
ข้อมูลพื้นฐานเกี่ยวกับโครงข่ายประสาทเทียมแบบ Convolutional: สิ่งที่คุณต้องรู้
เผยแพร่แล้ว: 2024-09-10โครงข่ายประสาทเทียมแบบ Convolutional (CNN) เป็นเครื่องมือพื้นฐานในการวิเคราะห์ข้อมูลและการเรียนรู้ของเครื่อง (ML) คู่มือนี้จะอธิบายวิธีการทำงานของ CNN ความแตกต่างจากโครงข่ายประสาทเทียมอื่นๆ แอปพลิเคชัน และข้อดีและข้อเสียที่เกี่ยวข้องกับการใช้งาน
สารบัญ
- ซีเอ็นเอ็นคืออะไร?
- CNN ทำงานอย่างไร
- CNN กับ RNN และหม้อแปลงไฟฟ้า
- การใช้งานของ CNN
- ข้อดี
- ข้อเสีย
โครงข่ายประสาทเทียมแบบ Convolutional คืออะไร?
โครงข่ายประสาทเทียมแบบหมุน (CNN) เป็นโครงข่ายประสาทเทียมที่รวมอยู่ในการเรียนรู้เชิงลึก ซึ่งออกแบบมาเพื่อประมวลผลและวิเคราะห์ข้อมูลเชิงพื้นที่ ใช้เลเยอร์แบบหมุนวนพร้อมตัวกรองเพื่อตรวจจับและเรียนรู้คุณสมบัติที่สำคัญภายในอินพุตโดยอัตโนมัติ ทำให้มีประสิทธิภาพโดยเฉพาะสำหรับงานต่างๆ เช่น การจดจำรูปภาพและวิดีโอ
มาคลายคำจำกัดความนี้กันสักหน่อย ข้อมูลเชิงพื้นที่คือข้อมูลที่ส่วนต่างๆ สัมพันธ์กันผ่านตำแหน่ง รูปภาพเป็นตัวอย่างที่ดีที่สุดของสิ่งนี้
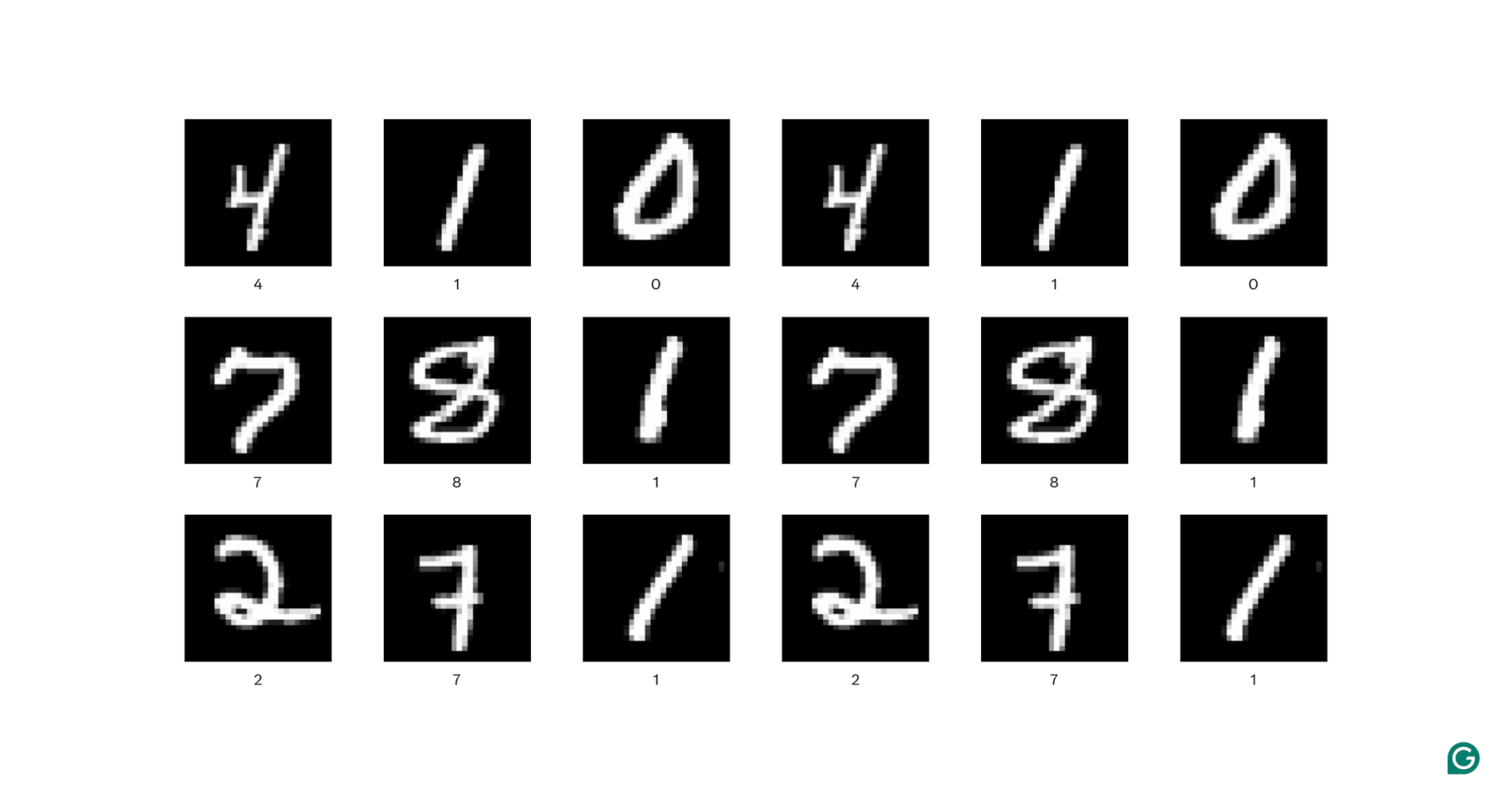
ในแต่ละภาพด้านบน พิกเซลสีขาวแต่ละพิกเซลเชื่อมต่อกับแต่ละพิกเซลสีขาวโดยรอบ: พวกมันจะรวมกันเป็นตัวเลข ตำแหน่งพิกเซลยังบอกผู้ชมว่าตัวเลขนั้นอยู่ที่ใดภายในภาพ

คุณลักษณะคือคุณลักษณะที่ปรากฏภายในรูปภาพ คุณลักษณะเหล่านี้อาจเป็นอะไรก็ได้ตั้งแต่ขอบที่เอียงเล็กน้อยไปจนถึงการมีจมูกหรือตา ไปจนถึงองค์ประกอบของตา ปาก และจมูก สิ่งสำคัญที่สุดคือ ลักษณะต่างๆ สามารถประกอบด้วยลักษณะที่เรียบง่ายกว่า (เช่น ดวงตาประกอบด้วยขอบโค้งสองสามจุดและมีจุดมืดตรงกลาง)
