
Bazele rețelei adversare generative: Ce trebuie să știți
Publicat: 2024-10-08Rețelele generative adverse (GAN) sunt un instrument puternic de inteligență artificială (AI) cu numeroase aplicații în învățarea automată (ML). Acest ghid explorează GAN-urile, modul în care funcționează, aplicațiile și avantajele și dezavantajele lor.
Cuprins
- Ce este un GAN?
- GAN vs. CNN
- Cum funcționează GAN-urile
- Tipuri de GAN-uri
- Aplicații ale GAN-urilor
- Avantajele GAN-urilor
- Dezavantajele GAN-urilor
Ce este o rețea adversativă generativă?
O rețea generativă adversară, sau GAN, este un tip de model de învățare profundă utilizat în mod obișnuit în învățarea automată nesupravegheată, dar și adaptabil pentru învățarea semi-supravegheată și supravegheată. GAN-urile sunt folosite pentru a genera date de înaltă calitate similare cu setul de date de antrenament. Ca un subset de IA generativă, GAN-urile sunt compuse din două submodele: generatorul și discriminatorul.
1 Generator:Generatorul creează date sintetice.
2 Discriminator:Discriminatorul evaluează ieșirea generatorului, făcând distincție între datele reale din setul de antrenament și datele sintetice create de generator.
Cele două modele se angajează într-o competiție: generatorul încearcă să păcălească discriminatorul pentru a clasifica datele generate ca fiind reale, în timp ce discriminatorul își îmbunătățește continuu capacitatea de a detecta datele sintetice. Acest proces contradictoriu continuă până când discriminatorul nu mai poate face distincția între datele reale și cele generate. În acest moment, GAN este capabil să genereze imagini realiste, videoclipuri și alte tipuri de date.
GAN vs. CNN
GAN-urile și rețelele neuronale convoluționale (CNN) sunt tipuri puternice de rețele neuronale utilizate în învățarea profundă, dar diferă semnificativ în ceea ce privește cazurile de utilizare și arhitectura.
Cazuri de utilizare
- GAN:Specializați-vă în generarea de date sintetice realiste bazate pe date de antrenament. Acest lucru face ca GAN-urile să fie potrivite pentru sarcini precum generarea de imagini, transferul stilului de imagine și creșterea datelor. GAN-urile sunt nesupravegheate, ceea ce înseamnă că pot fi aplicate scenariilor în care datele etichetate sunt rare sau indisponibile.
- CNN-uri:utilizate în principal pentru sarcini de clasificare a datelor structurate, cum ar fi analiza sentimentelor, clasificarea subiectelor și traducerea limbii. Datorită abilităților lor de clasificare, CNN-urile servesc și ca buni discriminatori în GAN. Cu toate acestea, deoarece CNN-urile necesită date de antrenament structurate, adnotate de om, ele sunt limitate la scenarii de învățare supravegheată.
Arhitectură
- GAN-uri:constau din două modele – un discriminator și un generator – care se angajează într-un proces competitiv. Generatorul creează imagini, în timp ce discriminatorul le evaluează, împingând generatorul să producă imagini din ce în ce mai realiste în timp.
- CNN-uri:Utilizați straturi de operațiuni convoluționale și de grupare pentru a extrage și analiza caracteristici din imagini. Această arhitectură cu un singur model se concentrează pe recunoașterea modelelor și structurilor din date.
În general, în timp ce CNN-urile se concentrează pe analiza datelor structurate existente, GAN-urile sunt orientate spre crearea de date noi, realiste.
Cum funcționează GAN-urile
La un nivel înalt, un GAN funcționează punând două rețele neuronale - generatorul și discriminatorul - una împotriva celeilalte. GAN-urile nu necesită un anumit tip de arhitectură de rețea neuronală pentru oricare dintre cele două componente ale lor, atâta timp cât arhitecturile selectate se completează reciproc. De exemplu, dacă un CNN este folosit ca discriminator pentru generarea de imagini, atunci generatorul ar putea fi o rețea neuronală deconvoluțională (deCNN), care efectuează procesul CNN în sens invers. Fiecare componentă are un scop diferit:
- Generator:pentru a produce date de o calitate atât de înaltă încât discriminatorul să fie păcălit să le clasifice drept reale.
