
Bazele rețelei neuronale recurente: Ce trebuie să știți
Publicat: 2024-09-19Rețelele neuronale recurente (RNN) sunt metode esențiale în domeniul analizei datelor, al învățării automate (ML) și al învățării profunde. Acest articol își propune să exploreze RNN-urile și să detalieze funcționalitatea, aplicațiile și avantajele și dezavantajele acestora în contextul mai larg al învățării profunde.
Cuprins
Ce este un RNN?
Cum funcționează RNN-urile
Tipuri de RNN
RNN-uri vs. transformatoare și CNN-uri
Aplicații ale RNN-urilor
Avantaje
Dezavantaje
Ce este o rețea neuronală recurentă?
O rețea neuronală recurentă este o rețea neuronală profundă care poate procesa date secvențiale menținând o memorie internă, permițându-i să țină evidența intrărilor anterioare pentru a genera ieșiri. RNN-urile sunt o componentă fundamentală a învățării profunde și sunt potrivite în special pentru sarcini care implică date secvențiale.
„Recurenta” din „rețeaua neuronală recurentă” se referă la modul în care modelul combină informațiile din intrările anterioare cu intrările curente. Informațiile din intrările vechi sunt stocate într-un fel de memorie internă, numită „stare ascunsă”. Se repetă—alimentând calculele anterioare înapoi în sine pentru a crea un flux continuu de informații.
Să demonstrăm cu un exemplu: Să presupunem că dorim să folosim un RNN pentru a detecta sentimentul (fie pozitiv sau negativ) al propoziției „A mâncat plăcinta fericit”. RNN ar procesa cuvântulel, își actualiza starea ascunsă pentru a încorpora acel cuvânt și apoi trece laate, combina asta cu ceea ce a învățat de laelși așa mai departe cu fiecare cuvânt până când propoziția este terminată. Pentru a o pune în perspectivă, un om care citește această propoziție și-ar actualiza înțelegerea cu fiecare cuvânt. Odată ce a citit și a înțeles întreaga propoziție, omul poate spune că propoziția este pozitivă sau negativă. Acest proces uman de înțelegere este ceea ce starea ascunsă încearcă să aproximeze.
RNN-urile sunt unul dintre modelele fundamentale de învățare profundă. S-au descurcat foarte bine în sarcinile de procesare a limbajului natural (NLP), deși transformatoarele le-au înlocuit. Transformatoarele sunt arhitecturi avansate de rețea neuronală care îmbunătățesc performanța RNN, de exemplu, procesând datele în paralel și fiind capabile să descopere relații între cuvintele care sunt îndepărtate în textul sursă (folosind mecanisme de atenție). Cu toate acestea, RNN-urile sunt încă utile pentru datele din seria temporală și pentru situațiile în care modelele mai simple sunt suficiente.
Cum funcționează RNN-urile
Pentru a descrie în detaliu modul în care funcționează RNN-urile, să revenim la sarcina de exemplu anterior: Clasificați sentimentul propoziției „A mâncat plăcinta fericit”.
Începem cu un RNN antrenat care acceptă intrări de text și returnează o ieșire binară (1 reprezentând pozitiv și 0 reprezentând negativ). Înainte ca intrarea să fie dată modelului, starea ascunsă este generică - a fost învățată din procesul de instruire, dar nu este încă specifică intrării.
Primul cuvânt,El, este trecut în model. În interiorul RNN, starea sa ascunsă este apoi actualizată (la starea ascunsă h1) pentru a încorpora cuvântulEl. Apoi, cuvântulateeste trecut în RNN și h1 este actualizat (la h2) pentru a include acest cuvânt nou. Acest proces se repetă până când ultimul cuvânt este transmis. Starea ascunsă (h4) este actualizată pentru a include ultimul cuvânt. Apoi, starea ascunsă actualizată este folosită pentru a genera fie 0, fie 1.
