
Что такое недостаточное оснащение в машинном обучении?
Опубликовано: 2024-10-16Недостаточное оснащение — распространенная проблема, возникающая при разработке моделей машинного обучения (ML). Это происходит, когда модель не может эффективно учиться на обучающих данных, что приводит к снижению производительности. В этой статье мы рассмотрим, что такое недостаточное оснащение, как оно происходит и как его избежать.
Оглавление
- Что такое недооснащение?
- Как происходит недостаточное оснащение
- Недооснащение против переоснащения
- Распространенные причины недостаточной оснащенности
- Как обнаружить неадекватность
- Методы предотвращения недостаточной подгонки
- Практические примеры недостаточной подгонки
Что такое недооснащение?
Недостаточная подгонка — это когда модель машинного обучения не может уловить основные закономерности в обучающих данных, что приводит к низкой производительности как обучающих, так и тестовых данных. Когда это происходит, это означает, что модель слишком проста и не справляется с задачей представления наиболее важных взаимосвязей данных. В результате модель с трудом делает точные прогнозы по всем данным, как данным, наблюдаемым во время обучения, так и любым новым, невидимым данным.
Как происходит недооснащение?
Недостаточное оснащение происходит, когда алгоритм машинного обучения создает модель, которая не может отразить наиболее важные свойства обучающих данных; модели, которые терпят неудачу таким образом, считаются слишком простыми. Например, представьте, что вы используете линейную регрессию для прогнозирования продаж на основе маркетинговых расходов, демографических данных клиентов и сезонности. Линейная регрессия предполагает, что взаимосвязь между этими факторами и продажами может быть представлена в виде комбинации прямых линий.
Хотя реальная связь между маркетинговыми расходами и продажами может быть изогнутой или включать в себя множество взаимодействий (например, сначала быстрый рост продаж, а затем стабилизация), линейная модель будет слишком упрощена, если будет рисовать прямую линию. Такое упрощение упускает из виду важные нюансы, что приводит к плохим прогнозам и общей производительности.
Эта проблема распространена во многих моделях машинного обучения, где высокая предвзятость (жесткие предположения) не позволяет модели изучить важные шаблоны, что приводит к ее плохой работе как на обучающих, так и на тестовых данных. Недостаточное соответствие обычно наблюдается, когда модель слишком проста, чтобы отразить истинную сложность данных.
Недооснащение против переоснащения
В машинном обучении недостаточное и переоснащение являются распространенными проблемами, которые могут негативно повлиять на способность модели делать точные прогнозы. Понимание разницы между ними имеет решающее значение для построения моделей, которые хорошо обобщаются на новые данные.
- Недостаточное соответствиепроисходит, когда модель слишком проста и не может отразить ключевые закономерности в данных. Это приводит к неточным прогнозам как для обучающих данных, так и для новых данных.
- Переобучениепроисходит, когда модель становится слишком сложной, подгоняя не только истинные закономерности, но и шум в обучающих данных. Это приводит к тому, что модель хорошо работает на обучающем наборе, но плохо на новых, невидимых данных.
Чтобы лучше проиллюстрировать эти концепции, рассмотрим модель, которая прогнозирует спортивные результаты на основе уровня стресса. Синие точки на диаграмме представляют точки данных из обучающего набора, а линии показывают прогнозы модели после обучения на этих данных. 
1 Недооснащение:в этом случае модель использует простую прямую линию для прогнозирования производительности, хотя фактическая зависимость кривая. Поскольку линия плохо соответствует данным, модель слишком проста и не может уловить важные закономерности, что приводит к плохим прогнозам. Это несоответствие, когда модель не может изучить наиболее полезные свойства данных.
2 Оптимальное соответствие:здесь модель достаточно точно соответствует кривой данных. Он фиксирует основную тенденцию, не будучи чрезмерно чувствительным к конкретным точкам данных или шуму. Это желаемый сценарий, при котором модель достаточно хорошо обобщает и может делать точные прогнозы на основе аналогичных новых данных. Тем не менее, обобщение по-прежнему может быть сложной задачей, когда мы сталкиваемся с совершенно разными или более сложными наборами данных.
