
Ce este un autoencoder? Un ghid pentru începători
Publicat: 2024-10-28Codificatoarele automate sunt o componentă esențială a învățării profunde, în special în sarcinile de învățare automată nesupravegheate. În acest articol, vom explora modul în care funcționează autoencoderele, arhitectura lor și diferitele tipuri disponibile. Veți descoperi, de asemenea, aplicațiile lor din lumea reală, împreună cu avantajele și compromisurile implicate în utilizarea lor.
Cuprins
- Ce este un autoencoder?
- Arhitectura autoencoder
- Tipuri de autoencodere
- Aplicație
- Avantaje
- Dezavantaje
Ce este un autoencoder?
Autoencoderele sunt un tip de rețea neuronală utilizată în învățarea profundă pentru a învăța reprezentări eficiente, de dimensiuni inferioare ale datelor de intrare, care sunt apoi folosite pentru a reconstrui datele originale. Procedând astfel, această rețea învață cele mai esențiale caracteristici ale datelor în timpul antrenamentului, fără a necesita etichete explicite, făcând-o parte din învățarea auto-supravegheată. Autoencoderele sunt aplicate pe scară largă în sarcini precum eliminarea zgomotului, detectarea anomaliilor și compresia datelor, unde capacitatea lor de a comprima și reconstrui datele este valoroasă.
Arhitectura autoencoder
Un autoencoder este compus din trei părți: un encoder, un blocaj (cunoscut și ca spațiu latent sau cod) și un decodor. Aceste componente lucrează împreună pentru a capta caracteristicile cheie ale datelor de intrare și le folosesc pentru a genera reconstrucții precise.
Autoencoderele își optimizează ieșirea prin ajustarea greutăților atât a codificatorului, cât și a decodorului, urmărind să producă o reprezentare comprimată a intrării care păstrează caracteristicile critice. Această optimizare minimizează eroarea de reconstrucție, care reprezintă diferența dintre datele de intrare și cele de ieșire.
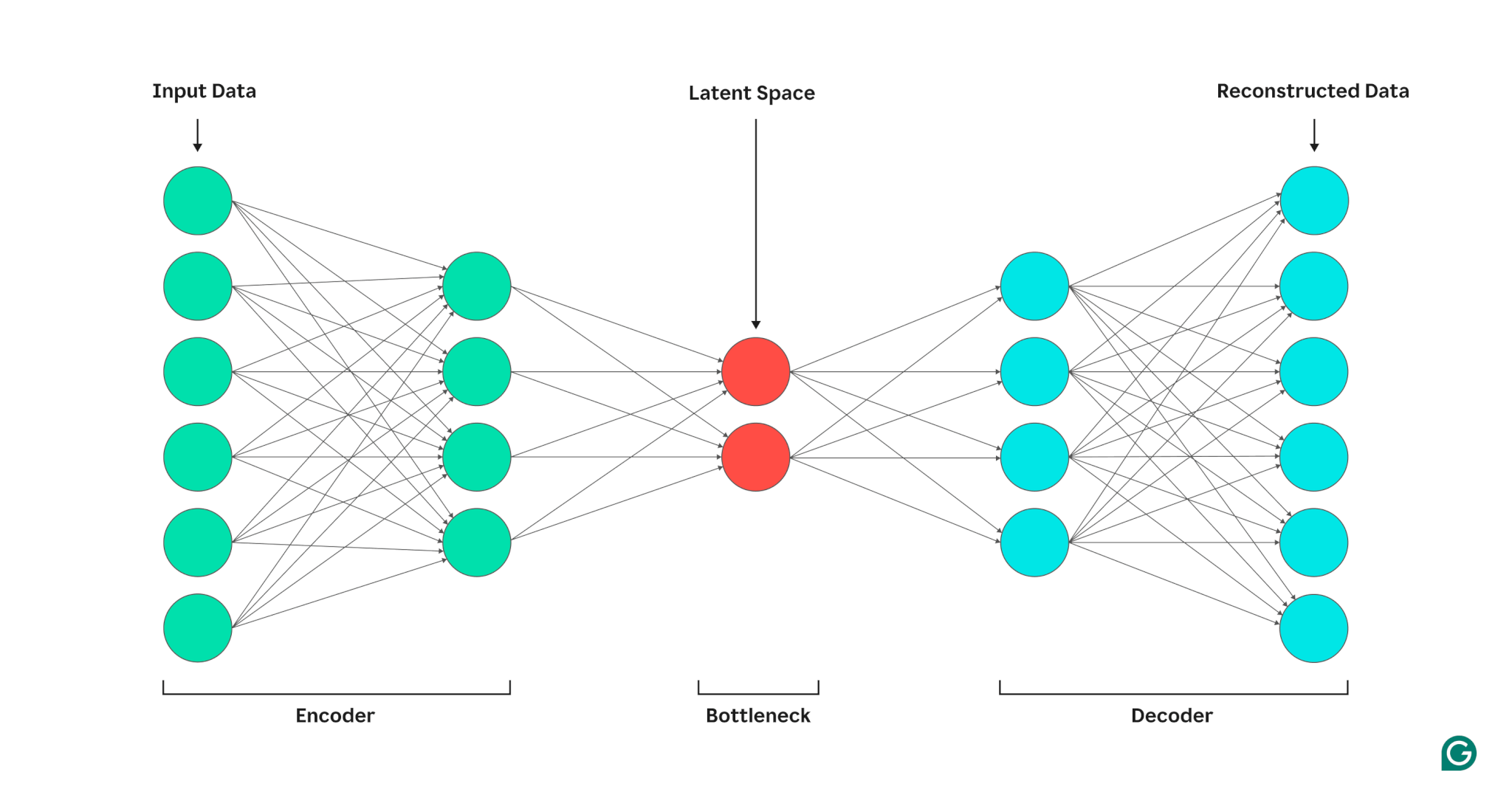
Codificator
