
O que é overfitting no aprendizado de máquina?
Publicados: 2024-10-15Overfitting é um problema comum que surge ao treinar modelos de aprendizado de máquina (ML). Pode impactar negativamente a capacidade de generalização de um modelo além dos dados de treinamento, levando a previsões imprecisas em cenários do mundo real. Neste artigo, exploraremos o que é overfitting, como ocorre, as causas comuns por trás dele e formas eficazes de detectá-lo e preveni-lo.
Índice
- O que é sobreajuste?
- Como ocorre o overfitting
- Sobreajuste vs. subajuste
- O que causa o sobreajuste?
- Como detectar overfitting
- Como evitar o overfitting
- Exemplos de sobreajuste
O que é sobreajuste?
Overfitting ocorre quando um modelo de aprendizado de máquina aprende os padrões subjacentes e o ruído nos dados de treinamento, tornando-se excessivamente especializado naquele conjunto de dados específico. Este foco excessivo nos detalhes dos dados de treino resulta num fraco desempenho quando o modelo é aplicado a dados novos e não vistos, uma vez que não consegue generalizar para além dos dados em que foi treinado.
Como acontece o overfitting?
O overfitting ocorre quando um modelo aprende muito com detalhes específicos e ruídos nos dados de treinamento, tornando-o excessivamente sensível a padrões que não são significativos para generalização. Por exemplo, considere um modelo construído para prever o desempenho dos funcionários com base em avaliações históricas. Se o modelo se ajustar excessivamente, poderá concentrar-se demasiado em detalhes específicos e não generalizáveis, como o estilo de classificação único de um antigo gestor ou circunstâncias específicas durante um ciclo de revisão anterior. Em vez de aprender os factores mais amplos e significativos que contribuem para o desempenho – como competências, experiência ou resultados de projectos – o modelo pode ter dificuldades em aplicar o seu conhecimento a novos funcionários ou em desenvolver critérios de avaliação. Isso leva a previsões menos precisas quando o modelo é aplicado a dados diferentes do conjunto de treinamento.
Sobreajuste vs. subajuste
Em contraste com o overfitting, o underfitting ocorre quando um modelo é simples demais para capturar os padrões subjacentes nos dados. Como resultado, ele tem um desempenho ruim no treinamento e também em novos dados, não conseguindo fazer previsões precisas.
Para visualizar a diferença entre underfitting e overfitting, imagine que estamos tentando prever o desempenho atlético com base no nível de estresse de uma pessoa. Podemos representar graficamente os dados e mostrar três modelos que tentam prever esta relação:

1 Underfitting:No primeiro exemplo, o modelo utiliza uma linha reta para fazer previsões, enquanto os dados reais seguem uma curva. O modelo é demasiado simples e não consegue captar a complexidade da relação entre o nível de stress e o desempenho atlético. Como resultado, as previsões são em sua maioria imprecisas, mesmo para os dados de treinamento. Isso é inadequado.
2Ajuste ideal:O segundo exemplo mostra um modelo que atinge o equilíbrio certo. Ele captura a tendência subjacente nos dados sem complicá-la. Esse modelo generaliza bem para novos dados porque não tenta ajustar todas as pequenas variações nos dados de treinamento — apenas o padrão principal.
3Overfitting:No exemplo final, o modelo usa uma curva ondulada altamente complexa para ajustar os dados de treinamento. Embora essa curva seja muito precisa para os dados de treinamento, ela também captura ruídos aleatórios e valores discrepantes que não representam o relacionamento real. Este modelo é overfitting porque está tão ajustado aos dados de treinamento que é provável que faça previsões ruins em dados novos e não vistos.
Causas comuns de overfitting
Agora que sabemos o que é overfitting e por que isso acontece, vamos explorar algumas causas comuns com mais detalhes:
- Dados de treinamento insuficientes
- Dados imprecisos, errados ou irrelevantes
- Grandes pesos
- Excesso de treinamento
- A arquitetura do modelo é muito sofisticada
Dados de treinamento insuficientes
Se o seu conjunto de dados de treinamento for muito pequeno, ele poderá representar apenas alguns dos cenários que o modelo encontrará no mundo real. Durante o treinamento, o modelo pode ajustar-se bem aos dados. No entanto, você poderá ver imprecisões significativas ao testá-lo em outros dados. O pequeno conjunto de dados limita a capacidade do modelo de generalizar para situações invisíveis, tornando-o propenso a ajustes excessivos.