- Discriminator:Pentru a clasifica cu exactitate un eșantion de date dat ca fiind real (din setul de date de antrenament) sau fals (generat de generator).
Această competiție este o implementare a unui joc cu sumă zero, în care o recompensă acordată unui model este, de asemenea, o penalizare pentru celălalt model. Pentru generator, păcălirea cu succes a discriminatorului are ca rezultat o actualizare a modelului care îi îmbunătățește capacitatea de a genera date realiste. În schimb, atunci când discriminatorul identifică corect datele false, acesta primește o actualizare care își îmbunătățește capacitățile de detectare. Din punct de vedere matematic, discriminatorul urmărește să minimizeze eroarea de clasificare, în timp ce generatorul caută să o maximizeze.
Procesul de instruire GAN
Antrenarea GAN-urilor implică alternarea între generator și discriminator pe mai multe epoci. Epocile sunt curse complete de antrenament pe întregul set de date. Acest proces continuă până când generatorul produce date sintetice care înșală discriminatorul în aproximativ 50% din timp. În timp ce ambele modele folosesc algoritmi similari pentru evaluarea și îmbunătățirea performanței, actualizările lor au loc independent. Aceste actualizări sunt efectuate folosind o metodă numită backpropagation, care măsoară eroarea fiecărui model și ajustează parametrii pentru a îmbunătăți performanța. Un algoritm de optimizare ajustează apoi parametrii fiecărui model în mod independent.
Iată o reprezentare vizuală a arhitecturii GAN, ilustrând competiția dintre generator și discriminator:
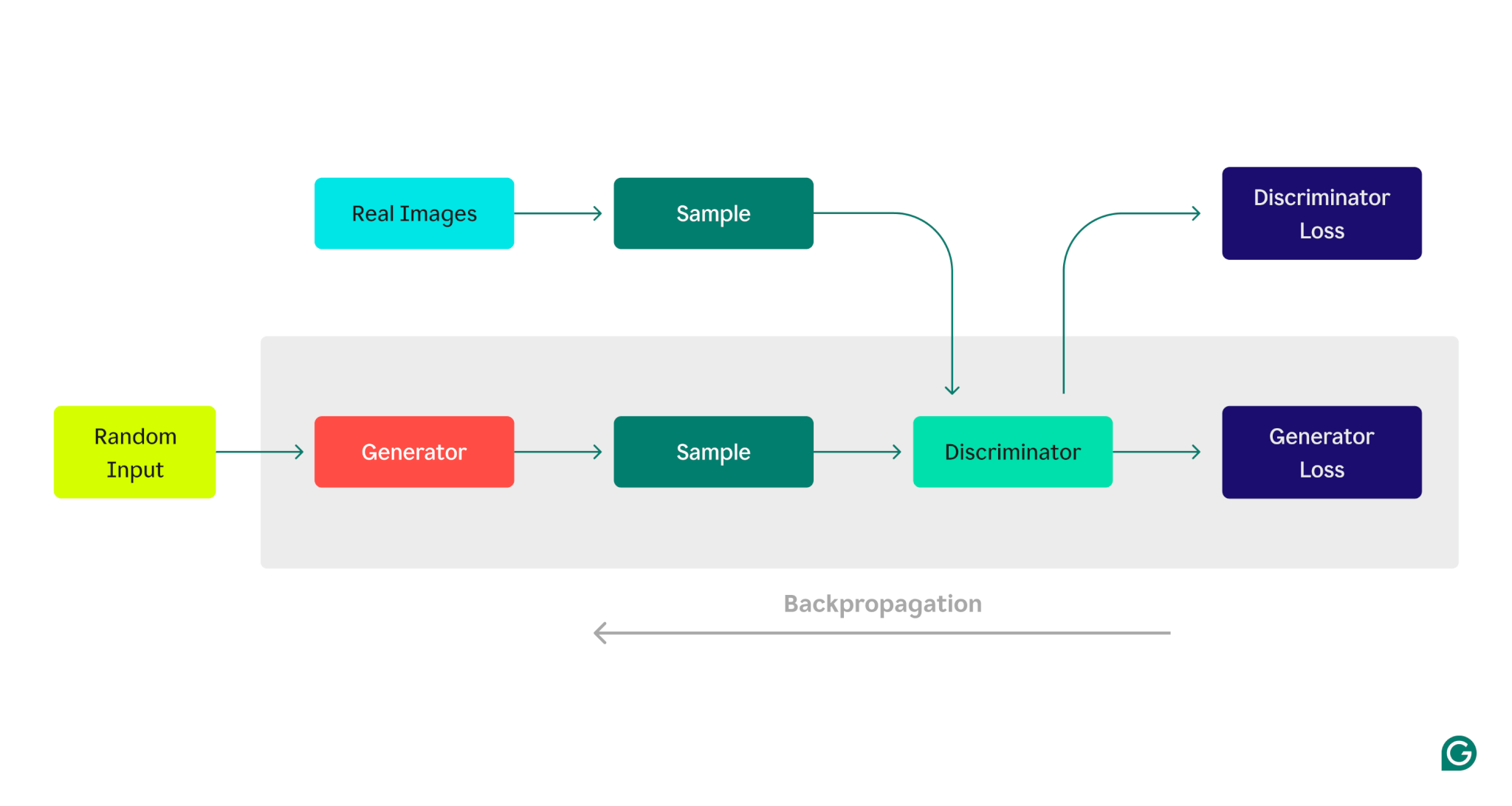
Faza de formare a generatorului:
1 Generatorul creează mostre de date, începând de obicei cu zgomot aleatoriu ca intrare.
