
O que é uma árvore de decisão em aprendizado de máquina?
Publicados: 2024-08-14As árvores de decisão são uma das ferramentas mais comuns no kit de ferramentas de aprendizado de máquina de um analista de dados. Neste guia, você aprenderá o que são árvores de decisão, como são construídas, vários aplicativos, benefícios e muito mais.
Índice
- O que é uma árvore de decisão?
- Terminologia da árvore de decisão
- Tipos de árvores de decisão
- Como funcionam as árvores de decisão
- Aplicativos
- Vantagens
- Desvantagens
O que é uma árvore de decisão?
No aprendizado de máquina (ML), uma árvore de decisão é um algoritmo de aprendizado supervisionado que se assemelha a um fluxograma ou gráfico de decisão. Ao contrário de muitos outros algoritmos de aprendizagem supervisionada, as árvores de decisão podem ser usadas tanto para tarefas de classificação quanto para tarefas de regressão. Cientistas e analistas de dados costumam usar árvores de decisão ao explorar novos conjuntos de dados porque são fáceis de construir e interpretar. Além disso, as árvores de decisão podem ajudar a identificar recursos de dados importantes que podem ser úteis na aplicação de algoritmos de ML mais complexos.
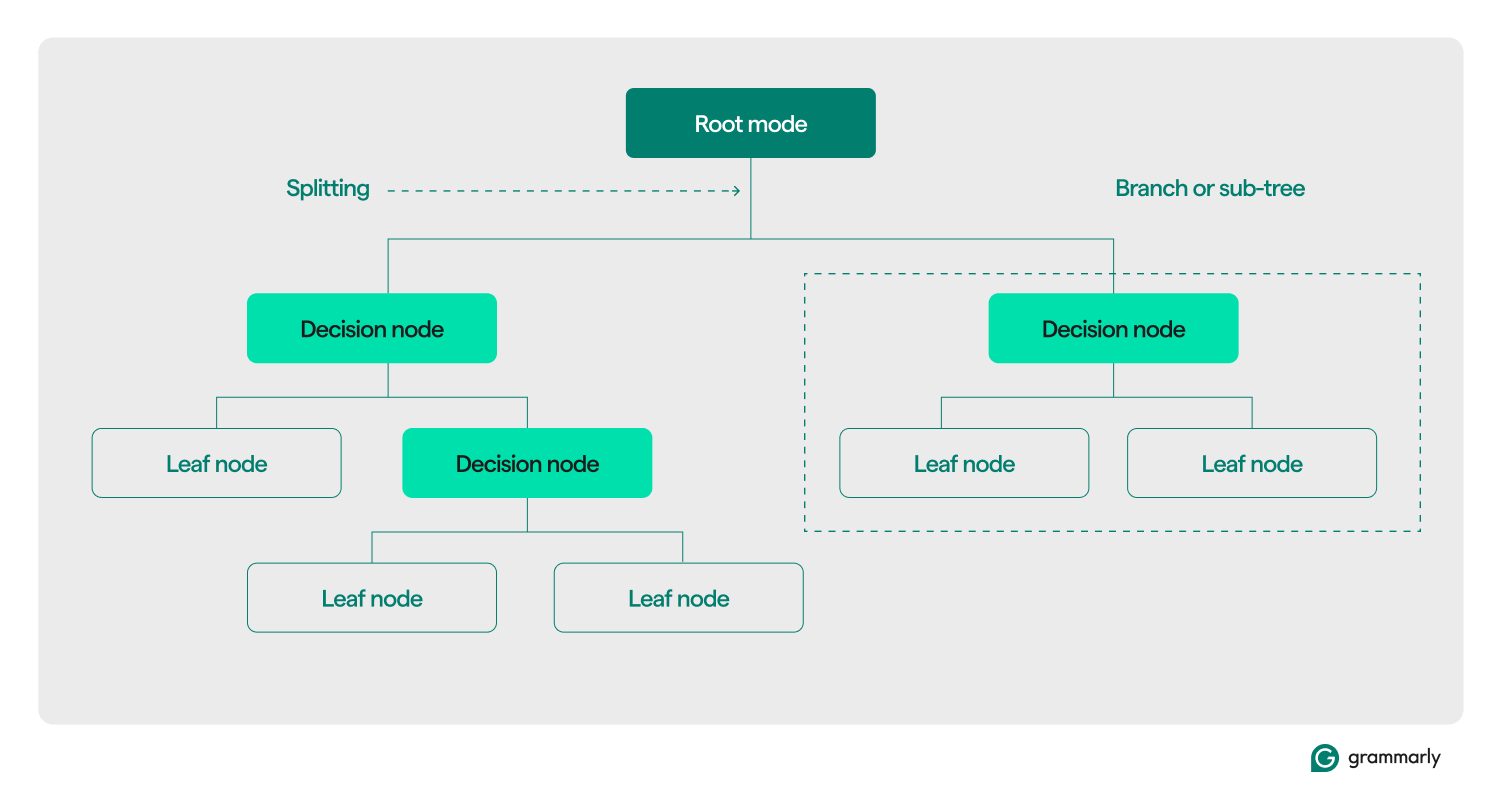
Terminologia da árvore de decisão
Estruturalmente, uma árvore de decisão normalmente consiste em três componentes: um nó raiz, nós folha e nós de decisão (ou internos). Assim como fluxogramas ou árvores em outros domínios, as decisões em uma árvore geralmente se movem em uma direção (para baixo ou para cima), começando no nó raiz, passando por alguns nós de decisão e terminando em um nó folha específico. Cada nó folha conecta um subconjunto de dados de treinamento a um rótulo. A árvore é montada por meio de um processo de treinamento e otimização de ML e, uma vez construída, pode ser aplicada a vários conjuntos de dados.
Aqui está um mergulho mais profundo no resto da terminologia:
- Nó raiz:um nó que contém a primeira de uma série de perguntas que a árvore de decisão fará sobre os dados. O nó será conectado a pelo menos um (mas geralmente dois ou mais) nós de decisão ou folha.
- Nós de decisão (ou nós internos):nós adicionais contendo perguntas. Um nó de decisão conterá exatamente uma pergunta sobre os dados e direcionará o fluxo de dados para um de seus filhos com base na resposta.
- Filhos:Um ou mais nós para os quais um nó raiz ou de decisão aponta. Eles representam uma lista das próximas opções que o processo de tomada de decisão pode tomar ao analisar os dados.
- Nós folha (ou nós terminais):Nós que indicam que o processo de decisão foi concluído. Assim que o processo de decisão atingir um nó folha, ele retornará o(s) valor(es) do nó folha como sua saída.
- Rótulo (classe, categoria):Geralmente, uma string associada por um nó folha a alguns dos dados de treinamento. Por exemplo, uma folha pode associar o rótulo “Cliente satisfeito” a um conjunto de clientes específicos aos quais o algoritmo de treinamento de ML da árvore de decisão foi apresentado.
- Ramo (ou subárvore):Este é o conjunto de nós que consiste em um nó de decisão em qualquer ponto da árvore, junto com todos os seus filhos e seus filhos, até os nós folha.
- Poda:Uma operação de otimização normalmente executada na árvore para torná-la menor e ajudá-la a retornar resultados mais rapidamente. A poda geralmente se refere à “pós-poda”, que envolve a remoção algorítmica de nós ou ramificações após o processo de treinamento de ML ter construído a árvore. “Pré-poda” refere-se ao estabelecimento de um limite arbitrário de quão profunda ou grande uma árvore de decisão pode crescer durante o treinamento. Ambos os processos impõem uma complexidade máxima à árvore de decisão, geralmente medida pela sua profundidade ou altura máxima. Otimizações menos comuns incluem limitar o número máximo de nós de decisão ou nós folha.
- Divisão:A principal etapa de transformação realizada em uma árvore de decisão durante o treinamento. Envolve dividir uma raiz ou nó de decisão em dois ou mais subnós.
