
Что такое переобучение в машинном обучении?
Опубликовано: 2024-10-15Переоснащение — распространенная проблема, возникающая при обучении моделей машинного обучения (ML). Это может негативно повлиять на способность модели обобщать данные обучения, что приводит к неточным прогнозам в реальных сценариях. В этой статье мы рассмотрим, что такое переоснащение, как оно происходит, общие причины, стоящие за ним, а также эффективные способы его обнаружения и предотвращения.
Оглавление
- Что такое переоснащение?
- Как происходит переобучение
- Переоснащение против недостаточного оснащения
- Что вызывает переобучение?
- Как обнаружить переобучение
- Как избежать переобучения
- Примеры переобучения
Что такое переоснащение?
Переоснащение — это когда модель машинного обучения изучает основные закономерности и шум в обучающих данных, становясь чрезмерно специализированным на этом конкретном наборе данных. Такое чрезмерное внимание к деталям обучающих данных приводит к низкой производительности, когда модель применяется к новым, невидимым данным, поскольку она не может обобщать данные, выходящие за рамки данных, на которых она обучалась.
Как происходит переобучение?
Переобучение происходит, когда модель слишком многому учится на конкретных деталях и шуме в обучающих данных, что делает ее чрезмерно чувствительной к шаблонам, не имеющим смысла для обобщения. Например, рассмотрим модель, построенную для прогнозирования производительности сотрудников на основе исторических оценок. Если модель подходит, она может слишком сильно сосредоточиться на конкретных, не поддающихся обобщению деталях, таких как уникальный стиль оценки бывшего менеджера или конкретные обстоятельства во время прошлого цикла проверки. Вместо изучения более широких и значимых факторов, влияющих на производительность, таких как навыки, опыт или результаты проекта, модель может с трудом применить свои знания к новым сотрудникам или разработать критерии оценки. Это приводит к менее точным прогнозам, когда модель применяется к данным, которые отличаются от обучающего набора.
Переоснащение против недостаточного оснащения
В отличие от переоснащения, недостаточное оснащение происходит, когда модель слишком проста, чтобы уловить основные закономерности в данных. В результате он плохо работает как с обучением, так и с новыми данными и не может сделать точные прогнозы.
Чтобы представить разницу между недостаточной и переподготовкой, представьте, что мы пытаемся предсказать спортивные результаты на основе уровня стресса человека. Мы можем построить данные и показать три модели, которые пытаются предсказать эту взаимосвязь:

1 Недооснащение:в первом примере модель использует прямую линию для прогнозирования, в то время как фактические данные следуют кривой. Модель слишком проста и не может отразить всю сложность взаимосвязи между уровнем стресса и спортивными результатами. В результате прогнозы в большинстве случаев оказываются неточными, даже для обучающих данных. Это не соответствует требованиям.
2Оптимальное соответствие.Второй пример демонстрирует модель, которая обеспечивает правильный баланс. Он фиксирует основную тенденцию в данных, не усложняя их. Эта модель хорошо обобщается на новые данные, поскольку она не пытается учесть все небольшие изменения в обучающих данных, а только основной шаблон.
3Переобучение.В последнем примере модель использует очень сложную волнистую кривую, соответствующую обучающим данным. Хотя эта кривая очень точна для обучающих данных, она также фиксирует случайный шум и выбросы, которые не отражают фактическую взаимосвязь. Эта модель является переоснащенной, потому что она настолько точно настроена на обучающие данные, что, скорее всего, будет делать неверные прогнозы на основе новых, невидимых данных.
Распространенные причины переобучения
Теперь мы знаем, что такое переоснащение и почему оно происходит, давайте рассмотрим некоторые распространенные причины более подробно:
- Недостаточно данных для обучения
- Неточные, ошибочные или нерелевантные данные.