ฟิลเตอร์เป็นส่วนหนึ่งของโมเดลที่ตรวจจับคุณสมบัติเหล่านี้ภายในภาพ ฟิลเตอร์แต่ละตัวจะมองหาคุณสมบัติเฉพาะอย่างหนึ่ง (เช่น ขอบโค้งจากซ้ายไปขวา) ทั่วทั้งภาพ
ในที่สุด "การบิด" ในโครงข่ายประสาทเทียมแบบหมุนหมายถึงวิธีการใช้ตัวกรองกับรูปภาพ เราจะอธิบายเรื่องนี้ในหัวข้อถัดไป
CNN ได้แสดงให้เห็นถึงประสิทธิภาพที่ยอดเยี่ยมในงานด้านภาพต่างๆ เช่น การตรวจจับวัตถุและการแบ่งส่วนภาพ โมเดล CNN (AlexNet) มีบทบาทสำคัญในการเพิ่มขึ้นของการเรียนรู้เชิงลึกในปี 2012
CNN ทำงานอย่างไร
มาสำรวจสถาปัตยกรรมโดยรวมของ CNN โดยใช้ตัวอย่างในการพิจารณาว่าตัวเลขใด (0–9) อยู่ในรูปภาพ
ก่อนที่จะป้อนรูปภาพลงในโมเดล รูปภาพจะต้องถูกเปลี่ยนให้เป็นการแสดงตัวเลข (หรือการเข้ารหัส) สำหรับภาพขาวดำ แต่ละพิกเซลจะถูกกำหนดหมายเลข: 255 หากเป็นสีขาวสนิท และ 0 หากเป็นสีดำสนิท (บางครั้งทำให้เป็นมาตรฐานเป็น 1 และ 0) สำหรับภาพสี แต่ละพิกเซลจะถูกกำหนดตัวเลขสามตัว โดยตัวหนึ่งระบุว่ามีสีแดง เขียว และน้ำเงินมากน้อยเพียงใด ซึ่งเรียกว่าค่า RGB ดังนั้นรูปภาพขนาด 256×256 พิกเซล (พร้อม 65,536 พิกเซล) จะมีค่า 65,536 ค่าในการเข้ารหัสขาวดำ และ 196,608 ค่าในการเข้ารหัสสี
จากนั้นโมเดลจะประมวลผลรูปภาพผ่านเลเยอร์สามประเภท:
1 เลเยอร์ Convolutional:เลเยอร์นี้ใช้ตัวกรองกับอินพุต ตัวกรองแต่ละตัวเป็นตารางตัวเลขตามขนาดที่กำหนด (เช่น 3×3) ตารางนี้ซ้อนทับบนรูปภาพโดยเริ่มจากด้านซ้ายบน จะใช้ค่าพิกเซลจากแถว 1–3 ในคอลัมน์ 1–3 ค่าพิกเซลเหล่านี้จะคูณด้วยค่าในตัวกรองแล้วจึงรวมเข้าด้วยกัน จากนั้นผลรวมนี้จะถูกวางไว้ในตารางเอาต์พุตตัวกรองในแถวที่ 1 คอลัมน์ 1 จากนั้นตัวกรองจะเลื่อนไปทางขวาหนึ่งพิกเซลและทำซ้ำขั้นตอนนี้จนกว่าจะครอบคลุมแถวและคอลัมน์ทั้งหมดในรูปภาพ ด้วยการเลื่อนทีละพิกเซล ตัวกรองสามารถค้นหาคุณลักษณะต่างๆ ได้ทุกที่ในภาพ ซึ่งเป็นคุณสมบัติที่เรียกว่าค่าไม่แปรผันของการแปล ตัวกรองแต่ละตัวจะสร้างตารางเอาต์พุตของตัวเอง ซึ่งจากนั้นจะถูกส่งไปยังเลเยอร์ถัดไป
2 เลเยอร์การรวมกลุ่ม: เลเยอร์นี้จะสรุปข้อมูลคุณลักษณะจากเลเยอร์ Convolution เลเยอร์แบบหมุนวนส่งคืนเอาต์พุตที่มีขนาดใหญ่กว่าอินพุต (ตัวกรองแต่ละตัวจะส่งคืนแผนผังคุณลักษณะซึ่งมีขนาดประมาณเท่ากับอินพุต และมีหลายตัวกรอง) เลเยอร์การรวมกลุ่มจะใช้แต่ละแผนผังคุณลักษณะและใช้ตารางอื่นกับแผนผังนั้น ตารางนี้ใช้ค่าเฉลี่ยหรือค่าสูงสุดของค่าในนั้นและส่งออกผลลัพธ์นั้น อย่างไรก็ตาม ตารางนี้จะไม่ย้ายทีละพิกเซล มันจะข้ามไปยังพิกเซลแพทช์ถัดไป ตัวอย่างเช่น ตารางรวมกลุ่ม 3×3 จะทำงานบนพิกเซลในแถว 1–3 และคอลัมน์ 1–3 ก่อน จากนั้นจะอยู่ในแถวเดียวกันแต่จะย้ายไปคอลัมน์ 4–6 หลังจากครอบคลุมคอลัมน์ทั้งหมดในแถวชุดแรก (1–3) แล้ว คอลัมน์จะเลื่อนลงไปที่แถว 4–6 และจัดการคอลัมน์เหล่านั้น ซึ่งจะช่วยลดจำนวนแถวและคอลัมน์ในเอาต์พุตได้อย่างมีประสิทธิภาพ เลเยอร์การรวมกลุ่มช่วยลดความซับซ้อน ทำให้โมเดลทนทานต่อสัญญาณรบกวนและการเปลี่ยนแปลงเล็กๆ น้อยๆ มากขึ้น และช่วยให้โมเดลมุ่งเน้นไปที่คุณลักษณะที่สำคัญที่สุด
3 เลเยอร์ที่เชื่อมต่อโดยสมบูรณ์: หลังจากเลเยอร์ Convolutional และ Pooling หลายรอบ การแมปคุณลักษณะสุดท้ายจะถูกส่งไปยังเลเยอร์โครงข่ายประสาทเทียมที่เชื่อมต่อโดยสมบูรณ์ ซึ่งจะส่งคืนเอาต์พุตที่เราสนใจ (เช่น ความน่าจะเป็นที่รูปภาพจะเป็นตัวเลขเฉพาะ) แผนผังคุณลักษณะจะต้องถูกทำให้เรียบ (แต่ละแถวของแผนผังคุณลักษณะจะต่อกันเป็นแถวยาวหนึ่งแถว) จากนั้นจึงนำมารวมกัน (แต่ละแถวของแผนผังคุณลักษณะแบบยาวจะต่อกันเป็นแถวขนาดใหญ่)
