
Noções básicas de rede adversária generativa: o que você precisa saber
Publicados: 2024-10-08As redes adversárias generativas (GANs) são uma ferramenta poderosa de inteligência artificial (IA) com inúmeras aplicações em aprendizado de máquina (ML). Este guia explora GANs, como funcionam, suas aplicações e suas vantagens e desvantagens.
Índice
- O que é um GAN?
- GANs x CNNs
- Como funcionam os GANs
- Tipos de GANs
- Aplicações de GANs
- Vantagens dos GANs
- Desvantagens dos GANs
O que é uma rede adversária generativa?
Uma rede adversária generativa, ou GAN, é um tipo de modelo de aprendizado profundo normalmente usado em aprendizado de máquina não supervisionado, mas também adaptável para aprendizado semissupervisionado e supervisionado. GANs são usados para gerar dados de alta qualidade semelhantes ao conjunto de dados de treinamento. Como um subconjunto da IA generativa, as GANs são compostas por dois submodelos: o gerador e o discriminador.
1 Gerador:O gerador cria dados sintéticos.
2 Discriminador:O discriminador avalia a saída do gerador, distinguindo entre dados reais do conjunto de treinamento e dados sintéticos criados pelo gerador.
Os dois modelos entram em competição: o gerador tenta enganar o discriminador para que classifique os dados gerados como reais, enquanto o discriminador melhora continuamente a sua capacidade de detectar dados sintéticos. Este processo adversário continua até que o discriminador não consiga mais distinguir entre dados reais e gerados. Neste ponto, o GAN é capaz de gerar imagens, vídeos e outros tipos de dados realistas.
GANs x CNNs
GANs e redes neurais convolucionais (CNNs) são tipos poderosos de redes neurais usadas em aprendizado profundo, mas diferem significativamente em termos de casos de uso e arquitetura.
Casos de uso
- GANs:Especializam-se na geração de dados sintéticos realistas com base em dados de treinamento. Isso torna os GANs adequados para tarefas como geração de imagens, transferência de estilo de imagem e aumento de dados. As GANs não são supervisionadas, o que significa que podem ser aplicadas a cenários onde os dados rotulados são escassos ou indisponíveis.
- CNNs:usadas principalmente para tarefas estruturadas de classificação de dados, como análise de sentimentos, categorização de tópicos e tradução de idiomas. Devido às suas habilidades de classificação, as CNNs também servem como bons discriminadores em GANs. No entanto, como as CNNs exigem dados de treinamento estruturados e anotados por humanos, elas estão limitadas a cenários de aprendizagem supervisionada.
Arquitetura
- GANs:Consistem em dois modelos – um discriminador e um gerador – que se envolvem em um processo competitivo. O gerador cria imagens, enquanto o discriminador as avalia, forçando o gerador a produzir imagens cada vez mais realistas ao longo do tempo.
- CNNs:Utilize camadas de operações convolucionais e de pooling para extrair e analisar recursos de imagens. Essa arquitetura de modelo único concentra-se no reconhecimento de padrões e estruturas nos dados.
No geral, enquanto as CNNs se concentram na análise de dados estruturados existentes, as GANs estão voltadas para a criação de dados novos e realistas.
Como funcionam os GANs
Em um nível superior, uma GAN funciona colocando duas redes neurais – o gerador e o discriminador – uma contra a outra. As GANs não exigem um tipo específico de arquitetura de rede neural para nenhum de seus dois componentes, desde que as arquiteturas selecionadas se complementem. Por exemplo, se uma CNN for usada como discriminador para geração de imagens, então o gerador pode ser uma rede neural deconvolucional (deCNN), que executa o processo CNN ao contrário. Cada componente tem um objetivo diferente:
- Gerador:Para produzir dados de tão alta qualidade que o discriminador seja enganado e classifique-os como reais.
- Discriminador:Para classificar com precisão uma determinada amostra de dados como real (do conjunto de dados de treinamento) ou falsa (gerada pelo gerador).
Esta competição é uma implementação de um jogo de soma zero, onde uma recompensa dada a um modelo é também uma penalidade para o outro modelo. Para o gerador, enganar o discriminador com sucesso resulta em uma atualização do modelo que aumenta sua capacidade de gerar dados realistas. Por outro lado, quando o discriminador identifica corretamente dados falsos, recebe uma atualização que melhora a sua capacidade de detecção. Matematicamente, o discriminador visa minimizar o erro de classificação, enquanto o gerador procura maximizá-lo.