- Classificação:um algoritmo de ML que tenta descobrir qual (de uma lista constante e discreta de classes, categorias ou rótulos) é o mais provável de ser aplicado a um dado. Pode tentar responder a perguntas como “Qual dia da semana é melhor para reservar um voo?” Mais sobre classificação abaixo.
- Regressão:um algoritmo de ML que tenta prever um valor contínuo, que nem sempre pode ter limites. Pode tentar responder (ou prever a resposta) a perguntas como “Quantas pessoas provavelmente reservarão um voo na próxima terça-feira?” Falaremos mais sobre árvores de regressão na próxima seção.
Tipos de árvores de decisão
As árvores de decisão são normalmente agrupadas em duas categorias: árvores de classificação e árvores de regressão. Uma árvore específica pode ser construída para aplicação em classificação, regressão ou ambos os casos de uso. A maioria das árvores de decisão modernas usa o algoritmo CART (Árvores de Classificação e Regressão), que pode executar ambos os tipos de tarefas.
Árvores de classificação
As árvores de classificação, o tipo mais comum de árvore de decisão, tentam resolver um problema de classificação. A partir de uma lista de respostas possíveis a uma pergunta (geralmente tão simples como “sim” ou “não”), uma árvore de classificação escolherá a mais provável após fazer algumas perguntas sobre os dados apresentados. Geralmente são implementados como árvores binárias, o que significa que cada nó de decisão tem exatamente dois filhos.
As árvores de classificação podem tentar responder a questões de múltipla escolha, como “Este cliente está satisfeito?” ou “Qual loja física provavelmente será visitada por este cliente?” ou “Amanhã será um bom dia para ir ao campo de golfe?”
Os dois métodos mais comuns para medir a qualidade de uma árvore de classificação são baseados no ganho de informação e na entropia:
- Ganho de informação:A eficiência de uma árvore aumenta quando ela faz menos perguntas antes de chegar a uma resposta. O ganho de informação mede a rapidez com que uma árvore pode obter uma resposta, avaliando quanta informação adicional é aprendida sobre um dado em cada nó de decisão. Avalia se as perguntas mais importantes e úteis são feitas primeiro na árvore.
- Entropia:A precisão é crucial para rótulos de árvores de decisão. As métricas de entropia medem essa precisão avaliando os rótulos produzidos pela árvore. Eles avaliam a frequência com que um dado aleatório termina com o rótulo errado e a semelhança entre todos os dados de treinamento que recebem o mesmo rótulo.
Medições mais avançadas da qualidade das árvores incluem oíndice de gini,taxa de ganho,avaliações qui-quadradoe várias medidas para redução de variância.
Árvores de regressão
As árvores de regressão são normalmente usadas em análises de regressão para análises estatísticas avançadas ou para prever dados de um intervalo contínuo e potencialmente ilimitado. Dada uma gama de opções contínuas (por exemplo, de zero a infinito na escala de números reais), a árvore de regressão tenta prever a correspondência mais provável para um determinado dado após fazer uma série de perguntas. Cada pergunta restringe a gama potencial de respostas. Por exemplo, uma árvore de regressão pode ser usada para prever pontuações de crédito, receitas de uma linha de negócios ou o número de interações em um vídeo de marketing.
A precisão das árvores de regressão geralmente é avaliada usando métricas comoerro quadrático médioouerro absoluto médio, que calculam a que distância um conjunto específico de previsões está comparado aos valores reais.
Como funcionam as árvores de decisão
Como exemplo de aprendizagem supervisionada, as árvores de decisão dependem de dados bem formatados para treinamento. Os dados de origem geralmente contêm uma lista de valores que o modelo deve aprender a prever ou classificar. Cada valor deve ter um rótulo anexado e uma lista de recursos associados – propriedades que o modelo deve aprender a associar ao rótulo.

