
O que é underfitting no aprendizado de máquina?
Publicados: 2024-10-16O underfitting é um problema comum encontrado durante o desenvolvimento de modelos de aprendizado de máquina (ML). Ocorre quando um modelo é incapaz de aprender efetivamente com os dados de treinamento, resultando em um desempenho abaixo da média. Neste artigo, exploraremos o que é o underfitting, como ele acontece e as estratégias para evitá-lo.
Índice
- O que é subajuste?
- Como ocorre o underfitting
- Underfitting vs. Overfitting
- Causas comuns de subajuste
- Como detectar subajuste
- Técnicas para prevenir o underfitting
- Exemplos práticos de underfitting
O que é subajuste?
Underfitting ocorre quando um modelo de aprendizado de máquina não consegue capturar os padrões subjacentes nos dados de treinamento, levando a um desempenho insatisfatório tanto nos dados de treinamento quanto nos dados de teste. Quando isso ocorre, significa que o modelo é muito simples e não representa bem os relacionamentos mais importantes dos dados. Como resultado, o modelo se esforça para fazer previsões precisas sobre todos os dados, tanto os dados vistos durante o treinamento quanto quaisquer dados novos e não vistos.
Como acontece o underfitting?
O underfitting ocorre quando um algoritmo de aprendizado de máquina produz um modelo que não consegue capturar as propriedades mais importantes dos dados de treinamento; modelos que falham desta forma são considerados muito simples. Por exemplo, imagine que você esteja usando regressão linear para prever vendas com base em gastos com marketing, dados demográficos do cliente e sazonalidade. A regressão linear pressupõe que a relação entre esses fatores e as vendas pode ser representada como uma combinação de linhas retas.
Embora a relação real entre os gastos com marketing e as vendas possa ser curva ou incluir múltiplas interações (por exemplo, as vendas aumentam rapidamente no início e depois estagnam), o modelo linear simplificará demais ao traçar uma linha reta. Esta simplificação ignora nuances importantes, levando a previsões e desempenho geral insatisfatórios.
Esse problema é comum em muitos modelos de ML em que o alto viés (suposições rígidas) impede o modelo de aprender padrões essenciais, fazendo com que ele tenha um desempenho insatisfatório tanto nos dados de treinamento quanto nos de teste. O underfitting normalmente é observado quando o modelo é simples demais para representar a verdadeira complexidade dos dados.
Underfitting vs. Overfitting
No ML, o underfitting e o overfitting são problemas comuns que podem afetar negativamente a capacidade de um modelo de fazer previsões precisas. Compreender a diferença entre os dois é crucial para construir modelos que generalizem bem para novos dados.
- O underfittingocorre quando um modelo é muito simples e não consegue capturar os principais padrões nos dados. Isso leva a previsões imprecisas tanto para os dados de treinamento quanto para os novos dados.
- O overfittingacontece quando um modelo se torna excessivamente complexo, ajustando não apenas os padrões verdadeiros, mas também o ruído nos dados de treinamento. Isso faz com que o modelo tenha um bom desempenho no conjunto de treinamento, mas um desempenho ruim em dados novos e não vistos.
Para ilustrar melhor esses conceitos, considere um modelo que preveja o desempenho atlético com base nos níveis de estresse. Os pontos azuis no gráfico representam os pontos de dados do conjunto de treinamento, enquanto as linhas mostram as previsões do modelo após ser treinado nesses dados. 
1 Underfitting:Neste caso, o modelo utiliza uma linha reta simples para prever o desempenho, mesmo que a relação real seja curva. Como a linha não se ajusta bem aos dados, o modelo é muito simples e não consegue capturar padrões importantes, resultando em previsões ruins. Isto é inadequado, onde o modelo não consegue aprender as propriedades mais úteis dos dados.
2 Ajuste ideal:aqui, o modelo ajusta a curva dos dados de forma suficientemente adequada. Ele captura a tendência subjacente sem ser excessivamente sensível a pontos de dados ou ruídos específicos. Este é o cenário desejado, onde o modelo generaliza razoavelmente bem e pode fazer previsões precisas sobre novos dados semelhantes. No entanto, a generalização ainda pode ser um desafio quando confrontada com conjuntos de dados muito diferentes ou mais complexos.