- Большие веса
- Перетренированность
- Архитектура модели слишком сложна
Недостаточно данных для обучения
Если ваш набор обучающих данных слишком мал, он может представлять только некоторые сценарии, с которыми модель столкнется в реальном мире. Во время обучения модель может хорошо соответствовать данным. Однако вы можете увидеть значительные неточности после проверки на других данных. Небольшой набор данных ограничивает способность модели обобщать невидимые ситуации, что делает ее склонной к переобучению.
Неточные, ошибочные или нерелевантные данные.
Даже если ваш набор обучающих данных большой, он может содержать ошибки. Эти ошибки могут возникать по разным причинам, например, из-за того, что участники предоставляют ложную информацию в опросах или ошибочные показания датчиков. Если модель попытается извлечь уроки из этих неточностей, она адаптируется к шаблонам, которые не отражают истинные основные взаимосвязи, что приведет к переобучению.
Большие веса
В моделях машинного обучения веса представляют собой числовые значения, которые отражают важность, присвоенную конкретным функциям данных при составлении прогнозов. Когда веса становятся непропорционально большими, модель может переобучиться, становясь чрезмерно чувствительной к определенным функциям, включая шум в данных. Это происходит потому, что модель становится слишком зависимой от конкретных функций, что ухудшает ее способность обобщать новые данные.
Перетренированность
Во время обучения алгоритм обрабатывает данные пакетами, вычисляет ошибку для каждого пакета и корректирует веса модели для повышения ее точности.
Стоит ли продолжать тренировки как можно дольше? Не совсем! Длительное обучение на одних и тех же данных может привести к тому, что модель запомнит определенные точки данных, ограничивая ее способность обобщать новые или невидимые данные, что и является сутью переобучения. Этот тип переобучения можно смягчить, используя методы ранней остановки или отслеживая производительность модели на проверочном наборе во время обучения. Мы обсудим, как это работает, позже в статье.

Архитектура модели слишком сложна
Архитектура модели машинного обучения относится к тому, как структурированы ее слои и нейроны и как они взаимодействуют при обработке информации.
Более сложные архитектуры могут фиксировать подробные закономерности в обучающих данных. Однако эта сложность увеличивает вероятность переобучения, поскольку модель также может научиться улавливать шум или несущественные детали, которые не способствуют точным прогнозам на новых данных. Упрощение архитектуры или использование методов регуляризации могут помочь снизить риск переобучения.
Как обнаружить переобучение
Обнаружить переобучение может быть непросто, потому что во время тренировки может показаться, что все идет хорошо, даже если переобучение происходит. Уровень потерь (или ошибок) — показатель того, насколько часто модель ошибается — будет продолжать снижаться, даже в сценарии переоснащения. Итак, как мы можем узнать, произошло ли переобучение? Нам нужен надежный тест.
Одним из эффективных методов является использование кривой обучения — диаграммы, которая отслеживает показатель, называемый потерями. Потери представляют собой величину ошибки, которую допускает модель. Однако мы не просто отслеживаем потери обучающих данных; мы также измеряем потери на невидимых данных, называемых данными проверки. Вот почему кривая обучения обычно имеет две линии: потери при обучении и потери при проверке.
