
O que é regressão linear em aprendizado de máquina?
Publicados: 2024-09-06A regressão linear é uma técnica fundamental em análise de dados e aprendizado de máquina (ML). Este guia o ajudará a compreender a regressão linear, como ela é construída e seus tipos, aplicações, benefícios e desvantagens.
Índice
- O que é regressão linear?
- Tipos de regressão linear
- Regressão linear vs. regressão logística
- Como funciona a regressão linear?
- Aplicações de regressão linear
- Vantagens da regressão linear em ML
- Desvantagens da regressão linear em ML
O que é regressão linear?
A regressão linear é um método estatístico usado em aprendizado de máquina para modelar a relação entre uma variável dependente e uma ou mais variáveis independentes. Ele modela relacionamentos ajustando uma equação linear aos dados observados, muitas vezes servindo como ponto de partida para algoritmos mais complexos e é amplamente utilizado em análises preditivas.
Essencialmente, a regressão linear modela a relação entre uma variável dependente (o resultado que você deseja prever) e uma ou mais variáveis independentes (os recursos de entrada que você usa para previsão) encontrando a linha reta de melhor ajuste através de um conjunto de pontos de dados. Esta linha, chamadalinha de regressão, representa a relação entre a variável dependente (o resultado que queremos prever) e a(s) variável(is) independente(s) (os recursos de entrada que usamos para previsão). A equação para uma linha de regressão linear simples é definida como:
y = mx + c
onde y é a variável dependente, x é a variável independente, m é a inclinação da reta e c é a interceptação y. Esta equação fornece um modelo matemático para mapear entradas em saídas previstas, com o objetivo de minimizar as diferenças entre valores previstos e observados, conhecidas como resíduos. Ao minimizar esses resíduos, a regressão linear produz um modelo que melhor representa os dados.
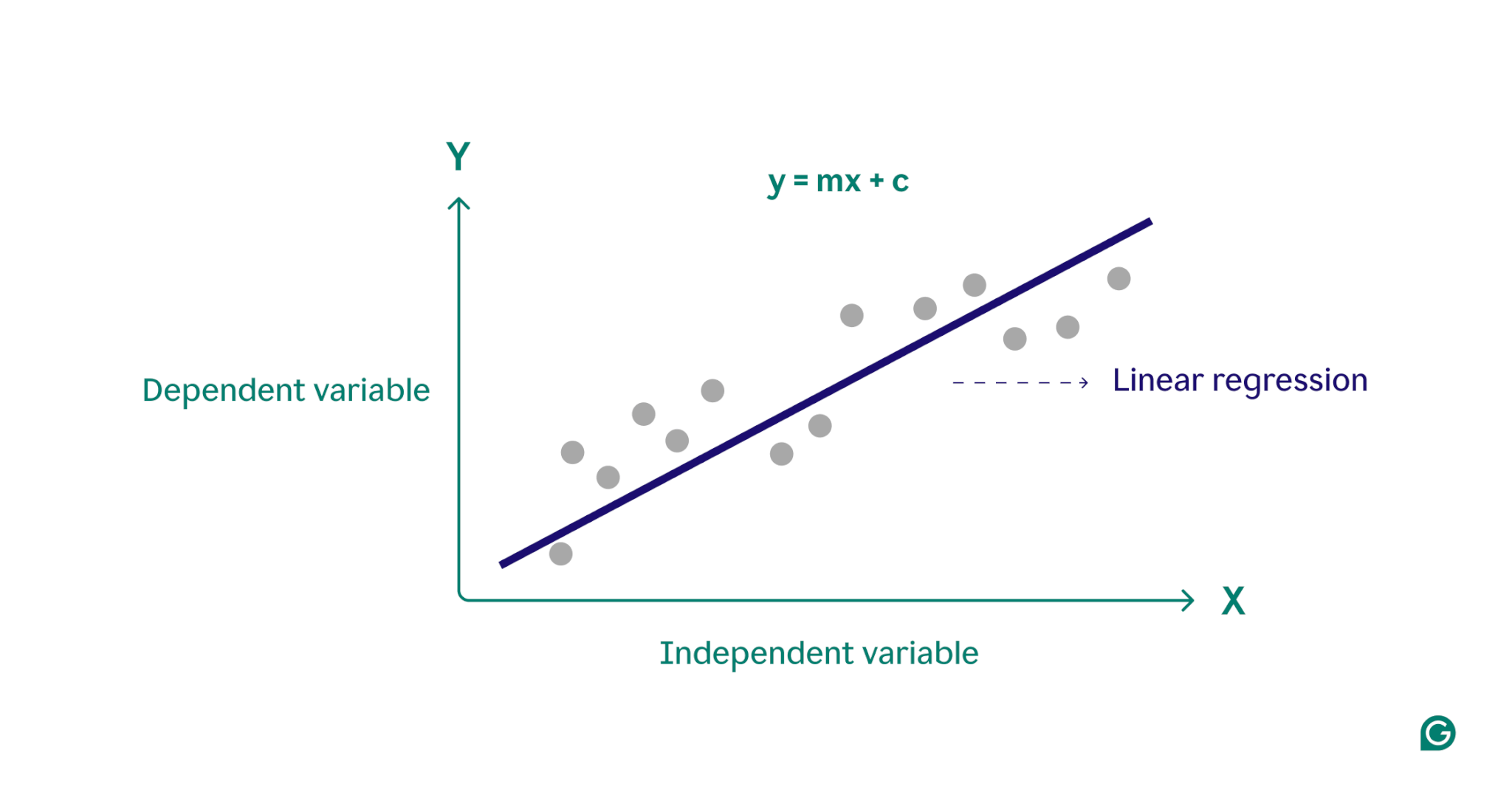
Conceitualmente, a regressão linear pode ser visualizada como o desenho de uma linha reta através de pontos em um gráfico para determinar se existe uma relação entre esses pontos de dados. O modelo de regressão linear ideal para um conjunto de pontos de dados é a linha que melhor aproxima os valores de cada ponto do conjunto de dados.