นี่คือการแสดงภาพสถาปัตยกรรม CNN ซึ่งแสดงให้เห็นว่าแต่ละเลเยอร์ประมวลผลภาพอินพุตและมีส่วนทำให้เกิดผลลัพธ์สุดท้ายอย่างไร:


หมายเหตุเพิ่มเติมบางประการเกี่ยวกับกระบวนการนี้:
- แต่ละเลเยอร์การบิดที่ต่อเนื่องกันจะค้นหาคุณสมบัติระดับที่สูงกว่า เลเยอร์การบิดชั้นแรกจะตรวจจับขอบ จุด หรือรูปแบบที่เรียบง่าย เลเยอร์ Convolutional ชั้นถัดไปจะนำเอาต์พุตที่รวมกลุ่มกันของเลเยอร์ Convolutional ชั้นแรกมาเป็นอินพุต ทำให้สามารถตรวจจับองค์ประกอบของคุณสมบัติระดับล่างที่ก่อตัวเป็นคุณสมบัติระดับที่สูงกว่า เช่น จมูกหรือตา
- โมเดลนี้ต้องมีการฝึกอบรม ในระหว่างการฝึก รูปภาพจะถูกส่งผ่านทุกเลเยอร์ (โดยมีน้ำหนักสุ่มในตอนแรก) และผลลัพธ์จะถูกสร้างขึ้น ความแตกต่างระหว่างผลลัพธ์กับคำตอบจริงจะใช้ในการปรับน้ำหนักเล็กน้อย ทำให้โมเดลมีแนวโน้มที่จะตอบถูกมากขึ้นในอนาคต ซึ่งทำได้โดยการไล่ระดับลง โดยที่อัลกอริธึมการฝึกอบรมจะคำนวณว่าน้ำหนักของแบบจำลองแต่ละแบบมีส่วนช่วยในคำตอบสุดท้ายเท่าใด (โดยใช้อนุพันธ์บางส่วน) และเลื่อนไปในทิศทางของคำตอบที่ถูกต้องเล็กน้อย ชั้นรวมกลุ่มไม่มีน้ำหนักใดๆ จึงไม่ได้รับผลกระทบจากกระบวนการฝึกอบรม
- CNN สามารถทำงานได้เฉพาะกับภาพที่มีขนาดเท่ากันกับภาพที่ฝึกฝนมาเท่านั้น หากโมเดลได้รับการฝึกฝนเกี่ยวกับรูปภาพที่มีขนาด 256×256 พิกเซล รูปภาพใดๆ ที่ใหญ่กว่านั้นจะต้องถูกลดขนาดลง และรูปภาพที่เล็กกว่านั้นจะต้องถูกอัปแซมปีล
CNN กับ RNN และหม้อแปลงไฟฟ้า
เครือข่ายประสาทเทียมมักถูกกล่าวถึงควบคู่ไปกับโครงข่ายประสาทเทียมที่เกิดซ้ำ (RNN) และหม้อแปลงไฟฟ้า แล้วมันแตกต่างกันอย่างไร?