În primul rând, codificatorul comprimă datele de intrare într-o reprezentare mai eficientă. Codificatoarele constau în general din mai multe straturi cu mai puține noduri în fiecare strat. Pe măsură ce datele sunt procesate prin fiecare strat, numărul redus de noduri obligă rețeaua să învețe cele mai importante caracteristici ale datelor pentru a crea o reprezentare care poate fi stocată în fiecare strat. Acest proces, cunoscut sub numele de reducere a dimensionalității, transformă intrarea într-un rezumat compact al caracteristicilor cheie ale datelor. Hiperparametrii cheie din codificator includ numărul de straturi și neuroni pe strat, care determină adâncimea și granularitatea compresiei, și funcția de activare, care dictează modul în care caracteristicile datelor sunt reprezentate și transformate la fiecare strat.
Gâtul de sticlă
Blocajul, cunoscut și ca spațiu sau cod latent, este locul în care este stocată reprezentarea comprimată a datelor de intrare în timpul procesării. Blocajul are un număr mic de noduri; aceasta limitează cantitatea de date care pot fi stocate și determină nivelul de compresie. Numărul de noduri din blocaj este un hiperparametru reglabil, care permite utilizatorilor să controleze compromisul dintre compresie și reținerea datelor. Dacă blocajul este prea mic, codificatorul automat poate reconstrui datele incorect din cauza pierderii detaliilor importante. Pe de altă parte, dacă blocajul este prea mare, codificatorul automat poate copia pur și simplu datele de intrare în loc să învețe o reprezentare generală semnificativă.
Decodor
În acest pas final, decodorul recreează datele originale din forma comprimată folosind caracteristicile cheie învățate în timpul procesului de codificare. Calitatea acestei decompresii este cuantificată folosind eroarea de reconstrucție, care este în esență o măsură a cât de diferite sunt datele reconstruite de intrare. Eroarea de reconstrucție este, în general, calculată folosind eroarea pătratică medie (MSE). Deoarece MSE măsoară diferența pătrată dintre datele originale și cele reconstruite, oferă o modalitate simplă din punct de vedere matematic de a penaliza mai puternic erorile de reconstrucție mai mari.
