
O que é um codificador automático? Um guia para iniciantes
Publicados: 2024-10-28Os codificadores automáticos são um componente essencial do aprendizado profundo, especialmente em tarefas de aprendizado de máquina não supervisionadas. Neste artigo, exploraremos como funcionam os autoencoders, sua arquitetura e os vários tipos disponíveis. Você também descobrirá suas aplicações no mundo real, juntamente com as vantagens e desvantagens envolvidas em seu uso.
Índice
- O que é um codificador automático?
- Arquitetura do codificador automático
- Tipos de codificadores automáticos
- Aplicativo
- Vantagens
- Desvantagens
O que é um codificador automático?
Autoencoders são um tipo de rede neural usada em aprendizado profundo para aprender representações eficientes e de menor dimensão dos dados de entrada, que são então usadas para reconstruir os dados originais. Ao fazer isso, esta rede aprende as características mais essenciais dos dados durante o treinamento sem exigir rótulos explícitos, tornando-os parte da aprendizagem auto-supervisionada. Os codificadores automáticos são amplamente aplicados em tarefas como eliminação de ruído de imagens, detecção de anomalias e compactação de dados, onde sua capacidade de compactar e reconstruir dados é valiosa.
Arquitetura do codificador automático
Um autoencoder é composto de três partes: um codificador, um gargalo (também conhecido como espaço latente ou código) e um decodificador. Esses componentes trabalham juntos para capturar os principais recursos dos dados de entrada e usá-los para gerar reconstruções precisas.
Os autoencoders otimizam sua saída ajustando os pesos do codificador e do decodificador, com o objetivo de produzir uma representação compactada da entrada que preserve recursos críticos. Esta otimização minimiza o erro de reconstrução, que representa a diferença entre os dados de entrada e de saída.
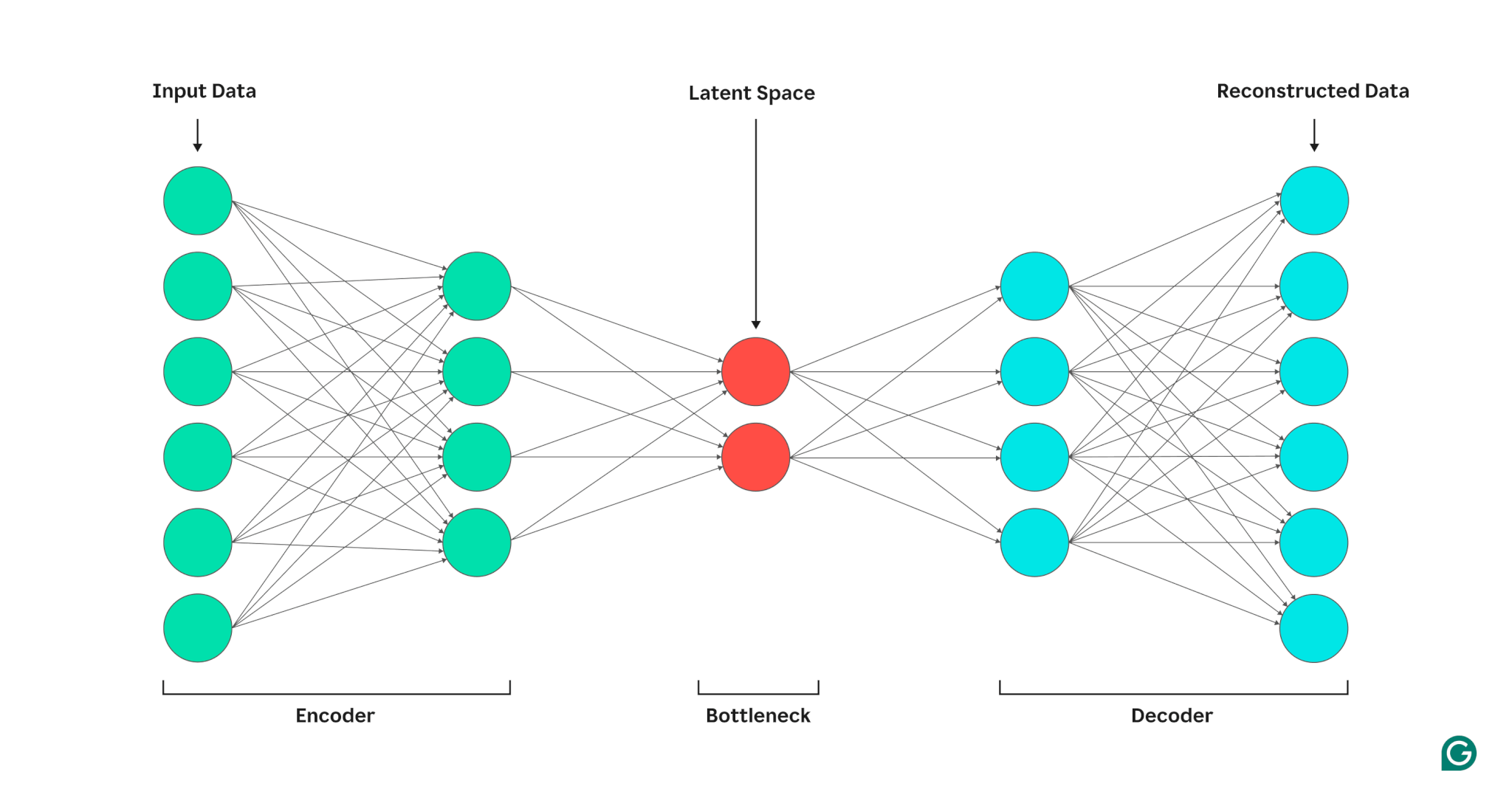
Codificador
Primeiro, o codificador compacta os dados de entrada em uma representação mais eficiente. Os codificadores geralmente consistem em múltiplas camadas com menos nós em cada camada. À medida que os dados são processados em cada camada, o número reduzido de nós força a rede a aprender os recursos mais importantes dos dados para criar uma representação que possa ser armazenada em cada camada. Este processo, conhecido como redução de dimensionalidade, transforma a entrada em um resumo compacto das principais características dos dados. Os principais hiperparâmetros no codificador incluem o número de camadas e neurônios por camada, que determinam a profundidade e granularidade da compactação, e a função de ativação, que determina como os recursos de dados são representados e transformados em cada camada.