3 Overfitting:No cenário de overfitting, o modelo segue de perto quase todos os pontos de dados, incluindo ruído e flutuações aleatórias nos dados de treinamento. Embora o modelo tenha um desempenho extremamente bom no conjunto de treinamento, ele é muito específico para os dados de treinamento e, portanto, será menos eficaz na previsão de novos dados. Tem dificuldade em generalizar e provavelmente fará previsões imprecisas quando aplicado a cenários invisíveis.
Causas comuns de subajuste
Existem muitas causas potenciais de subajuste. Os quatro mais comuns são:
- A arquitetura do modelo é muito simples.
- Má seleção de recursos
- Dados de treinamento insuficientes
- Treinamento insuficiente
Vamos nos aprofundar um pouco mais para entendê-los.
A arquitetura do modelo é muito simples
A arquitetura do modelo refere-se à combinação do algoritmo usado para treinar o modelo e a estrutura do modelo. Se a arquitetura for muito simples, poderá haver problemas para capturar as propriedades de alto nível dos dados de treinamento, levando a previsões imprecisas.
Por exemplo, se um modelo tentar usar uma única linha reta para modelar dados que seguem um padrão curvo, ele será consistentemente subajustado. Isto ocorre porque uma linha reta não pode representar com precisão o relacionamento de alto nível em dados curvos, tornando a arquitetura do modelo inadequada para a tarefa.
Má seleção de recursos
A seleção de recursos envolve a escolha das variáveis certas para o modelo de ML durante o treinamento. Por exemplo, você pode pedir a um algoritmo de ML que observe o ano de nascimento, a cor dos olhos, a idade ou todos os três de uma pessoa ao prever se uma pessoa clicará no botão de compra em um site de comércio eletrônico.
Se houver muitos recursos ou se os recursos selecionados não se correlacionarem fortemente com a variável de destino, o modelo não terá informações relevantes suficientes para fazer previsões precisas. A cor dos olhos pode ser irrelevante para a conversão, e a idade captura muitas das mesmas informações que o ano de nascimento.
Dados de treinamento insuficientes
Quando há poucos pontos de dados, o modelo pode ser insuficiente porque os dados não capturam as propriedades mais importantes do problema. Isto pode acontecer devido à falta de dados ou devido a um viés de amostragem, onde certas fontes de dados são excluídas ou sub-representadas, impedindo o modelo de aprender padrões importantes.

Treinamento insuficiente
Treinar um modelo de ML envolve ajustar seus parâmetros internos (pesos) com base na diferença entre suas previsões e os resultados reais. Quanto mais iterações de treinamento o modelo passar, melhor ele poderá se ajustar para se ajustar aos dados. Se o modelo for treinado com poucas iterações, poderá não ter oportunidades suficientes para aprender com os dados, levando ao subajuste.
Como detectar subajuste
Uma maneira de detectar o underfitting é analisando as curvas de aprendizado, que representam o desempenho do modelo (normalmente perda ou erro) em relação ao número de iterações de treinamento. Uma curva de aprendizado mostra como o modelo melhora (ou não melhora) ao longo do tempo nos conjuntos de dados de treinamento e validação.
A perda é a magnitude do erro do modelo para um determinado conjunto de dados. A perda de treinamento mede isso para os dados de treinamento e a perda de validação para os dados de validação. Os dados de validação são um conjunto de dados separado usado para testar o desempenho do modelo. Geralmente é produzido dividindo aleatoriamente um conjunto de dados maior em dados de treinamento e validação.
No caso de underfitting, você notará os seguintes padrões principais:
- Alta perda de treinamento:se a perda de treinamento do modelo permanecer alta e estagnar no início do processo, isso sugere que o modelo não está aprendendo com os dados de treinamento. Este é um sinal claro de subajuste, pois o modelo é demasiado simples para se adaptar à complexidade dos dados.
- Perda semelhante de treinamento e validação:se a perda de treinamento e validação for alta e permanecer próxima uma da outra durante todo o processo de treinamento, isso significa que o modelo está apresentando desempenho inferior em ambos os conjuntos de dados. Isto indica que o modelo não está capturando informações suficientes dos dados para fazer previsões precisas, o que aponta para subajuste.