Tipuri de autoencodere
Există mai multe tipuri de autoencodere specializate, fiecare optimizat pentru aplicații specifice, similare cu alte rețele neuronale.
Dezgomot autoencoder
Codificatoarele automate pentru eliminarea zgomotului sunt proiectate pentru a reconstrui date curate de la intrarea zgomotoasă sau coruptă. În timpul antrenamentului, zgomotul este adăugat în mod intenționat datelor de intrare, permițând modelului să învețe caracteristici care rămân consistente în ciuda zgomotului. Ieșirile sunt apoi comparate cu intrările originale curate. Acest proces face ca autoencoderele de dezgomot să fie extrem de eficiente în sarcinile de reducere a zgomotului de imagine și audio, inclusiv eliminarea zgomotului de fundal în conferințe video.
Autoencodere rare
Autoencoderele rare limitează numărul de neuroni activi la un moment dat, încurajând rețeaua să învețe reprezentări de date mai eficiente în comparație cu autoencoderele standard. Această constrângere de dispersie este impusă printr-o penalizare care descurajează activarea mai multor neuroni decât un prag specificat. Autoencoderele rare simplifică datele cu dimensiuni mari, păstrând în același timp caracteristicile esențiale, făcându-le valoroase pentru sarcini precum extragerea de caracteristici interpretabile și vizualizarea seturilor de date complexe.
Autoencodere variaționale (VAE)
Spre deosebire de autoencoderele tipice, VAE generează date noi prin codificarea caracteristicilor din datele de antrenament într-o distribuție de probabilitate, mai degrabă decât într-un punct fix. Prin eșantionarea din această distribuție, VAE-urile pot genera diverse date noi, în loc să reconstruiască datele originale din intrare. Această capacitate face VAE utile pentru sarcini generative, inclusiv generarea de date sintetice. De exemplu, în generarea de imagini, un VAE instruit pe un set de date de numere scrise de mână poate crea cifre noi, cu aspect realist, pe baza setului de antrenament, care nu sunt replici exacte.

Autoencodere contractive
Autoencoderele contractive introduc un termen suplimentar de penalizare în timpul calculului erorii de reconstrucție, încurajând modelul să învețe reprezentări de caracteristici care sunt robuste la zgomot. Această penalizare ajută la prevenirea supraajustării prin promovarea învățării caracteristicilor care este invariabilă la variațiile mici ale datelor de intrare. Ca rezultat, autoencoderele contractive sunt mai robuste la zgomot decât autoencoderele standard.
Autoencodere convoluționale (CAE)
CAE-urile utilizează straturi convoluționale pentru a captura ierarhii și modele spațiale în cadrul datelor cu dimensiuni mari. Utilizarea straturilor convoluționale face ca CAE-urile să fie deosebit de potrivite pentru procesarea datelor de imagine. CAE-urile sunt utilizate în mod obișnuit în sarcini precum compresia imaginilor și detectarea anomaliilor în imagini.
Aplicații ale autoencoderelor în AI
Autoencoderele au mai multe aplicații, cum ar fi reducerea dimensionalității, eliminarea zgomotului de imagine și detectarea anomaliilor.
Reducerea dimensionalității
Codificatoarele automate sunt instrumente eficiente pentru reducerea dimensionalității datelor de intrare, păstrând în același timp caracteristicile cheie. Acest proces este valoros pentru sarcini precum vizualizarea seturilor de date cu dimensiuni mari și comprimarea datelor. Prin simplificarea datelor, reducerea dimensionalității îmbunătățește și eficiența computațională, reducând atât dimensiunea, cât și complexitatea.
Detectarea anomaliilor
Învățând caracteristicile cheie ale unui set de date țintă, codificatoarele automate pot distinge între datele normale și cele anormale atunci când sunt furnizate cu o nouă intrare. Abaterea de la normal este indicată de rate de eroare de reconstrucție mai mari decât cele normale. Ca atare, codificatoarele automate pot fi aplicate în diverse domenii, cum ar fi întreținerea predictivă și securitatea rețelei de calculatoare.