Tipos de regressão linear
Existem dois tipos principais de regressão linear:regressão linear simpleseregressão linear múltipla.
Regressão linear simples
A regressão linear simples modela a relação entre uma única variável independente e uma variável dependente usando uma linha reta. A equação para regressão linear simples é:
y = mx + c
onde y é a variável dependente, x é a variável independente, m é a inclinação da reta e c é a interceptação y.
Este método é uma maneira simples de obter insights claros ao lidar com cenários de variável única. Considere um médico tentando entender como a altura do paciente afeta o peso. Ao traçar cada variável em um gráfico e encontrar a linha mais adequada usando regressão linear simples, o médico poderia prever o peso de um paciente com base apenas na altura.
Regressão linear múltipla
A regressão linear múltipla estende o conceito de regressão linear simples para acomodar mais de uma variável, permitindo a análise de como múltiplos fatores impactam a variável dependente. A equação para regressão linear múltipla é:
y = b 0 + b 1 x 1 + b 2 x 2 +… + b n x n
onde y é a variável dependente, x 1 , x 2 , …, x n são as variáveis independentes, e b 1 , b 2 , …, b n são os coeficientes que descrevem a relação entre cada variável independente e a variável dependente.
Por exemplo, considere um corretor de imóveis que deseja estimar os preços das casas. O agente poderia utilizar uma regressão linear simples baseada numa única variável, como o tamanho da casa ou o código postal, mas este modelo seria demasiado simplista, uma vez que os preços da habitação são muitas vezes impulsionados por uma interação complexa de múltiplos fatores. Uma regressão linear múltipla, incorporando variáveis como o tamanho da casa, a vizinhança e o número de quartos, provavelmente fornecerá um modelo de previsão mais preciso.
Regressão linear vs. regressão logística
A regressão linear é frequentemente confundida com a regressão logística. Embora a regressão linear preveja resultados em variáveiscontínuas, a regressão logística é usada quando a variável dependente écategórica, muitas vezes binária (sim ou não). Variáveis categóricas definem grupos não numéricos com um número finito de categorias, como faixa etária ou forma de pagamento. As variáveis contínuas, por outro lado, podem assumir qualquer valor numérico e são mensuráveis. Exemplos de variáveis contínuas incluem peso, preço e temperatura diária.
Ao contrário da função linear usada na regressão linear, a regressão logística modela a probabilidade de um resultado categórico usando uma curva em forma de S chamada função logística. No exemplo da classificação binária, os pontos de dados que pertencem à categoria “sim” ficam em um lado do formato S, enquanto os pontos de dados na categoria “não” ficam no outro lado. Na prática, a regressão logística pode ser usada para classificar se um e-mail é spam ou não, ou prever se um cliente comprará um produto ou não. Essencialmente, a regressão linear é usada para prever valores quantitativos, enquanto a regressão logística é usada para tarefas de classificação.
Como funciona a regressão linear?
A regressão linear funciona encontrando a linha mais adequada em um conjunto de pontos de dados. Este processo envolve:
1 Seleção do modelo:Na primeira etapa, é selecionada a equação linear apropriada para descrever a relação entre as variáveis dependentes e independentes.
2 Ajuste do modelo:A seguir, uma técnica chamada Mínimos Quadrados Ordinários (MQO) é usada para minimizar a soma das diferenças quadradas entre os valores observados e os valores previstos pelo modelo. Isto é feito ajustando a inclinação e a interceptação da linha para encontrar o melhor ajuste. O objetivo deste método é minimizar o erro, ou diferença, entre os valores previstos e reais. Este processo de ajuste é uma parte essencial do aprendizado de máquina supervisionado, no qual o modelo aprende com os dados de treinamento.

3 Avaliação do modelo:Na etapa final, a qualidade do ajuste é avaliada usando métricas como R-quadrado, que mede a proporção da variância na variável dependente que é previsível a partir das variáveis independentes. Em outras palavras, o R-quadrado mede quão bem os dados realmente se ajustam ao modelo de regressão.
Este processo gera um modelo de aprendizado de máquina que pode então ser usado para fazer previsões com base em novos dados.
