
Ce este un arbore de decizie în învățarea automată?
Publicat: 2024-08-14Arborele de decizie sunt unul dintre cele mai comune instrumente din setul de instrumente de învățare automată al unui analist de date. În acest ghid, veți afla ce sunt arborii de decizie, cum sunt construiți, diverse aplicații, beneficii și multe altele.
Cuprins
- Ce este un arbore de decizie?
- Terminologia arborelui decizional
- Tipuri de arbori de decizie
- Cum funcționează arborii de decizie
- Aplicații
- Avantaje
- Dezavantaje
Ce este un arbore de decizie?
În învățarea automată (ML), un arbore de decizie este un algoritm de învățare supravegheată care seamănă cu o diagramă de flux sau o diagramă de decizie. Spre deosebire de mulți alți algoritmi de învățare supravegheată, arborii de decizie pot fi utilizați atât pentru sarcini de clasificare, cât și pentru regresie. Oamenii de știință și analiștii de date folosesc adesea arbori de decizie atunci când explorează noi seturi de date, deoarece sunt ușor de construit și interpretat. În plus, arborii de decizie pot ajuta la identificarea caracteristicilor de date importante care pot fi utile atunci când se aplică algoritmi ML mai complecși.
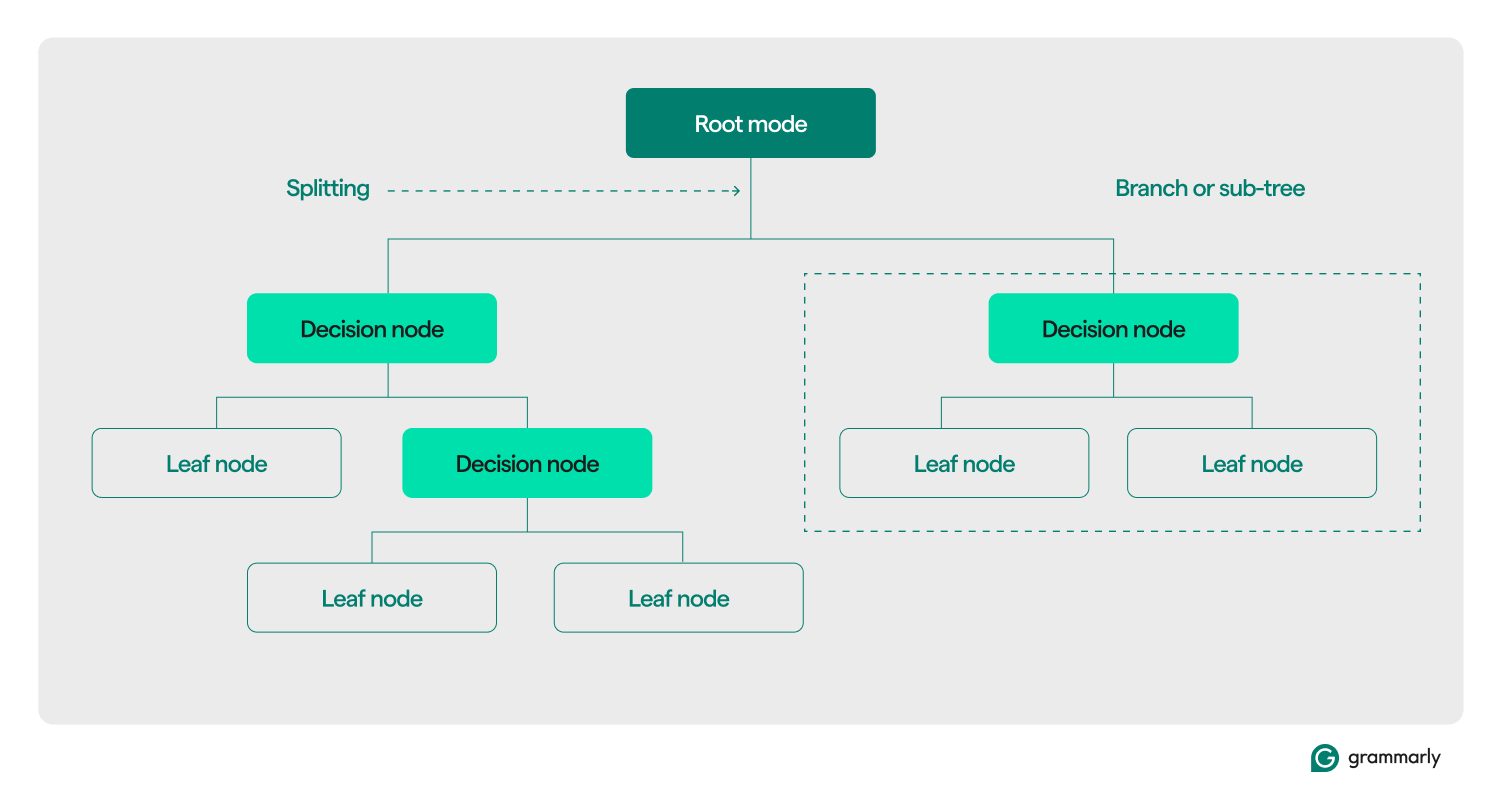
Terminologia arborelui decizional
Din punct de vedere structural, un arbore de decizie constă de obicei din trei componente: un nod rădăcină, noduri frunză și noduri de decizie (sau interne). La fel ca diagramele de flux sau arborii din alte domenii, deciziile dintr-un arbore se deplasează de obicei într-o direcție (fie în jos, fie în sus), pornind de la nodul rădăcină, trecând prin unele noduri de decizie și terminând la un anumit nod frunză. Fiecare nod frunză conectează un subset al datelor de antrenament la o etichetă. Arborele este asamblat printr-un proces de instruire și optimizare ML și, odată construit, poate fi aplicat la diferite seturi de date.
Iată o scufundare mai profundă în restul terminologiei:
- Nod rădăcină:un nod care conține prima dintr-o serie de întrebări pe care arborele de decizie le va adresa cu privire la date. Nodul va fi conectat la cel puțin unul (dar de obicei două sau mai multe) noduri de decizie sau frunză.
