
Ce este supraadaptarea în învățarea automată?
Publicat: 2024-10-15Supraadaptarea este o problemă comună care apare atunci când antrenați modele de învățare automată (ML). Poate avea un impact negativ asupra capacității unui model de a generaliza dincolo de datele de antrenament, ceea ce duce la predicții inexacte în scenariile din lumea reală. În acest articol, vom explora ce este supraadaptarea, cum apare, cauzele comune din spatele acesteia și modalități eficiente de a o detecta și preveni.
Cuprins
- Ce este supraadaptarea?
- Cum apare supraadaptarea
- Suprafitting vs underfitting
- Ce cauzează supraadaptarea?
- Cum să detectați supraadaptarea
- Cum să evitați supraadaptarea
- Exemple de supraajustare
Ce este supraadaptarea?
Suprafitting este atunci când un model de învățare automată învață tiparele de bază și zgomotul din datele de antrenament, devenind prea specializat în acel set de date specific. Această concentrare excesivă asupra detaliilor datelor de antrenament are ca rezultat o performanță slabă atunci când modelul este aplicat la date noi, nevăzute, deoarece nu reușește să se generalizeze dincolo de datele pe care a fost antrenat.
Cum se întâmplă supraadaptarea?
Supraadaptarea apare atunci când un model învață prea multe din detaliile specifice și zgomotul din datele de antrenament, făcându-l prea sensibil la modele care nu sunt semnificative pentru generalizare. De exemplu, luați în considerare un model construit pentru a prezice performanța angajaților pe baza evaluărilor istorice. Dacă modelul depășește, s-ar putea concentra prea mult pe detalii specifice, negeneralizabile, cum ar fi stilul unic de evaluare al unui fost manager sau circumstanțe particulare din timpul unui ciclu de revizuire trecut. În loc să învețe factorii mai largi și semnificativi care contribuie la performanță – cum ar fi abilitățile, experiența sau rezultatele proiectului – modelul poate avea dificultăți să-și aplice cunoștințele noilor angajați sau să evolueze criteriile de evaluare. Acest lucru duce la predicții mai puțin precise atunci când modelul este aplicat la date care diferă de setul de antrenament.
Suprafitting vs underfitting
Spre deosebire de supraajustare, subadaptarea apare atunci când un model este prea simplu pentru a capta modelele subiacente în date. Ca urmare, performează slab la antrenament, precum și la datele noi, nereușind să facă predicții precise.
Pentru a vizualiza diferența dintre underfitting și overfitting, imaginați-vă că încercăm să prezicem performanța atletică pe baza nivelului de stres al unei persoane. Putem reprezenta datele și arăta trei modele care încearcă să prezică această relație:

1 Underfitting:În primul exemplu, modelul folosește o linie dreaptă pentru a face predicții, în timp ce datele reale urmează o curbă. Modelul este prea simplu și nu reușește să surprindă complexitatea relației dintre nivelul de stres și performanța atletică. Ca urmare, predicțiile sunt în mare parte inexacte, chiar și pentru datele de antrenament. Acest lucru este insuficient.
2Potrivire optimă:al doilea exemplu arată un model care atinge echilibrul potrivit. Captează tendința de bază în date fără a o complica prea mult. Acest model se generalizează bine la datele noi, deoarece nu încearcă să se potrivească cu fiecare variație mică a datelor de antrenament - doar modelul de bază.
3Supraajustare:În exemplul final, modelul folosește o curbă ondulată extrem de complexă pentru a se potrivi cu datele de antrenament. Deși această curbă este foarte precisă pentru datele de antrenament, captează, de asemenea, zgomot aleatoriu și valori aberante care nu reprezintă relația reală. Acest model este supraadaptat, deoarece este atât de fin reglat la datele de antrenament, încât este probabil să facă predicții slabe asupra datelor noi, nevăzute.
Cauze comune ale supraajustării
Acum știm ce este supraadaptarea și de ce se întâmplă, haideți să explorăm câteva cauze comune mai detaliat:
- Date de antrenament insuficiente
- Date inexacte, eronate sau irelevante
- Greutăți mari
- Supraantrenamentul
- Arhitectura modelului este prea sofisticată
Date insuficiente de antrenament
Dacă setul de date de antrenament este prea mic, acesta poate reprezenta doar câteva dintre scenariile pe care modelul le va întâlni în lumea reală. În timpul antrenamentului, modelul se poate potrivi bine cu datele. Cu toate acestea, este posibil să observați inexactități semnificative odată ce îl testați pe alte date. Setul mic de date limitează capacitatea modelului de a se generaliza la situații nevăzute, făcându-l predispus la supraadaptare.