Dezgomot
Dezgomotul autoencoderelor poate curăța datele zgomotoase, învățând să le reconstruiască din intrările de antrenament zgomotoase. Această capacitate face ca autoencoderele de dezgomot să fie valoroase pentru sarcini precum optimizarea imaginii, inclusiv îmbunătățirea calității fotografiilor neclare. Autoencoderele de dezgomot sunt utile și în procesarea semnalului, unde pot curăța semnalele zgomotoase pentru o procesare și o analiză mai eficiente.
Avantajele autoencoderelor
Codificatoarele automate au o serie de avantaje cheie. Acestea includ capacitatea de a învăța din date neetichetate, de a învăța automat caracteristici fără instrucțiuni explicite și de a extrage caracteristici neliniare.
Capabil să învețe din date neetichetate
Codificatoarele automate sunt un model de învățare automată nesupravegheată, ceea ce înseamnă că pot învăța caracteristicile de date subiacente din date neetichetate. Această capacitate înseamnă că autoencoderele pot fi aplicate sarcinilor în care datele etichetate pot fi rare sau indisponibile.
Învățare automată a caracteristicilor
Tehnicile standard de extragere a caracteristicilor, cum ar fi analiza componentelor principale (PCA), sunt adesea nepractice atunci când vine vorba de manipularea seturi de date complexe și/sau mari. Deoarece codificatoarele automate au fost concepute având în vedere sarcini precum reducerea dimensionalității, ei pot învăța automat caracteristicile și modelele cheie în date fără proiectarea manuală a caracteristicilor.
Extragerea caracteristicilor neliniare
Codificatoarele automate pot gestiona relații neliniare în datele de intrare, permițând modelului să capteze caracteristici cheie din reprezentări de date mai complexe. Această capacitate înseamnă că autoencoderele au un avantaj față de modelele care pot funcționa numai cu date liniare, deoarece pot gestiona seturi de date mai complexe.
Limitările autoencoderelor
Ca și alte modele ML, autoencoderele vin cu propriul set de dezavantaje. Acestea includ lipsa de interpretabilitate, necesitatea unui set mare de date de antrenament pentru a funcționa bine și capacități limitate de generalizare.
Lipsa de interpretabilitate
Similar cu alte modele complexe ML, autoencoderele suferă de lipsă de interpretabilitate, ceea ce înseamnă că este greu de înțeles relația dintre datele de intrare și ieșirea modelului. În autoencodere, această lipsă de interpretabilitate apare deoarece autoencoderele învață automat caracteristici, spre deosebire de modelele tradiționale, unde caracteristicile sunt definite în mod explicit. Această reprezentare a caracteristicilor generate de mașină este adesea foarte abstractă și tinde să lipsească de caracteristici interpretabile de către om, ceea ce face dificilă înțelegerea a ceea ce înseamnă fiecare componentă din reprezentare.
Necesită seturi mari de date de antrenament
Codificatoarele automate necesită de obicei seturi mari de date de antrenament pentru a învăța reprezentări generalizabile ale caracteristicilor cheie ale datelor. Având în vedere seturile de date de antrenament mici, codificatoarele automate pot avea tendința de a se supraadapta, ceea ce duce la o generalizare slabă atunci când sunt prezentate cu date noi. Seturile mari de date, pe de altă parte, oferă diversitatea necesară pentru ca autoencoderul să învețe caracteristicile de date care pot fi aplicate într-o gamă largă de scenarii.
Generalizare limitată asupra datelor noi
Autoencoders instruiți pe un set de date au adesea capacități de generalizare limitate, ceea ce înseamnă că nu se adaptează la noile seturi de date. Această limitare apare deoarece codificatoarele automate sunt orientate spre reconstrucția datelor pe baza caracteristicilor proeminente dintr-un anumit set de date. Ca atare, codificatoarele automate aruncă în general detalii mai mici din date în timpul antrenamentului și nu pot gestiona datele care nu se potrivesc cu reprezentarea caracteristică generalizată.