniami. Jest to niedopasowanie, gdy model nie uczy się najbardziej przydatnych właściwości danych.
2 Optymalne dopasowanie:w tym przypadku model wystarczająco dobrze dopasowuje się do krzywej danych. Wychwytuje podstawowy trend bez nadmiernej wrażliwości na określone punkty danych lub szum. Jest to pożądany scenariusz, w którym model dość dobrze uogólnia i może dokonywać dokładnych prognoz na podstawie podobnych, nowych danych. Jednak uogólnianie może nadal stanowić wyzwanie w przypadku znacznie różnych lub bardziej złożonych zbiorów danych.
3 Nadmierne dopasowanie:W scenariuszu nadmiernego dopasowania model ściśle podąża za prawie każdym punktem danych, łącznie z szumem i przypadkowymi wahaniami danych uczących. Chociaż model działa wyjątkowo dobrze na zbiorze uczącym, jest zbyt specyficzny dla danych uczących, a zatem będzie mniej skuteczny przy przewidywaniu nowych danych. Trudno jest uogólniać i prawdopodobnie będzie dokonywać niedokładnych przewidywań, jeśli zastosuje się go do niewidzianych scenariuszy.
Najczęstsze przyczyny niedopasowania
Istnieje wiele potencjalnych przyczyn niedopasowania. Cztery najczęstsze to:
- Architektura modelu jest zbyt prosta.
- Zły wybór funkcji
- Niewystarczające dane szkoleniowe
- Za mało szkoleń
Przyjrzyjmy się tym bliżej, aby je zrozumieć.
Architektura modelu jest zbyt prosta
Architektura modelu odnosi się do kombinacji algorytmu użytego do uczenia modelu i jego struktury. Jeśli architektura jest zbyt prosta, może wystąpić problem z przechwytywaniem właściwości danych szkoleniowych wysokiego poziomu, co prowadzi do niedokładnych przewidywań.
Na przykład, jeśli model spróbuje użyć pojedynczej linii prostej do modelowania danych według zakrzywionego wzoru, będzie to konsekwentnie niedopasowane. Dzieje się tak, ponieważ linia prosta nie może dokładnie odzwierciedlać relacji wysokiego poziomu w zakrzywionych danych, co sprawia, że architektura modelu jest nieodpowiednia do tego zadania.
Zły wybór funkcji
Selekcja cech polega na wyborze odpowiednich zmiennych dla modelu ML podczas uczenia. Na przykład możesz poprosić algorytm ML o sprawdzenie roku urodzenia, koloru oczu, wieku lub wszystkich trzech czynników podczas przewidywania, czy dana osoba kliknie przycisk Kup w witrynie e-commerce.
Jeśli jest zbyt wiele cech lub wybrane cechy nie korelują silnie ze zmienną docelową, model nie będzie miał wystarczającej ilości odpowiednich informacji, aby dokonać dokładnych prognoz. Kolor oczu może nie mieć znaczenia przy konwersji, a wiek zawiera wiele takich samych informacji jak rok urodzenia.
Niewystarczające dane szkoleniowe
Gdy punktów danych jest zbyt mało, model może być niedopasowany, ponieważ dane nie oddają najważniejszych właściwości problemu. Może się to zdarzyć z powodu braku danych lub błędu próbkowania, gdy pewne źródła danych są wykluczone lub niedostatecznie reprezentowane, co uniemożliwia modelowi nauczenie się ważnych wzorców.

Za mało szkoleń
Uczenie modelu ML polega na dostosowaniu jego wewnętrznych parametrów (wag) w oparciu o różnicę między jego przewidywaniami a rzeczywistymi wynikami. Im więcej iteracji szkoleniowych przechodzi model, tym lepiej może się dopasować do danych. Jeśli model zostanie wyszkolony przy użyciu zbyt małej liczby iteracji, może nie mieć wystarczających możliwości uczenia się na podstawie danych, co prowadzi do niedopasowania.
Jak wykryć niedopasowanie
Jednym ze sposobów wykrycia niedopasowania jest analiza krzywych uczenia się, które przedstawiają wydajność modelu (zwykle stratę lub błąd) w funkcji liczby iteracji uczących. Krzywa uczenia się pokazuje, jak model poprawia się (lub nie poprawia) w czasie, zarówno w zbiorach danych szkoleniowych, jak i walidacyjnych.
Strata to wielkość błędu modelu dla danego zbioru danych. Straty szkoleniowe mierzą to dla danych szkoleniowych i straty walidacyjne dla danych walidacyjnych. Dane walidacyjne to oddzielny zbiór danych używany do testowania wydajności modelu. Zwykle powstaje poprzez losowe podzielenie większego zbioru danych na dane szkoleniowe i walidacyjne.
W przypadku niedopasowania zauważysz następujące kluczowe prawidłowości:
- Wysoka strata treningowa:Jeśli strata treningowa modelu pozostaje wysoka i nie zmienia się na początku procesu, sugeruje to, że model nie uczy się na podstawie danych szkoleniowych. Jest to wyraźna oznaka niedopasowania, gdyż model jest zbyt prosty, aby dostosować się do złożoności danych.
