
Florestas aleatórias no aprendizado de máquina: o que são e como eles funcionam
Publicados: 2025-02-03As florestas aleatórias são uma técnica poderosa e versátil no aprendizado de máquina (ML). Este guia ajudará você a entender as florestas aleatórias, como elas funcionam e suas aplicações, benefícios e desafios.
Índice
- O que é uma floresta aleatória?
- Árvores de decisão vs. floresta aleatória: qual é a diferença?
- Como as florestas aleatórias funcionam
- Aplicações práticas de florestas aleatórias
- Vantagens de florestas aleatórias
- Desvantagens de florestas aleatórias
O que é uma floresta aleatória?
Uma floresta aleatória é um algoritmo de aprendizado de máquina que usa várias árvores de decisão para fazer previsões. É um método de aprendizado supervisionado projetado para tarefas de classificação e regressão. Ao combinar as saídas de muitas árvores, uma floresta aleatória melhora a precisão, reduz o excesso de ajuste e fornece previsões mais estáveis em comparação com uma única árvore de decisão.
Árvores de decisão vs. floresta aleatória: qual é a diferença?
Embora as florestas aleatórias sejam construídas em árvores de decisão, os dois algoritmos diferem significativamente na estrutura e aplicação:
Árvores de decisão
Uma árvore de decisão consiste em três componentes principais: um nó raiz, nós de decisão (nós internos) e nós foliares. Como um fluxograma, o processo de decisão começa no nó raiz, flui através dos nós de decisão com base nas condições e termina em um nó foliar representando o resultado. Embora as árvores de decisão sejam fáceis de interpretar e conceituar, elas também são propensas a ajustar demais, especialmente com conjuntos de dados complexos ou barulhentos.
Florestas aleatórias
Uma floresta aleatória é um conjunto de árvores de decisão que combina seus resultados para melhorar previsões. Cada árvore é treinada em uma amostra exclusiva de bootstrap (um subconjunto amostrado aleatoriamente do conjunto de dados original com substituição) e avalia divisões de decisão usando um subconjunto de recursos selecionados aleatoriamente em cada nó. Essa abordagem, conhecida como ensacamento de recursos, introduz a diversidade entre as árvores. Ao agregar as previsões - usando a votação majoritária para classificação ou médias para a regressão - as florestas aleatórias produzem resultados mais precisos e estáveis do que qualquer árvore de decisão única no conjunto.
Como as florestas aleatórias funcionam
As florestas aleatórias operam combinando várias árvores de decisão para criar um modelo de previsão robusto e preciso.
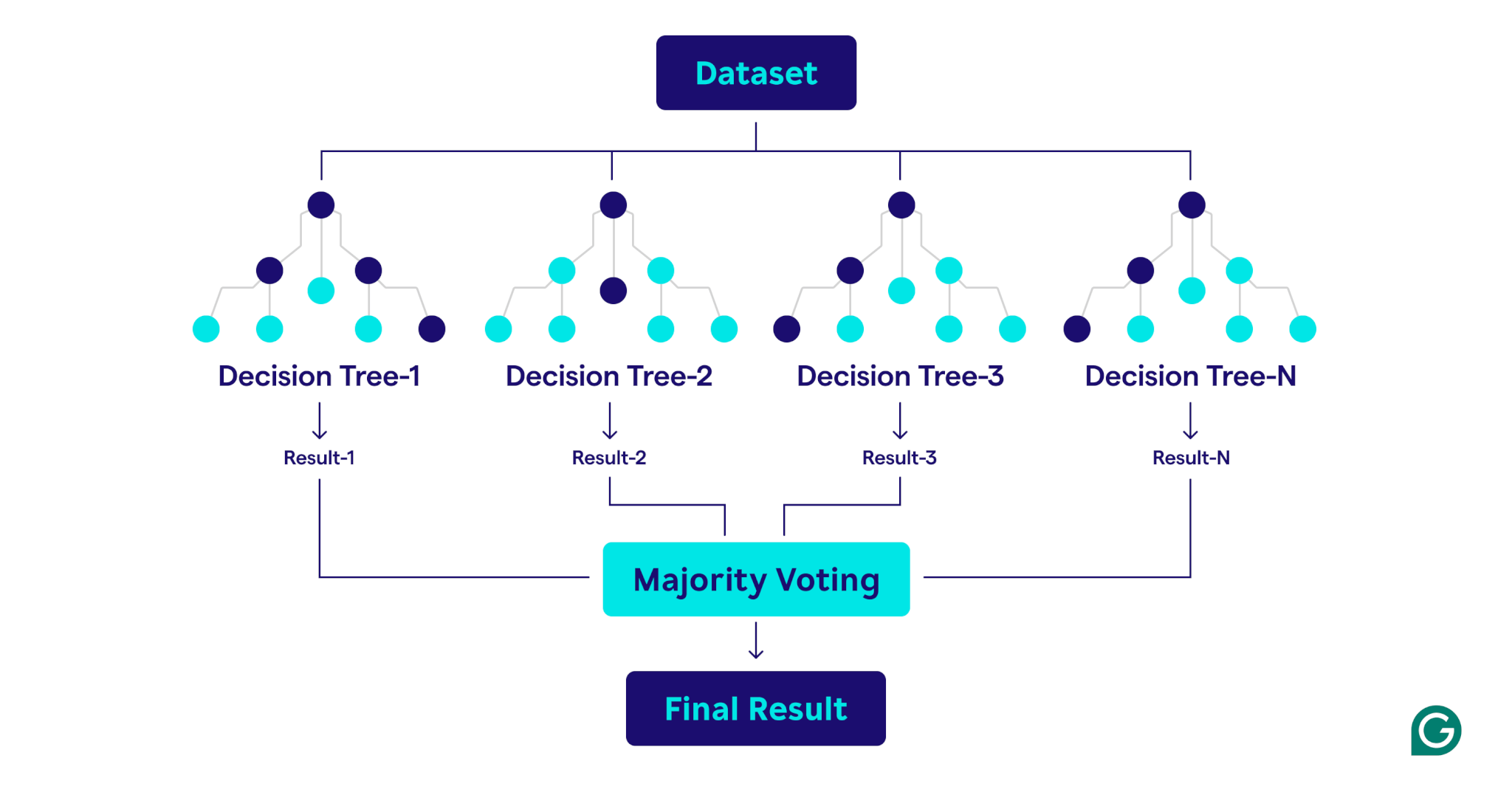
Aqui está uma explicação passo a passo do processo:
1. Definindo hiperparâmetros
O primeiro passo é definir os hiperparâmetros do modelo. Estes incluem:
- Número de árvores:determina o tamanho da floresta
- Profundidade máxima para cada árvore:controla a profundidade de cada árvore de decisão
- Número de recursos considerados em cada divisão:limita o número de recursos avaliados ao criar divisões
Esses hiperparâmetros permitem ajustar a complexidade do modelo e otimizar o desempenho para conjuntos de dados específicos.
