
Aprendizado de máquina 101: o que é e como funciona
Publicados: 2024-05-23O aprendizado de máquina (ML) rapidamente se tornou uma das tecnologias mais importantes do nosso tempo. Ele é a base de produtos como ChatGPT, recomendações da Netflix, carros autônomos e filtros de spam de e-mail. Para ajudá-lo a entender essa tecnologia difundida, este guia aborda o que é (e o que não é) ML, como funciona e seu impacto.
Índice
- O que é aprendizado de máquina?
- Como funciona o aprendizado de máquina
- Tipo de aprendizado de máquina
- Formulários
- Vantagens
- Desvantagens
- Futuro do ML
- Conclusão
O que é aprendizado de máquina?
Para entender o aprendizado de máquina, devemos primeiro entender a inteligência artificial (IA). Embora os dois sejam usados de forma intercambiável, eles não são a mesma coisa. A inteligência artificial é ao mesmo tempo um objetivo e um campo de estudo. O objetivo é construir sistemas computacionais capazes de pensar e raciocinar em níveis humanos (ou mesmo sobre-humanos). A IA também consiste em muitos métodos diferentes para chegar lá. O aprendizado de máquina é um desses métodos, tornando-o um subconjunto da inteligência artificial.
O aprendizado de máquina concentra-se especificamente no uso de dados e estatísticas na busca pela IA. O objetivo é criar sistemas inteligentes que possam aprender sendo alimentados com numerosos exemplos (dados) e que não precisem ser explicitamente programados. Com dados suficientes e um bom algoritmo de aprendizagem, o computador capta os padrões dos dados e melhora seu desempenho.
Em contraste, as abordagens não-ML para IA não dependem de dados e têm lógica codificada gravada. Por exemplo, você poderia criar um bot de IA do jogo da velha com desempenho sobre-humano apenas codificando todos os movimentos ideais (há 255.168 jogos de jogo da velha possíveis, então demoraria um pouco, mas ainda é possível). No entanto, seria impossível codificar um bot de IA de xadrez – há mais jogos de xadrez possíveis do que átomos no universo. O ML funcionaria melhor nesses casos.
Uma pergunta razoável neste momento é: como exatamente um computador melhora quando você lhe dá exemplos?
Como funciona o aprendizado de máquina
Em qualquer sistema de ML, você precisa de três coisas: o conjunto de dados, o modelo de ML (GPT é um exemplo) e o algoritmo de treinamento. Primeiro, você passa exemplos do conjunto de dados. O modelo então prevê o resultado correto para esse exemplo. Se o modelo estiver errado, você usa o algoritmo de treinamento para aumentar a probabilidade de o modelo estar correto para exemplos semelhantes no futuro. Você repete esse processo até ficar sem dados ou ficar satisfeito com os resultados. Depois de concluir esse processo, você poderá usar seu modelo para prever dados futuros.
Um exemplo básico desse processo é ensinar um computador a reconhecer dígitos manuscritos como os mostrados abaixo.
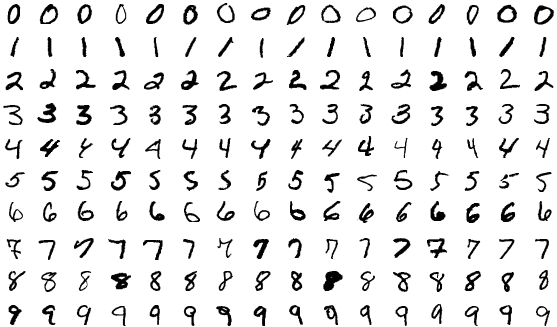
Fonte
Você coleta milhares ou centenas de milhares de imagens de dígitos. Você começa com um modelo de ML que ainda não viu nenhum exemplo. Você alimenta o modelo com as imagens e pede que ele preveja qual número ele acha que está na imagem. Ele retornará um número entre zero e nove, digamos um. Então, você basicamente diz: “Este número é na verdade cinco, não um”. O algoritmo de treinamento atualiza o modelo, portanto é mais provável que ele responda com cinco na próxima vez. Você repete esse processo para (quase) todas as imagens disponíveis e, idealmente, você tem um modelo com bom desempenho que pode reconhecer dígitos corretamente 90% das vezes. Agora você pode usar este modelo para ler milhões de dígitos em escala mais rápido do que um ser humano conseguiria. Na prática, o Serviço Postal dos Estados Unidos usa modelos de ML para ler 98% dos endereços manuscritos.