- Podobne straty podczas szkolenia i walidacji:jeśli zarówno straty podczas uczenia, jak i walidacji są wysokie i pozostają blisko siebie przez cały proces uczenia, oznacza to, że model ma słabą wydajność w obu zbiorach danych. Oznacza to, że model nie pobiera wystarczającej ilości informacji z danych, aby dokonać dokładnych przewidywań, co wskazuje na niedopasowanie.
Poniżej znajduje się przykładowy wykres przedstawiający krzywe uczenia się w scenariuszu niedopasowania:
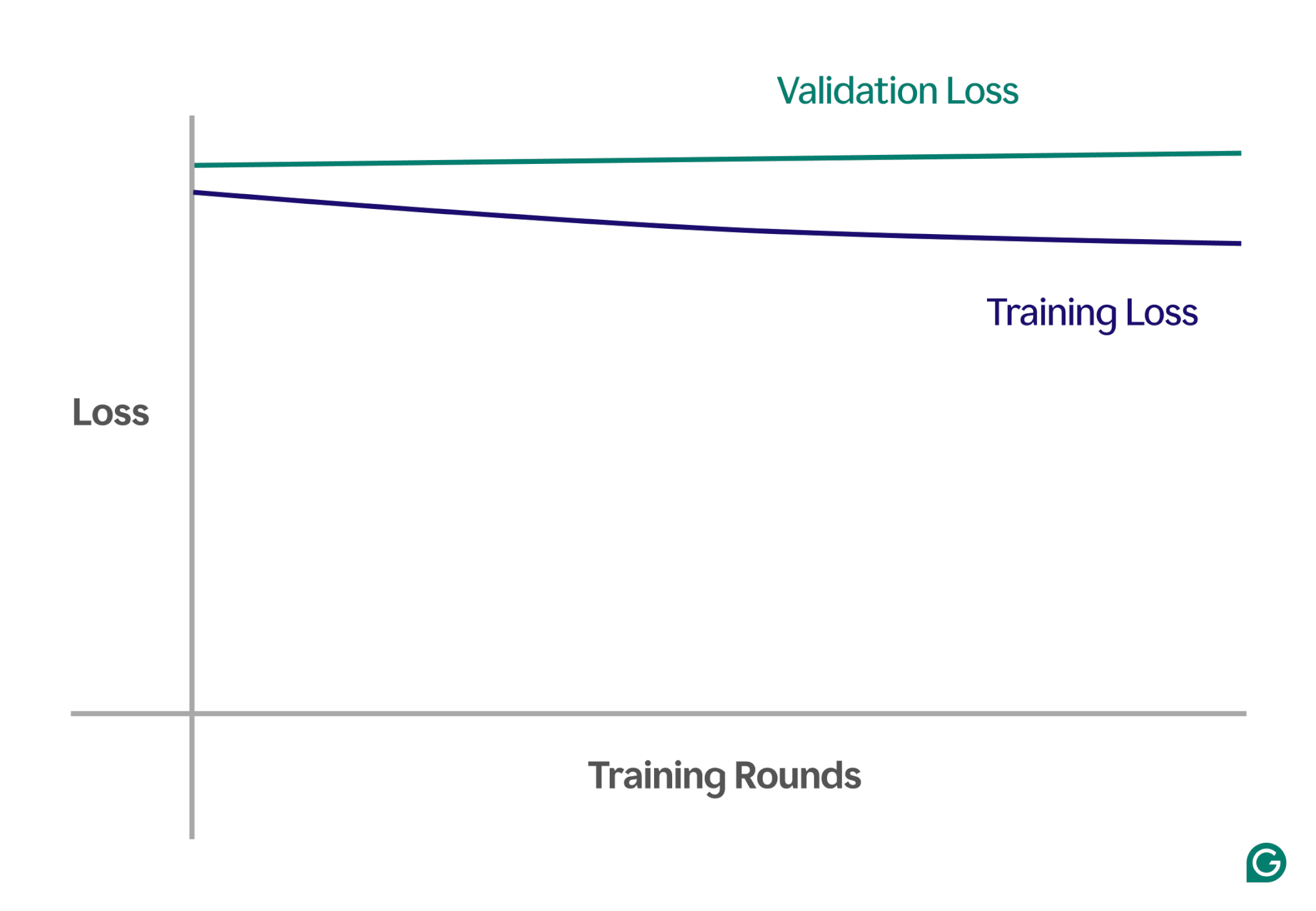
Na tym wizualnym przedstawieniu niedopasowanie jest łatwe do wykrycia:
- W dobrze dopasowanym modelu straty szkoleniowe znacznie się zmniejszają, podczas gdy straty walidacyjne mają podobny wzór, ostatecznie się stabilizując.
- W modelu niedopasowanym zarówno straty w zakresie uczenia, jak i walidacji zaczynają się od wysokich wartości i pozostają wysokie, bez żadnej znaczącej poprawy.