Construção ou treinamento
Durante o processo de treinamento, os nós de decisão na árvore de decisão são divididos recursivamente em nós mais específicos de acordo com um ou mais algoritmos de treinamento. Uma descrição do processo em nível humano pode ser assim:
- Comece com o nó raizconectado a todo o conjunto de treinamento.
- Dividir o nó raiz:Usando uma abordagem estatística, atribua uma decisão ao nó raiz com base em um dos recursos de dados e distribua os dados de treinamento para pelo menos dois nós folha separados, conectados como filhos à raiz.
- Aplique recursivamente a etapa doisa cada um dos filhos, transformando-os de nós folha em nós de decisão. Pare quando algum limite for atingido (por exemplo, a altura/profundidade da árvore, uma medida da qualidade dos filhos em cada folha em cada nó, etc.) ou se você ficar sem dados (ou seja, cada folha contém dados pontos relacionados a exatamente um rótulo).
A decisão sobre quais recursos considerar em cada nó difere para casos de uso de classificação, regressão e classificação combinada e regressão. Existem muitos algoritmos para escolher para cada cenário. Algoritmos típicos incluem:
- ID3 (classificação):Otimiza entropia e ganho de informação
- C4.5 (classificação):Uma versão mais complexa do ID3, adicionando normalização ao ganho de informação
- CART (classificação/regressão): “Árvore de classificação e regressão”; um algoritmo ganancioso que otimiza o mínimo de impureza em conjuntos de resultados
- CHAID (classificação/regressão): “Detecção automática de interação qui-quadrado”; usa medidas qui-quadrado em vez de entropia e ganho de informação
- MARS (classificação/regressão): usa aproximações lineares por partes para capturar não linearidades
Um regime de treinamento comum é a floresta aleatória. Uma floresta aleatória, ou floresta de decisão aleatória, é um sistema que constrói muitas árvores de decisão relacionadas. Múltiplas versões de uma árvore podem ser treinadas em paralelo usando combinações de algoritmos de treinamento. Com base em várias medições da qualidade das árvores, um subconjunto destas árvores será utilizado para produzir uma resposta. Para casos de uso de classificação, a classe selecionada pelo maior número de árvores é retornada como resposta. Para casos de uso de regressão, a resposta é agregada, geralmente como a média ou previsão média de árvores individuais.
Avaliando e usando árvores de decisão
Uma vez construída uma árvore de decisão, ela pode classificar novos dados ou prever valores para um caso de uso específico. É importante manter métricas sobre o desempenho da árvore e usá-las para avaliar a precisão e a frequência de erros. Se o modelo se desviar muito do desempenho esperado, talvez seja hora de treiná-lo novamente com novos dados ou encontrar outros sistemas de ML para aplicar a esse caso de uso.
Aplicações de árvores de decisão em ML
As árvores de decisão têm uma ampla gama de aplicações em vários campos. Aqui estão alguns exemplos para ilustrar sua versatilidade:
Tomada de decisão pessoal informada
Um indivíduo pode acompanhar dados sobre, digamos, os restaurantes que visitou. Eles podem rastrear quaisquer detalhes relevantes, como tempo de viagem, tempo de espera, cozinha oferecida, horário de funcionamento, pontuação média de avaliação, custo e visita mais recente, juntamente com uma pontuação de satisfação para a visita do indivíduo a esse restaurante. Uma árvore de decisão pode ser treinada com base nesses dados para prever o provável índice de satisfação de um novo restaurante.
Calcule as probabilidades em torno do comportamento do cliente
Os sistemas de suporte ao cliente podem usar árvores de decisão para prever ou classificar a satisfação do cliente. Uma árvore de decisão pode ser treinada para prever a satisfação do cliente com base em vários fatores, como se o cliente entrou em contato com o suporte ou fez uma compra repetida ou com base em ações realizadas em um aplicativo. Além disso, pode incorporar resultados de pesquisas de satisfação ou outros comentários de clientes.
