
Основы генеративно-состязательной сети: что вам нужно знать
Опубликовано: 2024-10-08Генеративно-состязательные сети (GAN) — это мощный инструмент искусственного интеллекта (ИИ), имеющий множество применений в машинном обучении (ML). В этом руководстве рассматриваются GAN, как они работают, их применение, а также их преимущества и недостатки.
Оглавление
- Что такое ГАН?
- GAN против CNN
- Как работают GAN
- Типы ГАНов
- Применение GAN
- Преимущества ГАНов
- Недостатки GAN
Что такое генеративно-состязательная сеть?
Генеративно-состязательная сеть, или GAN, — это тип модели глубокого обучения, обычно используемый в машинном обучении без учителя, но также адаптируемый для полуконтролируемого и контролируемого обучения. GAN используются для генерации высококачественных данных, аналогичных набору обучающих данных. Являясь подмножеством генеративного ИИ, GAN состоят из двух подмоделей: генератора и дискриминатора.
1 Генератор:Генератор создает синтетические данные.
2 Дискриминатор:Дискриминатор оценивает выходные данные генератора, различая реальные данные из обучающего набора и синтетические данные, созданные генератором.
Две модели конкурируют: генератор пытается обмануть дискриминатор, заставив его классифицировать сгенерированные данные как реальные, в то время как дискриминатор постоянно совершенствует свою способность обнаруживать синтетические данные. Этот состязательный процесс продолжается до тех пор, пока дискриминатор больше не сможет различать реальные и сгенерированные данные. На этом этапе GAN способна генерировать реалистичные изображения, видео и другие типы данных.
GAN против CNN
GAN и сверточные нейронные сети (CNN) — это мощные типы нейронных сетей, используемые в глубоком обучении, но они существенно различаются с точки зрения вариантов использования и архитектуры.
Варианты использования
- GAN:специализируются на создании реалистичных синтетических данных на основе обучающих данных. Это делает GAN хорошо подходящими для таких задач, как генерация изображений, передача стилей изображений и увеличение данных. GAN не контролируются, а это означает, что их можно применять в сценариях, где помеченные данные недостаточны или недоступны.
- CNN:в основном используются для задач классификации структурированных данных, таких как анализ настроений, категоризация тем и языковой перевод. Благодаря своим классификационным способностям CNN также служат хорошими дискриминаторами в GAN. Однако, поскольку CNN требуют структурированных, аннотированных человеком обучающих данных, они ограничены сценариями обучения с учителем.
Архитектура
- GAN:состоят из двух моделей — дискриминатора и генератора, которые участвуют в конкурентном процессе. Генератор создает изображения, а дискриминатор оценивает их, заставляя генератор со временем создавать все более реалистичные изображения.
- CNN:используйте слои сверточных операций и операций объединения для извлечения и анализа функций из изображений. Эта одномодельная архитектура ориентирована на распознавание шаблонов и структур в данных.
В целом, в то время как CNN ориентированы на анализ существующих структурированных данных, GAN ориентированы на создание новых, реалистичных данных.
Как работают GAN
На высоком уровне GAN работает, противопоставляя друг другу две нейронные сети — генератор и дискриминатор. GAN не требуют определенного типа архитектуры нейронной сети ни для одного из двух своих компонентов, если выбранные архитектуры дополняют друг друга. Например, если CNN используется в качестве дискриминатора для генерации изображений, то генератором может быть деконволюционная нейронная сеть (deCNN), которая выполняет процесс CNN в обратном порядке. У каждого компонента своя цель:
- Генератор:производить данные такого высокого качества, что дискриминатор обманом классифицирует их как реальные.
- Дискриминатор:для точной классификации данного образца данных как реального (из набора обучающих данных) или поддельного (сгенерированного генератором).
Это соревнование представляет собой реализацию игры с нулевой суммой, в которой вознаграждение, данное одной модели, является также штрафом для другой модели. Для генератора успешный обман дискриминатора приводит к обновлению модели, которое повышает его способность генерировать реалистичные данные. И наоборот, когда дискриминатор правильно идентифицирует фальшивые данные, он получает обновление, которое улучшает его возможности обнаружения. Математически дискриминатор стремится минимизировать ошибку классификации, а генератор стремится максимизировать ее.
