
O que é uma rede neural?
Publicados: 2024-06-26O que é uma rede neural?
Uma rede neural é um tipo de modelo de aprendizado profundo dentro do campo mais amplo do aprendizado de máquina (ML) que simula o cérebro humano. Ele processa dados por meio de nós ou neurônios interconectados organizados em camadas – entrada, oculta e saída. Cada nó realiza cálculos simples, contribuindo para a capacidade do modelo de reconhecer padrões e fazer previsões.
As redes neurais de aprendizagem profunda são particularmente eficazes no tratamento de tarefas complexas, como reconhecimento de imagem e fala, constituindo um componente crucial de muitas aplicações de IA. Avanços recentes em arquiteturas de redes neurais e técnicas de treinamento melhoraram substancialmente as capacidades dos sistemas de IA.
Como as redes neurais são estruturadas
Conforme indicado pelo nome, um modelo de rede neural se inspira nos neurônios, os blocos de construção do cérebro. Os seres humanos adultos têm cerca de 85 mil milhões de neurónios, cada um ligado a cerca de 1.000 outros. Uma célula cerebral se comunica com outra enviando substâncias químicas chamadas neurotransmissores. Se a célula receptora receber uma quantidade suficiente desses produtos químicos, ela ficará excitada e enviará seus próprios produtos químicos para outra célula.
A unidade fundamental do que às vezes é chamada de rede neural artificial (RNA) é umnó, que, em vez de ser uma célula, é uma função matemática. Assim como os neurônios, eles se comunicam com outros nós se receberem informações suficientes.
É aí que as semelhanças terminam. As redes neurais são estruturadas de forma muito mais simples que o cérebro, com camadas bem definidas: entrada, ocultas e saída. Uma coleção dessas camadas é chamada demodelo.Eles aprendem outreinamtentando repetidamente gerar artificialmente resultados mais parecidos com os resultados desejados. (Mais sobre isso em um minuto.)
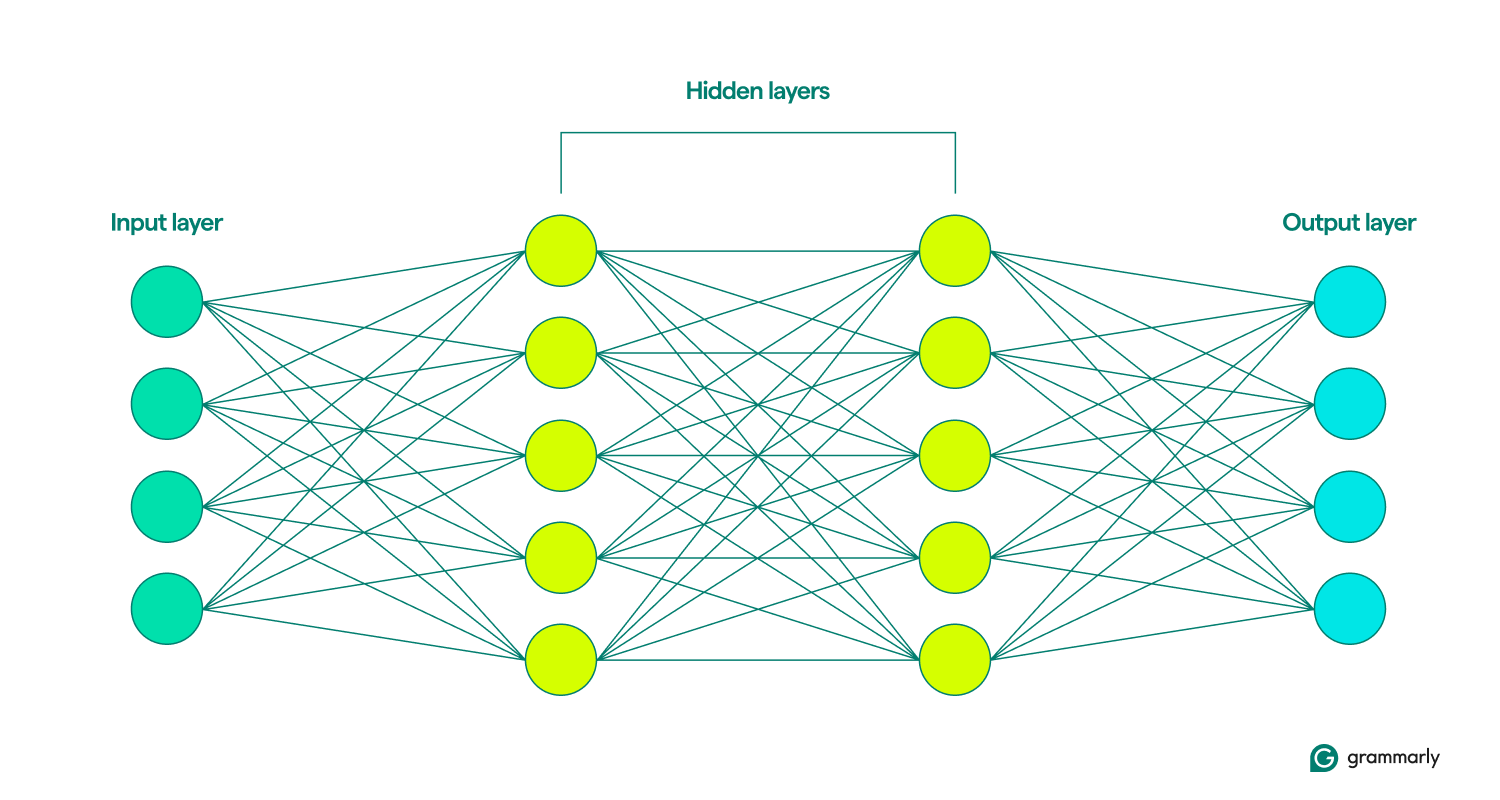