2. Amostragem de bootstrap
Uma vez definido os hiperparâmetros, o processo de treinamento começa com a amostragem de bootstrap. Isso envolve:
- Os pontos de dados do conjunto de dados originais são selecionados aleatoriamente para criar conjuntos de dados de treinamento (amostras de bootstrap) para cada árvore de decisão.
- Cada amostra de bootstrap é tipicamente cerca de dois terços do tamanho do conjunto de dados original, com alguns pontos de dados repetidos e outros excluídos.
- O terço restante dos pontos de dados, não incluído na amostra de bootstrap, é chamado de dados fora de saco (OOB).
3. Construindo árvores de decisão
Cada árvore de decisão na floresta aleatória é treinada em sua amostra de bootstrap correspondente usando um processo exclusivo:
- Bagagem de recursos:Em cada divisão, é selecionado um subconjunto aleatório de recursos, garantindo a diversidade entre as árvores.
- Divisão de nós:o melhor recurso do subconjunto é usado para dividir o nó:
- Para tarefas de classificação, critérios como a impureza de Gini (uma medida de com que frequência um elemento escolhido aleatoriamente seria classificado incorretamente se fosse rotulado aleatoriamente de acordo com a distribuição de etiquetas de classe no nó) medir a queda da divisão das classes.
- Para tarefas de regressão, técnicas como redução de variação (um método que mede quanta divisão de um nó diminui a variação dos valores alvo, levando a previsões mais precisas) avaliar quanto a divisão reduz o erro de previsão.
- A árvore cresce recursivamente até que atenda às condições de parada, como uma profundidade máxima ou um número mínimo de pontos de dados por nó.
4. Avaliando o desempenho
À medida que cada árvore é construída, o desempenho do modelo é estimado usando os dados do OOB:
- A estimativa de erro OOB fornece uma medida imparcial do desempenho do modelo, eliminando a necessidade de um conjunto de dados de validação separado.
- Ao agregar previsões de todas as árvores, a floresta aleatória atinge a precisão aprimorada e reduz o ajuste excessivo em comparação com as árvores de decisão individuais.

Aplicações práticas de florestas aleatórias
Como as árvores de decisão nas quais são construídas, as florestas aleatórias podem ser aplicadas a problemas de classificação e regressão em uma ampla variedade de setores, como assistência médica e finanças.
Classificando as condições do paciente
Na área da saúde, as florestas aleatórias são usadas para classificar as condições do paciente com base em informações como histórico médico, dados demográficos e resultados dos testes. Por exemplo, para prever se é provável que um paciente desenvolva uma condição específica como o diabetes, cada árvore de decisão classifica o paciente como em risco ou não com base em dados relevantes, e a floresta aleatória faz a determinação final com base na maioria dos votos. Essa abordagem significa que as florestas aleatórias são particularmente adequadas para os conjuntos de dados complexos e ricos em recursos encontrados nos cuidados de saúde.