Abaixo está um gráfico de exemplo que mostra curvas de aprendizado em um cenário de underfitting:
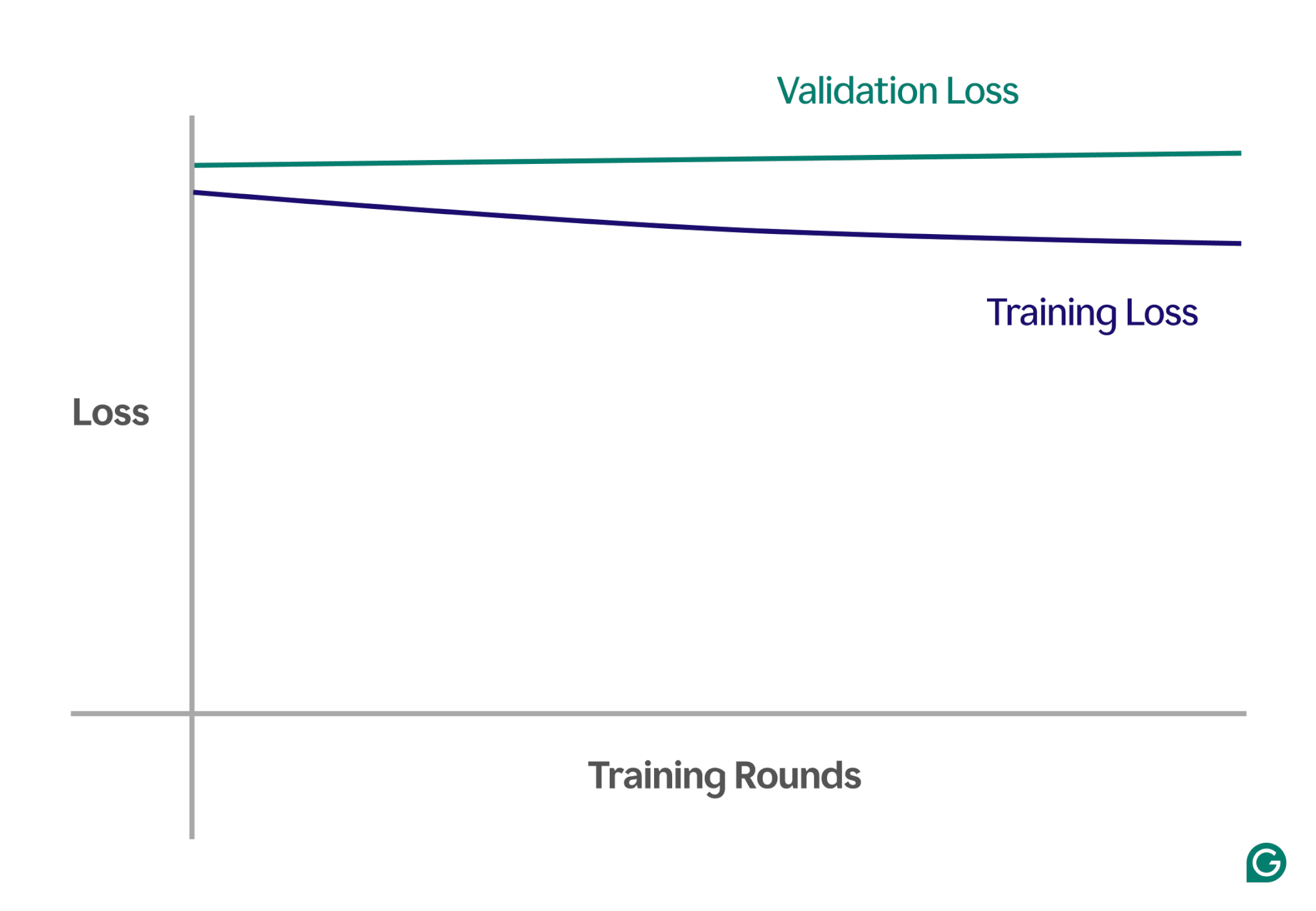
Nesta representação visual, o underfitting é fácil de detectar:
- Num modelo bem ajustado, a perda de treino diminui significativamente enquanto a perda de validação segue um padrão semelhante, eventualmente estabilizando.
- Num modelo subajustado, tanto a perda de treino como a de validação começam altas e permanecem altas, sem qualquer melhoria significativa.