As camadas de entrada e saída são bastante autoexplicativas. A maior parte do que as redes neurais fazem ocorre nas camadas ocultas. Quando um nó é ativado pela entrada de uma camada anterior, ele faz seus cálculos e decide se repassa a saída para os nós da próxima camada. Essas camadas recebem esse nome porque suas operações são invisíveis para o usuário final, embora existam técnicas para os engenheiros verem o que está acontecendo nas chamadas camadas ocultas.
Quando as redes neurais incluem múltiplas camadas ocultas, elas são chamadas de redes de aprendizagem profunda. As redes neurais profundas modernas geralmente têm muitas camadas, incluindo subcamadas especializadas que executam funções distintas. Por exemplo, algumas subcamadas melhoram a capacidade da rede de considerar informações contextuais além da entrada imediata que está sendo analisada.
Como funcionam as redes neurais
Pense em como os bebês aprendem. Eles tentam algo, falham e tentam novamente de uma maneira diferente. O ciclo continua indefinidamente até que eles aperfeiçoem o comportamento. É mais ou menos assim que as redes neurais também aprendem.
Logo no início do treinamento, as redes neurais fazem suposições aleatórias. Um nó na camada de entrada decide aleatoriamente qual dos nós da primeira camada oculta será ativado e, em seguida, esses nós ativam aleatoriamente os nós da próxima camada e assim por diante, até que esse processo aleatório atinja a camada de saída. (Grandes modelos de linguagem, como GPT-4, têm cerca de 100 camadas, com dezenas ou centenas de milhares de nós em cada camada.)
Considerando toda a aleatoriedade, o modelo compara seu resultado – o que provavelmente é terrível – e descobre o quão errado ele estava. Em seguida, ele ajusta a conexão de cada nó com outros nós, alterando o quão mais ou menos propensos eles devem ser à ativação com base em uma determinada entrada. Ele faz isso repetidamente até que seus resultados estejam o mais próximo possível das respostas desejadas.