3 Переобучение.В сценарии переобучения модель внимательно отслеживает почти каждую точку данных, включая шум и случайные колебания в обучающих данных. Хотя модель очень хорошо работает на обучающем наборе, она слишком специфична для обучающих данных и поэтому будет менее эффективна при прогнозировании новых данных. Он с трудом поддается обобщениям и, скорее всего, будет давать неточные прогнозы применительно к невидимым сценариям.
Распространенные причины недостаточной оснащенности
Существует множество потенциальных причин недостаточной подгонки. Четырьмя наиболее распространенными являются:
- Архитектура модели слишком проста.
- Плохой выбор функций
- Недостаточно данных для обучения
- Недостаточно обучения
Давайте углубимся в них немного дальше, чтобы понять их.
Архитектура модели слишком проста
Архитектура модели — это комбинация алгоритма, используемого для обучения модели, и ее структуры. Если архитектура слишком проста, могут возникнуть проблемы с захватом высокоуровневых свойств обучающих данных, что приведет к неточным прогнозам.
Например, если модель пытается использовать одну прямую линию для моделирования данных, которые следуют изогнутому шаблону, она будет постоянно не соответствовать требованиям. Это связано с тем, что прямая линия не может точно отразить взаимосвязь высокого уровня в изогнутых данных, что делает архитектуру модели неадекватной для этой задачи.
Плохой выбор функций
Выбор функций включает в себя выбор правильных переменных для модели ML во время обучения. Например, вы можете попросить алгоритм ML учитывать год рождения человека, цвет глаз, возраст или все три фактора при прогнозировании того, нажмет ли человек кнопку покупки на веб-сайте электронной коммерции.
Если признаков слишком много или выбранные признаки не сильно коррелируют с целевой переменной, модель не будет иметь достаточной информации для точных прогнозов. Цвет глаз может не иметь значения для конверсии, а возраст содержит большую часть той же информации, что и год рождения.
Недостаточно данных для обучения
Когда точек данных слишком мало, модель может оказаться недостаточно подходящей, поскольку данные не отражают наиболее важные свойства проблемы. Это может произойти либо из-за нехватки данных, либо из-за систематической ошибки выборки, когда определенные источники данных исключены или недостаточно представлены, что не позволяет модели изучить важные закономерности.

Недостаточно обучения
Обучение модели МО включает в себя корректировку ее внутренних параметров (весов) на основе разницы между ее прогнозами и фактическими результатами. Чем больше итераций обучения проходит модель, тем лучше она может адаптироваться к данным. Если модель обучена с использованием слишком малого количества итераций, у нее может не хватить возможностей для обучения на данных, что приведет к недостаточному подбору.
Как обнаружить неадекватность
Один из способов обнаружить недостаточную подгонку — анализ кривых обучения, которые отображают производительность модели (обычно потери или ошибки) в зависимости от количества итераций обучения. Кривая обучения показывает, как модель улучшается (или не улучшается) с течением времени как в наборах данных обучения, так и в наборах проверочных данных.
Потери — это величина ошибки модели для данного набора данных. Потери при обучении измеряют это для данных обучения и потери при проверке для данных проверки. Данные проверки — это отдельный набор данных, используемый для проверки производительности модели. Обычно он создается путем случайного разделения большого набора данных на данные обучения и проверки.
В случае недостаточной подгонки вы заметите следующие ключевые закономерности:
- Высокие потери при обучении.Если потери при обучении модели остаются высокими и стабилизируются на ранних этапах процесса, это означает, что модель не учится на обучающих данных. Это явный признак недостаточной подгонки, поскольку модель слишком проста, чтобы адаптироваться к сложности данных.
- Аналогичные потери при обучении и проверке.Если потери при обучении и проверке высоки и остаются близкими друг к другу на протяжении всего процесса обучения, это означает, что модель неэффективна на обоих наборах данных. Это указывает на то, что модель не собирает достаточно информации из данных, чтобы делать точные прогнозы, что указывает на недостаточное соответствие.