Ao observar essas tendências, é possível identificar rapidamente se o modelo é muito simplista e precisa de ajustes para aumentar sua complexidade.
Técnicas para prevenir o underfitting
Se você encontrar subajuste, existem várias estratégias que você pode usar para melhorar o desempenho do modelo:
- Mais dados de treinamento:Se possível, obtenha dados de treinamento adicionais. Mais dados dão ao modelo oportunidades adicionais para aprender padrões, desde que os dados sejam de alta qualidade e relevantes para o problema em questão.
- Expandir a seleção de recursos:adicione recursos mais relevantes ao modelo. Escolha recursos que tenham um forte relacionamento com a variável de destino, dando ao modelo uma chance melhor de capturar padrões importantes que foram perdidos anteriormente.
- Aumente o poder da arquitetura:em modelos baseados em redes neurais, você pode ajustar a estrutura da arquitetura alterando o número de pesos, camadas ou outros hiperparâmetros. Isso pode permitir que o modelo seja mais flexível e encontre mais facilmente os padrões de alto nível nos dados.
- Escolha um modelo diferente:Às vezes, mesmo depois de ajustar os hiperparâmetros, um modelo específico pode não ser adequado para a tarefa. Testar vários algoritmos de modelo pode ajudar a encontrar um modelo mais apropriado e melhorar o desempenho.
Exemplos práticos de underfitting
Para ilustrar os efeitos do underfitting, vejamos exemplos do mundo real em vários domínios onde os modelos não conseguem capturar a complexidade dos dados, levando a previsões imprecisas.
Previsão de preços de casas
Para prever com precisão o preço de uma casa, é necessário considerar muitos fatores, incluindo localização, tamanho, tipo de casa, condição e número de quartos.
Se você usar poucos recursos – como apenas o tamanho e o tipo da casa – o modelo não terá acesso a informações críticas. Por exemplo, o modelo pode assumir que um pequeno estúdio é barato, sem saber que está localizado em Mayfair, Londres, uma área com preços imobiliários elevados. Isso leva a previsões ruins.
Para resolver isso, os cientistas de dados devem garantir a seleção adequada de recursos. Isso envolve a inclusão de todos os recursos relevantes, a exclusão dos irrelevantes e o uso de dados de treinamento precisos.
Reconhecimento de fala
A tecnologia de reconhecimento de voz tornou-se cada vez mais comum na vida diária. Por exemplo, assistentes de smartphones, linhas de apoio ao cliente e tecnologia assistiva para deficiências usam reconhecimento de fala. No treinamento desses modelos, são utilizados dados de amostras de fala e suas corretas interpretações.
Para reconhecer a fala, o modelo converte as ondas sonoras captadas por um microfone em dados. Se simplificarmos isso fornecendo apenas a frequência dominante e o volume da voz em intervalos específicos, reduziremos a quantidade de dados que o modelo deve processar.
No entanto, esta abordagem elimina informações essenciais necessárias para a compreensão completa do discurso. Os dados tornam-se simplistas demais para capturar a complexidade da fala humana, como variações de tom, tom e sotaque.
Como resultado, o modelo se ajustará mal, lutando para reconhecer até mesmo comandos básicos de palavras, quanto mais frases completas. Mesmo que o modelo seja suficientemente complexo, a falta de dados abrangentes leva ao subajuste.
Classificação de imagens
Um classificador de imagens é projetado para pegar uma imagem como entrada e gerar uma palavra para descrevê-la. Digamos que você esteja construindo um modelo para detectar se uma imagem contém uma bola ou não. Você treina o modelo usando imagens rotuladas de bolas e outros objetos.
Se você usar por engano uma rede neural simples de duas camadas em vez de um modelo mais adequado como uma rede neural convolucional (CNN), o modelo terá dificuldades. A rede de duas camadas nivela a imagem em uma única camada, perdendo informações espaciais importantes. Além disso, com apenas duas camadas, o modelo não tem capacidade para identificar características complexas.
Isso leva ao subajuste, pois o modelo não conseguirá fazer previsões precisas, mesmo nos dados de treinamento. As CNNs resolvem esse problema preservando a estrutura espacial das imagens e usando camadas convolucionais com filtros que aprendem automaticamente a detectar características importantes como bordas e formas nas camadas iniciais e objetos mais complexos nas camadas posteriores.