Você poderia passar meses ou anos dissecando os detalhes, mesmo que seja uma pequena parte desse processo (veja quantas versões diferentes de algoritmos de otimização existem).
Tipos comuns de aprendizado de máquina
Na verdade, existem quatro tipos diferentes de métodos de aprendizado de máquina: supervisionado, não supervisionado, semissupervisionado e reforço. A principal diferença é como seus dados são rotulados (ou seja, com ou sem a resposta correta).
Aprendizagem supervisionada
Os modelos de aprendizagem supervisionada recebem dados rotulados (com respostas corretas). O exemplo dos dígitos manuscritos se enquadra nesta categoria: podemos dizer ao modelo: “Cinco é a resposta certa”. O modelo visa aprender as conexões explícitas entre as entradas e as saídas. Esses modelos podem produzir rótulos discretos (por exemplo, prever “gato” ou “cachorro” dada a imagem de um animal de estimação) ou números (por exemplo, o preço previsto de uma casa dado o número de camas, banheiros, localização, etc.) .
Aprendizagem não supervisionada
Os modelos de aprendizagem não supervisionados recebem dados não rotulados (sem respostas corretas). Esses modelos identificam padrões nos dados de entrada para agrupar os dados de forma significativa. Por exemplo, dadas muitas imagens de cães e gatos sem uma resposta correta, o modelo de ML não supervisionado analisaria as semelhanças e diferenças nas imagens para agrupar imagens de cães e gatos. Clustering, regras de associação e redução de dimensionalidade são métodos essenciais em ML não supervisionado.
Aprendizagem semissupervisionada
A aprendizagem semissupervisionada é uma abordagem de aprendizado de máquina que fica entre a aprendizagem supervisionada e a não supervisionada. Este método fornece uma quantidade significativa de dados não rotulados e um conjunto menor de dados rotulados para treinar o modelo. Primeiro, o modelo é treinado nos dados rotulados e, em seguida, atribui rótulos aos dados não rotulados, comparando sua similaridade com os dados rotulados.
Aprendizagem por reforço
O aprendizado por reforço não possui um determinado conjunto de exemplos e rótulos. Em vez disso, é dado ao modelo um ambiente (por exemplo, jogos são comuns), uma função de recompensa e um objetivo. O modelo aprende a atingir a meta por tentativa e erro. Ele realizará uma ação, e a função de recompensa informará se a ação ajuda a atingir o objetivo geral. Então, o modelo se atualiza para realizar mais ou menos essa ação. O modelo pode aprender a atingir a meta fazendo isso muitas vezes.
Um exemplo famoso de modelo de aprendizagem por reforço é AlphaGo Zero. Este modelo foi treinado para vencer jogos de Go e recebeu apenas o estado do tabuleiro Go. Em seguida, jogou milhões de partidas contra si mesmo, aprendendo com o tempo quais movimentos lhe davam vantagens e quais não. Alcançou desempenho de nível sobre-humano em 70 horas de treinamento, acima dos campeões mundiais de Go.
Aprendizagem auto-supervisionada
Na verdade, existe um quinto tipo de aprendizado de máquina que se tornou importante recentemente: o aprendizado autossupervisionado. Os modelos de aprendizagem autossupervisionados recebem dados não rotulados, mas aprendem a criar rótulos a partir desses dados. Isso é a base dos modelos GPT por trás do ChatGPT. Durante o treinamento GPT, o modelo visa prever a próxima palavra dada uma sequência de palavras de entrada. Por exemplo, veja a frase “O gato sentou no tapete”. GPT recebe “The” e é solicitado a prever qual palavra vem a seguir. Ele faz sua previsão (digamos, “cachorro”), mas como possui a frase original, sabe qual é a resposta correta: “gato”. Em seguida, o GPT recebe “O gato” e é solicitado a prever a próxima palavra e assim por diante. Ao fazer isso, ele pode aprender padrões estatísticos entre palavras e muito mais.
Aplicações de aprendizado de máquina
Qualquer problema ou setor que tenha muitos dados pode usar ML. Muitas indústrias obtiveram resultados extraordinários ao fazer isso, e mais casos de uso estão surgindo constantemente. Aqui estão alguns casos de uso comuns de ML:
Escrita
Os modelos de ML potencializam produtos de escrita de IA generativos, como Grammarly. Por ser treinado em grandes quantidades de redação excelente, Grammarly pode criar um rascunho para você, ajudá-lo a reescrever e aperfeiçoar e debater ideias com você, tudo em seu tom e estilo preferidos.