Então, como as redes neurais sabem o que deveriam estar fazendo? O aprendizado de máquina (ML) pode ser dividido em diferentes abordagens, incluindo aprendizado supervisionado e não supervisionado. Na aprendizagem supervisionada, o modelo é treinado em dados que incluem rótulos ou respostas explícitas, como imagens emparelhadas com texto descritivo. A aprendizagem não supervisionada, no entanto, envolve fornecer ao modelo dados não rotulados, permitindo-lhe identificar padrões e relações de forma independente.
Um complemento comum a este treinamento é o aprendizado por reforço, onde o modelo melhora em resposta ao feedback. Freqüentemente, isso é fornecido por avaliadores humanos (se você já clicou com o polegar para cima ou para baixo na sugestão de um computador, você contribuiu para o aprendizado por reforço). Ainda assim, também existem maneiras de os modelos aprenderem de forma iterativa e independente.
É preciso e instrutivo pensar na saída de uma rede neural como uma previsão. Seja avaliando a qualidade de crédito ou gerando uma música, os modelos de IA funcionam adivinhando o que provavelmente está certo. A IA generativa, como o ChatGPT, leva a previsão um passo adiante. Ele funciona sequencialmente, fazendo suposições sobre o que deve vir após a saída que acabou de gerar. (Veremos por que isso pode ser problemático mais tarde.)
Como as redes neurais geram respostas
Depois que uma rede é treinada, como ela processa as informações que vê para prever a resposta correta? Quando você digita uma mensagem como “Conte-me uma história sobre fadas” na interface do ChatGPT, como o ChatGPT decide como responder?
A primeira etapa é a camada de entrada da rede neural dividir seu prompt em pequenos pedaços de informações, conhecidos comotokens. Para uma rede de reconhecimento de imagem, os tokens podem ser pixels. Para uma rede que usa processamento de linguagem natural (PNL), como ChatGPT, um token normalmente é uma palavra, parte de uma palavra ou uma frase muito curta.
Depois que a rede registra os tokens na entrada, essa informação passa pelas camadas ocultas treinadas anteriormente. Os nós que ele passa de uma camada para a próxima analisam seções cada vez maiores da entrada. Dessa forma, uma rede de PNL pode eventualmente interpretar uma frase ou parágrafo inteiro, não apenas uma palavra ou uma letra.
Agora a rede pode começar a elaborar sua resposta, o que ela faz como uma série de previsões palavra por palavra do que viria a seguir com base em tudo o que foi treinado.
Considere a sugestão: “Conte-me uma história sobre fadas”. Para gerar uma resposta, a rede neural analisa o prompt para prever a primeira palavra mais provável. Por exemplo, pode determinar que há 80% de chance de que “A” seja a melhor escolha, 10% de chance de “A” e 10% de chance de “Uma vez”. Em seguida, seleciona aleatoriamente um número: Se o número estiver entre 1 e 8, escolhe “O”; se for 9, escolhe “A”; e se for 10, escolhe “Uma vez”. Suponha que o número aleatório seja 4, que corresponde a “O”. A rede então atualiza o prompt para “Conte-me uma história sobre fadas. The” e repete o processo para prever a próxima palavra após “The”. Este ciclo continua, com cada nova previsão de palavra baseada no prompt atualizado, até que uma história completa seja gerada.
Redes diferentes farão esta previsão de forma diferente. Por exemplo, um modelo de reconhecimento de imagem pode tentar prever qual rótulo dar à imagem de um cachorro e determinar que há 70% de probabilidade de que o rótulo correto seja “laboratório de chocolate”, 20% para “spaniel inglês” e 10% para “golden retriever”. No caso de classificação, geralmente, a rede irá com a escolha mais provável em vez de uma estimativa probabilística.
Tipos de redes neurais
Aqui está uma visão geral dos diferentes tipos de redes neurais e como elas funcionam.