O processo de treinamento GAN
O treinamento de GANs envolve a alternância entre o gerador e o discriminador em várias épocas. Épocas são execuções de treinamento completas em todo o conjunto de dados. Este processo continua até que o gerador produza dados sintéticos que enganam o discriminador em cerca de 50% das vezes. Embora ambos os modelos utilizem algoritmos semelhantes para avaliação e melhoria de desempenho, suas atualizações acontecem de forma independente. Essas atualizações são realizadas por meio de um método denominado backpropagation, que mede o erro de cada modelo e ajusta parâmetros para melhorar o desempenho. Um algoritmo de otimização ajusta então os parâmetros de cada modelo de forma independente.
Aqui está uma representação visual da arquitetura GAN, ilustrando a competição entre o gerador e o discriminador:
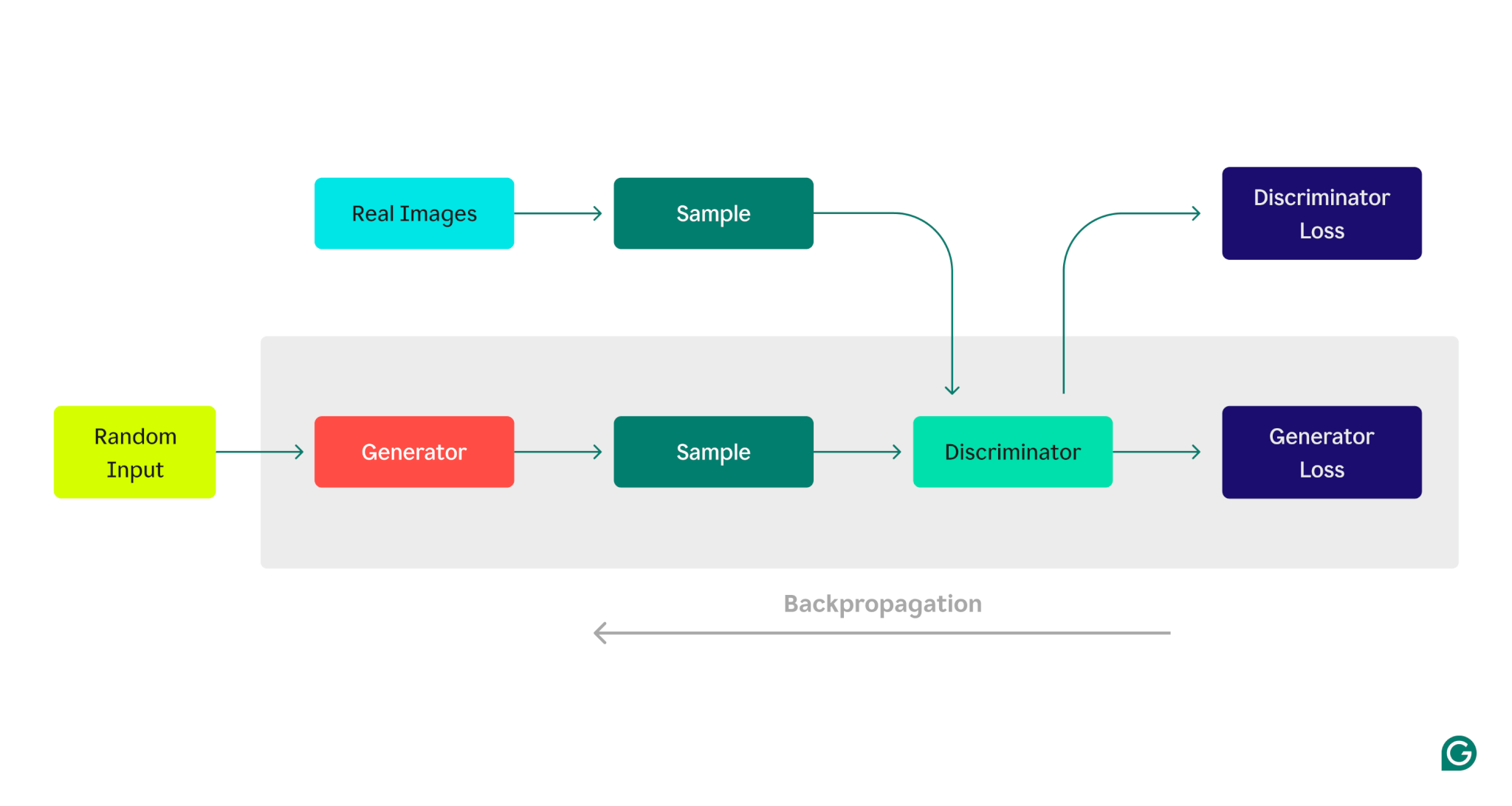
Fase de treinamento do gerador:
1 O gerador cria amostras de dados, normalmente começando com ruído aleatório como entrada.
2 O discriminador classifica essas amostras como reais (do conjunto de dados de treinamento) ou falsas (geradas pelo gerador).