CNN กับ RNN
RNN และ CNN ดำเนินงานในโดเมนที่แตกต่างกัน RNN เหมาะที่สุดสำหรับข้อมูลตามลำดับ เช่น ข้อความ ในขณะที่ CNN ทำงานได้ดีกับข้อมูลเชิงพื้นที่ เช่น รูปภาพ RNN มีโมดูลหน่วยความจำที่คอยติดตามส่วนต่างๆ ของอินพุตที่เห็นก่อนหน้านี้เพื่อสร้างบริบทให้กับส่วนถัดไป ในทางตรงกันข้าม CNN จะปรับบริบทของอินพุตบางส่วนโดยพิจารณาจากเพื่อนบ้านที่อยู่บริเวณใกล้เคียง เนื่องจาก CNN ไม่มีโมดูลหน่วยความจำ จึงไม่เหมาะกับงานข้อความ พวกเขาจะลืมคำแรกในประโยคเมื่อถึงคำสุดท้าย
ซีเอ็นเอ็นกับหม้อแปลง
Transformers ยังถูกใช้อย่างมากสำหรับงานต่อเนื่อง พวกเขาสามารถใช้ส่วนใดก็ได้ของอินพุตเพื่อสร้างบริบทของอินพุตใหม่ ทำให้เป็นที่นิยมสำหรับงานประมวลผลภาษาธรรมชาติ (NLP) อย่างไรก็ตาม เมื่อเร็ว ๆ นี้ มีการใช้หม้อแปลงไฟฟ้ากับภาพ ในรูปแบบของวิชั่นทรานส์ฟอร์มเมอร์ โมเดลเหล่านี้ถ่ายภาพ แบ่งเป็นแพตช์ ดึงความสนใจ (กลไกหลักในสถาปัตยกรรมหม้อแปลงไฟฟ้า) บนแพตช์ จากนั้นจึงจัดประเภทรูปภาพ วิชันทรานส์ฟอร์มเมอร์สามารถทำงานได้ดีกว่า CNN บนชุดข้อมูลขนาดใหญ่ แต่ขาดความแปรปรวนในการแปลที่มีอยู่ใน CNN ค่าคงที่การแปลใน CNN ช่วยให้โมเดลจดจำวัตถุได้โดยไม่คำนึงถึงตำแหน่งในภาพ ทำให้ CNN มีประสิทธิภาพสูงสำหรับงานที่ความสัมพันธ์เชิงพื้นที่ของคุณลักษณะเป็นสิ่งสำคัญ
การใช้งานของ CNN
CNN มักใช้กับรูปภาพเนื่องจากความไม่แปรผันในการแปลและคุณลักษณะเชิงพื้นที่ แต่ด้วยการประมวลผลที่ชาญฉลาด CNN จึงสามารถทำงานในโดเมนอื่นได้ (โดยมักจะแปลงเป็นรูปภาพก่อน)
การจำแนกประเภทภาพ
การจัดหมวดหมู่ภาพเป็นการใช้งานหลักของ CNN CNN ขนาดใหญ่ที่ผ่านการฝึกอบรมมาเป็นอย่างดีสามารถจดจำวัตถุต่างๆ ได้นับล้านชิ้น และสามารถทำงานกับภาพใดๆ ก็ตามที่ได้รับมาได้เกือบทุกภาพ แม้จะมีการเพิ่มขึ้นของหม้อแปลง แต่ประสิทธิภาพการคำนวณของ CNN ทำให้หม้อแปลงเหล่านี้เป็นตัวเลือกที่ทำงานได้
การรู้จำเสียง
เสียงที่บันทึกสามารถเปลี่ยนเป็นข้อมูลเชิงพื้นที่ผ่านสเปกโตรแกรม ซึ่งเป็นการแสดงภาพเสียง CNN สามารถใช้สเปกโตรแกรมเป็นอินพุตและเรียนรู้การจับคู่รูปคลื่นต่างๆ กับคำที่ต่างกัน ในทำนองเดียวกัน CNN สามารถจดจำจังหวะและตัวอย่างเพลงได้
การแบ่งส่วนรูปภาพ
การแบ่งส่วนรูปภาพเกี่ยวข้องกับการระบุและการวาดขอบเขตรอบวัตถุต่างๆ ในภาพ CNN ได้รับความนิยมในงานนี้เนื่องจากมีประสิทธิภาพที่โดดเด่นในการจดจำวัตถุต่างๆ เมื่อแบ่งภาพแล้ว เราจะเข้าใจเนื้อหาได้ดีขึ้น ตัวอย่างเช่น โมเดลการเรียนรู้เชิงลึกอีกรูปแบบหนึ่งสามารถวิเคราะห์ส่วนต่างๆ และอธิบายฉากนี้ได้: “คนสองคนกำลังเดินอยู่ในสวนสาธารณะ มีเสาไฟอยู่ทางขวาและมีรถอยู่ข้างหน้าพวกเขา” ในวงการแพทย์ การแบ่งส่วนภาพสามารถแยกแยะเนื้องอกจากเซลล์ปกติในการสแกนได้ สำหรับรถยนต์ขับเคลื่อนอัตโนมัติ สามารถระบุเครื่องหมายช่องทาง ป้ายถนน และยานพาหนะอื่นๆ ได้