Dados imprecisos, errados ou irrelevantes
Mesmo que o seu conjunto de dados de treinamento seja grande, ele poderá conter erros. Esses erros podem surgir de diversas fontes, como participantes fornecendo informações falsas em pesquisas ou leituras incorretas de sensores. Se o modelo tentar aprender com essas imprecisões, ele se adaptará a padrões que não refletem as verdadeiras relações subjacentes, levando ao sobreajuste.
Grandes pesos
Nos modelos de aprendizado de máquina, os pesos são valores numéricos que representam a importância atribuída a recursos específicos dos dados ao fazer previsões. Quando os pesos se tornam desproporcionalmente grandes, o modelo pode se ajustar demais, tornando-se excessivamente sensível a determinados recursos, incluindo ruído nos dados. Isto acontece porque o modelo se torna demasiado dependente de características particulares, o que prejudica a sua capacidade de generalização para novos dados.
Excesso de treinamento
Durante o treinamento, o algoritmo processa os dados em lotes, calcula o erro de cada lote e ajusta os pesos do modelo para melhorar sua precisão.
É uma boa ideia continuar treinando pelo maior tempo possível? Na verdade! O treinamento prolongado nos mesmos dados pode fazer com que o modelo memorize pontos de dados específicos, limitando sua capacidade de generalizar para dados novos ou não vistos, que é a essência do overfitting. Este tipo de overfitting pode ser mitigado usando técnicas de parada antecipada ou monitorando o desempenho do modelo em um conjunto de validação durante o treinamento. Discutiremos como isso funciona posteriormente neste artigo.
A arquitetura do modelo é muito complexa
A arquitetura de um modelo de aprendizado de máquina refere-se a como suas camadas e neurônios são estruturados e como eles interagem para processar informações.

Arquiteturas mais complexas podem capturar padrões detalhados nos dados de treinamento. No entanto, esta complexidade aumenta a probabilidade de sobreajuste, uma vez que o modelo também pode aprender a capturar ruído ou detalhes irrelevantes que não contribuem para previsões precisas sobre novos dados. Simplificar a arquitetura ou usar técnicas de regularização pode ajudar a reduzir o risco de overfitting.
Como detectar overfitting
Detectar o overfitting pode ser complicado porque tudo pode parecer estar indo bem durante o treinamento, mesmo quando o overfitting está acontecendo. A taxa de perda (ou erro) — uma medida da frequência com que o modelo está errado — continuará a diminuir, mesmo num cenário de sobreajuste. Então, como podemos saber se ocorreu overfitting? Precisamos de um teste confiável.
Um método eficaz é usar uma curva de aprendizado, um gráfico que rastreia uma medida chamada perda. A perda representa a magnitude do erro que o modelo está cometendo. No entanto, não rastreamos apenas a perda dos dados de treinamento; também medimos a perda de dados não vistos, chamados de dados de validação. É por isso que a curva de aprendizado normalmente tem duas linhas: perda de treinamento e perda de validação.