- Noduri de decizie (sau noduri interne):noduri suplimentare care conțin întrebări. Un nod de decizie va conține exact o întrebare despre date și va direcționa fluxul de date către unul dintre copiii săi pe baza răspunsului.
- Copii:unul sau mai multe noduri către care indică o rădăcină sau un nod de decizie. Ele reprezintă o listă cu următoarele opțiuni pe care le poate lua procesul decizional în timp ce analizează datele.
- Noduri frunză (sau noduri terminale):Noduri care indică faptul că procesul de decizie a fost finalizat. Odată ce procesul de decizie ajunge la un nod frunză, va returna valoarea (valorile) de la nodul frunză ca rezultat.
- Etichetă (clasă, categorie):în general, un șir asociat de un nod frunză cu unele dintre datele de antrenament. De exemplu, o frunză ar putea asocia eticheta „Client satisfăcut” cu un set de clienți specifici cărora le-a fost prezentat algoritmul de antrenament ML a arborelui de decizie.
- Ramura (sau sub-arborele):Acesta este setul de noduri constând dintr-un nod de decizie în orice punct al arborelui, împreună cu toți copiii săi și copiii lor, până la nodurile frunzelor.
- Tunderea:o operațiune de optimizare efectuată de obicei pe arbore pentru a-l micșora și pentru a-l ajuta să returneze mai repede rezultatele. Tăierea se referă de obicei la „post-tundere”, care implică eliminarea algoritmică a nodurilor sau ramurilor după ce procesul de antrenament ML a construit arborele. „Tăieri înainte” se referă la stabilirea unei limite arbitrare asupra cât de adânc sau mare poate crește un arbore de decizie în timpul antrenamentului. Ambele procese impun o complexitate maximă pentru arborele de decizie, de obicei măsurată prin adâncimea sau înălțimea maximă. Optimizările mai puțin frecvente includ limitarea numărului maxim de noduri de decizie sau de noduri frunză.
- Împărțire:pasul de transformare de bază efectuat pe un arbore de decizie în timpul antrenamentului. Implica împărțirea unei rădăcini sau a unui nod de decizie în două sau mai multe sub-noduri.
- Clasificare:un algoritm ML care încearcă să descopere care (dintr-o listă constantă și discretă de clase, categorii sau etichete) este cel mai probabil să se aplice unei date. Ar putea încerca să răspundă la întrebări precum „Care zi a săptămânii este cea mai bună pentru rezervarea unui zbor?” Mai multe despre clasificare mai jos.