- Redes neurais feedforward (FNNs): Nesses modelos, as informações fluem em uma direção: da camada de entrada, passando pelas camadas ocultas e, finalmente, até a camada de saída.Esse tipo de modelo é melhor para tarefas de previsão mais simples, como detecção de fraudes de cartão de crédito.
- Redes neurais recorrentes (RNNs): Em contraste com os FNNs, os RNNs consideram entradas anteriores ao gerar uma previsão.Isto os torna adequados para tarefas de processamento de linguagem, uma vez que o final de uma frase gerada em resposta a um prompt depende de como a frase começou.
- Redes de memória de longo prazo (LSTMs): As LSTMs esquecem seletivamente as informações, o que lhes permite trabalhar com mais eficiência.Isto é crucial para processar grandes quantidades de texto; por exemplo, a atualização de 2016 do Google Translate para tradução automática neural contou com LSTMs.
- Redes neurais convolucionais (CNNs): As CNNs funcionam melhor no processamento de imagens.Eles usamcamadas convolucionaispara digitalizar a imagem inteira e procurar recursos como linhas ou formas. Isso permite que as CNNs considerem a localização espacial, como determinar se um objeto está localizado na metade superior ou inferior da imagem, e também identificar uma forma ou tipo de objeto, independentemente de sua localização.
- Redes adversárias generativas (GANs): GANs são frequentemente usadas para gerar novas imagens com base em uma descrição ou em uma imagem existente.Eles estão estruturados como uma competição entre duas redes neurais: uma redegeradora, que tenta enganar uma redediscriminadorafazendo-a acreditar que uma entrada falsa é real.
- Transformadores e redes de atenção: Os transformadores são responsáveis pela atual explosão nas capacidades de IA.Esses modelos incorporam um foco de atenção que lhes permite filtrar suas entradas para focar nos elementos mais importantes e em como esses elementos se relacionam entre si, mesmo em páginas de texto. Os transformadores também podem treinar em enormes quantidades de dados, por isso modelos como ChatGPT e Gemini são chamados demodelos de linguagem grande (LLMs).
Aplicações de redes neurais
Há muitos para listar, então aqui está uma seleção de maneiras pelas quais as redes neurais são usadas hoje, com ênfase na linguagem natural.

Assistência à escrita: Os transformadores transformaram a forma como os computadores podem ajudar as pessoas a escrever melhor.Ferramentas de escrita de IA, como Grammarly, oferecem reescritas de frases e parágrafos para melhorar o tom e a clareza. Este tipo de modelo também melhorou a velocidade e a precisão das sugestões gramaticais básicas. Saiba mais sobre como Grammarly usa IA.
Geração de conteúdo: se você usou ChatGPT ou DALL-E, você experimentou IA generativa em primeira mão.Os transformadores revolucionaram a capacidade dos computadores de criar mídias que ressoam com os humanos, desde histórias para dormir até representações arquitetônicas hiper-realistas.
Reconhecimento de fala: Os computadores estão melhorando a cada dia no reconhecimento da fala humana.Com as tecnologias mais recentes que lhes permitem considerar mais o contexto, os modelos tornaram-se cada vez mais precisos no reconhecimento do que o orador pretende dizer, mesmo que os sons por si só possam ter múltiplas interpretações.
Diagnóstico médico e pesquisa: As redes neurais são excelentes na detecção e classificação de padrões, que são cada vez mais utilizadas para ajudar pesquisadores e profissionais de saúde a compreender e tratar doenças.Por exemplo, devemos agradecer em parte à IA pelo rápido desenvolvimento das vacinas contra a COVID-19.
Desafios e limitações das redes neurais
Aqui está uma breve olhada em algumas, mas não todas, as questões levantadas pelas redes neurais.
Viés: uma rede neural só pode aprender com o que lhe foi dito.Se for exposto a conteúdo sexista ou racista, a sua produção provavelmente também será sexista ou racista. Isto pode ocorrer na tradução de uma língua sem género para uma língua com género, onde os estereótipos persistem sem identificação explícita de género.