Se a perda de treinamento continuar a diminuir conforme esperado, mas a perda de validação aumentar, isso sugere overfitting. Em outras palavras, o modelo está se tornando excessivamente especializado nos dados de treinamento e lutando para generalizar para dados novos e invisíveis. A curva de aprendizado pode ser mais ou menos assim:
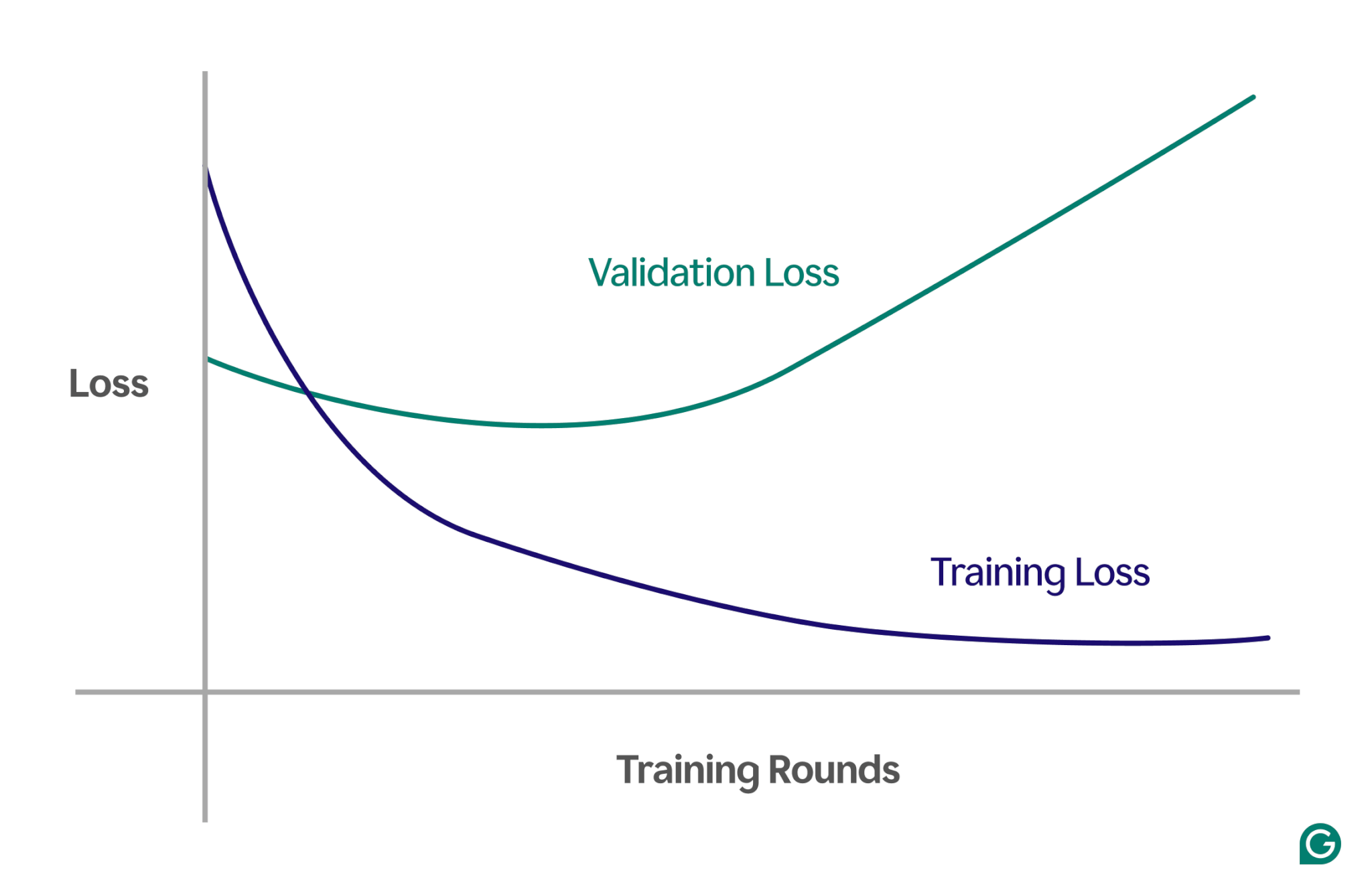
Nesse cenário, embora o modelo melhore durante o treinamento, ele apresenta desempenho insatisfatório em dados não vistos. Isso provavelmente significa que ocorreu overfitting.
Como evitar o overfitting
O overfitting pode ser resolvido usando diversas técnicas. Aqui estão alguns dos métodos mais comuns:
Reduza o tamanho do modelo
A maioria das arquiteturas de modelo permite ajustar o número de pesos alterando o número de camadas, tamanhos de camadas e outros parâmetros conhecidos como hiperparâmetros. Se a complexidade do modelo estiver causando overfitting, reduzir seu tamanho pode ajudar. Simplificar o modelo reduzindo o número de camadas ou neurônios pode diminuir o risco de overfitting, pois o modelo terá menos oportunidades de memorizar os dados de treinamento.
Regularize o modelo
A regularização envolve a modificação do modelo para desencorajar grandes pesos. Uma abordagem é ajustar a função de perda para que ela meça o erro e inclua o tamanho dos pesos.