- Regresie:un algoritm ML care încearcă să prezică o valoare continuă, care poate să nu aibă întotdeauna limite. Ar putea încerca să răspundă (sau să prezică răspunsul) la întrebări precum „Câți oameni sunt probabil să rezerve un zbor marțea viitoare?” Vom vorbi mai multe despre arborii de regresie în secțiunea următoare.
Tipuri de arbori de decizie
Arborii de decizie sunt de obicei grupați în două categorii: arbori de clasificare și arbori de regresie. Un arbore specific poate fi construit pentru a se aplica clasificării, regresiei sau ambelor cazuri de utilizare. Majoritatea arborilor de decizie moderni folosesc algoritmul CART (Arbori de clasificare și regresie), care poate îndeplini ambele tipuri de sarcini.
Arbori de clasificare
Arborele de clasificare, cel mai comun tip de arbore de decizie, încearcă să rezolve o problemă de clasificare. Dintr-o listă de răspunsuri posibile la o întrebare (deseori la fel de simplu ca „da” sau „nu”), un arbore de clasificare îl va alege pe cel mai probabil după ce pune câteva întrebări despre datele cu care este prezentat. Ele sunt de obicei implementate ca arbori binari, ceea ce înseamnă că fiecare nod de decizie are exact doi copii.
Arborele de clasificare ar putea încerca să răspundă la întrebări cu variante multiple, cum ar fi „Este acest client mulțumit?” sau „Ce magazin fizic poate fi vizitat de acest client?” sau „Mâine va fi o zi bună pentru a merge la terenul de golf?”
Cele mai comune două metode de măsurare a calității unui arbore de clasificare se bazează pe câștigul de informații și entropia:
- Câștig de informații:eficiența unui arbore este îmbunătățită atunci când pune mai puține întrebări înainte de a ajunge la un răspuns. Câștigul de informații măsoară cât de „rapid” un arbore poate obține un răspuns evaluând cât de multă informații sunt învățate despre o bucată de date la fiecare nod de decizie. Evaluează dacă cele mai importante și utile întrebări sunt adresate mai întâi în arbore.
- Entropie:acuratețea este crucială pentru etichetele arborelui de decizie. Valorile de entropie măsoară această acuratețe prin evaluarea etichetelor produse de arbore. Ei evaluează cât de des o bucată de date aleatoare ajunge cu o etichetă greșită și asemănarea dintre toate datele de antrenament care primesc aceeași etichetă.
Măsurătorile mai avansate ale calității arborilor includindicele gini,raportul de câștig,evaluările chi-pătratși diverse măsurători pentru reducerea varianței.
Arbori de regresie
Arborii de regresie sunt utilizați de obicei în analiza de regresie pentru analize statistice avansate sau pentru a prezice date dintr-un interval continuu, potențial nelimitat. Având în vedere o serie de opțiuni continue (de exemplu, de la zero la infinit pe scara numerelor reale), arborele de regresie încearcă să prezică cea mai probabilă potrivire pentru o anumită bucată de date după ce pune o serie de întrebări. Fiecare întrebare restrânge gama potențială de răspunsuri. De exemplu, un arbore de regresie poate fi folosit pentru a prezice scorurile de credit, veniturile dintr-o linie de afaceri sau numărul de interacțiuni pe un videoclip de marketing.
Precizia arborilor de regresie este de obicei evaluată folosind valori precumeroarea pătrată mediesaueroarea absolută medie, care calculează cât de departe este un anumit set de predicții în comparație cu valorile reale.
Cum funcționează arborii de decizie
Ca exemplu de învățare supravegheată, arborii de decizie se bazează pe date bine formatate pentru instruire. Datele sursă conțin de obicei o listă de valori pe care modelul ar trebui să învețe să le prezică sau să le clasifice. Fiecare valoare ar trebui să aibă o etichetă atașată și o listă de caracteristici asociate - proprietăți pe care modelul ar trebui să învețe să le asocieze cu eticheta.

Construire sau antrenament
În timpul procesului de antrenament, nodurile de decizie din arborele de decizie sunt împărțite recursiv în noduri mai specifice conform unuia sau mai multor algoritmi de antrenament. O descriere la nivel uman a procesului ar putea arăta astfel:
- Începeți cu nodul rădăcinăconectat la întregul set de antrenament.