Ajude a informar decisões de negócios
Para certas decisões de negócios com muitos dados históricos, uma árvore de decisão pode fornecer estimativas ou previsões para as próximas etapas. Por exemplo, uma empresa que recolhe informações demográficas e geográficas sobre os seus clientes pode treinar uma árvore de decisão para avaliar quais as novas localizações geográficas que provavelmente serão lucrativas ou que devem ser evitadas. As árvores de decisão também podem ajudar a determinar os melhores limites de classificação para os dados demográficos existentes, como identificar faixas etárias a serem consideradas separadamente ao agrupar clientes.
Seleção de recursos para ML avançado e outros casos de uso
As estruturas da árvore de decisão são legíveis e compreensíveis por humanos. Uma vez construída uma árvore, é possível identificar quais características são mais relevantes para o conjunto de dados e em que ordem. Essas informações podem orientar o desenvolvimento de sistemas de ML ou algoritmos de decisão mais complexos. Por exemplo, se uma empresa aprender com uma árvore de decisão que os clientes priorizam o custo de um produto acima de tudo, ela poderá concentrar sistemas de ML mais complexos nesse insight ou ignorar o custo ao explorar recursos mais diferenciados.
Vantagens das árvores de decisão em ML
As árvores de decisão oferecem várias vantagens significativas que as tornam uma escolha popular em aplicações de ML. Aqui estão alguns benefícios principais:
Rápido e fácil de construir
As árvores de decisão são um dos algoritmos de ML mais maduros e bem compreendidos. Eles não dependem de cálculos particularmente complexos e podem ser construídos de forma rápida e fácil. Contanto que as informações necessárias estejam prontamente disponíveis, uma árvore de decisão é um primeiro passo fácil ao considerar soluções de ML para um problema.
Fácil para os humanos entenderem
A saída das árvores de decisão é particularmente fácil de ler e interpretar. A representação gráfica de uma árvore de decisão não depende de um conhecimento avançado de estatística. Como tal, as árvores de decisão e as suas representações podem ser utilizadas para interpretar, explicar e apoiar os resultados de análises mais complexas. As árvores de decisão são excelentes para encontrar e destacar algumas das propriedades de alto nível de um determinado conjunto de dados.
Processamento mínimo de dados necessário
As árvores de decisão podem ser construídas com a mesma facilidade em dados incompletos ou com dados discrepantes incluídos. Dados dados decorados com recursos interessantes, os algoritmos de árvore de decisão tendem a não ser tão afetados quanto outros algoritmos de ML se forem alimentados com dados que não foram pré-processados.
Desvantagens das árvores de decisão em ML
Embora as árvores de decisão ofereçam muitos benefícios, elas também apresentam várias desvantagens:
Suscetível a overfitting
As árvores de decisão são propensas ao overfitting, que ocorre quando um modelo aprende o ruído e os detalhes dos dados de treinamento, reduzindo seu desempenho em novos dados. Por exemplo, se os dados de treinamento estiverem incompletos ou esparsos, pequenas alterações nos dados podem produzir estruturas de árvore significativamente diferentes. Técnicas avançadas como poda ou definição de profundidade máxima podem melhorar o comportamento da árvore. Na prática, as árvores de decisão muitas vezes precisam de atualização com novas informações, o que pode alterar significativamente a sua estrutura.
Má escalabilidade
Além da tendência ao ajuste excessivo, as árvores de decisão enfrentam problemas mais avançados que exigem muito mais dados. Comparado a outros algoritmos, o tempo de treinamento para árvores de decisão aumenta rapidamente à medida que o volume de dados aumenta. Para conjuntos de dados maiores que podem ter propriedades significativas de alto nível para detectar, as árvores de decisão não são uma boa opção.
Não é tão eficaz para regressão ou casos de uso contínuo
As árvores de decisão não aprendem muito bem distribuições complexas de dados. Eles dividem o espaço de recursos em linhas fáceis de entender, mas matematicamente simples. Para problemas complexos onde valores discrepantes são relevantes, regressão e casos de uso contínuo, isso geralmente se traduz em desempenho muito inferior do que outros modelos e técnicas de ML.