2 Discriminatorul clasifică aceste eșantioane ca reale (din setul de date de antrenament) sau false (generate de generator).
3 Pe baza răspunsului discriminatorului, parametrii generatorului sunt actualizați utilizând backpropagation.
Faza de formare a discriminatorilor:
1 Datele false sunt generate folosind starea curentă a generatorului.
2 Eșantioanele generate sunt furnizate discriminatorului, împreună cu mostre din setul de date de antrenament.
3 Folosind backpropagation, parametrii discriminatorului sunt actualizați pe baza performanței sale de clasificare.
Acest proces de antrenament iterativ continuă, parametrii fiecărui model fiind ajustați în funcție de performanța acestuia, până când generatorul produce în mod constant date pe care discriminatorul nu le poate distinge în mod fiabil de datele reale.
Tipuri de GAN-uri
Bazându-se pe arhitectura GAN de bază, denumită adesea GAN vanilla, alte tipuri specializate de GAN au fost dezvoltate și optimizate pentru diverse sarcini. Unele dintre cele mai comune variații sunt descrise mai jos, deși aceasta nu este o listă exhaustivă:
GAN condiționat (cGAN)
GAN-urile condiționate sau cGAN-urile folosesc informații suplimentare, numite condiții, pentru a ghida modelul în generarea unor tipuri specifice de date atunci când se antrenează pe un set de date mai general. O condiție poate fi o etichetă de clasă, o descriere bazată pe text sau un alt tip de informații de clasificare pentru date. De exemplu, imaginați-vă că trebuie să generați doar imagini cu pisici siameze, dar setul de date de antrenament conține imagini cu tot felul de pisici. Într-un cGAN, puteți eticheta imaginile de antrenament cu tipul de pisică, iar modelul ar putea folosi acest lucru pentru a învăța cum să genereze doar imagini cu pisici siameze.