Ниже приведен пример диаграммы, показывающей кривые обучения в сценарии недостаточной оснащенности:
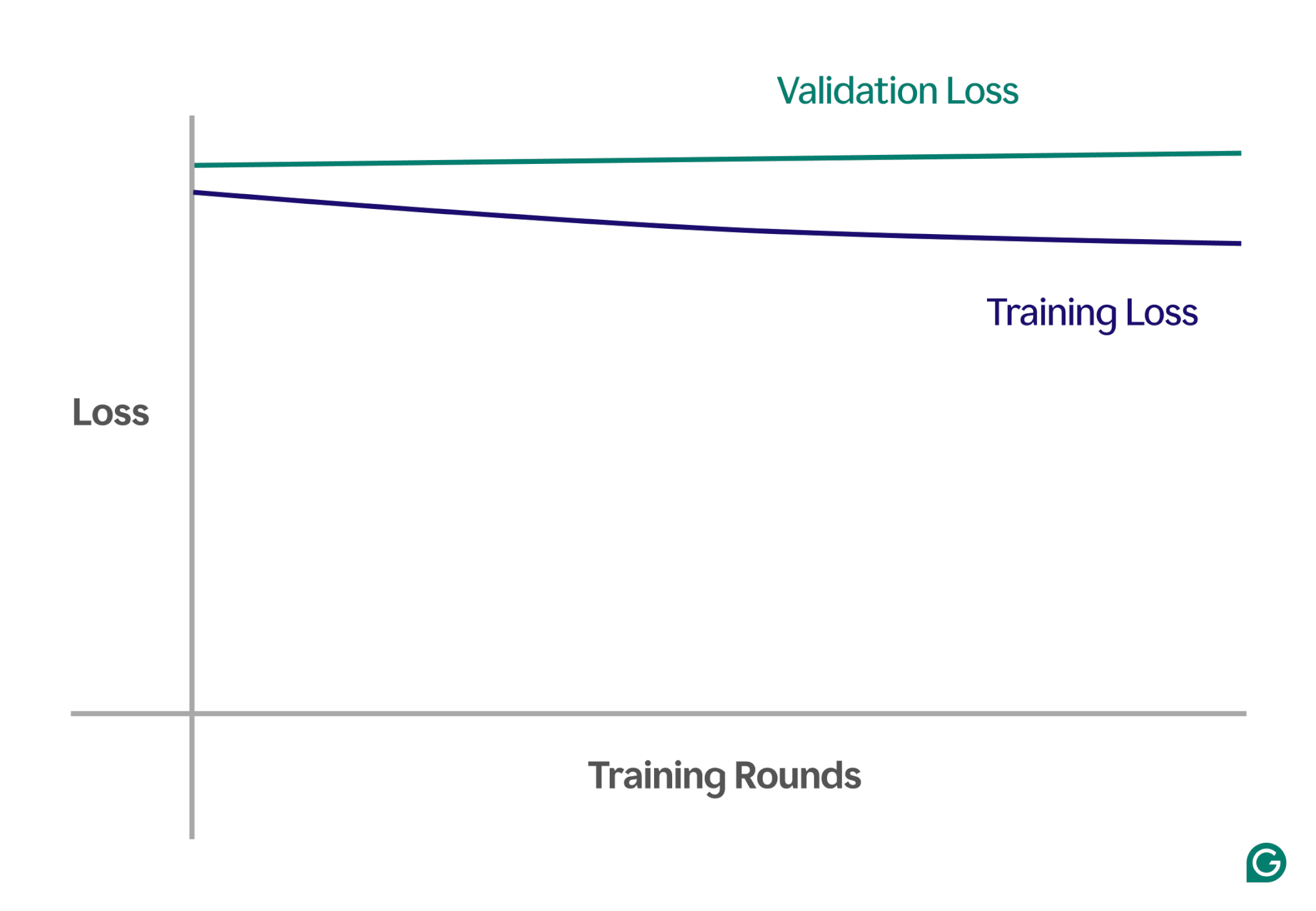
В этом визуальном представлении легко заметить несоответствие:
- В хорошо подобранной модели потери при обучении значительно уменьшаются, в то время как потери при проверке следуют аналогичной схеме и в конечном итоге стабилизируются.
- В модели с недостаточным оснащением потери при обучении и проверке начинаются с высоких значений и остаются высокими без какого-либо значительного улучшения.
