
Noções básicas de redes neurais recorrentes: o que você precisa saber
Publicados: 2024-09-19Redes neurais recorrentes (RNNs) são métodos essenciais nas áreas de análise de dados, aprendizado de máquina (ML) e aprendizado profundo. Este artigo tem como objetivo explorar RNNs e detalhar suas funcionalidades, aplicações e vantagens e desvantagens no contexto mais amplo de aprendizagem profunda.
Índice
O que é uma RNN?
Como funcionam as RNNs
Tipos de RNNs
RNNs vs. transformadores e CNNs
Aplicações de RNNs
Vantagens
Desvantagens
O que é uma rede neural recorrente?
Uma rede neural recorrente é uma rede neural profunda que pode processar dados sequenciais mantendo uma memória interna, permitindo rastrear entradas anteriores para gerar saídas. RNNs são um componente fundamental do aprendizado profundo e são particularmente adequados para tarefas que envolvem dados sequenciais.
O “recorrente” em “rede neural recorrente” refere-se a como o modelo combina informações de entradas anteriores com entradas atuais. As informações de entradas antigas são armazenadas em uma espécie de memória interna, chamada de “estado oculto”. Ele se repete – alimentando cálculos anteriores de volta para si mesmo para criar um fluxo contínuo de informações.
Vamos demonstrar com um exemplo: suponha que quiséssemos usar um RNN para detectar o sentimento (positivo ou negativo) da frase “Ele comeu a torta feliz”. O RNN processaria a palavrahe, atualizaria seu estado oculto para incorporar essa palavra e, em seguida, passaria paraate, combinaria isso com o que aprendeu comhe, e assim por diante com cada palavra até que a frase fosse concluída. Para colocar isso em perspectiva, um ser humano que lesse esta frase atualizaria seu entendimento a cada palavra. Depois de ler e compreender a frase inteira, o humano pode dizer que a frase é positiva ou negativa. Este processo humano de compreensão é o que o estado oculto tenta aproximar.
RNNs são um dos modelos fundamentais de aprendizagem profunda. Eles se saíram muito bem em tarefas de processamento de linguagem natural (PNL), embora os transformadores os tenham suplantado. Os transformadores são arquiteturas de redes neurais avançadas que melhoram o desempenho da RNN, por exemplo, processando dados em paralelo e sendo capazes de descobrir relações entre palavras que estão distantes umas das outras no texto fonte (usando mecanismos de atenção). No entanto, as RNNs ainda são úteis para dados de séries temporais e para situações onde modelos mais simples são suficientes.
Como funcionam as RNNs
Para descrever em detalhes como funcionam os RNNs, vamos retornar à tarefa de exemplo anterior: Classificar o sentimento da frase “Ele comeu a torta felizmente”.
Começamos com um RNN treinado que aceita entradas de texto e retorna uma saída binária (1 representando positivo e 0 representando negativo). Antes de a entrada ser fornecida ao modelo, o estado oculto é genérico – foi aprendido no processo de treinamento, mas ainda não é específico da entrada.
A primeira palavra,He, é passada para o modelo. Dentro da RNN, seu estado oculto é então atualizado (para o estado oculto h1) para incorporar a palavraHe. Em seguida, a palavraateé passada para o RNN e h1 é atualizado (para h2) para incluir esta nova palavra. Este processo se repete até que a última palavra seja passada. O estado oculto (h4) é atualizado para incluir a última palavra. Em seguida, o estado oculto atualizado é usado para gerar 0 ou 1.