Com a regularização, o algoritmo de treinamento minimiza tanto o erro quanto o tamanho dos pesos, reduzindo a probabilidade de pesos grandes, a menos que proporcionem uma vantagem clara ao modelo. Isso ajuda a evitar overfitting, mantendo o modelo mais generalizado.
Adicione mais dados de treinamento
Aumentar o tamanho do conjunto de dados de treinamento também pode ajudar a prevenir o overfitting. Com mais dados, é menos provável que o modelo seja influenciado por ruídos ou imprecisões no conjunto de dados. Expor o modelo a exemplos mais variados irá torná-lo menos inclinado a memorizar pontos de dados individuais e, em vez disso, aprender padrões mais amplos.
Aplicar redução de dimensionalidade
Às vezes, os dados podem conter recursos (ou dimensões) correlacionados, o que significa que vários recursos estão relacionados de alguma forma. Os modelos de aprendizado de máquina tratam as dimensões como independentes; portanto, se os recursos estiverem correlacionados, o modelo poderá se concentrar demais neles, levando a um ajuste excessivo.
Técnicas estatísticas, como a análise de componentes principais (PCA), podem reduzir essas correlações. O PCA simplifica os dados reduzindo o número de dimensões e removendo correlações, tornando menos provável o sobreajuste. Ao focar nos recursos mais relevantes, o modelo torna-se melhor na generalização para novos dados.
Exemplos práticos de overfitting
Para entender melhor o overfitting, vamos explorar alguns exemplos práticos em diferentes campos onde o overfitting pode levar a resultados enganosos.
Classificação de imagens
Os classificadores de imagens são projetados para reconhecer objetos em imagens – por exemplo, se uma imagem contém um pássaro ou um cachorro.
Outros detalhes podem estar relacionados com o que você está tentando detectar nessas imagens. Por exemplo, fotos de cães podem frequentemente ter grama ao fundo, enquanto fotos de pássaros podem frequentemente ter o céu ou as copas das árvores ao fundo.
Se todas as imagens de treinamento tiverem esses detalhes de fundo consistentes, o modelo de aprendizado de máquina poderá começar a confiar no fundo para reconhecer o animal, em vez de focar nas características reais do próprio animal. Como resultado, quando o modelo é solicitado a classificar a imagem de um pássaro pousado em um gramado, ele pode classificá-lo incorretamente como um cachorro porque está se ajustando demais às informações de fundo. Este é um caso de overfitting aos dados de treinamento.
Modelagem financeira
Digamos que você esteja negociando ações em seu tempo livre e acredite que é possível prever movimentos de preços com base nas tendências de pesquisas do Google para determinadas palavras-chave. Você configura um modelo de aprendizado de máquina usando dados do Google Trends para milhares de palavras.
Como existem tantas palavras, algumas provavelmente mostrarão uma correlação com os preços de suas ações por puro acaso. O modelo pode superajustar essas correlações coincidentes, fazendo previsões ruins sobre dados futuros porque as palavras não são preditores relevantes dos preços das ações.
Ao construir modelos para aplicações financeiras, é importante compreender a base teórica para as relações nos dados. Alimentar grandes conjuntos de dados em um modelo sem uma seleção cuidadosa de recursos pode aumentar o risco de overfitting, especialmente quando o modelo identifica correlações espúrias que existem puramente por acaso nos dados de treinamento.
Superstição esportiva
Embora não estejam estritamente relacionadas com a aprendizagem automática, as superstições desportivas podem ilustrar o conceito de overfitting – especialmente quando os resultados estão ligados a dados que logicamente não têm qualquer ligação com o resultado.
Durante o campeonato de futebol UEFA Euro 2008 e a Copa do Mundo FIFA de 2010, um polvo chamado Paul foi famoso por ser usado para prever resultados de jogos envolvendo a Alemanha. Paulo acertou quatro das seis previsões em 2008 e todas as sete em 2010.
Se considerarmos apenas os “dados de treinamento” das previsões anteriores de Paul, um modelo que concorda com as escolhas de Paul pareceria prever muito bem os resultados. No entanto, este modelo não seria bem generalizado para jogos futuros, uma vez que as escolhas do polvo não são preditores confiáveis dos resultados dos jogos.