ข้อดีของ CNN
CNN ถูกนำมาใช้กันอย่างแพร่หลายในอุตสาหกรรมด้วยเหตุผลหลายประการ
ประสิทธิภาพของภาพที่แข็งแกร่ง
เนื่องจากมีข้อมูลรูปภาพมากมาย จึงจำเป็นต้องมีโมเดลที่ทำงานได้ดีกับรูปภาพประเภทต่างๆ CNN เหมาะสมอย่างยิ่งสำหรับจุดประสงค์นี้ ความคงที่ในการแปลและความสามารถในการสร้างคุณสมบัติที่ใหญ่ขึ้นจากคุณสมบัติที่เล็กลง ทำให้สามารถตรวจจับคุณสมบัติต่างๆ ได้ทั่วทั้งภาพ รูปภาพประเภทต่างๆ ไม่จำเป็นต้องใช้สถาปัตยกรรมที่แตกต่างกัน เนื่องจาก CNN พื้นฐานสามารถนำไปใช้กับข้อมูลรูปภาพได้ทุกประเภท
ไม่มีวิศวกรรมคุณสมบัติแบบแมนนวล
ก่อนที่จะมี CNN โมเดลรูปภาพที่มีประสิทธิภาพดีที่สุดต้องใช้ความพยายามอย่างมาก ผู้เชี่ยวชาญด้านโดเมนต้องสร้างโมดูลเพื่อตรวจจับคุณสมบัติเฉพาะประเภท (เช่น ฟิลเตอร์สำหรับขอบ) ซึ่งเป็นกระบวนการที่ใช้เวลานานซึ่งขาดความยืดหยุ่นสำหรับรูปภาพที่หลากหลาย รูปภาพแต่ละชุดจำเป็นต้องมีชุดคุณสมบัติของตัวเอง ในทางตรงกันข้าม CNN (AlexNet) อันโด่งดังแห่งแรกสามารถจัดหมวดหมู่รูปภาพได้ 20,000 ประเภทโดยอัตโนมัติ ซึ่งช่วยลดความจำเป็นในการใช้วิศวกรรมคุณสมบัติแบบแมนนวล
ข้อเสียของ CNN
แน่นอนว่ายังมีข้อด้อยในการใช้ CNN
ไฮเปอร์พารามิเตอร์จำนวนมาก
การฝึกอบรม CNN เกี่ยวข้องกับการเลือกไฮเปอร์พารามิเตอร์จำนวนมาก เช่นเดียวกับโครงข่ายประสาทเทียมอื่นๆ มีไฮเปอร์พารามิเตอร์ เช่น จำนวนเลเยอร์ ขนาดแบทช์ และอัตราการเรียนรู้ นอกจากนี้ ตัวกรองแต่ละตัวจำเป็นต้องมีชุดไฮเปอร์พารามิเตอร์ของตัวเอง: ขนาดตัวกรอง (เช่น 3×3, 5×5) และก้าว (จำนวนพิกเซลที่จะเคลื่อนที่หลังจากแต่ละขั้นตอน) ไม่สามารถปรับไฮเปอร์พารามิเตอร์ได้อย่างง่ายดายในระหว่างกระบวนการฝึกอบรม แต่คุณต้องฝึกโมเดลหลายตัวด้วยชุดไฮเปอร์พารามิเตอร์ที่แตกต่างกัน (เช่น ชุด A และชุด B) และเปรียบเทียบประสิทธิภาพเพื่อกำหนดตัวเลือกที่ดีที่สุด
ความไวต่อขนาดอินพุต
CNN แต่ละแห่งได้รับการฝึกอบรมให้ยอมรับภาพที่มีขนาดที่แน่นอน (เช่น 256×256 พิกเซล) รูปภาพจำนวนมากที่คุณต้องการประมวลผลอาจไม่ตรงกับขนาดนี้ เพื่อแก้ไขปัญหานี้ คุณสามารถขยายหรือลดขนาดรูปภาพของคุณได้ อย่างไรก็ตาม การปรับขนาดนี้อาจส่งผลให้ข้อมูลอันมีค่าสูญหาย และอาจลดประสิทธิภาพของโมเดลได้