Aqui está uma representação visual de como funciona o processo RNN:
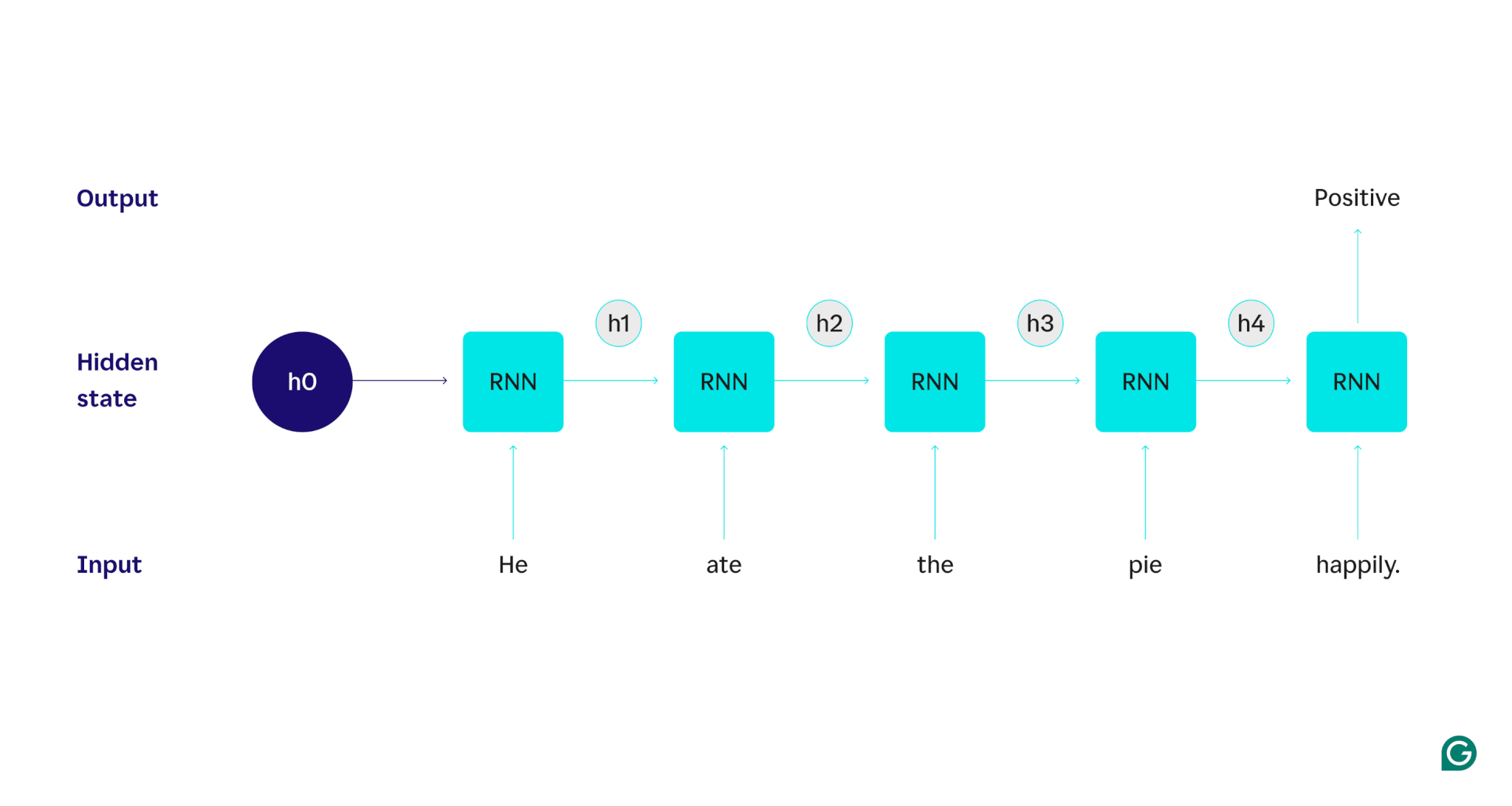
Essa recorrência é o cerne da RNN, mas existem algumas outras considerações:
- Incorporação de texto:O RNN não pode processar texto diretamente, pois funciona apenas em representações numéricas. O texto deve ser convertido em embeddings antes de poder ser processado por um RNN.
- Geração de saída:Uma saída será gerada pelo RNN em cada etapa. No entanto, a saída pode não ser muito precisa até que a maior parte dos dados de origem seja processada. Por exemplo, depois de processar apenas a parte “Ele comeu” da frase, o RNN pode não ter certeza se representa um sentimento positivo ou negativo – “Ele comeu” pode parecer neutro. Somente após o processamento da frase completa a saída do RNN seria precisa.
- Treinando o RNN:O RNN deve ser treinado para realizar análises de sentimento com precisão. O treinamento envolve o uso de muitos exemplos rotulados (por exemplo, “Ele comeu a torta com raiva”, rotulados como negativos), executá-los no RNN e ajustar o modelo com base em quão distantes estão suas previsões. Este processo define o valor padrão e o mecanismo de alteração para o estado oculto, permitindo que o RNN aprenda quais palavras são significativas para rastreamento em toda a entrada.
Tipos de redes neurais recorrentes
Existem vários tipos diferentes de RNNs, cada um variando em sua estrutura e aplicação. RNNs básicos diferem principalmente no tamanho de suas entradas e saídas. RNNs avançados, como redes de memória de longo e curto prazo (LSTM), abordam algumas das limitações dos RNNs básicos.
RNNs básicos
RNN um para um:Este RNN recebe uma entrada de comprimento um e retorna uma saída de comprimento um. Portanto, nenhuma recorrência realmente acontece, tornando-a uma rede neural padrão em vez de uma RNN. Um exemplo de RNN um para um seria um classificador de imagem, onde a entrada é uma única imagem e a saída é um rótulo (por exemplo, “pássaro”).