Процесс обучения GAN
Обучение GAN включает в себя поочередное использование генератора и дискриминатора в течение нескольких эпох. Эпохи — это полные обучающие прогоны по всему набору данных. Этот процесс продолжается до тех пор, пока генератор не выдаст синтетические данные, которые обманывают дискриминатор примерно в 50% случаев. Хотя обе модели используют схожие алгоритмы для оценки и улучшения производительности, их обновления происходят независимо. Эти обновления выполняются с использованием метода обратного распространения ошибки, который измеряет ошибку каждой модели и корректирует параметры для повышения производительности. Затем алгоритм оптимизации настраивает параметры каждой модели независимо.
Вот визуальное представление архитектуры GAN, иллюстрирующее конкуренцию между генератором и дискриминатором:
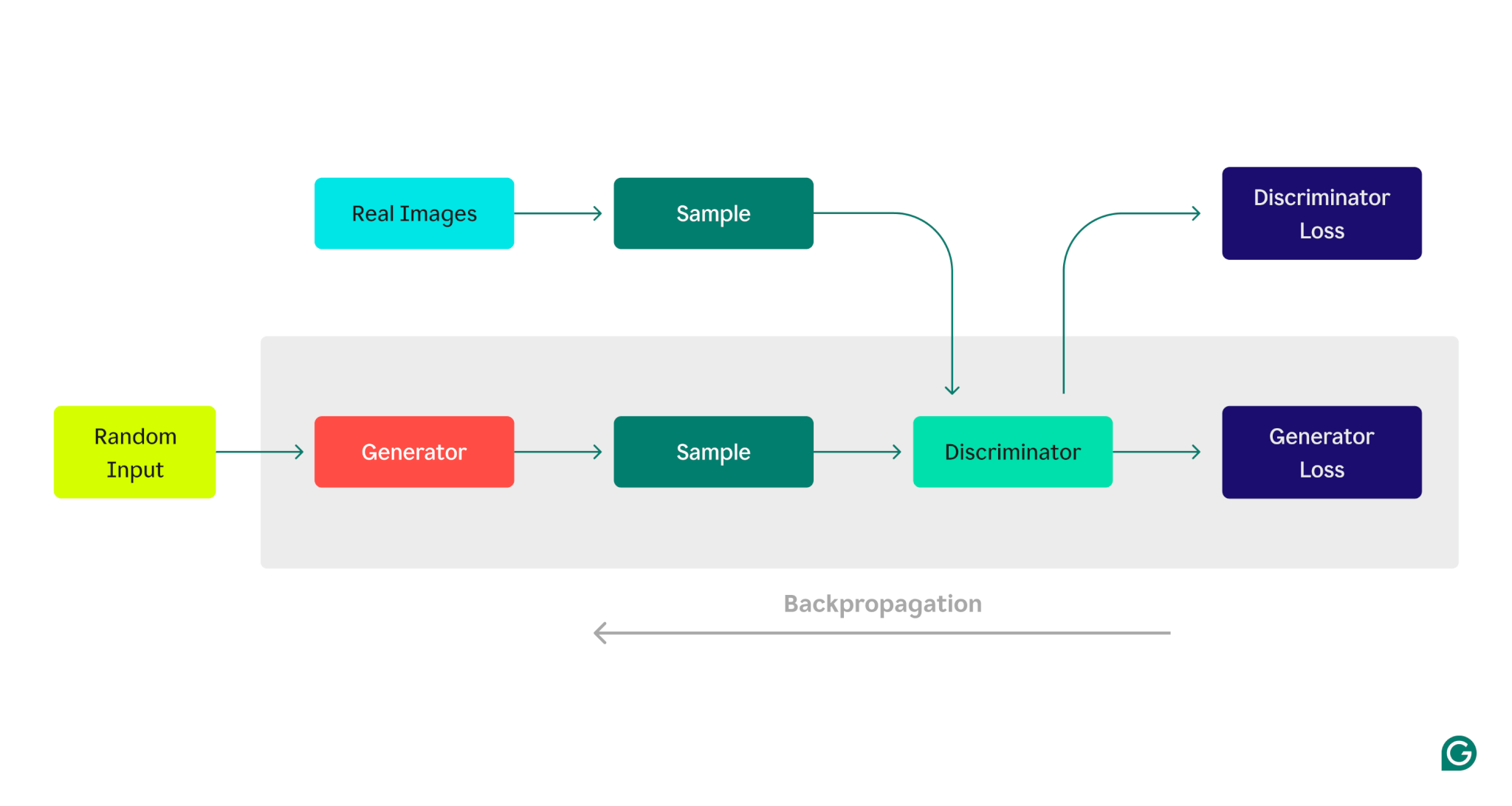
Этап обучения генератора:
1 Генератор создает выборки данных, обычно начиная со случайного шума в качестве входных данных.