Наблюдая за этими тенденциями, вы сможете быстро определить, не является ли модель слишком упрощенной и нуждается ли она в корректировках для увеличения ее сложности.
Методы предотвращения недостаточной подгонки
Если вы столкнулись с недостаточной подгонкой, есть несколько стратегий, которые можно использовать для улучшения производительности модели:
- Дополнительные данные обучения.Если возможно, получите дополнительные данные обучения. Больше данных дает модели дополнительные возможности для изучения закономерностей при условии, что данные высокого качества и соответствуют рассматриваемой проблеме.
- Расширьте выбор функций:добавьте к модели функции, которые более актуальны. Выбирайте функции, которые имеют тесную связь с целевой переменной, что дает модели больше шансов уловить важные закономерности, которые ранее были упущены.
- Увеличение мощности архитектуры.В моделях на основе нейронных сетей вы можете корректировать архитектурную структуру, изменяя количество весов, слоев или других гиперпараметров. Это может сделать модель более гибкой и облегчить поиск закономерностей высокого уровня в данных.
- Выберите другую модель.Иногда даже после настройки гиперпараметров конкретная модель может не подходить для поставленной задачи. Тестирование алгоритмов нескольких моделей может помочь найти более подходящую модель и повысить производительность.
Практические примеры недостаточной подгонки
Чтобы проиллюстрировать последствия недостаточной подгонки, давайте рассмотрим реальные примеры из различных областей, где модели не могут отразить сложность данных, что приводит к неточным прогнозам.
Прогнозирование цен на жилье
Чтобы точно спрогнозировать цену дома, необходимо учитывать множество факторов, включая местоположение, размер, тип дома, состояние и количество спален.
Если вы используете слишком мало функций (например, только размер и тип дома), модель не будет иметь доступа к важной информации. Например, модель может предположить, что небольшая студия стоит недорого, не зная, что она расположена в Мейфэр, Лондон, районе с высокими ценами на недвижимость. Это приводит к плохим прогнозам.
Чтобы решить эту проблему, ученые, работающие с данными, должны обеспечить правильный выбор функций. Это предполагает включение всех важных функций, исключение ненужных и использование точных данных обучения.
Распознавание речи
Технология распознавания голоса становится все более распространенной в повседневной жизни. Например, ассистенты на смартфонах, линии помощи клиентам и вспомогательные технологии для людей с ограниченными возможностями используют распознавание речи. При обучении этих моделей используются данные речевых образцов и их правильные интерпретации.
Чтобы распознавать речь, модель преобразует звуковые волны, улавливаемые микрофоном, в данные. Если мы упростим это, предоставляя доминирующую частоту и громкость голоса только через определенные интервалы времени, мы уменьшим объем данных, которые должна обрабатывать модель.
Однако этот подход удаляет важную информацию, необходимую для полного понимания речи. Данные становятся слишком упрощенными, чтобы охватить всю сложность человеческой речи, например, изменения тона, высоты тона и акцента.
В результате модель не сможет распознать даже базовые словесные команды, не говоря уже о полных предложениях. Даже если модель достаточно сложна, отсутствие полных данных приводит к ее несоответствию.
Классификация изображений
Классификатор изображений предназначен для приема изображения в качестве входных данных и вывода слова для его описания. Допустим, вы создаете модель, чтобы определить, содержит ли изображение мяч или нет. Вы обучаете модель, используя помеченные изображения шаров и других объектов.
Если вы по ошибке используете простую двухслойную нейронную сеть вместо более подходящей модели, такой как сверточная нейронная сеть (CNN), модель будет неэффективной. Двухслойная сеть сглаживает изображение в один слой, теряя важную пространственную информацию. Кроме того, поскольку модель состоит всего из двух слоев, она не способна идентифицировать сложные функции.
Это приводит к недостаточной подгонке, поскольку модель не сможет делать точные прогнозы даже на основе обучающих данных. CNN решают эту проблему, сохраняя пространственную структуру изображений и используя сверточные слои с фильтрами, которые автоматически учатся обнаруживать важные особенности, такие как края и формы, на ранних слоях и более сложные объекты на более поздних слоях.