
Что такое автоэнкодер? Руководство для начинающих
Опубликовано: 2024-10-28Автоэнкодеры являются важным компонентом глубокого обучения, особенно в задачах машинного обучения без учителя. В этой статье мы рассмотрим, как работают автоэнкодеры, их архитектуру и различные доступные типы. Вы также узнаете об их реальных приложениях, а также о преимуществах и компромиссах, связанных с их использованием.
Оглавление
- Что такое автоэнкодер?
- Архитектура автоэнкодера
- Типы автоэнкодеров
- Приложение
- Преимущества
- Недостатки
Что такое автоэнкодер?
Автоэнкодеры — это тип нейронной сети, используемый в глубоком обучении для изучения эффективных низкоразмерных представлений входных данных, которые затем используются для восстановления исходных данных. Таким образом, эта сеть изучает наиболее важные характеристики данных во время обучения, не требуя явных меток, что делает его частью самостоятельного обучения. Автокодировщики широко применяются в таких задачах, как шумоподавление изображений, обнаружение аномалий и сжатие данных, где ценна их способность сжимать и восстанавливать данные.
Архитектура автоэнкодера
Автокодировщик состоит из трех частей: кодировщика, узкого места (также известного как скрытое пространство или код) и декодера. Эти компоненты работают вместе, чтобы фиксировать ключевые особенности входных данных и использовать их для создания точных реконструкций.
Автоэнкодеры оптимизируют свои выходные данные, регулируя веса как кодера, так и декодера, стремясь создать сжатое представление входных данных, сохраняющее важные функции. Эта оптимизация минимизирует ошибку реконструкции, которая представляет собой разницу между входными и выходными данными.
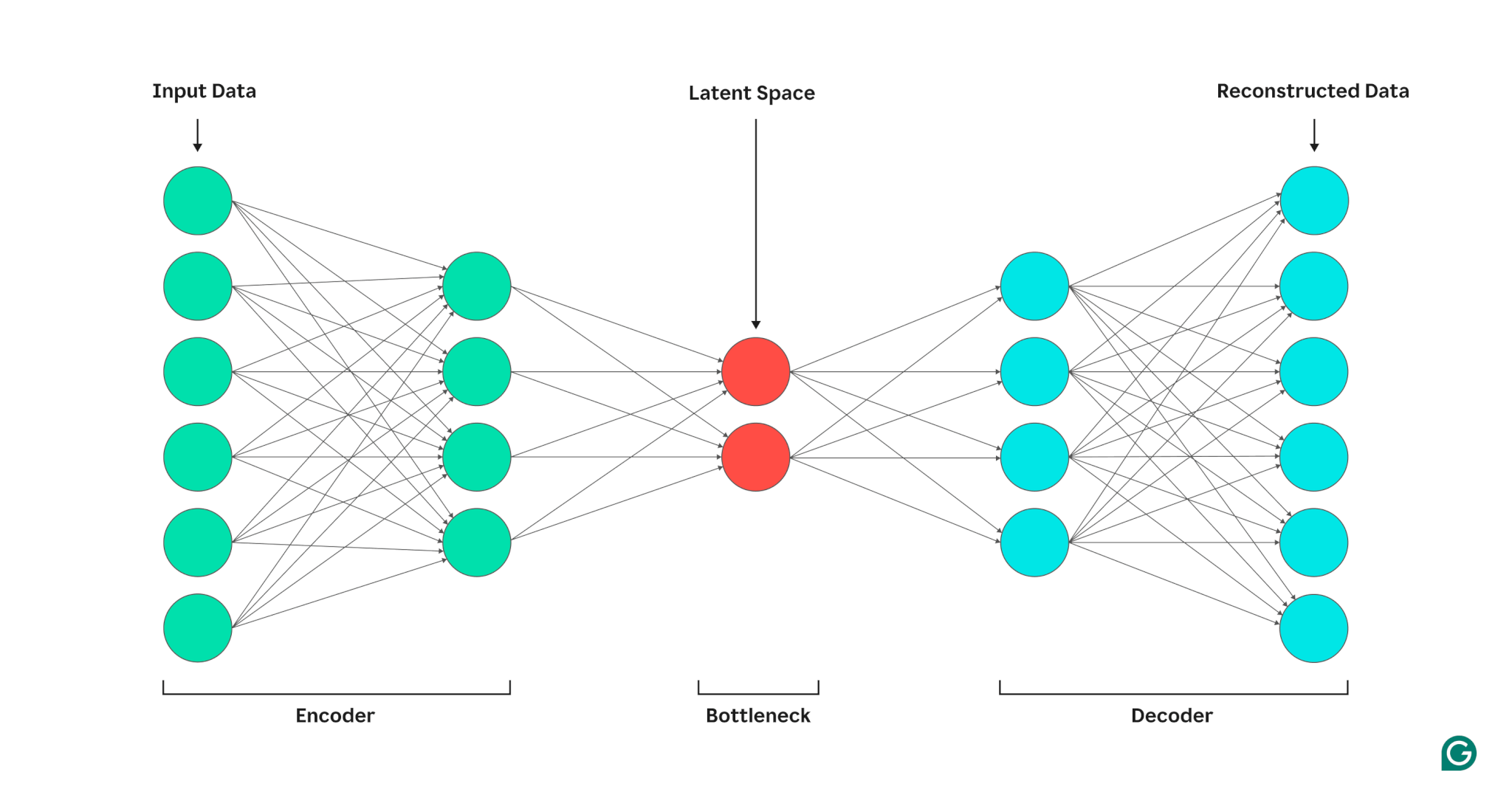
Кодер
Во-первых, кодер сжимает входные данные в более эффективное представление. Кодеры обычно состоят из нескольких уровней с меньшим количеством узлов на каждом уровне. Поскольку данные обрабатываются на каждом уровне, уменьшенное количество узлов заставляет сеть изучать наиболее важные особенности данных для создания представления, которое может храниться на каждом уровне. Этот процесс, известный как уменьшение размерности, преобразует входные данные в компактную сводку ключевых характеристик данных. Ключевые гиперпараметры кодера включают количество слоев и нейронов на слой, которые определяют глубину и степень детализации сжатия, а также функцию активации, которая определяет, как функции данных представляются и преобразуются на каждом уровне.
Узкое место
Узкое место, также известное как скрытое пространство или код, — это место, где сжатое представление входных данных сохраняется во время обработки. Узкое место имеет небольшое количество узлов; это ограничивает объем данных, которые можно хранить, и определяет уровень сжатия. Количество узлов в узком месте — это настраиваемый гиперпараметр, позволяющий пользователям контролировать компромисс между сжатием и сохранением данных. Если узкое место слишком мало, автоэнкодер может неправильно реконструировать данные из-за потери важных деталей. С другой стороны, если узкое место слишком велико, автоэнкодер может просто скопировать входные данные вместо изучения значимого общего представления.
