
Основы рекуррентной нейронной сети: что вам нужно знать
Опубликовано: 2024-09-19Рекуррентные нейронные сети (RNN) являются важными методами в области анализа данных, машинного обучения (ML) и глубокого обучения. Цель этой статьи — изучить RNN и подробно описать их функциональность, применение, преимущества и недостатки в более широком контексте глубокого обучения.
Оглавление
Что такое РНН?
Как работают RNN
Типы РНС
RNN против преобразователей и CNN
Приложения RNN
Преимущества
Недостатки
Что такое рекуррентная нейронная сеть?
Рекуррентная нейронная сеть — это глубокая нейронная сеть, которая может обрабатывать последовательные данные, сохраняя внутреннюю память, что позволяет ей отслеживать прошлые входные данные для генерации выходных данных. RNN являются фундаментальным компонентом глубокого обучения и особенно подходят для задач, включающих последовательные данные.
«Рекуррентный» в «рекуррентной нейронной сети» относится к тому, как модель объединяет информацию из прошлых входных данных с текущими входными данными. Информация со старых входов хранится в своего рода внутренней памяти, называемой «скрытым состоянием». Оно повторяется — возвращает предыдущие вычисления обратно в себя, создавая непрерывный поток информации.
Давайте продемонстрируем это на примере: предположим, что мы хотим использовать RNN для определения настроения (положительного или отрицательного) предложения «Он счастливо съел пирог». RNN обработает словоhe, обновит его скрытое состояние, чтобы включить это слово, а затем перейдет кate, объединит его с тем, что он узнал отhe, и так далее с каждым словом, пока предложение не будет готово. Для сравнения: человек, читающий это предложение, будет обновлять свое понимание с каждым словом. Прочитав и поняв предложение целиком, человек может сказать, что предложение является положительным или отрицательным. Этот человеческий процесс понимания и есть то, к чему пытается приблизиться скрытое состояние.
RNN являются одной из фундаментальных моделей глубокого обучения. Они очень хорошо справились с задачами обработки естественного языка (НЛП), хотя трансформеры их вытеснили. Трансформаторы — это усовершенствованные архитектуры нейронных сетей, которые улучшают производительность RNN, например, за счет параллельной обработки данных и возможности обнаруживать связи между словами, которые находятся далеко друг от друга в исходном тексте (с использованием механизмов внимания). Однако RNN по-прежнему полезны для данных временных рядов и в ситуациях, когда достаточно более простых моделей.
Как работают RNN
Чтобы подробно описать, как работают RNN, давайте вернемся к предыдущему примеру задачи: классифицировать тональность предложения «Он с радостью съел пирог».
Мы начнем с обученной RNN, которая принимает текстовые входные данные и возвращает двоичный выходной сигнал (1 представляет положительный результат, а 0 представляет отрицательный результат). До того, как входные данные передаются в модель, скрытое состояние является общим — оно было изучено в процессе обучения, но еще не характерно для входных данных.
Первое словоHeпередается в модель. Внутри RNN его скрытое состояние затем обновляется (до скрытого состояния h1), чтобы включить словоHe. Затем словоateпередается в RNN, и h1 обновляется (до h2), чтобы включить это новое слово. Этот процесс повторяется до тех пор, пока не будет передано последнее слово. Скрытое состояние (h4) обновляется и включает последнее слово. Затем обновленное скрытое состояние используется для генерации либо 0, либо 1.