Date inexacte, eronate sau irelevante
Chiar dacă setul de date de antrenament este mare, acesta poate conține erori. Aceste erori pot apărea din diverse surse, cum ar fi participanții care furnizează informații false în sondaje sau citirile defectuoase ale senzorilor. Dacă modelul încearcă să învețe din aceste inexactități, se va adapta la tipare care nu reflectă adevăratele relații de bază, ceea ce duce la supraadaptare.
Greutăți mari
În modelele de învățare automată, ponderile sunt valori numerice care reprezintă importanța atribuită unor caracteristici specifice din date atunci când se fac predicții. Când greutățile devin disproporționat de mari, modelul se poate supraadapta, devenind prea sensibil la anumite caracteristici, inclusiv zgomotul din date. Acest lucru se întâmplă deoarece modelul devine prea dependent de anumite caracteristici, ceea ce îi dăunează capacității de generalizare la date noi.
Supraantrenamentul
În timpul antrenamentului, algoritmul prelucrează datele în loturi, calculează eroarea pentru fiecare lot și ajustează greutățile modelului pentru a-și îmbunătăți acuratețea.
Este o idee bună să continuați antrenamentul cât mai mult timp posibil? Nu chiar! Antrenamentul prelungit pe aceleași date poate determina modelul să memoreze anumite puncte de date, limitându-și capacitatea de generalizare la date noi sau nevăzute, care este esența supraajustării. Acest tip de supraadaptare poate fi atenuat prin utilizarea tehnicilor de oprire timpurie sau prin monitorizarea performanței modelului pe un set de validare în timpul antrenamentului. Vom discuta cum funcționează acest lucru mai târziu în articol.
Arhitectura modelului este prea complexă
Arhitectura unui model de învățare automată se referă la modul în care straturile și neuronii săi sunt structurați și modul în care aceștia interacționează pentru a procesa informații.

Arhitecturile mai complexe pot captura modele detaliate în datele de antrenament. Cu toate acestea, această complexitate crește probabilitatea de supraadaptare, deoarece modelul poate învăța, de asemenea, să capteze zgomotul sau detalii irelevante care nu contribuie la predicții precise asupra datelor noi. Simplificarea arhitecturii sau folosirea tehnicilor de regularizare poate contribui la reducerea riscului de supraadaptare.
Cum să detectați supraadaptarea
Detectarea supraajustării poate fi dificilă, deoarece totul poate părea să meargă bine în timpul antrenamentului, chiar și atunci când are loc supraadaptarea. Rata de pierdere (sau eroare) - o măsură a frecvenței cu care modelul este greșit - va continua să scadă, chiar și într-un scenariu de supraadaptare. Așadar, cum putem ști dacă a avut loc supraadaptarea? Avem nevoie de un test de încredere.
O metodă eficientă este utilizarea unei curbe de învățare, o diagramă care urmărește o măsură numită pierdere. Pierderea reprezintă mărimea erorii pe care modelul o face. Cu toate acestea, nu urmărim doar pierderea datelor de antrenament; măsurăm, de asemenea, pierderea datelor nevăzute, numite date de validare. Acesta este motivul pentru care curba de învățare are de obicei două linii: pierderea antrenamentului și pierderea validării.