Obserwując te trendy, można szybko zidentyfikować, czy model jest zbyt uproszczony i wymaga poprawek w celu zwiększenia jego złożoności.
Techniki zapobiegania niedopasowaniu
Jeśli napotkasz niedopasowanie, możesz zastosować kilka strategii, aby poprawić wydajność modelu:
- Więcej danych treningowych:Jeśli to możliwe, uzyskaj dodatkowe dane treningowe. Więcej danych daje modelowi dodatkowe możliwości uczenia się wzorców, pod warunkiem, że dane są wysokiej jakości i istotne dla rozpatrywanego problemu.
- Rozszerz wybór funkcji:Dodaj do modelu funkcje, które są bardziej odpowiednie. Wybierz funkcje, które mają silny związek ze zmienną docelową, dając modelowi większą szansę na uchwycenie ważnych wzorców, które wcześniej zostały pominięte.
- Zwiększ moc architektury:W modelach opartych na sieciach neuronowych możesz dostosować strukturę architektoniczną, zmieniając liczbę wag, warstw lub innych hiperparametrów. Dzięki temu model może być bardziej elastyczny i łatwiej znajdować wzorce wysokiego poziomu w danych.
- Wybierz inny model:Czasami nawet po dostrojeniu hiperparametrów określony model może nie być dobrze dostosowany do zadania. Testowanie algorytmów wielu modeli może pomóc w znalezieniu bardziej odpowiedniego modelu i poprawie wydajności.
Praktyczne przykłady niedopasowania
Aby zilustrować skutki niedopasowania, przyjrzyjmy się przykładom z życia codziennego z różnych dziedzin, w których modele nie oddają złożoności danych, co prowadzi do niedokładnych przewidywań.
Przewidywanie cen domów
Aby dokładnie przewidzieć cenę domu, należy wziąć pod uwagę wiele czynników, w tym lokalizację, wielkość, rodzaj domu, stan i liczbę sypialni.
Jeśli użyjesz zbyt małej liczby funkcji – takich jak tylko rozmiar i typ domu – model nie będzie miał dostępu do kluczowych informacji. Na przykład model może zakładać, że małe studio jest niedrogie, nie wiedząc, że znajduje się w Mayfair w Londynie, w okolicy o wysokich cenach nieruchomości. Prowadzi to do złych prognoz.
Aby rozwiązać ten problem, badacze danych muszą zapewnić odpowiedni wybór funkcji. Obejmuje to uwzględnienie wszystkich istotnych funkcji, z wyłączeniem nieistotnych, i wykorzystanie dokładnych danych szkoleniowych.
Rozpoznawanie mowy
Technologia rozpoznawania głosu staje się coraz bardziej powszechna w życiu codziennym. Na przykład asystenci smartfonów, infolinie obsługi klienta i technologie wspomagające dla niepełnosprawnych korzystają z rozpoznawania mowy. Podczas uczenia tych modeli wykorzystywane są dane z próbek mowy i ich prawidłowe interpretacje.
Aby rozpoznać mowę, model przekształca fale dźwiękowe przechwycone przez mikrofon na dane. Jeśli uprościmy to, podając tylko dominującą częstotliwość i głośność głosu w określonych odstępach czasu, zmniejszymy ilość danych, które model musi przetworzyć.
Jednak takie podejście usuwa istotne informacje potrzebne do pełnego zrozumienia mowy. Dane stają się zbyt uproszczone, aby uchwycić złożoność ludzkiej mowy, taką jak różnice w tonie, wysokości i akcencie.
W rezultacie model będzie niedopasowany i będzie miał trudności z rozpoznawaniem nawet podstawowych poleceń słownych, nie mówiąc już o pełnych zdaniach. Nawet jeśli model jest wystarczająco złożony, brak kompleksowych danych prowadzi do niedopasowania.
Klasyfikacja obrazu
Klasyfikator obrazu ma na celu przyjęcie obrazu jako wejścia i wyprowadzenie słowa opisującego go. Załóżmy, że budujesz model wykrywający, czy obraz zawiera piłkę, czy nie. Trenujesz model, korzystając z oznaczonych obrazów piłek i innych obiektów.
Jeśli przez pomyłkę użyjesz prostej dwuwarstwowej sieci neuronowej zamiast bardziej odpowiedniego modelu, takiego jak splotowa sieć neuronowa (CNN), model będzie miał problemy. Dwuwarstwowa sieć spłaszcza obraz w jedną warstwę, tracąc ważne informacje przestrzenne. Dodatkowo, mając tylko dwie warstwy, model nie jest w stanie zidentyfikować złożonych cech.
Prowadzi to do niedopasowania, ponieważ model nie będzie w stanie dokonać dokładnych przewidywań, nawet na podstawie danych uczących. CNN rozwiązują ten problem, zachowując przestrzenną strukturę obrazów i stosując warstwy splotowe z filtrami, które automatycznie uczą się wykrywać ważne cechy, takie jak krawędzie i kształty we wczesnych warstwach oraz bardziej złożone obiekty w późniejszych warstwach.