Iată o reprezentare vizuală a modului în care funcționează procesul RNN:
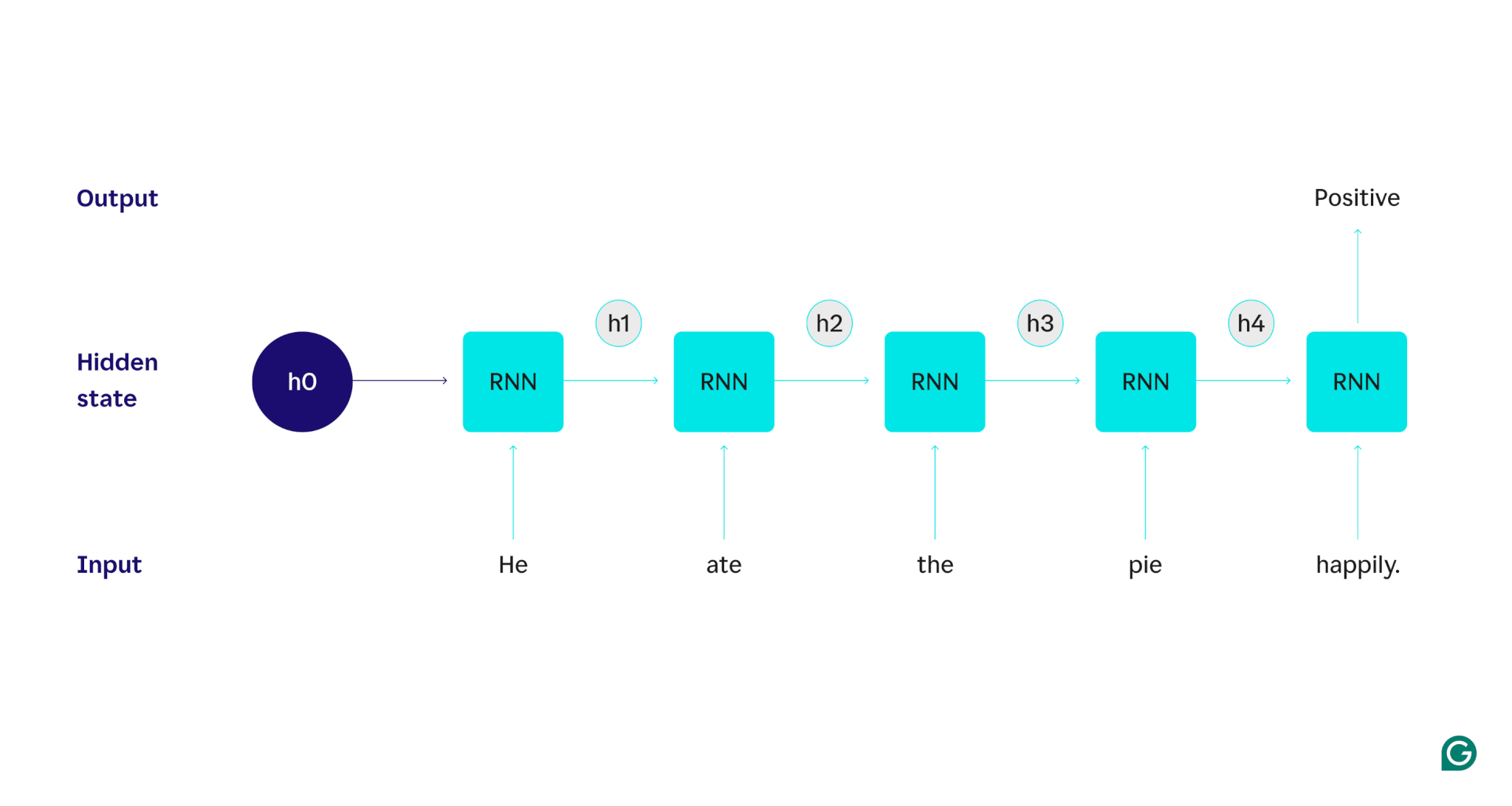
Această recurență este nucleul RNN, dar există câteva alte considerații:
- Încorporarea textului:RNN nu poate procesa text direct, deoarece funcționează numai pe reprezentări numerice. Textul trebuie convertit în înglobări înainte de a putea fi procesat de un RNN.