GAN convoluțional profund (DCGAN)
Un GAN convoluțional profund, sau DCGAN, este optimizat pentru generarea de imagini. Într-un DCGAN, generatorul este o rețea neuronală convoluțională de încorporare profundă (deCNN), iar discriminatorul este un CNN profund. CNN-urile sunt mai potrivite pentru lucrul cu și generarea de imagini datorită capacității lor de a captura ierarhii și modele spațiale. Generatorul dintr-un DCGAN utilizează supraeșantionare și straturi convoluționale transpuse pentru a crea imagini de calitate superioară decât ar putea genera un perceptron multistrat (o rețea neuronală simplă care ia decizii prin cântărirea caracteristicilor de intrare). În mod similar, discriminatorul folosește straturi convoluționale pentru a extrage caracteristici din mostrele de imagine și pentru a le clasifica cu precizie ca fiind reale sau false.
CycleGAN
CycleGAN este un tip de GAN conceput pentru a genera un tip de imagine din altul. De exemplu, un CycleGAN poate transforma o imagine a unui șoarece într-un șobolan sau a unui câine într-un coiot. CycleGAN-urile sunt capabile să efectueze această traducere imagine-la-imagine fără antrenament pe seturi de date pereche, adică seturi de date care conțin atât imaginea de bază, cât și transformarea dorită. Această capacitate este obținută prin utilizarea a două generatoare și două discriminatoare în loc de singura pereche pe care o folosește un GAN vanilie. În CycleGAN, un generator convertește imaginile din imaginea de bază în versiunea transformată, în timp ce celălalt generator efectuează o conversie în direcția opusă. De asemenea, fiecare discriminator verifică un anumit tip de imagine pentru a determina dacă este reală sau falsă. CycleGAN folosește apoi o verificare a coerenței pentru a se asigura că conversia unei imagini în celălalt stil și înapoi are ca rezultat imaginea originală.
Aplicații ale GAN-urilor
Datorită arhitecturii lor distincte, GAN-urile au fost aplicate la o serie de cazuri de utilizare inovatoare, deși performanța lor depinde în mare măsură de sarcini specifice și de calitatea datelor. Unele dintre cele mai puternice aplicații includ generarea text-to-image, mărirea datelor și generarea și manipularea video.
Generare text-to-image
GAN-urile pot genera imagini dintr-o descriere textuală. Această aplicație este valoroasă în industriile creative, permițând autorilor și designerilor să vizualizeze scenele și personajele descrise în text. În timp ce GAN-urile sunt adesea folosite pentru astfel de sarcini, alte modele AI generative, cum ar fi DALL-E de la OpenAI, folosesc arhitecturi bazate pe transformatoare pentru a obține rezultate similare.
Mărirea datelor
GAN-urile sunt utile pentru creșterea datelor, deoarece pot genera date sintetice care seamănă cu datele reale de antrenament, deși gradul de acuratețe și realism pot varia în funcție de cazul de utilizare specific și de formarea modelului. Această capacitate este deosebit de valoroasă în învățarea automată pentru extinderea seturilor limitate de date și îmbunătățirea performanței modelului. În plus, GAN-urile oferă o soluție pentru menținerea confidențialității datelor. În domenii sensibile precum sănătatea și finanțele, GAN-urile pot produce date sintetice care păstrează proprietățile statistice ale setului de date original fără a compromite informațiile sensibile.
Generare și manipulare video
GAN-urile s-au arătat promițătoare în anumite sarcini de generare și manipulare video. De exemplu, GAN-urile pot fi folosite pentru a genera cadre viitoare dintr-o secvență video inițială, ajutând în aplicații precum prezicerea mișcării pietonilor sau prognozarea pericolelor rutiere pentru vehiculele autonome. Cu toate acestea, aceste aplicații sunt încă în curs de cercetare și dezvoltare activă. GAN-urile pot fi, de asemenea, folosite pentru a genera conținut video complet sintetic și pentru a îmbunătăți videoclipurile cu efecte speciale realiste.
Avantajele GAN-urilor
GAN-urile oferă câteva avantaje distincte, inclusiv capacitatea de a genera date sintetice realiste, de a învăța din date nepereche și de a efectua antrenament nesupravegheat.