3 Com base na resposta do discriminador, os parâmetros do gerador são atualizados usando retropropagação.
Fase de treinamento do discriminador:
1 Dados falsos são gerados usando o estado atual do gerador.
2 As amostras geradas são fornecidas ao discriminador, juntamente com amostras do conjunto de dados de treinamento.
3 Utilizando retropropagação, os parâmetros do discriminador são atualizados com base no seu desempenho de classificação.
Este processo de treinamento iterativo continua, com os parâmetros de cada modelo sendo ajustados com base em seu desempenho, até que o gerador produza consistentemente dados que o discriminador não consegue distinguir com segurança dos dados reais.
Tipos de GANs
Com base na arquitetura GAN básica, muitas vezes chamada de GAN vanilla, outros tipos especializados de GANs foram desenvolvidos e otimizados para diversas tarefas. Algumas das variações mais comuns são descritas abaixo, embora esta não seja uma lista exaustiva:
GAN condicional (cGAN)
GANs condicionais, ou cGANs, usam informações adicionais, chamadas condições, para orientar o modelo na geração de tipos específicos de dados ao treinar em um conjunto de dados mais geral. Uma condição pode ser um rótulo de classe, uma descrição baseada em texto ou outro tipo de informação de classificação para os dados. Por exemplo, imagine que você precisa gerar imagens apenas de gatos siameses, mas seu conjunto de dados de treinamento contém imagens de todos os tipos de gatos. Em um cGAN, você poderia rotular imagens de treinamento com o tipo de gato, e o modelo poderia usar isso para aprender como gerar apenas imagens de gatos siameses.

GAN convolucional profundo (DCGAN)
Um GAN convolucional profundo, ou DCGAN, é otimizado para geração de imagens. Em um DCGAN, o gerador é uma rede neural convolucional de incorporação profunda (deCNN), e o discriminador é uma CNN profunda. As CNNs são mais adequadas para trabalhar e gerar imagens devido à sua capacidade de capturar hierarquias e padrões espaciais. O gerador em um DCGAN usa upsampling e camadas convolucionais transpostas para criar imagens de maior qualidade do que um perceptron multicamadas (uma rede neural simples que toma decisões pesando recursos de entrada) poderia gerar. Da mesma forma, o discriminador usa camadas convolucionais para extrair características das amostras de imagens e classificá-las com precisão como reais ou falsas.
CicloGAN
CycleGAN é um tipo de GAN projetado para gerar um tipo de imagem a partir de outro. Por exemplo, um CycleGAN pode transformar a imagem de um rato em um rato ou de um cachorro em um coiote. Os CycleGANs são capazes de realizar essa tradução de imagem para imagem sem treinamento em conjuntos de dados emparelhados, ou seja, conjuntos de dados contendo a imagem base e a transformação desejada. Essa capacidade é alcançada usando dois geradores e dois discriminadores em vez do par único usado por um GAN vanilla. No CycleGAN, um gerador converte imagens da imagem base para a versão transformada, enquanto o outro gerador realiza uma conversão na direção oposta. Da mesma forma, cada discriminador verifica um tipo específico de imagem para determinar se é real ou falsa. CycleGAN então usa uma verificação de consistência para garantir que a conversão de uma imagem para outro estilo e vice-versa resulte na imagem original.
Aplicações de GANs
Devido à sua arquitetura distinta, as GANs foram aplicadas a uma série de casos de uso inovadores, embora o seu desempenho seja altamente dependente de tarefas específicas e da qualidade dos dados. Alguns dos aplicativos mais poderosos incluem geração de texto para imagem, aumento de dados e geração e manipulação de vídeo.
Geração de texto para imagem
GANs podem gerar imagens a partir de uma descrição textual. Este aplicativo é valioso nas indústrias criativas, permitindo que autores e designers visualizem as cenas e personagens descritos no texto. Embora as GANs sejam frequentemente usadas para tais tarefas, outros modelos generativos de IA, como o DALL-E da OpenAI, usam arquiteturas baseadas em transformadores para alcançar resultados semelhantes.
Aumento de dados
GANs são úteis para aumento de dados porque podem gerar dados sintéticos que se assemelham a dados de treinamento reais, embora o grau de precisão e realismo possa variar dependendo do caso de uso específico e do treinamento do modelo. Esse recurso é particularmente valioso no aprendizado de máquina para expandir conjuntos de dados limitados e melhorar o desempenho do modelo. Além disso, os GANs oferecem uma solução para manter a privacidade dos dados. Em áreas sensíveis como saúde e finanças, as GANs podem produzir dados sintéticos que preservam as propriedades estatísticas do conjunto de dados original sem comprometer informações confidenciais.