2 Дискриминатор классифицирует эти выборки как настоящие (из обучающего набора данных) или поддельные (сгенерированные генератором).
3 На основе ответа дискриминатора параметры генератора обновляются с использованием обратного распространения ошибки.
Фаза обучения дискриминатора:
1 Фейковые данные генерируются с использованием текущего состояния генератора.
2 Сгенерированные выборки передаются дискриминатору вместе с выборками из набора обучающих данных.
3. Используя обратное распространение ошибки, параметры дискриминатора обновляются в зависимости от его эффективности классификации.
Этот итеративный процесс обучения продолжается, при этом параметры каждой модели корректируются в зависимости от ее производительности, пока генератор последовательно не выдаст данные, которые дискриминатор не может надежно отличить от реальных данных.
Типы ГАНов
Основываясь на базовой архитектуре GAN, часто называемой «ванильной GAN», были разработаны и оптимизированы другие специализированные типы GAN для различных задач. Некоторые из наиболее распространенных вариантов описаны ниже, хотя это не исчерпывающий список:
Условный ГАН (cGAN)
Условные GAN, или cGAN, используют дополнительную информацию, называемую условиями, чтобы помочь модели генерировать определенные типы данных при обучении на более общем наборе данных. Условием может быть метка класса, текстовое описание или другой тип классифицирующей информации для данных. Например, представьте, что вам нужно создать изображения только сиамских кошек, но ваш набор обучающих данных содержит изображения всех видов кошек. В cGAN вы можете пометить обучающие изображения типом кошки, и модель может использовать это, чтобы научиться генерировать только изображения сиамских кошек.

Глубокий сверточный GAN (DCGAN)
Глубокая сверточная GAN, или DCGAN, оптимизирована для генерации изображений. В DCGAN генератором является сверточная нейронная сеть глубокого внедрения (deCNN), а дискриминатором — глубокая CNN. CNN лучше подходят для работы с изображениями и их создания благодаря их способности улавливать пространственные иерархии и закономерности. Генератор в DCGAN использует повышающую дискретизацию и транспонированные сверточные слои для создания изображений более высокого качества, чем мог бы создать многослойный персептрон (простая нейронная сеть, которая принимает решения путем взвешивания входных функций). Аналогично, дискриминатор использует сверточные слои для извлечения признаков из образцов изображений и точной классификации их как реальных или поддельных.
ЦиклГАН
CycleGAN — это тип GAN, предназначенный для создания одного типа изображения из другого. Например, CycleGAN может преобразовать изображение мыши в крысу или собаку в койота. CycleGAN способны выполнять этот перевод изображения в изображение без обучения на парных наборах данных, то есть наборах данных, содержащих как базовое изображение, так и желаемое преобразование. Эта возможность достигается за счет использования двух генераторов и двух дискриминаторов вместо одной пары, которую использует стандартная GAN. В CycleGAN один генератор преобразует изображения из базового изображения в преобразованную версию, а другой генератор выполняет преобразование в противоположном направлении. Аналогично, каждый дискриминатор проверяет определенный тип изображения, чтобы определить, настоящее оно или поддельное. Затем CycleGAN использует проверку согласованности, чтобы убедиться, что преобразование изображения в другой стиль и обратно приводит к исходному изображению.
Применение GAN
Благодаря своей уникальной архитектуре GAN применяются в ряде инновационных случаев использования, хотя их производительность во многом зависит от конкретных задач и качества данных. Некоторые из наиболее мощных приложений включают генерацию текста в изображение, увеличение данных, а также генерацию и манипулирование видео.
Генерация текста в изображение
GAN могут генерировать изображения из текстового описания. Это приложение ценно в творческих отраслях, поскольку позволяет авторам и дизайнерам визуализировать сцены и персонажей, описанных в тексте. Хотя GAN часто используются для таких задач, другие модели генеративного ИИ, такие как DALL-E от OpenAI, используют архитектуры на основе трансформаторов для достижения аналогичных результатов.