Вот визуальное представление того, как работает процесс RNN:
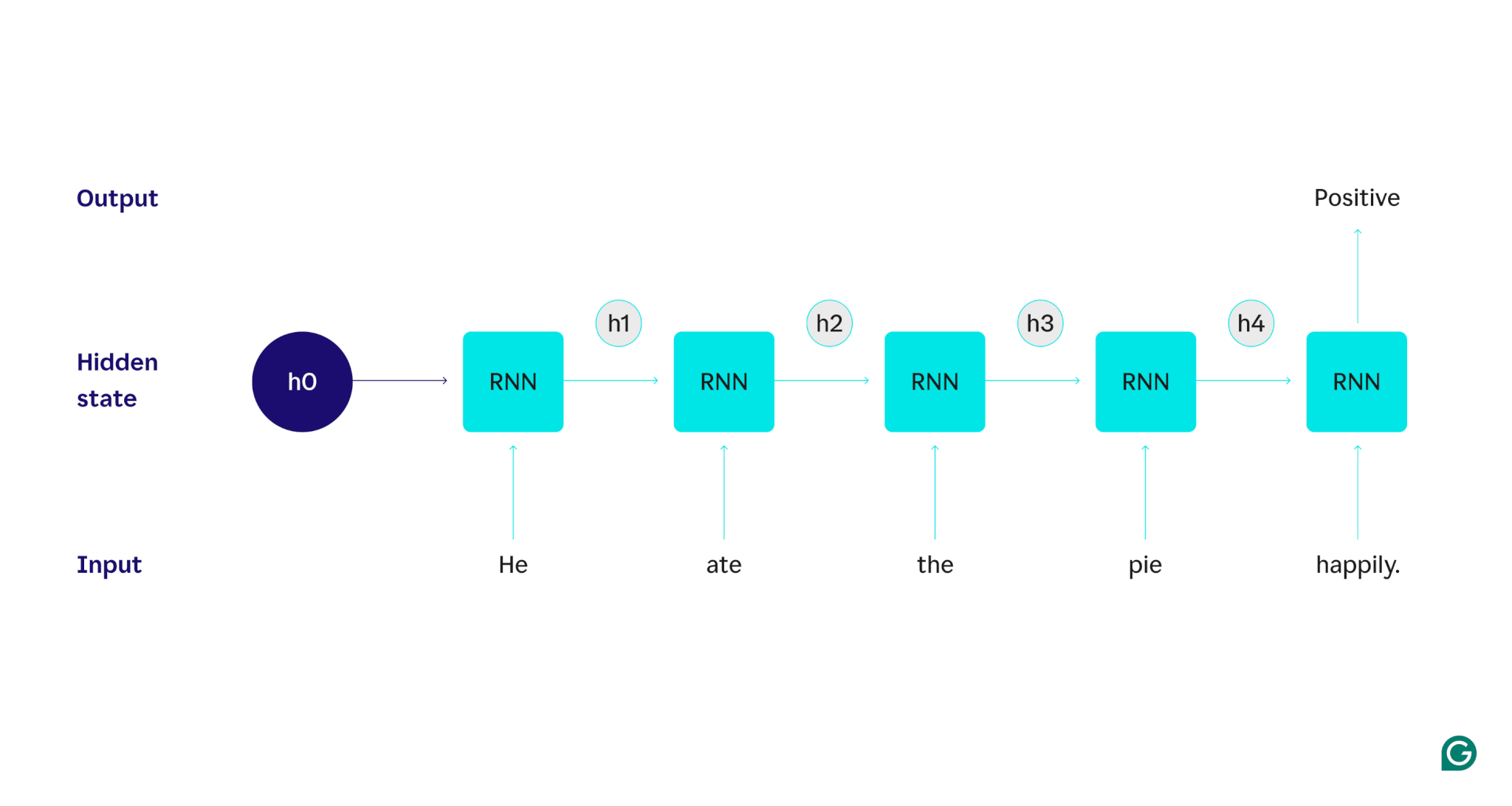
Это повторение является основой RNN, но есть еще несколько соображений:
- Встраивание текста:RNN не может обрабатывать текст напрямую, поскольку работает только с числовыми представлениями. Текст должен быть преобразован во вложения, прежде чем он сможет быть обработан RNN.
- Генерация выходных данных:выходные данные будут генерироваться RNN на каждом этапе. Однако выходные данные могут быть не очень точными, пока не будет обработана большая часть исходных данных. Например, после обработки только части предложения «Он ел» RNN может быть не уверен в том, представляет ли она положительное или отрицательное настроение — фраза «Он ел» может показаться нейтральной. Только после обработки полного предложения выходные данные RNN будут точными.
- Обучение RNN:RNN необходимо обучить точному анализу настроений. Обучение включает в себя использование множества помеченных примеров (например, «Он в гневе съел пирог», помеченных как отрицательные), их пропускание через RNN и корректировку модели в зависимости от того, насколько далеки ее прогнозы. Этот процесс устанавливает значение по умолчанию и механизм изменения скрытого состояния, позволяя RNN узнать, какие слова важны для отслеживания на протяжении всего ввода.
Типы рекуррентных нейронных сетей
Существует несколько различных типов RNN, каждый из которых различается по своей структуре и применению. Базовые RNN различаются в основном размером входных и выходных данных. Усовершенствованные RNN, такие как сети с длинной краткосрочной памятью (LSTM), устраняют некоторые ограничения базовых RNN.
Базовые RNN
RNN «один-к-одному»:этот RNN принимает входные данные длины один и возвращает выходные данные длины один. Таким образом, повторений на самом деле не происходит, что делает ее стандартной нейронной сетью, а не RNN. Примером RNN «один к одному» может быть классификатор изображений, где входными данными является одно изображение, а выходными данными — метка (например, «птица»).