Если потери при обучении продолжают уменьшаться, как и ожидалось, но потери при проверке увеличиваются, это говорит о переобучении. Другими словами, модель становится чрезмерно специализированной на обучающих данных и с трудом поддается обобщению на новые, невидимые данные. Кривая обучения может выглядеть примерно так:
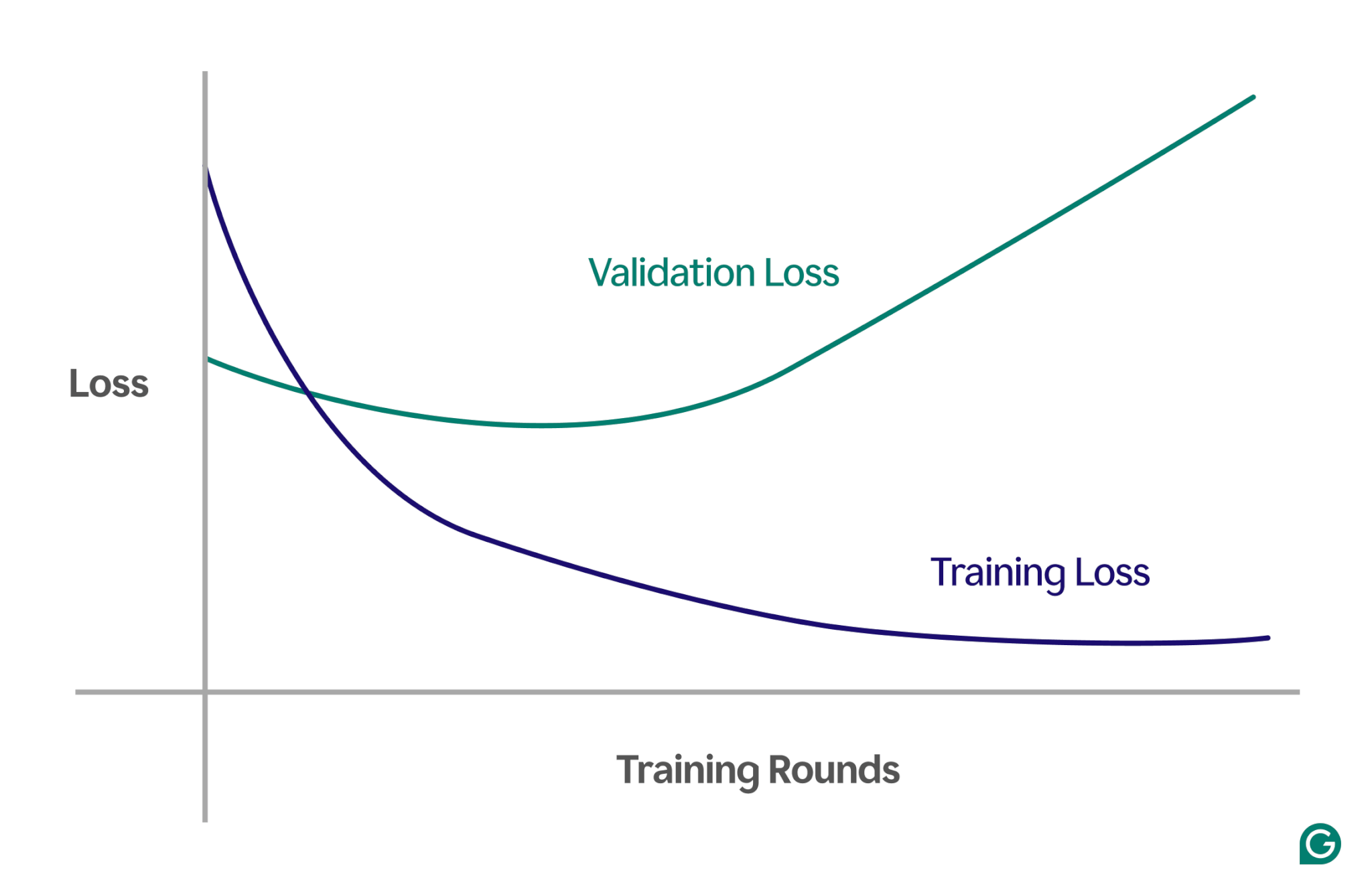
В этом сценарии, хотя модель и улучшается во время обучения, она плохо работает на невидимых данных. Вероятно, это означает, что произошло переобучение.
Как избежать переобучения
С переобучением можно справиться несколькими способами. Вот некоторые из наиболее распространенных методов:
Уменьшите размер модели
Большинство архитектур моделей позволяют регулировать количество весов, изменяя количество слоев, размеры слоев и другие параметры, известные как гиперпараметры. Если сложность модели вызывает переобучение, может помочь уменьшение ее размера. Упрощение модели за счет уменьшения количества слоев или нейронов может снизить риск переобучения, поскольку у модели будет меньше возможностей для запоминания обучающих данных.