- Generare de ieșire:O ieșire va fi generată de RNN la fiecare pas. Cu toate acestea, rezultatul poate să nu fie foarte precis până când majoritatea datelor sursă nu sunt procesate. De exemplu, după procesarea doar a părții „El a mâncat” a propoziției, RNN-ul ar putea fi incert dacă reprezintă un sentiment pozitiv sau negativ – „El a mâncat” ar putea părea neutru. Numai după procesarea întregii propoziții, rezultatul RNN va fi corect.
- Antrenarea RNN:RNN-ul trebuie să fie instruit pentru a efectua analiza sentimentelor cu acuratețe. Antrenamentul implică utilizarea multor exemple etichetate (de exemplu, „A mâncat plăcinta supărat”, etichetate drept negative), trecerea lor prin RNN și ajustarea modelului în funcție de cât de departe sunt predicțiile sale. Acest proces stabilește valoarea implicită și mecanismul de modificare pentru starea ascunsă, permițând RNN-ului să învețe ce cuvinte sunt semnificative pentru urmărire pe tot parcursul intrării.
Tipuri de rețele neuronale recurente
Există mai multe tipuri diferite de RNN, fiecare variind în structura și aplicarea lor. RNN-urile de bază diferă în mare parte prin dimensiunea intrărilor și ieșirilor lor. RNN-urile avansate, cum ar fi rețelele de memorie pe termen scurt (LSTM), abordează unele dintre limitările RNN-urilor de bază.
RNN de bază
RNN unu-la-unu:Acest RNN preia o intrare cu lungimea unu și returnează o ieșire cu lungimea unu. Prin urmare, nu se întâmplă de fapt nicio recidivă, ceea ce o face mai degrabă o rețea neuronală standard decât o RNN. Un exemplu de RNN unu-la-unu ar fi un clasificator de imagine, unde intrarea este o singură imagine, iar rezultatul este o etichetă (de exemplu, „pasăre”).
RNN unu-la-mulți:acest RNN preia o intrare de lungime unu și returnează o ieșire cu mai multe părți. De exemplu, într-o sarcină de subtitrare a imaginii, intrarea este o imagine, iar rezultatul este o secvență de cuvinte care descriu imaginea (de exemplu, „O pasăre traversează un râu într-o zi însorită”).
RNN multi-la-unu:acest RNN preia o intrare cu mai multe părți (de exemplu, o propoziție, o serie de imagini sau date în serie de timp) și returnează o ieșire cu lungimea unu. De exemplu, un clasificator de sentimente de propoziție (cum ar fi cel despre care am discutat), unde intrarea este o propoziție și rezultatul este o singură etichetă de sentiment (fie pozitiv, fie negativ).
Many-to-many RNN:Acest RNN preia o intrare cu mai multe părți și returnează o ieșire cu mai multe părți. Un exemplu este un model de recunoaștere a vorbirii, în care intrarea este o serie de forme de undă audio, iar ieșirea este o secvență de cuvinte care reprezintă conținutul rostit.
RNN avansat: memorie pe termen lung (LSTM)
Rețelele de memorie pe termen lung sunt concepute pentru a rezolva o problemă semnificativă cu RNN-urile standard: uită informațiile prin intrări lungi. În RNN-urile standard, starea ascunsă este puternic ponderată față de părțile recente ale intrării. Într-o intrare care are mii de cuvinte, RNN va uita detalii importante din propozițiile de început. LSTM-urile au o arhitectură specială pentru a rezolva această problemă de uitare. Au module care aleg și aleg ce informații să-și amintească și să le uite în mod explicit. Deci informațiile recente, dar inutile, vor fi uitate, în timp ce informațiile vechi, dar relevante, vor fi păstrate. Ca rezultat, LSTM-urile sunt mult mai comune decât RNN-urile standard - pur și simplu funcționează mai bine la sarcini complexe sau lungi. Cu toate acestea, nu sunt perfecte, deoarece aleg totuși să uite articole.
RNN-uri vs. transformatoare și CNN-uri
Alte două modele comune de învățare profundă sunt rețelele neuronale convoluționale (CNN) și transformatoarele. Cum diferă ele?

RNN-uri vs. transformatoare
Atât RNN-urile, cât și transformatoarele sunt foarte utilizate în NLP. Cu toate acestea, ele diferă semnificativ în arhitecturi și abordări ale procesării intrărilor.