Previsão de inadimplência de empréstimos
Os bancos e as principais instituições financeiras usam amplamente as florestas aleatórias para determinar a elegibilidade do empréstimo e entender melhor o risco. O modelo usa fatores como renda e pontuação de crédito para determinar o risco. Como o risco é medido como um valor numérico contínuo, a floresta aleatória realiza regressão em vez de classificação. Cada árvore de decisão, treinada em amostras de bootstrap ligeiramente diferentes, produz uma pontuação de risco prevista. Em seguida, a floresta aleatória calcula todas as previsões individuais, resultando em uma estimativa robusta de risco holística.
Prevendo a perda do cliente
No marketing, as florestas aleatórias são frequentemente usadas para prever a probabilidade de um cliente interromper o uso de um produto ou serviço. Isso envolve a análise dos padrões de comportamento do cliente, como frequência de compra e interações com o atendimento ao cliente. Ao identificar esses padrões, as florestas aleatórias podem classificar os clientes em risco de sair. Com essas idéias, as empresas podem tomar etapas proativas e orientadas a dados para reter clientes, como oferecer programas de fidelidade ou promoções direcionadas.
Prevendo preços imobiliários
As florestas aleatórias podem ser usadas para prever os preços dos imóveis, o que é uma tarefa de regressão. Para fazer a previsão, a floresta aleatória usa dados históricos que incluem fatores como localização geográfica, metragem quadrada e vendas recentes na área. O processo médio da Forest Random resulta em uma previsão de preços mais confiável e estável do que a de uma árvore de decisão individual, que é útil nos mercados imobiliários altamente voláteis.
Vantagens de florestas aleatórias
As florestas aleatórias oferecem inúmeras vantagens, incluindo precisão, robustez, versatilidade e a capacidade de estimar a importância dos recursos.
Precisão e robustez
As florestas aleatórias são mais precisas e robustas que as árvores de decisão individuais. Isso é conseguido combinando as saídas de várias árvores de decisão treinadas em diferentes amostras de bootstrap do conjunto de dados original. A diversidade resultante significa que as florestas aleatórias são menos propensas a ajustes excessivos do que as árvores de decisão individuais. Essa abordagem do conjunto significa que as florestas aleatórias são boas para lidar com dados barulhentos, mesmo em conjuntos de dados complexos.
Versatilidade
Como as árvores de decisão nas quais são construídas, as florestas aleatórias são altamente versáteis. Eles podem lidar com tarefas de regressão e classificação, tornando -as aplicáveis a uma ampla gama de problemas. As florestas aleatórias também funcionam bem com conjuntos de dados grandes e ricos em recursos e podem lidar com dados numéricos e categóricos.
Destaque
As florestas aleatórias têm uma capacidade interna de estimar a importância de características específicas. Como parte do processo de treinamento, as florestas aleatórias produzem uma pontuação que mede quanto a precisão do modelo muda se um recurso específico for removido. Ao calcular a média das pontuações para cada recurso, as florestas aleatórias podem fornecer uma medida quantificável de importância do recurso. Características menos importantes podem ser removidas para criar árvores e florestas mais eficientes.
Desvantagens de florestas aleatórias
Embora as florestas aleatórias ofereçam muitos benefícios, elas são mais difíceis de interpretar e mais caras de treinar do que uma única árvore de decisão, e podem gerar previsões mais lentamente do que outros modelos.
Complexidade
Enquanto florestas aleatórias e árvores de decisão têm muito em comum, as florestas aleatórias são mais difíceis de interpretar e visualizar. Essa complexidade surge porque as florestas aleatórias usam centenas ou milhares de árvores de decisão. A natureza da “caixa preta” das florestas aleatórias é uma séria desvantagem quando a explicação do modelo é um requisito.
Custo computacional
Treinar centenas ou milhares de árvores de decisão requer muito mais poder e memória de processamento do que treinar uma única árvore de decisão. Quando grandes conjuntos de dados estão envolvidos, o custo computacional pode ser ainda maior. Esse grande requisito de recursos pode resultar em um custo monetário mais alto e nos tempos de treinamento mais longos. Como resultado, as florestas aleatórias podem não ser práticas em cenários como a computação de borda, onde o poder da computação e a memória são escassos. No entanto, florestas aleatórias podem ser paralelas, o que pode ajudar a reduzir o custo de computação.
Tempo de previsão mais lento
O processo de previsão de uma floresta aleatória envolve atravessar todas as árvores da floresta e agregar suas saídas, o que é inerentemente mais lento do que usar um único modelo. Esse processo pode resultar em tempos de previsão mais lentos do que modelos mais simples, como regressão logística ou redes neurais, especialmente para grandes florestas contendo árvores profundas. Para casos de uso em que o tempo é essencial, como negociação de alta frequência ou veículos autônomos, esse atraso pode ser proibitivo.