Регуляризация модели
Регуляризация включает в себя изменение модели, чтобы исключить использование больших весов. Один из подходов — настроить функцию потерь так, чтобы она измеряла ошибку и включала размер весов.
Благодаря регуляризации алгоритм обучения минимизирует как ошибку, так и размер весов, уменьшая вероятность больших весов, если они не обеспечивают явного преимущества модели. Это помогает предотвратить переобучение, сохраняя модель более обобщенной.
Добавить дополнительные данные обучения
Увеличение размера набора обучающих данных также может помочь предотвратить переобучение. При наличии большего количества данных на модель с меньшей вероятностью будет влиять шум или неточности в наборе данных. Если модель будет представлена на более разнообразных примерах, она будет менее склонна запоминать отдельные точки данных и вместо этого изучать более широкие закономерности.
Применить уменьшение размерности
Иногда данные могут содержать коррелированные функции (или измерения), то есть несколько функций каким-то образом связаны. Модели машинного обучения рассматривают измерения как независимые, поэтому, если функции коррелируют, модель может слишком сильно сосредоточиться на них, что приведет к переобучению.
Статистические методы, такие как анализ главных компонент (PCA), могут уменьшить эти корреляции. PCA упрощает данные за счет уменьшения количества измерений и удаления корреляций, что снижает вероятность переобучения. Сосредоточив внимание на наиболее важных функциях, модель лучше обобщает новые данные.
Практические примеры переобучения
Чтобы лучше понять переобучение, давайте рассмотрим несколько практических примеров из разных областей, где переоснащение может привести к ошибочным результатам.
Классификация изображений
Классификаторы изображений предназначены для распознавания объектов на изображениях, например, есть ли на изображении птица или собака.
Другие детали могут соответствовать тому, что вы пытаетесь обнаружить на этих изображениях. Например, на фотографиях собак часто может быть трава на заднем плане, а на фотографиях птиц часто может быть небо или верхушки деревьев.
Если все обучающие изображения имеют одинаковые детали фона, модель машинного обучения может начать полагаться на фон для распознавания животного, а не сосредотачиваться на реальных особенностях самого животного. В результате, когда модель просят классифицировать изображение птицы, сидящей на лужайке, она может ошибочно классифицировать ее как собаку, поскольку она не соответствует фоновой информации. Это случай переподбора обучающих данных.
Финансовое моделирование
Допустим, вы торгуете акциями в свободное время и считаете, что можно предсказать движение цен на основе тенденций поиска в Google по определенным ключевым словам. Вы настраиваете модель машинного обучения, используя данные Google Trends для тысяч слов.
Поскольку слов так много, некоторые из них, скорее всего, случайно покажут корреляцию с ценами ваших акций. Модель может переоценивать эти случайные корреляции, делая неверные прогнозы относительно будущих данных, поскольку слова не являются релевантными предикторами цен на акции.
При построении моделей для финансовых приложений важно понимать теоретическую основу взаимосвязей в данных. Ввод больших наборов данных в модель без тщательного выбора признаков может увеличить риск переобучения, особенно когда модель выявляет ложные корреляции, которые существуют чисто случайно в обучающих данных.
Спортивные суеверия
Хотя спортивные суеверия не связаны строго с машинным обучением, они могут служить иллюстрацией концепции переобучения, особенно когда результаты привязаны к данным, которые логически не связаны с результатом.
Во время чемпионата Европы по футболу 2008 года и чемпионата мира по футболу 2010 года осьминог по имени Пауль, как известно, использовался для прогнозирования исходов матчей с участием Германии. Пол оправдал четыре из шести предсказаний в 2008 году и все семь в 2010 году.
Если вы примете во внимание только «обучающие данные» прошлых предсказаний Пола, то модель, которая согласуется с выбором Пола, будет, по-видимому, очень хорошо предсказывать результаты. Однако эту модель невозможно обобщить на будущие игры, поскольку выбор осьминога не является надежным предиктором исхода матча.