Arhitectură și prelucrare
- RNN-urile:RNN-urile procesează intrarea secvenţial, câte un cuvânt, menţinând o stare ascunsă care transportă informaţii din cuvintele anterioare. Această natură secvențială înseamnă că RNN-urile se pot lupta cu dependențe pe termen lung din cauza acestei uitări, în care informațiile anterioare se pot pierde pe măsură ce secvența progresează.
- Transformatoare:transformatoarele folosesc un mecanism numit „atenție” pentru a procesa intrarea. Spre deosebire de RNN, transformatoarele privesc întreaga secvență simultan, comparând fiecare cuvânt cu fiecare alt cuvânt. Această abordare elimină problema uitării, deoarece fiecare cuvânt are acces direct la întregul context de intrare. Transformers au demonstrat performanțe superioare în sarcini precum generarea de text și analiza sentimentelor datorită acestei capacități.
Paralelizarea
- RNN-uri:natura secvențială a RNN-urilor înseamnă că modelul trebuie să finalizeze procesarea unei părți a intrării înainte de a trece la următoarea. Acest lucru necesită foarte mult timp, deoarece fiecare pas depinde de cel anterior.
- Transformatoare:transformatoarele procesează toate părțile intrării simultan, deoarece arhitectura lor nu se bazează pe o stare ascunsă secvențială. Acest lucru le face mult mai paralelizabile și mai eficiente. De exemplu, dacă procesarea unei propoziții durează 5 secunde pe cuvânt, un RNN ar dura 25 de secunde pentru o propoziție de 5 cuvinte, în timp ce un transformator ar dura doar 5 secunde.
Implicații practice
Datorită acestor avantaje, transformatoarele sunt utilizate pe scară largă în industrie. Cu toate acestea, RNN-urile, în special rețelele de memorie pe termen scurt (LSTM), pot fi încă eficiente pentru sarcini mai simple sau atunci când se ocupă cu secvențe mai scurte. LSTM-urile sunt adesea folosite ca module critice de stocare a memoriei în arhitecturi mari de învățare automată.
RNN-uri vs. CNN-uri
CNN-urile sunt fundamental diferite de RNN-uri în ceea ce privește datele pe care le manipulează și mecanismele lor operaționale.
Tip de date
- RNN-urile:RNN-urile sunt concepute pentru date secvențiale, cum ar fi textul sau seriile de timp, unde ordinea punctelor de date este importantă.
- CNN-urile:CNN-urile sunt utilizate în principal pentru date spațiale, cum ar fi imaginile, unde se pune accent pe relațiile dintre punctele de date adiacente (de exemplu, culoarea, intensitatea și alte proprietăți ale unui pixel dintr-o imagine sunt strâns legate de proprietățile altora din apropiere). pixeli).
Operațiunea
- RNN:RNN-urile păstrează o memorie a întregii secvențe, făcându-le potrivite pentru sarcini în care contextul și secvența contează.
- CNN-urile:CNN-urile funcționează prin analizarea regiunilor locale ale intrării (de exemplu, pixeli vecini) prin straturi convoluționale. Acest lucru le face extrem de eficiente pentru procesarea imaginilor, dar mai puțin pentru datele secvențiale, unde dependențele pe termen lung ar putea fi mai importante.
Lungimea de intrare
- RNN-urile:RNN-urile pot gestiona secvențe de intrare cu lungime variabilă cu o structură mai puțin definită, făcându-le flexibile pentru diferite tipuri de date secvențiale.
- CNN-uri:CNN-urile necesită de obicei intrări de dimensiune fixă, ceea ce poate fi o limitare pentru manipularea secvențelor cu lungime variabilă.
Aplicații ale RNN-urilor
RNN-urile sunt utilizate pe scară largă în diverse domenii datorită capacității lor de a gestiona datele secvențiale în mod eficient.
Procesarea limbajului natural
Limba este o formă de date foarte secvențială, astfel încât RNN-urile funcționează bine la sarcinile lingvistice. RNN-urile excelează în sarcini precum generarea de text, analiza sentimentelor, traducerea și rezumarea. Cu biblioteci precum PyTorch, cineva ar putea crea un chatbot simplu folosind un RNN și câțiva gigaocteți de exemple de text.