Reconhecimento de fala
Siri, Alexa e a versão de voz do ChatGPT dependem de modelos de ML. Esses modelos são treinados em muitos exemplos de áudio, juntamente com as transcrições corretas correspondentes. Com estes exemplos, os modelos podem transformar a fala em texto. Sem ML, esse problema seria quase intratável porque cada pessoa tem maneiras diferentes de falar e pronunciar. Seria impossível enumerar todas as possibilidades.
Recomendações
Por trás de seus feeds no TikTok, Netflix, Instagram e Amazon estão modelos de recomendação de ML. Esses modelos são treinados com base em muitos exemplos de preferências (por exemplo, pessoas como você gostaram deste filme em vez daquele filme, deste produto em vez daquele produto) para mostrar itens e conteúdos que você deseja ver. Com o tempo, os modelos também podem incorporar suas preferências específicas para criar um feed que atraia especificamente você.
Detecção de fraude
Os bancos usam modelos de ML para detectar fraudes de cartão de crédito. Os provedores de e-mail usam modelos de ML para detectar e desviar e-mails de spam. Os modelos de fraude ML recebem muitos exemplos de dados fraudulentos; esses modelos aprendem padrões entre os dados para identificar fraudes no futuro.
Carros autônomos
Carros autônomos usam ML para interpretar e navegar nas estradas. O ML ajuda os carros a identificar pedestres e faixas de rodagem, prever o movimento de outros carros e decidir sua próxima ação (por exemplo, acelerar, mudar de faixa, etc.). Carros autônomos ganham proficiência treinando bilhões de exemplos usando esses métodos de ML.
Vantagens do aprendizado de máquina
Quando bem feito, o ML pode ser transformador. Os modelos de ML geralmente podem tornar os processos mais baratos, melhores ou ambos.
Eficiência de custo de mão de obra
Modelos de ML treinados podem simular o trabalho de um especialista por uma fração do custo. Por exemplo, um corretor de imóveis especialista em humanos tem grande intuição quando se trata de quanto custa uma casa, mas isso pode levar anos de treinamento. Corretores de imóveis especializados (e especialistas de qualquer tipo) também são caros para contratar. No entanto, um modelo de ML treinado em milhões de exemplos poderia aproximar-se do desempenho de um corretor de imóveis especialista. Esse modelo poderia ser treinado em questão de dias e custaria muito menos para ser usado depois de treinado. Corretores de imóveis menos experientes podem então usar esses modelos para realizar mais trabalhos em menos tempo.
Eficiência de tempo
Os modelos de ML não são limitados pelo tempo da mesma forma que os humanos. AlphaGo Zero jogou4,9 milhões de partidasde Go em três dias de treinamento . Isso levaria anos, senão décadas, para um ser humano fazer. Devido a essa escalabilidade, o modelo foi capaz de explorar uma ampla variedade de movimentos e posições do Go, levando a um desempenho sobre-humano. Os modelos de ML podem até detectar padrões que os especialistas não percebem; AlphaGo Zero até encontrou e usou movimentos que normalmente não são executados por humanos. Isso não significa que os especialistas não sejam mais valiosos; Os especialistas em Go melhoraram muito ao usar modelos como AlphaGo para testar novas estratégias.
Desvantagens do aprendizado de máquina
É claro que também há desvantagens no uso de modelos de ML. Ou seja, eles são caros para treinar e seus resultados não são facilmente explicáveis.
Treinamento caro
O treinamento de ML pode sair caro. Por exemplo, o desenvolvimento do AlphaGo Zero custou US$ 25 milhões e o desenvolvimento do GPT-4 custou mais de US$ 100 milhões. Os principais custos para o desenvolvimento de modelos de ML são rotulagem de dados, despesas de hardware e salários de funcionários.
Grandes modelos de ML supervisionados exigem milhões de exemplos rotulados, cada um dos quais deve ser rotulado por um ser humano. Depois que todos os rótulos forem coletados, é necessário hardware especializado para treinar o modelo. Unidades de processamento gráfico (GPUs) e unidades de processamento de tensor (TPUs) são o padrão para hardware de ML e podem ser caras para alugar ou comprar – as GPUs podem custar entre milhares e dezenas de milhares de dólares para comprar.