Декодер
На этом последнем этапе декодер воссоздает исходные данные из сжатой формы, используя ключевые функции, полученные в процессе кодирования. Качество этой декомпрессии количественно оценивается с помощью ошибки реконструкции, которая, по сути, является мерой того, насколько восстановленные данные отличаются от входных. Ошибка реконструкции обычно рассчитывается с использованием среднеквадратической ошибки (MSE). Поскольку MSE измеряет квадрат разницы между исходными и реконструированными данными, он обеспечивает математически простой способ более строго наказывать за более крупные ошибки реконструкции.
Типы автоэнкодеров
Существует несколько типов специализированных автоэнкодеров, каждый из которых оптимизирован для конкретных приложений, как и другие нейронные сети.
Автоэнкодеры с шумоподавлением
Автоэнкодеры с шумоподавлением предназначены для восстановления чистых данных из зашумленных или поврежденных входных данных. Во время обучения к входным данным намеренно добавляется шум, что позволяет модели изучать функции, которые остаются согласованными, несмотря на шум. Затем выходные данные сравниваются с исходными чистыми входными данными. Этот процесс делает автокодировщики с шумоподавлением очень эффективными в задачах снижения шума изображения и звука, включая удаление фонового шума в видеоконференциях.
Разреженные автоэнкодеры
Разреженные автокодировщики ограничивают количество активных нейронов в любой момент времени, побуждая сеть изучать более эффективные представления данных по сравнению со стандартными автокодировщиками. Это ограничение разреженности реализуется посредством штрафа, который препятствует активации большего количества нейронов, чем указанный порог. Разреженные автокодировщики упрощают многомерные данные, сохраняя при этом основные функции, что делает их ценными для таких задач, как извлечение интерпретируемых функций и визуализация сложных наборов данных.
Вариационные автоэнкодеры (VAE)
В отличие от типичных автоэнкодеров, VAE генерируют новые данные путем кодирования функций обучающих данных в распределение вероятностей, а не в фиксированную точку. Делая выборку из этого распределения, VAE могут генерировать разнообразные новые данные вместо того, чтобы восстанавливать исходные данные на основе входных данных. Эта возможность делает VAE полезными для генеративных задач, включая генерацию синтетических данных. Например, при генерации изображений VAE, обученный на наборе данных рукописных чисел, может создавать новые, реалистично выглядящие цифры на основе обучающего набора, которые не являются точными копиями.

Сжимающие автоэнкодеры
Сжимающие автоэнкодеры вводят дополнительный штрафной член во время расчета ошибки реконструкции, побуждая модель изучать представления объектов, устойчивые к шуму. Этот штраф помогает предотвратить переобучение, способствуя обучению признаков, которое инвариантно к небольшим изменениям входных данных. В результате сжимающие автоэнкодеры более устойчивы к шуму, чем стандартные автоэнкодеры.