Recunoașterea vorbirii
Recunoașterea vorbirii este limbajul în centrul său și, prin urmare, este, de asemenea, foarte secvențială. Pentru această sarcină ar putea fi folosit un RNN de la mulți la mulți. La fiecare pas, RNN preia starea ascunsă anterioară și forma de undă, scoțând cuvântul asociat cu forma de undă (pe baza contextului propoziției până la acel moment).
Generație muzicală
Muzica este, de asemenea, foarte secvențială. Beaturile anterioare dintr-o melodie influențează puternic ritmurile viitoare. Un RNN multi-la-mulți ar putea lua câteva bătăi de început ca intrare și apoi să genereze bătăi suplimentare, după cum dorește utilizatorul. Alternativ, ar putea lua o introducere de text precum „jazz melodic” și ar putea scoate cea mai bună aproximare a ritmurilor de jazz melodice.
Avantajele RNN-urilor
Deși RNN-urile nu mai sunt modelul de facto NLP, ele au încă unele utilizări din cauza câțiva factori.
Performanță secvențială bună
RNN-urile, în special LSTM-urile, se descurcă bine cu datele secvențiale. LSTM-urile, cu arhitectura lor de memorie specializată, pot gestiona intrări secvențiale lungi și complexe. De exemplu, Google Translate obișnuia să ruleze pe un model LSTM înainte de era transformatoarelor. LSTM-urile pot fi folosite pentru a adăuga module de memorie strategice atunci când rețelele bazate pe transformatoare sunt combinate pentru a forma arhitecturi mai avansate.
Modele mai mici, mai simple
RNN-urile au de obicei mai puțini parametri de model decât transformatoarele. Straturile de atenție și feedforward din transformatoare necesită mai mulți parametri pentru a funcționa eficient. RNN-urile pot fi antrenate cu mai puține rulări și exemple de date, făcându-le mai eficiente pentru cazuri de utilizare mai simple. Acest lucru are ca rezultat modele mai mici, mai puțin costisitoare și mai eficiente, care sunt încă suficient de performante.
Dezavantajele RNN-urilor
RNN-urile au căzut din favoarea unui motiv: transformatoarele, în ciuda dimensiunilor mai mari și a procesului de antrenament, nu au aceleași defecte ca și RNN-urile.
Memoria limitată
Starea ascunsă din RNN-urile standard influențează puternic intrările recente, ceea ce face dificilă păstrarea dependențelor pe distanță lungă. Sarcinile cu intrări lungi nu funcționează la fel de bine cu RNN. În timp ce LSTM-urile urmăresc să abordeze această problemă, ele doar o atenuează și nu o rezolvă pe deplin. Multe sarcini AI necesită gestionarea intrărilor lungi, ceea ce face ca memoria limitată să fie un dezavantaj semnificativ.
Nu este paralelizabil
Fiecare rulare a modelului RNN depinde de rezultatul rulării anterioare, în special de starea ascunsă actualizată. Ca rezultat, întregul model trebuie procesat secvenţial pentru fiecare parte a unei intrări. În schimb, transformatoarele și CNN-urile pot procesa întreaga intrare simultan. Acest lucru permite procesarea paralelă pe mai multe GPU-uri, accelerând semnificativ calculul. Lipsa de paralelizare a RNN-urilor duce la un antrenament mai lent, o generare mai lentă a rezultatelor și o cantitate maximă mai mică de date din care pot fi învățate.
Probleme cu gradient
Antrenarea RNN-urilor poate fi o provocare, deoarece procesul de backpropagation trebuie să treacă prin fiecare pas de intrare (backpropagation în timp). Datorită numeroșilor pași de timp, gradienții - care indică modul în care fiecare parametru de model ar trebui ajustat - se pot degrada și deveni ineficiente. Gradienții pot eșua prin dispariție, ceea ce înseamnă că devin foarte mici și modelul nu le mai poate folosi pentru a învăța, sau prin explozie, în care gradienții devin foarte mari și modelul își depășește actualizările, făcând modelul inutilizabil. Este dificil să echilibrezi aceste probleme.