RNN «один-ко-многим»:этот RNN принимает входные данные длиной один и возвращает составной выходной сигнал. Например, в задаче создания подписей к изображениям входными данными является одно изображение, а выходными — последовательность слов, описывающих изображение (например, «Птица перелетает реку в солнечный день»).
RNN «многие к одному»:этот RNN принимает входные данные, состоящие из нескольких частей (например, предложение, серию изображений или данные временного ряда), и возвращает выходные данные длиной один. Например, классификатор тональности предложения (подобный тому, который мы обсуждали), где входными данными является предложение, а выходными данными — одна метка тональности (положительная или отрицательная).
RNN «многие ко многим»:этот RNN принимает составные входные данные и возвращает составные выходные данные. Примером является модель распознавания речи, где входные данные представляют собой серию звуковых сигналов, а выходные данные — последовательность слов, представляющих произнесенный контент.
Расширенный RNN: длинная кратковременная память (LSTM)
Сети с длинной краткосрочной памятью предназначены для решения важной проблемы стандартных RNN: они забывают информацию при длительных входных данных. В стандартных RNN скрытое состояние сильно зависит от последних частей ввода. При вводе длиной в тысячи слов RNN забудет важные детали из первых предложений. LSTM имеют специальную архитектуру, позволяющую обойти эту проблему забывания. У них есть модули, которые выбирают, какую информацию следует запомнить, а какую забыть. Таким образом, недавняя, но бесполезная информация будет забыта, а старая, но актуальная информация сохранится. В результате LSTM гораздо более распространены, чем стандартные RNN — они просто лучше справляются со сложными или длительными задачами. Однако они не идеальны, поскольку все равно предпочитают забывать предметы.
RNN против преобразователей и CNN
Двумя другими распространенными моделями глубокого обучения являются сверточные нейронные сети (CNN) и преобразователи. Чем они отличаются?

RNN против трансформаторов
И RNN, и преобразователи широко используются в НЛП. Однако они существенно различаются по своей архитектуре и подходам к обработке входных данных.
Архитектура и обработка
- RNN:RNN обрабатывают вводимые данные последовательно, по одному слову за раз, сохраняя скрытое состояние, в котором содержится информация из предыдущих слов. Эта последовательная природа означает, что RNN могут бороться с долгосрочными зависимостями из-за этого забывания, при котором более ранняя информация может быть потеряна по мере развития последовательности.
- Трансформаторы:Трансформаторы используют механизм, называемый «внимание», для обработки входных данных. В отличие от RNN, преобразователи просматривают всю последовательность одновременно, сравнивая каждое слово с каждым другим словом. Этот подход устраняет проблему забывания, поскольку каждое слово имеет прямой доступ ко всему входному контексту. Благодаря этой возможности преобразователи показали превосходную производительность в таких задачах, как генерация текста и анализ настроений.
Распараллеливание
- RNN.Последовательный характер RNN означает, что модель должна завершить обработку одной части входных данных, прежде чем перейти к следующей. Это очень трудоемко, так как каждый шаг зависит от предыдущего.
- Трансформаторы:Трансформаторы обрабатывают все части ввода одновременно, поскольку их архитектура не опирается на последовательное скрытое состояние. Это делает их гораздо более распараллеливаемыми и эффективными. Например, если обработка предложения занимает 5 секунд на одно слово, RNN потребуется 25 секунд для предложения из 5 слов, тогда как преобразователю потребуется всего 5 секунд.
Практические последствия
Благодаря этим преимуществам трансформаторы получили более широкое применение в промышленности. Однако RNN, особенно сети с длинной краткосрочной памятью (LSTM), по-прежнему могут быть эффективны для более простых задач или при работе с более короткими последовательностями. LSTM часто используются в качестве критически важных модулей хранения памяти в больших архитектурах машинного обучения.
RNN против CNN
CNN фундаментально отличаются от RNN с точки зрения данных, которые они обрабатывают, и механизмов их работы.
Тип данных
- RNN:RNN предназначены для последовательных данных, таких как текст или временные ряды, где важен порядок точек данных.
- CNN:CNN используются в основном для пространственных данных, таких как изображения, где основное внимание уделяется взаимосвязям между соседними точками данных (например, цвет, интенсивность и другие свойства пикселя в изображении тесно связаны со свойствами других близлежащих точек данных). пикселей).
Операция
- RNN:RNN сохраняют память обо всей последовательности, что делает их пригодными для задач, где важны контекст и последовательность.