Aplicações de regressão linear em ML
No aprendizado de máquina, a regressão linear é uma ferramenta comumente usada para prever resultados e compreender as relações entre variáveis em vários campos. Aqui estão alguns exemplos notáveis de suas aplicações:
Previsão de gastos do consumidor
Os níveis de renda podem ser usados em um modelo de regressão linear para prever os gastos do consumidor. Especificamente, a regressão linear múltipla poderia incorporar fatores como renda histórica, idade e situação profissional para fornecer uma análise abrangente. Isto pode ajudar os economistas no desenvolvimento de políticas económicas baseadas em dados e ajudar as empresas a compreender melhor os padrões comportamentais dos consumidores.
Analisando o impacto do marketing
Os profissionais de marketing podem usar a regressão linear para entender como os gastos com publicidade afetam a receita de vendas. Ao aplicar um modelo de regressão linear a dados históricos, é possível prever receitas futuras de vendas, permitindo que os profissionais de marketing otimizem seus orçamentos e estratégias publicitárias para obter o máximo impacto.
Previsão de preços de ações
No mundo financeiro, a regressão linear é um dos muitos métodos utilizados para prever os preços das ações. Usando dados históricos de ações e vários indicadores econômicos, analistas e investidores podem construir vários modelos de regressão linear que os ajudam a tomar decisões de investimento mais inteligentes.
Previsão das condições ambientais
Na ciência ambiental, a regressão linear pode ser usada para prever as condições ambientais. Por exemplo, vários factores como o volume de tráfego, as condições meteorológicas e a densidade populacional podem ajudar a prever os níveis de poluentes. Estes modelos de aprendizagem automática podem então ser utilizados por decisores políticos, cientistas e outras partes interessadas para compreender e mitigar os impactos de diversas ações no ambiente.
Vantagens da regressão linear em ML
A regressão linear oferece diversas vantagens que a tornam uma técnica fundamental no aprendizado de máquina.
Simples de usar e implementar
Comparada com a maioria das ferramentas e modelos matemáticos, a regressão linear é fácil de compreender e aplicar. É especialmente excelente como ponto de partida para novos profissionais de aprendizado de máquina, fornecendo insights e experiência valiosos como base para algoritmos mais avançados.
Computacionalmente eficiente
Os modelos de aprendizado de máquina podem consumir muitos recursos. A regressão linear requer um poder computacional relativamente baixo em comparação com muitos algoritmos e ainda pode fornecer insights preditivos significativos.
Resultados interpretáveis
Modelos estatísticos avançados, embora poderosos, são muitas vezes difíceis de interpretar. Com um modelo simples como a regressão linear, a relação entre as variáveis é fácil de entender e o impacto de cada variável é claramente indicado pelo seu coeficiente.
Base para técnicas avançadas
Compreender e implementar a regressão linear oferece uma base sólida para explorar métodos de aprendizado de máquina mais avançados. Por exemplo, a regressão polinomial baseia-se na regressão linear para descrever relações mais complexas e não lineares entre variáveis.
Desvantagens da regressão linear em ML
Embora a regressão linear seja uma ferramenta valiosa no aprendizado de máquina, ela tem várias limitações notáveis. Compreender essas desvantagens é fundamental para selecionar a ferramenta de aprendizado de máquina apropriada.
Assumindo uma relação linear
O modelo de regressão linear assume que a relação entre variáveis dependentes e independentes é linear. Em cenários complexos do mundo real, nem sempre é esse o caso. Por exemplo, a altura de uma pessoa ao longo da vida não é linear, com o rápido crescimento que ocorre durante a infância desacelerando e parando na idade adulta. Portanto, prever a altura usando regressão linear pode levar a previsões imprecisas.
Sensibilidade a outliers
Outliers são pontos de dados que se desviam significativamente da maioria das observações em um conjunto de dados. Se não forem tratados adequadamente, esses valores extremos podem distorcer os resultados, levando a conclusões imprecisas. No aprendizado de máquina, essa sensibilidade significa que valores discrepantes podem afetar desproporcionalmente a precisão preditiva e a confiabilidade do modelo.
Multicolinearidade
Em modelos de regressão linear múltipla, variáveis independentes altamente correlacionadas podem distorcer os resultados, fenômeno conhecido comomulticolinearidade. Por exemplo, o número de quartos de uma casa e o seu tamanho podem estar altamente correlacionados, uma vez que casas maiores tendem a ter mais quartos. Isto pode dificultar a determinação do impacto individual de variáveis individuais nos preços da habitação, conduzindo a resultados pouco fiáveis.
Assumindo uma propagação de erro constante
A regressão linear assume que as diferenças entre os valores observados e previstos (a dispersão do erro) são as mesmas para todas as variáveis independentes. Se isto não for verdade, as previsões geradas pelo modelo podem não ser confiáveis. No aprendizado de máquina supervisionado, não abordar a propagação do erro pode fazer com que o modelo gere estimativas tendenciosas e ineficientes, reduzindo sua eficácia geral.