Увеличение данных
GAN полезны для увеличения данных, поскольку они могут генерировать синтетические данные, напоминающие реальные данные обучения, хотя степень точности и реалистичности может варьироваться в зависимости от конкретного варианта использования и обучения модели. Эта возможность особенно ценна в машинном обучении для расширения ограниченных наборов данных и повышения производительности модели. Кроме того, GAN предлагают решение для обеспечения конфиденциальности данных. В таких чувствительных областях, как здравоохранение и финансы, GAN могут создавать синтетические данные, сохраняющие статистические свойства исходного набора данных без ущерба для конфиденциальной информации.
Генерация и обработка видео
GAN показали себя многообещающе в некоторых задачах создания и манипулирования видео. Например, GAN можно использовать для генерации будущих кадров из исходной видеопоследовательности, что помогает в таких приложениях, как прогнозирование движения пешеходов или прогнозирование дорожных опасностей для автономных транспортных средств. Однако эти приложения все еще находятся в стадии активных исследований и разработок. GAN также можно использовать для создания полностью синтетического видеоконтента и улучшения видео с помощью реалистичных спецэффектов.
Преимущества ГАНов
GAN предлагают несколько явных преимуществ, включая возможность генерировать реалистичные синтетические данные, учиться на непарных данных и выполнять обучение без присмотра.
Генерация высококачественных синтетических данных
Архитектура GAN позволяет им создавать синтетические данные, которые могут аппроксимировать реальные данные в таких приложениях, как увеличение данных и создание видео, хотя качество и точность этих данных могут сильно зависеть от условий обучения и параметров модели. Например, DCGAN, которые используют CNN для оптимальной обработки изображений, превосходно создают реалистичные изображения.
Способен учиться на непарных данных
В отличие от некоторых моделей ML, GAN могут учиться на наборах данных без парных примеров входных и выходных данных. Такая гибкость позволяет использовать GAN в широком спектре задач, где парные данные недостаточны или недоступны. Например, в задачах перевода изображений в изображения традиционные модели часто требуют набора данных изображений и их преобразований для обучения. Напротив, GAN могут использовать более широкий спектр потенциальных наборов данных для обучения.
Обучение без присмотра
GAN — это метод машинного обучения без учителя, что означает, что их можно обучать на неразмеченных данных без явного указания. Это особенно выгодно, поскольку маркировка данных — трудоемкий и дорогостоящий процесс. Способность GAN учиться на неразмеченных данных делает их ценными для приложений, где размеченные данные ограничены или их трудно получить. GAN также можно адаптировать для полуконтролируемого и контролируемого обучения, что позволяет им также использовать помеченные данные.
Недостатки GAN
Хотя GAN являются мощным инструментом машинного обучения, их архитектура имеет ряд уникальных недостатков. Эти недостатки включают чувствительность к гиперпараметрам, высокие вычислительные затраты, сбой сходимости и явление, называемое коллапсом мод.
Чувствительность гиперпараметра
GAN чувствительны к гиперпараметрам, которые представляют собой параметры, установленные до обучения, а не полученные из данных. Примеры включают сетевые архитектуры и количество обучающих примеров, используемых за одну итерацию. Небольшие изменения в этих параметрах могут существенно повлиять на процесс обучения и результаты модели, что потребует обширной тонкой настройки для практических приложений.
Высокая вычислительная стоимость
Из-за сложной архитектуры, итеративного процесса обучения и чувствительности к гиперпараметрам GAN часто требуют больших вычислительных затрат. Для успешного обучения GAN требуется специализированное и дорогое оборудование, а также значительное время, что может стать препятствием для многих организаций, желающих использовать GAN.
Ошибка конвергенции
Инженеры и исследователи могут потратить значительное количество времени на экспериментирование с конфигурациями обучения, прежде чем они достигнут приемлемой скорости, при которой выходные данные модели станут стабильными и точными, известной как скорость сходимости. Конвергенции в GAN может быть очень трудно достичь, и она может длиться недолго. Ошибка сходимости — это когда дискриминатору не удается в достаточной степени сделать выбор между реальными и поддельными данными, что приводит к точности примерно 50%, поскольку он не получил возможности идентифицировать реальные данные, в отличие от предполагаемого баланса, достигнутого во время успешного обучения. Некоторые GAN могут никогда не достичь сходимости, и для их восстановления может потребоваться специализированный анализ.
Свернуть режим
GAN подвержены проблеме, называемой коллапсом режима, когда генератор создает ограниченный диапазон выходных данных и не может отразить разнообразие реальных распределений данных. Эта проблема возникает из-за архитектуры GAN, поскольку генератор чрезмерно фокусируется на создании данных, которые могут обмануть дискриминатор, заставляя его генерировать аналогичные примеры.