Dacă pierderea de antrenament continuă să scadă conform așteptărilor, dar pierderea de validare crește, acest lucru sugerează o supraadaptare. Cu alte cuvinte, modelul devine excesiv de specializat pentru datele de antrenament și se luptă să se generalizeze la date noi, nevăzute. Curba de învățare ar putea arăta cam așa:
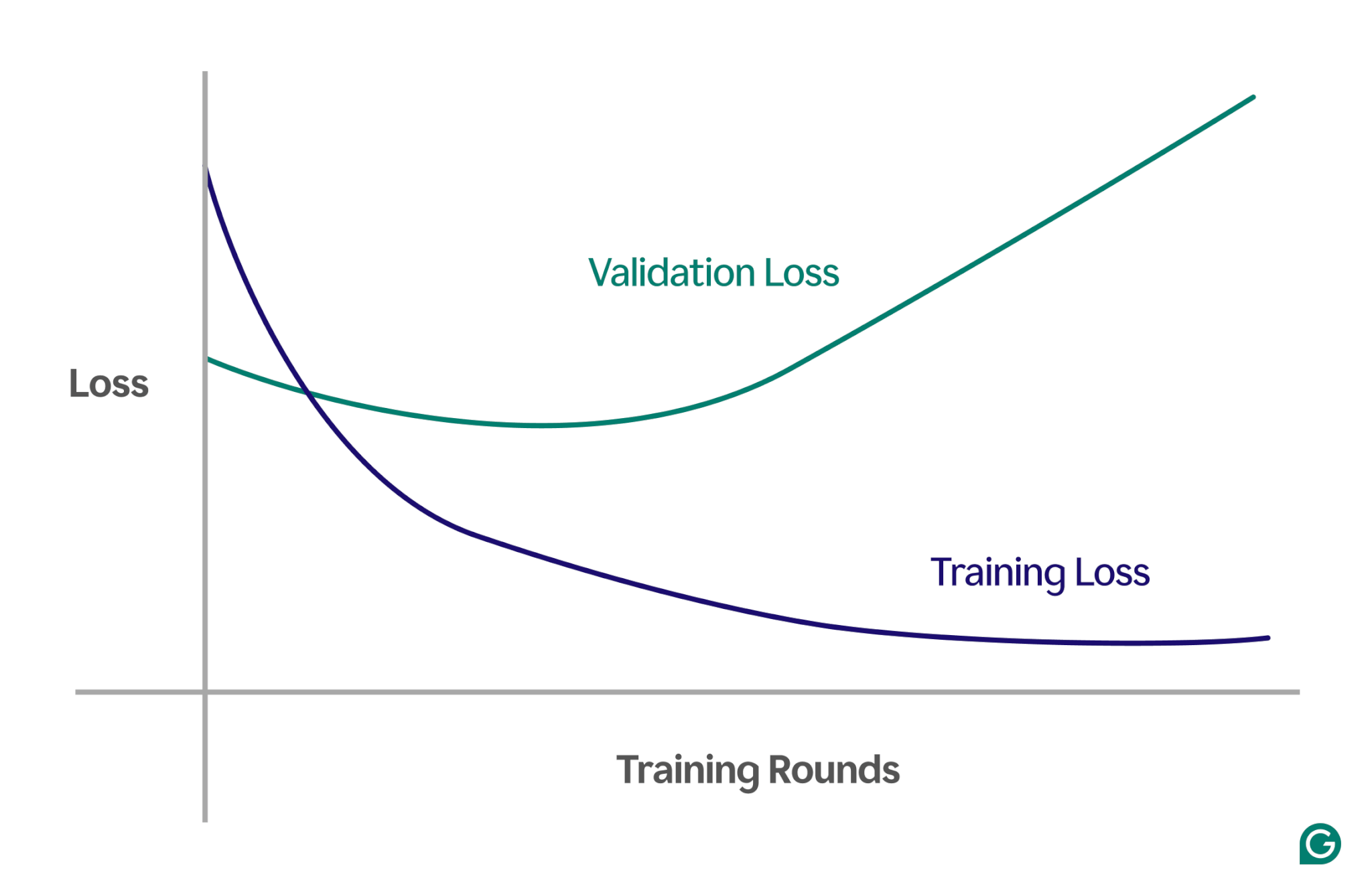
În acest scenariu, în timp ce modelul se îmbunătățește în timpul antrenamentului, are performanțe slabe pe datele nevăzute. Acest lucru înseamnă probabil că a avut loc o supraadaptare.
Cum să evitați supraadaptarea
Suprafitting poate fi abordat folosind mai multe tehnici. Iată câteva dintre cele mai comune metode:
Reduceți dimensiunea modelului
Majoritatea arhitecturilor de model vă permit să ajustați numărul de greutăți prin modificarea numărului de straturi, dimensiunilor straturilor și alți parametri cunoscuți sub numele de hiperparametri. Dacă complexitatea modelului provoacă supraajustare, reducerea dimensiunii acestuia poate ajuta. Simplificarea modelului prin reducerea numărului de straturi sau neuroni poate reduce riscul de supraadaptare, deoarece modelul va avea mai puține oportunități de a memora datele de antrenament.
Regularizează modelul
Regularizarea presupune modificarea modelului pentru a descuraja greutățile mari. O abordare este ajustarea funcției de pierdere astfel încât să măsoare eroarea și să includă dimensiunea greutăților.