RNN um para muitos:Este RNN recebe uma entrada de comprimento um e retorna uma saída multipartes. Por exemplo, em uma tarefa de legendagem de imagens, a entrada é uma imagem e a saída é uma sequência de palavras que descrevem a imagem (por exemplo, “Um pássaro atravessa um rio em um dia ensolarado”).
RNN muitos para um:Este RNN recebe uma entrada multipartes (por exemplo, uma frase, uma série de imagens ou dados de série temporal) e retorna uma saída de comprimento um. Por exemplo, um classificador de sentimento de frase (como o que discutimos), onde a entrada é uma frase e a saída é um único rótulo de sentimento (positivo ou negativo).
RNN muitos para muitos:Este RNN recebe uma entrada multipartes e retorna uma saída multipartes. Um exemplo é um modelo de reconhecimento de fala, onde a entrada é uma série de formas de onda de áudio e a saída é uma sequência de palavras que representam o conteúdo falado.
RNN avançado: memória longa de curto prazo (LSTM)
As redes de memória de longo e curto prazo são projetadas para resolver um problema significativo com RNNs padrão: elas esquecem informações em entradas longas. Em RNNs padrão, o estado oculto tem grande peso nas partes recentes da entrada. Em uma entrada com milhares de palavras, o RNN esquecerá detalhes importantes das frases iniciais. Os LSTMs possuem uma arquitetura especial para contornar esse problema de esquecimento. Eles têm módulos que escolhem quais informações lembrar e esquecer explicitamente. Assim, as informações recentes, mas inúteis, serão esquecidas, enquanto as informações antigas, mas relevantes, serão retidas. Como resultado, os LSTMs são muito mais comuns que os RNNs padrão – eles simplesmente apresentam melhor desempenho em tarefas complexas ou longas. No entanto, eles não são perfeitos, pois ainda optam por esquecer itens.
RNNs vs. transformadores e CNNs
Dois outros modelos comuns de aprendizagem profunda são redes neurais convolucionais (CNNs) e transformadores. Como eles diferem?

RNNs vs. transformadores
Tanto RNNs quanto transformadores são muito usados em PNL. No entanto, eles diferem significativamente em suas arquiteturas e abordagens para processar entradas.
Arquitetura e processamento
- RNNs:RNNs processam a entrada sequencialmente, uma palavra por vez, mantendo um estado oculto que transporta informações de palavras anteriores. Esta natureza sequencial significa que as RNNs podem lutar com dependências de longo prazo devido a este esquecimento, em que informações anteriores podem ser perdidas à medida que a sequência avança.
- Transformadores:Os transformadores usam um mecanismo chamado “atenção” para processar a entrada. Ao contrário dos RNNs, os transformadores analisam toda a sequência simultaneamente, comparando cada palavra com todas as outras palavras. Essa abordagem elimina o problema do esquecimento, pois cada palavra tem acesso direto a todo o contexto de entrada. Os Transformers demonstraram desempenho superior em tarefas como geração de texto e análise de sentimentos devido a esse recurso.
Paralelização
- RNNs:A natureza sequencial dos RNNs significa que o modelo deve concluir o processamento de uma parte da entrada antes de passar para a próxima. Isso consome muito tempo, pois cada etapa depende da anterior.
- Transformadores:Os transformadores processam todas as partes da entrada simultaneamente, pois sua arquitetura não depende de um estado oculto sequencial. Isso os torna muito mais paralelizáveis e eficientes. Por exemplo, se o processamento de uma frase levar 5 segundos por palavra, um RNN levaria 25 segundos para uma frase de 5 palavras, enquanto um transformador levaria apenas 5 segundos.
Implicações práticas
Devido a essas vantagens, os transformadores são mais amplamente utilizados na indústria. No entanto, as RNNs, especialmente as redes de memória de longo e curto prazo (LSTM), ainda podem ser eficazes para tarefas mais simples ou ao lidar com sequências mais curtas. LSTMs são frequentemente usados como módulos críticos de armazenamento de memória em grandes arquiteturas de aprendizado de máquina.
RNNs x CNNs
As CNNs são fundamentalmente diferentes das RNNs em termos dos dados que manipulam e dos seus mecanismos operacionais.
Tipo de dados
- RNNs:RNNs são projetados para dados sequenciais, como texto ou séries temporais, onde a ordem dos pontos de dados é importante.
- CNNs:CNNs são usadas principalmente para dados espaciais, como imagens, onde o foco está nas relações entre pontos de dados adjacentes (por exemplo, a cor, intensidade e outras propriedades de um pixel em uma imagem estão intimamente relacionadas às propriedades de outros pixels próximos). pixels).
Operação
- RNNs:RNNs mantêm uma memória de toda a sequência, tornando-os adequados para tarefas onde o contexto e a sequência são importantes.