Por último, o desenvolvimento de modelos de ML excelentes requer a contratação de pesquisadores ou engenheiros de aprendizado de máquina, que podem exigir altos salários devido às suas habilidades e conhecimentos.
Clareza limitada na tomada de decisões
Para muitos modelos de ML, não está claro por que eles fornecem os resultados que fornecem. AlphaGo Zero não consegue explicar o raciocínio por trás de sua tomada de decisão; sabe que uma mudança funcionará numa situação específica, mas não sabeporquê. Isto pode ter consequências significativas quando os modelos de ML são usados em situações cotidianas. Os modelos de ML usados na área da saúde podem fornecer resultados incorretos ou tendenciosos, e podemos não saber disso porque a razão por trás de seus resultados é opaca. O preconceito, em geral, é uma grande preocupação nos modelos de ML, e a falta de explicabilidade torna o problema mais difícil de resolver. Esses problemas se aplicam especialmente a modelos de aprendizagem profunda. Modelos de aprendizagem profunda são modelos de ML que usam redes neurais de várias camadas para processar a entrada. Eles são capazes de lidar com dados e questões mais complicadas.
Por outro lado, modelos de ML mais simples e “superficiais” (como árvores de decisão e modelos de regressão) não sofrem das mesmas desvantagens. Eles ainda exigem muitos dados, mas são baratos para treinar de outra forma. Eles também são mais explicáveis. A desvantagem é que esses modelos podem ter utilidade limitada; aplicativos avançados como GPT exigem modelos mais complexos.
Futuro do aprendizado de máquina
Os modelos de ML baseados em Transformer têm estado na moda nos últimos anos. Este é o tipo de modelo de ML específico que alimenta GPT (o T em GPT), Grammarly e Claude AI. Os modelos de ML baseados em difusão, que potencializam produtos de criação de imagens como DALL-E e Midjourney, também receberam atenção.
Essa tendência não parece mudar tão cedo. As empresas de ML estão focadas em aumentar o tamanho de seus modelos – modelos maiores que têm melhores capacidades e conjuntos de dados maiores para treiná-los. O GPT-4 tinha 10 vezes mais parâmetros de modelo que o GPT-3 tinha, por exemplo. Provavelmente veremos ainda mais indústrias usando IA generativa em seus produtos para criar experiências personalizadas para os usuários.
A robótica também está esquentando. Os pesquisadores estão usando o ML para criar robôs que podem mover e usar objetos como os humanos. Esses robôs podem fazer experiências em seu ambiente e usar o aprendizado por reforço para se adaptar rapidamente e atingir seus objetivos – por exemplo, como chutar uma bola de futebol.
No entanto, à medida que os modelos de ML se tornam mais poderosos e difundidos, surgem preocupações sobre o seu potencial impacto na sociedade. Questões como o preconceito, a privacidade e a deslocação profissional estão a ser calorosamente debatidas e há um reconhecimento crescente da necessidade de orientações éticas e práticas de desenvolvimento responsável.
Conclusão
O aprendizado de máquina é um subconjunto da IA, com o objetivo explícito de criar sistemas inteligentes, permitindo-lhes aprender com os dados. Aprendizagem supervisionada, não supervisionada, semissupervisionada e por reforço são os principais tipos de ML (junto com a aprendizagem autossupervisionada). O ML está no centro de muitos novos produtos lançados hoje, como ChatGPT, carros autônomos e recomendações da Netflix. Pode ser mais barato ou melhor que o desempenho humano, mas, ao mesmo tempo, é inicialmente caro e menos explicável e orientável. O ML também deverá se tornar ainda mais popular nos próximos anos.
O ML envolve muitos meandros e a oportunidade de aprender e contribuir na área está se expandindo. Em particular, os guias do Grammarly sobre IA, aprendizado profundo e ChatGPT podem ajudá-lo a aprender mais sobre outras partes importantes deste campo. Além disso, entrar nos detalhes do ML (como a forma como os dados são coletados, a aparência real dos modelos e os algoritmos por trás do “aprendizado”) pode ajudá-lo a incorporá-lo de forma eficaz em seu trabalho.
Com o ML continuando a crescer – e com a expectativa de que afetará quase todos os setores – agora é a hora de iniciar sua jornada de ML!