Overfitting: um modelo treinado incorretamente pode ler muito nos dados que recebeu e ter dificuldades com novas entradas.Por exemplo, softwares de reconhecimento facial treinados principalmente em pessoas de uma determinada etnia podem ter um desempenho ruim com rostos de outras raças. Ou um filtro de spam pode perder uma nova variedade de lixo eletrônico porque está muito focado em padrões vistos antes.
Alucinações: Grande parte da IA generativa de hoje usa a probabilidade, até certo ponto, para escolher o que produzir, em vez de sempre selecionar a escolha mais bem classificada.Esta abordagem ajuda-o a ser mais criativo e a produzir textos que soam mais naturais, mas também pode levá-lo a fazer afirmações que são simplesmente falsas. (É também por isso que os LLMs às vezes erram na matemática básica.) Infelizmente, essas alucinações são difíceis de detectar, a menos que você saiba melhor ou verifique os fatos com outras fontes.
Interpretabilidade: Muitas vezes é impossível saber exatamente como uma rede neural faz previsões.Embora isto possa ser frustrante do ponto de vista de alguém que tenta melhorar o modelo, também pode ter consequências, uma vez que se confia cada vez mais na IA para tomar decisões que têm grande impacto na vida das pessoas. Alguns modelos usados hoje não são baseados em redes neurais precisamente porque seus criadores desejam poder inspecionar e compreender cada etapa do processo.
Propriedade intelectual: Muitos acreditam que os LLMs violam os direitos autorais ao incorporar textos e outras obras de arte sem permissão.Embora tendam a não reproduzir diretamente obras protegidas por direitos autorais, sabe-se que esses modelos criam imagens ou frases que provavelmente são derivadas de artistas específicos ou até mesmo criam obras no estilo distinto de um artista quando solicitado.
Consumo de energia: Todo esse treinamento e operação de modelos de transformadores consome uma energia enorme.Na verdade, dentro de alguns anos, a IA poderá consumir tanta energia como a Suécia ou a Argentina. Isto destaca a crescente importância de considerar as fontes de energia e a eficiência no desenvolvimento da IA.
Futuro das redes neurais
Prever o futuro da IA é notoriamente difícil. Em 1970, um dos principais investigadores de IA previu que “dentro de três a oito anos, teremos uma máquina com a inteligência geral de um ser humano médio”. (Ainda não estamos muito próximos da inteligência artificial geral (AGI). Pelo menos a maioria das pessoas não pensa assim.)
No entanto, podemos apontar algumas tendências a serem observadas. Modelos mais eficientes reduziriam o consumo de energia e executariam redes neurais mais poderosas diretamente em dispositivos como smartphones. Novas técnicas de treinamento poderiam permitir previsões mais úteis com menos dados de treinamento. Um avanço na interpretabilidade poderia aumentar a confiança e abrir novos caminhos para melhorar a produção da rede neural. Finalmente, combinar a computação quântica e as redes neurais poderá levar a inovações que apenas podemos começar a imaginar.
Conclusão
As redes neurais, inspiradas na estrutura e função do cérebro humano, são fundamentais para a inteligência artificial moderna. Eles se destacam em tarefas de reconhecimento e previsão de padrões, sustentando muitas das aplicações atuais de IA, desde reconhecimento de imagem e fala até processamento de linguagem natural. Com os avanços na arquitetura e nas técnicas de treinamento, as redes neurais continuam a gerar melhorias significativas nas capacidades de IA.
Apesar do seu potencial, as redes neurais enfrentam desafios como viés, overfitting e alto consumo de energia. Abordar estas questões é crucial à medida que a IA continua a evoluir. Olhando para o futuro, as inovações na eficiência dos modelos, na interpretabilidade e na integração com a computação quântica prometem expandir ainda mais as possibilidades das redes neurais, levando potencialmente a aplicações ainda mais transformadoras.