- Împărțiți nodul rădăcină:folosind o abordare statistică, atribuiți o decizie nodului rădăcină pe baza uneia dintre caracteristicile de date și distribuiți datele de antrenament la cel puțin două noduri frunză separate, conectate ca copii la rădăcină.
- Aplicați recursiv pasul doifiecăruia dintre copii, transformându-i din noduri frunză în noduri de decizie. Opriți-vă când este atinsă o anumită limită (de exemplu, înălțimea/adâncimea copacului, o măsură a calității copiilor din fiecare frunză la fiecare nod etc.) sau dacă ați rămas fără date (adică, fiecare frunză conține date). puncte care sunt legate de exact o etichetă).
Decizia asupra caracteristicilor care trebuie luate în considerare la fiecare nod diferă pentru cazurile de utilizare de clasificare, regresie și clasificare combinată și regresie. Există mulți algoritmi din care să alegeți pentru fiecare scenariu. Algoritmii tipici includ:
- ID3 (clasificare):Optimizează entropia și câștigul de informații
- C4.5 (clasificare):O versiune mai complexă a ID3, adăugând normalizarea câștigului de informații
- CART (clasificare/regresie): „Arborele de clasificare și regresie”; un algoritm lacom care optimizează pentru impurități minime în seturile de rezultate
- CHAID (clasificare/regresie): „Detecție automată a interacțiunii chi-pătrat”; folosește măsurători chi-pătrat în loc de entropie și câștig de informații
- MARS (clasificare/regresie): folosește aproximări liniare pe bucăți pentru a capta neliniaritățile
Un regim de antrenament comun este pădurea aleatorie. O pădure aleatoare sau o pădure de decizie aleatoare este un sistem care construiește mulți arbori de decizie înrudiți. Mai multe versiuni ale unui arbore pot fi antrenate în paralel folosind combinații de algoritmi de antrenament. Pe baza diferitelor măsurători ale calității arborilor, un subset al acestor arbori va fi utilizat pentru a produce un răspuns. Pentru cazurile de utilizare de clasificare, clasa selectată de cel mai mare număr de arbori este returnată ca răspuns. Pentru cazurile de utilizare de regresie, răspunsul este agregat, de obicei ca predicție medie sau medie a arborilor individuali.
Evaluarea și utilizarea arborilor de decizie
Odată ce un arbore de decizie a fost construit, acesta poate clasifica date noi sau poate prezice valori pentru un anumit caz de utilizare. Este important să păstrați valorile privind performanța arborelui și să le folosiți pentru a evalua acuratețea și frecvența erorilor. Dacă modelul se abate prea mult de la performanța așteptată, ar putea fi timpul să-l reeducați pe date noi sau să găsiți alte sisteme ML pe care să le aplicați cazului de utilizare respectiv.
Aplicații ale arborilor de decizie în ML
Arborele de decizie au o gamă largă de aplicații în diverse domenii. Iată câteva exemple pentru a ilustra versatilitatea lor:
Luare a deciziilor personale informate
Un individ ar putea ține evidența datelor despre, de exemplu, restaurantele pe care le-a vizitat. Ei pot urmări orice detalii relevante, cum ar fi timpul de călătorie, timpul de așteptare, bucătăria oferită, orele de deschidere, scorul mediu al recenziilor, costul și cea mai recentă vizită, împreună cu un scor de satisfacție pentru vizita individului la restaurantul respectiv. Un arbore de decizie poate fi antrenat pe aceste date pentru a prezice scorul probabil de satisfacție pentru un nou restaurant.
Calculați probabilitățile în jurul comportamentului clienților
Sistemele de asistență pentru clienți pot folosi arbori de decizie pentru a prezice sau clasifica satisfacția clienților. Un arbore de decizie poate fi antrenat pentru a prezice satisfacția clienților pe baza diferiților factori, cum ar fi dacă clientul a contactat asistența sau a făcut o achiziție repetată sau pe baza acțiunilor efectuate în cadrul unei aplicații. În plus, poate include rezultate din sondaje de satisfacție sau alte feedback-uri ale clienților.