Generare de date sintetice de înaltă calitate
Arhitectura GAN-urilor le permite să producă date sintetice care pot aproxima datele din lumea reală în aplicații precum creșterea datelor și crearea video, deși calitatea și precizia acestor date pot depinde în mare măsură de condițiile de antrenament și de parametrii modelului. De exemplu, DCGAN, care utilizează CNN-uri pentru procesarea optimă a imaginii, excelează în generarea de imagini realiste.
Capabil să învețe din date nepereche
Spre deosebire de unele modele ML, GAN-urile pot învăța din seturi de date fără exemple asociate de intrări și ieșiri. Această flexibilitate permite ca GAN-urile să fie utilizate într-o gamă largă de sarcini în care datele asociate sunt rare sau indisponibile. De exemplu, în sarcinile de traducere imagine în imagine, modelele tradiționale necesită adesea un set de date de imagini și transformările acestora pentru antrenament. În schimb, GAN-urile pot folosi o varietate mai largă de seturi de date potențiale pentru instruire.
Învățare nesupravegheată
GAN-urile sunt o metodă de învățare automată nesupravegheată, ceea ce înseamnă că pot fi antrenate pe date neetichetate fără o direcție explicită. Acest lucru este deosebit de avantajos, deoarece etichetarea datelor este un proces care necesită timp și costisitor. Capacitatea GAN-urilor de a învăța din datele neetichetate le face valoroase pentru aplicațiile în care datele etichetate sunt limitate sau dificil de obținut. GAN-urile pot fi, de asemenea, adaptate pentru învățarea semi-supravegheată și supravegheată, permițându-le să utilizeze și date etichetate.
Dezavantajele GAN-urilor
În timp ce GAN-urile sunt un instrument puternic în învățarea automată, arhitectura lor creează un set unic de dezavantaje. Aceste dezavantaje includ sensibilitatea la hiperparametri, costurile de calcul ridicate, eșecul convergenței și un fenomen numit colaps de mod.
Sensibilitate hiperparametrică
GAN-urile sunt sensibile la hiperparametri, care sunt parametri stabiliți înainte de antrenament și care nu sunt învățați din date. Exemplele includ arhitecturi de rețea și numărul de exemple de instruire utilizate într-o singură iterație. Micile modificări ale acestor parametri pot afecta în mod semnificativ procesul de instruire și rezultatele modelului, necesitând o reglare fină extinsă pentru aplicații practice.
Cost de calcul ridicat
Datorită arhitecturii lor complexe, procesului de antrenament iterativ și sensibilității hiperparametrilor, GAN-urile implică adesea costuri de calcul ridicate. Formarea cu succes a unui GAN necesită hardware specializat și costisitor, precum și timp semnificativ, ceea ce poate fi o barieră pentru multe organizații care doresc să utilizeze GAN-urile.
Eșecul convergenței
Inginerii și cercetătorii pot petrece cantități semnificative de timp experimentând configurațiile de antrenament înainte de a atinge o rată acceptabilă la care rezultatul modelului devine stabil și precis, cunoscut sub numele de rata de convergență. Convergența în GAN poate fi foarte dificil de realizat și s-ar putea să nu dureze foarte mult. Eșecul de convergență este atunci când discriminatorul nu reușește să decidă suficient între datele reale și cele false, rezultând o acuratețe de aproximativ 50%, deoarece nu a câștigat capacitatea de a identifica datele reale, spre deosebire de echilibrul dorit atins în timpul antrenamentului de succes. Este posibil ca unele GAN-uri să nu ajungă niciodată la convergență și pot necesita analize specializate pentru reparare.
Colapsul modului
GAN-urile sunt predispuse la o problemă numită colapsul modului, în care generatorul creează o gamă limitată de ieșiri și nu reușește să reflecte diversitatea distribuțiilor de date din lumea reală. Această problemă apare din arhitectura GAN, deoarece generatorul devine excesiv de concentrat pe producerea de date care pot păcăli discriminatorul, determinându-l să genereze exemple similare.