Сверточные автоэнкодеры (CAE)
CAE используют сверточные слои для фиксации пространственных иерархий и закономерностей в многомерных данных. Использование сверточных слоев делает CAE особенно подходящими для обработки данных изображений. CAE обычно используются в таких задачах, как сжатие изображений и обнаружение аномалий в изображениях.
Применение автоэнкодеров в ИИ
Автоэнкодеры имеют несколько приложений, таких как уменьшение размерности, шумоподавление изображений и обнаружение аномалий.
Уменьшение размерности
Автоэнкодеры — эффективные инструменты для уменьшения размерности входных данных при сохранении ключевых функций. Этот процесс полезен для таких задач, как визуализация многомерных наборов данных и сжатие данных. Упрощая данные, уменьшение размерности также повышает эффективность вычислений, уменьшая как размер, так и сложность.
Обнаружение аномалий
Изучая ключевые особенности целевого набора данных, автоэнкодеры могут различать нормальные и аномальные данные при предоставлении новых входных данных. На отклонение от нормы указывает более высокий, чем нормальный уровень ошибок реконструкции. Таким образом, автокодировщики могут применяться в различных областях, таких как профилактическое обслуживание и безопасность компьютерных сетей.
шумоподавление
Автокодировщики с шумоподавлением могут очищать зашумленные данные, научившись восстанавливать их на основе зашумленных обучающих входных данных. Эта возможность делает автокодировщики с шумоподавлением полезными для таких задач, как оптимизация изображений, включая повышение качества размытых фотографий. Автоэнкодеры с шумоподавлением также полезны при обработке сигналов, где они могут очищать зашумленные сигналы для более эффективной обработки и анализа.
Преимущества автоэнкодеров
Автоэнкодеры имеют ряд ключевых преимуществ. К ним относятся способность учиться на неразмеченных данных, автоматически изучать функции без явных инструкций и извлекать нелинейные функции.
Способность учиться на немаркированных данных
Автоэнкодеры — это модель машинного обучения без учителя, что означает, что они могут изучать базовые функции данных на основе немаркированных данных. Эта возможность означает, что автокодировщики можно применять для задач, в которых помеченные данные могут быть недостаточными или недоступными.
Автоматическое изучение функций
Стандартные методы извлечения признаков, такие как анализ главных компонентов (PCA), часто непрактичны, когда речь идет об обработке сложных и/или больших наборов данных. Поскольку автоэнкодеры были разработаны с учетом таких задач, как уменьшение размерности, они могут автоматически изучать ключевые функции и закономерности в данных без ручного проектирования функций.
Нелинейное извлечение признаков
Автоэнкодеры могут обрабатывать нелинейные отношения во входных данных, позволяя модели улавливать ключевые функции из более сложных представлений данных. Эта способность означает, что автоэнкодеры имеют преимущество перед моделями, которые могут работать только с линейными данными, поскольку они могут обрабатывать более сложные наборы данных.
Ограничения автоэнкодеров
Как и другие модели машинного обучения, автоэнкодеры имеют свои недостатки. К ним относятся отсутствие интерпретируемости, необходимость в больших наборах обучающих данных для хорошей работы и ограниченные возможности обобщения.
Отсутствие интерпретируемости
Как и другие сложные модели машинного обучения, автоэнкодеры страдают от отсутствия интерпретируемости, а это означает, что трудно понять взаимосвязь между входными данными и выходными данными модели. В автокодировщиках отсутствие интерпретируемости происходит потому, что автокодировщики автоматически изучают функции, в отличие от традиционных моделей, где функции определяются явно. Это сгенерированное машиной представление объектов часто бывает очень абстрактным и, как правило, лишено функций, интерпретируемых человеком, что затрудняет понимание того, что означает каждый компонент представления.
Требуются большие наборы обучающих данных
Автоэнкодерам обычно требуются большие наборы обучающих данных для изучения обобщаемых представлений ключевых функций данных. Учитывая небольшие наборы обучающих данных, автоэнкодеры могут иметь тенденцию к переобучению, что приводит к плохому обобщению при представлении новых данных. С другой стороны, большие наборы данных предоставляют автокодировщику необходимое разнообразие для изучения функций данных, которые можно применять в широком диапазоне сценариев.
Ограниченное обобщение по новым данным
Автоэнкодеры, обученные на одном наборе данных, часто имеют ограниченные возможности обобщения, а это означает, что они не могут адаптироваться к новым наборам данных. Это ограничение возникает потому, что автокодировщики ориентированы на реконструкцию данных на основе характерных особенностей из данного набора данных. Таким образом, автоэнкодеры обычно исключают более мелкие детали из данных во время обучения и не могут обрабатывать данные, которые не соответствуют обобщенному представлению признаков.