Ajută la informarea deciziilor de afaceri
Pentru anumite decizii de afaceri cu o mulțime de date istorice, un arbore de decizie poate oferi estimări sau predicții pentru următorii pași. De exemplu, o afacere care colectează informații demografice și geografice despre clienții săi poate antrena un arbore decizional pentru a evalua ce noi locații geografice sunt susceptibile de a fi profitabile sau ar trebui evitate. Arborele de decizie poate ajuta, de asemenea, la determinarea celor mai bune limite de clasificare pentru datele demografice existente, cum ar fi identificarea intervalelor de vârstă care trebuie luate în considerare separat atunci când se grupează clienții.
Selectarea caracteristicilor pentru ML avansat și alte cazuri de utilizare
Structurile arborelui de decizie sunt ușor de citit și de înțeles de către om. Odată construit un arbore, este posibil să identificăm care caracteristici sunt cele mai relevante pentru setul de date și în ce ordine. Aceste informații pot ghida dezvoltarea unor sisteme ML mai complexe sau algoritmi de decizie. De exemplu, dacă o companie învață dintr-un arbore de decizie că clienții acordă prioritate costului unui produs mai presus de orice altceva, poate concentra sisteme ML mai complexe pe această perspectivă sau poate ignora costul atunci când explorează funcții mai nuanțate.
Avantajele arborilor de decizie în ML
Arborele de decizie oferă câteva avantaje semnificative care îi fac o alegere populară în aplicațiile ML. Iată câteva beneficii cheie:
Rapid și ușor de construit
Arborii de decizie sunt unul dintre cei mai maturi și mai bine înțeleși algoritmi ML. Ele nu depind de calcule deosebit de complexe și pot fi construite rapid și ușor. Atâta timp cât informațiile necesare sunt disponibile cu ușurință, un arbore de decizie este un prim pas ușor de făcut atunci când se analizează soluțiile ML la o problemă.
Ușor de înțeles pentru oameni
Rezultatele din arborii de decizie sunt deosebit de ușor de citit și interpretat. Reprezentarea grafică a unui arbore de decizie nu depinde de o înțelegere avansată a statisticilor. Ca atare, arborii de decizie și reprezentările lor pot fi utilizate pentru a interpreta, explica și susține rezultatele unor analize mai complexe. Arborii de decizie sunt excelenți la găsirea și evidențierea unora dintre proprietățile de nivel înalt ale unui anumit set de date.
Prelucrarea datelor este necesară
Arborele de decizie poate fi construit la fel de ușor pe date incomplete sau date cu valori aberante incluse. Având în vedere date decorate cu caracteristici interesante, algoritmii arborelui de decizie tind să nu fie afectați la fel de mult ca alți algoritmi ML dacă sunt alimentați cu date care nu au fost preprocesate.
Dezavantajele arborilor de decizie în ML
În timp ce arborii de decizie oferă multe beneficii, ei vin și cu câteva dezavantaje:
Susceptibil la supraadaptare
Arborii de decizie sunt predispuși la supraadaptare, care apare atunci când un model învață zgomotul și detaliile din datele de antrenament, reducându-și performanța pe date noi. De exemplu, dacă datele de antrenament sunt incomplete sau rare, mici modificări ale datelor pot produce structuri arborescente semnificativ diferite. Tehnicile avansate precum tăierea sau stabilirea unei adâncimi maxime pot îmbunătăți comportamentul copacilor. În practică, arborii de decizie au adesea nevoie de actualizare cu informații noi, care le pot modifica semnificativ structura.
Scalabilitate slabă
Pe lângă tendința lor de supraadaptare, arborii de decizie se luptă cu probleme mai avansate care necesită mult mai multe date. În comparație cu alți algoritmi, timpul de pregătire pentru arborii de decizie crește rapid pe măsură ce volumul de date crește. Pentru seturi de date mai mari care ar putea avea proprietăți semnificative la nivel înalt de detectat, arborii de decizie nu se potrivesc foarte bine.
Nu la fel de eficient pentru regresie sau cazuri de utilizare continuă
Arborele de decizie nu învață foarte bine distribuțiile complexe de date. Ele împart spațiul caracteristicilor de-a lungul unor linii ușor de înțeles, dar simple din punct de vedere matematic. Pentru probleme complexe în care valorile aberante sunt relevante, regresie și cazuri de utilizare continuă, acest lucru se traduce adesea în performanțe mult mai slabe decât alte modele și tehnici ML.