- CNN:CNN работают, просматривая локальные области ввода (например, соседние пиксели) через сверточные слои. Это делает их очень эффективными для обработки изображений, но менее эффективными для последовательных данных, где долгосрочные зависимости могут быть более важными.
Входная длина
- RNN:RNN могут обрабатывать входные последовательности переменной длины с менее определенной структурой, что делает их гибкими для различных последовательных типов данных.
- CNN:CNN обычно требуют входных данных фиксированного размера, что может быть ограничением для обработки последовательностей переменной длины.
Приложения RNN
RNN широко используются в различных областях благодаря их способности эффективно обрабатывать последовательные данные.
Обработка естественного языка
Язык — это очень последовательная форма данных, поэтому RNN хорошо справляются с языковыми задачами. RNN превосходно справляются с такими задачами, как генерация текста, анализ настроений, перевод и обобщение. С помощью таких библиотек, как PyTorch, кто-то может создать простого чат-бота, используя RNN и несколько гигабайт текстовых примеров.
Распознавание речи
Распознавание речи по своей сути является языком, поэтому оно также очень последовательно. Для этой задачи можно использовать RNN «многие ко многим». На каждом этапе RNN принимает предыдущее скрытое состояние и форму сигнала, выводя слово, связанное с формой сигнала (в зависимости от контекста предложения до этого момента).
Генерация музыки
Музыка также очень последовательна. Предыдущие доли песни сильно влияют на будущие доли. RNN «многие-ко-многим» может принимать несколько начальных тактов в качестве входных данных, а затем генерировать дополнительные такты по желанию пользователя. Альтернативно, он может принять текстовый ввод, например «мелодичный джаз», и вывести наилучшее приближение мелодичных джазовых битов.
Преимущества RNN
Хотя RNN больше не являются фактической моделью НЛП, они все еще имеют некоторое применение из-за нескольких факторов.
Хорошая последовательная производительность
RNN, особенно LSTM, хорошо работают с последовательными данными. LSTM с их специализированной архитектурой памяти могут управлять длинными и сложными последовательными входными данными. Например, до эры трансформаторов Google Translate работал на модели LSTM. LSTM можно использовать для добавления стратегических модулей памяти, когда сети на основе трансформаторов объединяются для формирования более совершенных архитектур.
Меньшие и простые модели.
RNN обычно имеют меньше параметров модели, чем преобразователи. Уровни внимания и прямой связи в трансформаторах требуют большего количества параметров для эффективного функционирования. RNN можно обучать с помощью меньшего количества прогонов и примеров данных, что делает их более эффективными для более простых случаев использования. В результате появляются меньшие по размеру, менее дорогие и более эффективные модели, которые при этом остаются достаточно производительными.
Недостатки RNN
RNN вышли из моды по определенной причине: трансформаторы, несмотря на их больший размер и процесс обучения, не имеют тех же недостатков, что и RNN.
Ограниченная память
Скрытое состояние в стандартных RNN сильно искажает недавние входные данные, что затрудняет сохранение долгосрочных зависимостей. Задачи с длинными входными данными не так хорошо выполняются с помощью RNN. Хотя LSTM направлены на решение этой проблемы, они лишь смягчают ее, а не решают полностью. Многие задачи ИИ требуют обработки длинных входных данных, что делает ограниченность памяти существенным недостатком.
Не распараллеливается
Каждый запуск модели RNN зависит от результатов предыдущего запуска, в частности, от обновленного скрытого состояния. В результате вся модель должна обрабатываться последовательно для каждой части входных данных. Напротив, трансформаторы и CNN могут обрабатывать весь входной сигнал одновременно. Это позволяет выполнять параллельную обработку на нескольких графических процессорах, что значительно ускоряет вычисления. Отсутствие распараллеливаемости RNN приводит к более медленному обучению, более медленному генерированию выходных данных и меньшему максимальному объему данных, из которых можно извлечь данные.
Проблемы с градиентом
Обучение RNN может быть сложной задачей, поскольку процесс обратного распространения ошибки должен проходить через каждый входной шаг (обратное распространение ошибки во времени). Из-за множества временных шагов градиенты, указывающие, как следует корректировать каждый параметр модели, могут ухудшиться и стать неэффективными. Градиенты могут выйти из строя из-за исчезновения, что означает, что они становятся очень маленькими, и модель больше не может использовать их для обучения, или из-за взрыва, когда градиенты становятся очень большими, и модель выходит за пределы своих обновлений, что делает модель непригодной для использования. Сбалансировать эти вопросы сложно.