Gargalo
O gargalo, também conhecido como espaço latente ou código, é onde a representação compactada dos dados de entrada é armazenada durante o processamento. O gargalo possui um pequeno número de nós; isso limita a quantidade de dados que podem ser armazenados e determina o nível de compactação. O número de nós no gargalo é um hiperparâmetro ajustável, permitindo aos usuários controlar a compensação entre compactação e retenção de dados. Se o gargalo for muito pequeno, o autoencoder poderá reconstruir os dados incorretamente devido à perda de detalhes importantes. Por outro lado, se o gargalo for muito grande, o autoencoder pode simplesmente copiar os dados de entrada em vez de aprender uma representação geral significativa.
Decodificador
Nesta etapa final, o decodificador recria os dados originais do formato compactado usando os principais recursos aprendidos durante o processo de codificação. A qualidade desta descompressão é quantificada usando o erro de reconstrução, que é essencialmente uma medida de quão diferentes são os dados reconstruídos da entrada. O erro de reconstrução é geralmente calculado usando o erro quadrático médio (MSE). Como o MSE mede a diferença quadrática entre os dados originais e os reconstruídos, ele fornece uma maneira matematicamente direta de penalizar mais fortemente erros de reconstrução maiores.
Tipos de codificadores automáticos
Existem vários tipos de autoencoders especializados, cada um otimizado para aplicações específicas, semelhantes a outras redes neurais.
Remoção de ruído de autoencoders
Os autoencoders de eliminação de ruído são projetados para reconstruir dados limpos de entradas ruidosas ou corrompidas. Durante o treinamento, o ruído é adicionado intencionalmente aos dados de entrada, permitindo que o modelo aprenda recursos que permanecem consistentes apesar do ruído. As saídas são então comparadas com as entradas limpas originais. Esse processo torna os codificadores automáticos de eliminação de ruído altamente eficazes em tarefas de redução de ruído de imagem e áudio, incluindo a remoção de ruído de fundo em videoconferências.
Autoencoders esparsos
Autoencoders esparsos restringem o número de neurônios ativos em um determinado momento, incentivando a rede a aprender representações de dados mais eficientes em comparação com autoencoders padrão. Essa restrição de dispersão é imposta por meio de uma penalidade que desencoraja a ativação de mais neurônios do que um limite especificado. Autoencoders esparsos simplificam dados de alta dimensão enquanto preservam recursos essenciais, tornando-os valiosos para tarefas como extração de recursos interpretáveis e visualização de conjuntos de dados complexos.
Autoencoders variacionais (VAEs)
Ao contrário dos autoencoders típicos, os VAEs geram novos dados codificando recursos dos dados de treinamento em uma distribuição de probabilidade, em vez de um ponto fixo. Ao amostrar esta distribuição, os VAEs podem gerar diversos novos dados, em vez de reconstruir os dados originais a partir da entrada. Esta capacidade torna os VAEs úteis para tarefas generativas, incluindo geração de dados sintéticos. Por exemplo, na geração de imagens, um VAE treinado em um conjunto de dados de números manuscritos pode criar novos dígitos de aparência realista com base no conjunto de treinamento que não são réplicas exatas.

Autoencoders contrativos
Os autoencoders contrativos introduzem um termo de penalidade adicional durante o cálculo do erro de reconstrução, incentivando o modelo a aprender representações de recursos que sejam robustas ao ruído. Essa penalidade ajuda a prevenir o overfitting, promovendo o aprendizado de recursos que é invariante a pequenas variações nos dados de entrada. Como resultado, os autoencoders contrativos são mais robustos ao ruído do que os autoencoders padrão.