Odată cu regularizarea, algoritmul de antrenament minimizează atât eroarea, cât și dimensiunea greutăților, reducând probabilitatea unor greutăți mari, cu excepția cazului în care acestea oferă un avantaj clar modelului. Acest lucru ajută la prevenirea supraajustării prin păstrarea modelului mai generalizat.
Adăugați mai multe date de antrenament
Creșterea dimensiunii setului de date de antrenament poate ajuta, de asemenea, la prevenirea supraadaptării. Cu mai multe date, este mai puțin probabil ca modelul să fie influențat de zgomot sau inexactități din setul de date. Expunerea modelului la exemple mai variate va face ca acesta să fie mai puțin înclinat să memoreze puncte de date individuale și, în schimb, să învețe modele mai largi.
Aplicați reducerea dimensionalității
Uneori, datele pot conține caracteristici (sau dimensiuni) corelate, ceea ce înseamnă că mai multe caracteristici sunt legate într-un fel. Modelele de învățare automată tratează dimensiunile ca fiind independente, așa că, dacă caracteristicile sunt corelate, modelul s-ar putea concentra prea mult asupra lor, ceea ce duce la supraadaptare.
Tehnicile statistice, cum ar fi analiza componentelor principale (PCA), pot reduce aceste corelații. PCA simplifică datele prin reducerea numărului de dimensiuni și eliminarea corelațiilor, făcând supraadaptarea mai puțin probabilă. Prin concentrarea pe cele mai relevante caracteristici, modelul devine mai bun la generalizarea la date noi.
Exemple practice de supraadaptare
Pentru a înțelege mai bine supraadaptarea, haideți să explorăm câteva exemple practice în diferite domenii în care supraadaptarea poate duce la rezultate înșelătoare.
Clasificarea imaginilor
Clasificatoarele de imagini sunt concepute pentru a recunoaște obiectele din imagini, de exemplu, dacă o imagine conține o pasăre sau un câine.
Alte detalii se pot corela cu ceea ce încercați să detectați în aceste imagini. De exemplu, fotografiile cu câini pot avea adesea iarbă în fundal, în timp ce fotografiile cu păsări pot avea adesea un cer sau vârfurile copacilor în fundal.
Dacă toate imaginile de antrenament au aceste detalii consistente de fundal, modelul de învățare automată poate începe să se bazeze pe fundal pentru a recunoaște animalul, în loc să se concentreze pe caracteristicile reale ale animalului însuși. Ca urmare, atunci când modelului i se cere să clasifice o imagine a unei păsări cocoțate pe un gazon, este posibil să o clasifice incorect drept câine, deoarece este prea potrivită cu informațiile de fundal. Acesta este un caz de supraadaptare la datele de antrenament.
Modelare financiară
Să presupunem că tranzacționați acțiuni în timpul liber și credeți că este posibil să preziceți mișcările prețurilor pe baza tendințelor căutărilor Google pentru anumite cuvinte cheie. Ați configurat un model de învățare automată folosind datele Google Trends pentru mii de cuvinte.
Deoarece există atât de multe cuvinte, unele vor arăta probabil o corelație cu prețurile acțiunilor dvs. pur întâmplător. Modelul poate supraadapta aceste corelații coincidente, făcând predicții slabe asupra datelor viitoare, deoarece cuvintele nu sunt predictori relevanți ai prețurilor acțiunilor.
Când construiți modele pentru aplicații financiare, este important să înțelegeți baza teoretică a relațiilor din date. Introducerea unor seturi mari de date într-un model fără o selecție atentă a caracteristicilor poate crește riscul de supraadaptare, mai ales atunci când modelul identifică corelații false care există pur întâmplător în datele de antrenament.
Superstiția sportivă
Deși nu sunt strict legate de învățarea automată, superstițiile sportive pot ilustra conceptul de supraadaptare – în special atunci când rezultatele sunt legate de date care în mod logic nu au nicio legătură cu rezultatul.
În timpul campionatelor de fotbal UEFA Euro 2008 și a Cupei Mondiale FIFA din 2010, o caracatiță pe nume Paul a fost folosită pentru a prezice rezultatele meciurilor cu Germania. Paul a corectat patru din șase predicții în 2008 și toate șapte în 2010.
Dacă luați în considerare doar „datele de antrenament” ale predicțiilor anterioare ale lui Pavel, un model care este de acord cu alegerile lui Pavel ar părea să prezică foarte bine rezultatele. Cu toate acestea, acest model nu ar fi generalizat bine la jocurile viitoare, deoarece alegerile caracatiței sunt predictori nesiguri ai rezultatelor meciurilor.