Geração e manipulação de vídeo
Os GANs têm se mostrado promissores em certas tarefas de geração e manipulação de vídeo. Por exemplo, GANs podem ser usados para gerar quadros futuros a partir de uma sequência de vídeo inicial, auxiliando em aplicações como previsão de movimento de pedestres ou previsão de perigos rodoviários para veículos autônomos. No entanto, essas aplicações ainda estão sob pesquisa e desenvolvimento ativos. GANs também podem ser usados para gerar conteúdo de vídeo totalmente sintético e aprimorar vídeos com efeitos especiais realistas.
Vantagens dos GANs
As GANs oferecem diversas vantagens distintas, incluindo a capacidade de gerar dados sintéticos realistas, aprender com dados não pareados e realizar treinamento não supervisionado.
Geração de dados sintéticos de alta qualidade
A arquitetura das GANs lhes permite produzir dados sintéticos que podem aproximar dados do mundo real em aplicações como aumento de dados e criação de vídeo, embora a qualidade e a precisão desses dados possam depender fortemente das condições de treinamento e dos parâmetros do modelo. Por exemplo, DCGANs, que utilizam CNNs para processamento ideal de imagens, são excelentes na geração de imagens realistas.
Capaz de aprender com dados não pareados
Ao contrário de alguns modelos de ML, os GANs podem aprender com conjuntos de dados sem exemplos emparelhados de entradas e saídas. Essa flexibilidade permite que as GANs sejam usadas em uma ampla gama de tarefas onde os dados emparelhados são escassos ou indisponíveis. Por exemplo, em tarefas de tradução de imagem para imagem, os modelos tradicionais geralmente exigem um conjunto de dados de imagens e suas transformações para treinamento. Em contraste, as GANs podem aproveitar uma variedade mais ampla de conjuntos de dados potenciais para treinamento.
Aprendizagem não supervisionada
GANs são um método de aprendizado de máquina não supervisionado, o que significa que podem ser treinados em dados não rotulados sem orientação explícita. Isto é particularmente vantajoso porque a rotulagem de dados é um processo demorado e dispendioso. A capacidade dos GANs de aprender com dados não rotulados os torna valiosos para aplicações onde os dados rotulados são limitados ou difíceis de obter. Os GANs também podem ser adaptados para aprendizagem semissupervisionada e supervisionada, permitindo-lhes também usar dados rotulados.
Desvantagens dos GANs
Embora as GANs sejam uma ferramenta poderosa no aprendizado de máquina, sua arquitetura cria um conjunto único de desvantagens. Essas desvantagens incluem sensibilidade a hiperparâmetros, altos custos computacionais, falha de convergência e um fenômeno chamado colapso de modo.
Sensibilidade do hiperparâmetro
GANs são sensíveis a hiperparâmetros, que são parâmetros definidos antes do treinamento e não aprendidos com os dados. Os exemplos incluem arquiteturas de rede e o número de exemplos de treinamento usados em uma única iteração. Pequenas alterações nesses parâmetros podem afetar significativamente o processo de treinamento e os resultados do modelo, necessitando de extensos ajustes para aplicações práticas.
Alto custo computacional
Devido à sua arquitetura complexa, processo de treinamento iterativo e sensibilidade aos hiperparâmetros, os GANs geralmente incorrem em altos custos computacionais. O treinamento bem-sucedido de uma GAN requer hardware especializado e caro, bem como um tempo significativo, o que pode ser uma barreira para muitas organizações que buscam utilizar GANs.
Falha de convergência
Engenheiros e pesquisadores podem gastar uma quantidade significativa de tempo experimentando configurações de treinamento antes de atingirem uma taxa aceitável na qual a saída do modelo se torna estável e precisa, conhecida como taxa de convergência. A convergência nas GANs pode ser muito difícil de alcançar e pode não durar muito. A falha de convergência ocorre quando o discriminador não consegue decidir suficientemente entre dados reais e falsos, resultando em uma precisão de aproximadamente 50% porque não ganhou a capacidade de identificar dados reais, ao contrário do equilíbrio pretendido alcançado durante o treinamento bem-sucedido. Algumas GANs podem nunca atingir a convergência e podem exigir análise especializada para serem reparadas.
Colapso do modo
As GANs estão sujeitas a um problema chamado colapso de modo, em que o gerador cria uma gama limitada de resultados e não reflete a diversidade das distribuições de dados do mundo real. Esse problema surge da arquitetura GAN, pois o gerador fica excessivamente focado na produção de dados que podem enganar o discriminador, levando-o a gerar exemplos semelhantes.