- CNNs:As CNNs operam observando regiões locais da entrada (por exemplo, pixels vizinhos) através de camadas convolucionais. Isso os torna altamente eficazes para processamento de imagens, mas menos eficazes para dados sequenciais, onde as dependências de longo prazo podem ser mais importantes.
Comprimento de entrada
- RNNs:RNNs podem lidar com sequências de entrada de comprimento variável com uma estrutura menos definida, tornando-as flexíveis para diferentes tipos de dados sequenciais.
- CNNs:CNNs normalmente exigem entradas de tamanho fixo, o que pode ser uma limitação para lidar com sequências de comprimento variável.
Aplicações de RNNs
RNNs são amplamente utilizados em vários campos devido à sua capacidade de lidar com dados sequenciais de forma eficaz.
Processamento de linguagem natural
A linguagem é uma forma de dados altamente sequencial, portanto os RNNs têm um bom desempenho em tarefas linguísticas. RNNs se destacam em tarefas como geração de texto, análise de sentimento, tradução e resumo. Com bibliotecas como PyTorch, alguém poderia criar um chatbot simples usando um RNN e alguns gigabytes de exemplos de texto.
Reconhecimento de fala
O reconhecimento de fala é a linguagem em sua essência e, portanto, também é altamente sequencial. Um RNN muitos para muitos poderia ser usado para esta tarefa. A cada passo, o RNN assume o estado oculto anterior e a forma de onda, emitindo a palavra associada à forma de onda (com base no contexto da frase até aquele ponto).
Geração musical
A música também é altamente sequencial. As batidas anteriores de uma música influenciam fortemente as batidas futuras. Um RNN muitos para muitos poderia receber algumas batidas iniciais como entrada e então gerar batidas adicionais conforme desejado pelo usuário. Alternativamente, ele poderia receber uma entrada de texto como “jazz melódico” e produzir sua melhor aproximação de batidas de jazz melódico.
Vantagens dos RNNs
Embora os RNNs não sejam mais o modelo de PNL de fato, eles ainda têm alguns usos devido a alguns fatores.
Bom desempenho sequencial
RNNs, especialmente LSTMs, funcionam bem em dados sequenciais. Os LSTMs, com sua arquitetura de memória especializada, podem gerenciar entradas sequenciais longas e complexas. Por exemplo, o Google Translate costumava rodar em um modelo LSTM antes da era dos transformadores. LSTMs podem ser usados para adicionar módulos de memória estratégicos quando redes baseadas em transformadores são combinadas para formar arquiteturas mais avançadas.
Modelos menores e mais simples
RNNs geralmente têm menos parâmetros de modelo que transformadores. As camadas de atenção e feedforward nos transformadores requerem mais parâmetros para funcionar de forma eficaz. As RNNs podem ser treinadas com menos execuções e exemplos de dados, tornando-as mais eficientes para casos de uso mais simples. Isso resulta em modelos menores, mais baratos e mais eficientes, que ainda apresentam desempenho suficiente.
Desvantagens dos RNNs
As RNNs caíram em desuso por um motivo: os transformadores, apesar de seu tamanho e processo de treinamento maiores, não têm as mesmas falhas que as RNNs.
Memória limitada
O estado oculto nas RNNs padrão influencia fortemente as entradas recentes, dificultando a retenção de dependências de longo alcance. Tarefas com entradas longas não funcionam tão bem com RNNs. Embora os LSTM pretendam resolver este problema, apenas o atenuam e não o resolvem totalmente. Muitas tarefas de IA exigem o tratamento de entradas longas, tornando a memória limitada uma desvantagem significativa.
Não paralelizável
Cada execução do modelo RNN depende da saída da execução anterior, especificamente do estado oculto atualizado. Como resultado, todo o modelo deve ser processado sequencialmente para cada parte de uma entrada. Em contraste, transformadores e CNNs podem processar toda a entrada simultaneamente. Isso permite o processamento paralelo em várias GPUs, acelerando significativamente a computação. A falta de paralelização das RNNs leva a um treinamento mais lento, à geração de resultados mais lenta e a uma quantidade máxima menor de dados com os quais se pode aprender.
Problemas de gradiente
O treinamento de RNNs pode ser desafiador porque o processo de retropropagação deve passar por cada etapa de entrada (retropropagação ao longo do tempo). Devido aos muitos intervalos de tempo, os gradientes – que indicam como cada parâmetro do modelo deve ser ajustado – podem degradar-se e tornar-se ineficazes. Os gradientes podem falhar ao desaparecer, o que significa que se tornam muito pequenos e o modelo não pode mais usá-los para aprender, ou ao explodir, onde os gradientes se tornam muito grandes e o modelo ultrapassa suas atualizações, tornando o modelo inutilizável. Equilibrar essas questões é difícil.