Autoencodificadores convolucionais (CAEs)
Os CAEs utilizam camadas convolucionais para capturar hierarquias e padrões espaciais em dados de alta dimensão. O uso de camadas convolucionais torna os CAEs particularmente adequados para o processamento de dados de imagem. CAEs são comumente usados em tarefas como compactação de imagens e detecção de anomalias em imagens.
Aplicações de autoencoders em IA
Os codificadores automáticos têm diversas aplicações, como redução de dimensionalidade, eliminação de ruído de imagem e detecção de anomalias.
Redução de dimensionalidade
Os codificadores automáticos são ferramentas eficazes para reduzir a dimensionalidade dos dados de entrada e, ao mesmo tempo, preservar os principais recursos. Esse processo é valioso para tarefas como visualização de conjuntos de dados de alta dimensão e compactação de dados. Ao simplificar os dados, a redução da dimensionalidade também aumenta a eficiência computacional, diminuindo o tamanho e a complexidade.
Detecção de anomalias
Ao aprender os principais recursos de um conjunto de dados de destino, os codificadores automáticos podem distinguir entre dados normais e anômalos quando recebem uma nova entrada. O desvio do normal é indicado por taxas de erro de reconstrução superiores ao normal. Como tal, os autoencoders podem ser aplicados a diversos domínios, como manutenção preditiva e segurança de redes de computadores.
Eliminação de ruído
Os autoencoders de eliminação de ruído podem limpar dados ruidosos, aprendendo a reconstruí-los a partir de entradas de treinamento ruidosas. Esse recurso torna os codificadores automáticos de eliminação de ruído valiosos para tarefas como otimização de imagens, incluindo o aprimoramento da qualidade de fotografias borradas. Os autoencoders de eliminação de ruído também são úteis no processamento de sinais, onde podem limpar sinais ruidosos para processamento e análise mais eficientes.
Vantagens dos codificadores automáticos
Os codificadores automáticos têm uma série de vantagens importantes. Isso inclui a capacidade de aprender com dados não rotulados, aprender recursos automaticamente sem instruções explícitas e extrair recursos não lineares.
Capaz de aprender com dados não rotulados
Os codificadores automáticos são um modelo de aprendizado de máquina não supervisionado, o que significa que eles podem aprender recursos de dados subjacentes a partir de dados não rotulados. Esse recurso significa que os codificadores automáticos podem ser aplicados a tarefas onde os dados rotulados podem ser escassos ou indisponíveis.
Aprendizado automático de recursos
Técnicas padrão de extração de recursos, como análise de componentes principais (PCA), muitas vezes são impraticáveis quando se trata de lidar com conjuntos de dados complexos e/ou grandes. Como os codificadores automáticos foram projetados com tarefas como redução de dimensionalidade em mente, eles podem aprender automaticamente os principais recursos e padrões nos dados sem o design manual de recursos.
Extração de recursos não lineares
Os codificadores automáticos podem lidar com relacionamentos não lineares em dados de entrada, permitindo que o modelo capture os principais recursos de representações de dados mais complexas. Essa capacidade significa que os codificadores automáticos têm uma vantagem sobre os modelos que funcionam apenas com dados lineares, pois podem lidar com conjuntos de dados mais complexos.
Limitações dos codificadores automáticos
Como outros modelos de ML, os codificadores automáticos apresentam seu próprio conjunto de desvantagens. Isso inclui a falta de interpretabilidade, a necessidade de grandes conjuntos de dados de treinamento para um bom desempenho e capacidades limitadas de generalização.
Falta de interpretabilidade
Semelhante a outros modelos complexos de ML, os autoencoders sofrem de falta de interpretabilidade, o que significa que é difícil entender a relação entre os dados de entrada e a saída do modelo. Nos autoencoders, essa falta de interpretabilidade ocorre porque os autoencoders aprendem recursos automaticamente, em oposição aos modelos tradicionais, onde os recursos são definidos explicitamente. Essa representação de recursos gerada por máquina é muitas vezes altamente abstrata e tende a não ter recursos interpretáveis por humanos, dificultando a compreensão do que cada componente da representação significa.
Exigir grandes conjuntos de dados de treinamento
Os codificadores automáticos normalmente exigem grandes conjuntos de dados de treinamento para aprender representações generalizáveis dos principais recursos de dados. Dados pequenos conjuntos de dados de treinamento, os codificadores automáticos podem tender a se ajustar demais, levando a uma generalização deficiente quando novos dados são apresentados. Grandes conjuntos de dados, por outro lado, fornecem a diversidade necessária para que o autoencoder aprenda recursos de dados que podem ser aplicados em uma ampla variedade de cenários.
Generalização limitada sobre novos dados
Os codificadores automáticos treinados em um conjunto de dados geralmente têm recursos de generalização limitados, o que significa que não conseguem se adaptar a novos conjuntos de dados. Essa limitação ocorre porque os codificadores automáticos são voltados para a reconstrução de dados com base em recursos proeminentes de um determinado conjunto de dados. Dessa forma, os codificadores automáticos geralmente eliminam detalhes menores dos dados durante o treinamento e não conseguem lidar com dados que não se enquadram na representação generalizada de recursos.