
ข้อมูลพื้นฐานเกี่ยวกับเครือข่ายปฏิปักษ์ทั่วไป: สิ่งที่คุณต้องรู้
เผยแพร่แล้ว: 2024-10-08Generative Adversarial Network (GAN) เป็นเครื่องมือปัญญาประดิษฐ์ (AI) ที่ทรงพลัง พร้อมด้วยแอปพลิเคชันมากมายในการเรียนรู้ของเครื่อง (ML) คู่มือนี้จะสำรวจ GAN วิธีทำงาน แอปพลิเคชัน ตลอดจนข้อดีและข้อเสีย
สารบัญ
- GAN คืออะไร?
- GAN กับ CNN
- GAN ทำงานอย่างไร
- ประเภทของ GAN
- การประยุกต์ใช้ GAN
- ข้อดีของ GAN
- ข้อเสียของ GAN
เครือข่ายปฏิปักษ์กำเนิดคืออะไร?
เครือข่ายปฏิปักษ์เชิงสร้างสรรค์หรือ GAN เป็นโมเดลการเรียนรู้เชิงลึกประเภทหนึ่งที่โดยทั่วไปใช้ในการเรียนรู้ของเครื่องแบบไม่มีผู้ดูแล แต่ยังสามารถปรับให้เข้ากับการเรียนรู้แบบกึ่งควบคุมและการเรียนรู้แบบมีผู้สอนได้ด้วย GAN ใช้เพื่อสร้างข้อมูลคุณภาพสูงคล้ายกับชุดข้อมูลการฝึกอบรม เนื่องจากเป็นชุดย่อยของ generative AI GAN จึงประกอบด้วยโมเดลย่อย 2 รุ่น ได้แก่ ตัวสร้างและตัวแบ่งแยก
1 ตัวสร้าง:ตัวสร้างสร้างข้อมูลสังเคราะห์
2 Discriminator:Discriminator จะประเมินเอาท์พุตของเครื่องกำเนิดไฟฟ้า โดยแยกความแตกต่างระหว่างข้อมูลจริงจากชุดการฝึกและข้อมูลสังเคราะห์ที่สร้างขึ้นโดยเครื่องกำเนิดไฟฟ้า
ทั้งสองโมเดลมีส่วนร่วมในการแข่งขัน: เครื่องกำเนิดไฟฟ้าพยายามหลอกผู้เลือกปฏิบัติให้จำแนกข้อมูลที่สร้างขึ้นว่าเป็นของจริง ในขณะที่ผู้เลือกปฏิบัติจะปรับปรุงความสามารถในการตรวจจับข้อมูลสังเคราะห์อย่างต่อเนื่อง กระบวนการปฏิปักษ์นี้จะดำเนินต่อไปจนกว่าผู้เลือกปฏิบัติจะไม่สามารถแยกแยะระหว่างข้อมูลจริงและข้อมูลที่สร้างขึ้นได้อีกต่อไป ณ จุดนี้ GAN สามารถสร้างภาพ วิดีโอ และข้อมูลประเภทอื่นๆ ที่สมจริงได้
GAN กับ CNN
GAN และโครงข่ายประสาทเทียมแบบหมุน (CNN) เป็นโครงข่ายประสาทเทียมประเภททรงพลังที่ใช้ในการเรียนรู้เชิงลึก แต่จะมีความแตกต่างกันอย่างมากในแง่ของกรณีการใช้งานและสถาปัตยกรรม
กรณีการใช้งาน
- GAN:เชี่ยวชาญในการสร้างข้อมูลสังเคราะห์ที่สมจริงตามข้อมูลการฝึกอบรม ทำให้ GAN เหมาะสมกับงานต่างๆ เช่น การสร้างภาพ การถ่ายโอนรูปแบบภาพ และการเพิ่มข้อมูล GAN ไม่ได้รับการดูแล ซึ่งหมายความว่าสามารถนำไปใช้กับสถานการณ์ที่ข้อมูลที่ติดป้ายกำกับขาดแคลนหรือไม่พร้อมใช้งานได้
- CNN:ใช้เป็นหลักสำหรับงานจำแนกประเภทข้อมูลที่มีโครงสร้าง เช่น การวิเคราะห์ความรู้สึก การจัดหมวดหมู่หัวข้อ และการแปลภาษา เนื่องจากความสามารถในการจำแนกประเภท CNN ยังทำหน้าที่เป็นผู้เลือกปฏิบัติที่ดีใน GAN อีกด้วย อย่างไรก็ตาม เนื่องจาก CNN ต้องการข้อมูลการฝึกอบรมที่มีโครงสร้างและมีคำอธิบายประกอบโดยมนุษย์ ข้อมูลเหล่านี้จึงจำกัดอยู่เพียงสถานการณ์การเรียนรู้ภายใต้การดูแลเท่านั้น
สถาปัตยกรรม
- GAN:ประกอบด้วยสองโมเดล—ผู้เลือกปฏิบัติและผู้สร้าง—ที่มีส่วนร่วมในกระบวนการแข่งขัน เครื่องกำเนิดจะสร้างภาพ ในขณะที่ผู้เลือกปฏิบัติจะประเมินภาพเหล่านั้น โดยผลักดันให้เครื่องกำเนิดสร้างภาพที่สมจริงมากขึ้นเมื่อเวลาผ่านไป
- CNN:ใช้เลเยอร์ของการดำเนินการแบบ Convolutional และ Pooling เพื่อแยกและวิเคราะห์คุณสมบัติจากรูปภาพ สถาปัตยกรรมรุ่นเดียวนี้มุ่งเน้นไปที่การจดจำรูปแบบและโครงสร้างภายในข้อมูล
โดยรวมแล้ว แม้ว่า CNN จะมุ่งเน้นไปที่การวิเคราะห์ข้อมูลที่มีโครงสร้างที่มีอยู่ แต่ GAN ก็มุ่งเน้นไปที่การสร้างข้อมูลใหม่ที่สมจริง
GAN ทำงานอย่างไร
ในระดับสูง GAN ทำงานโดยการวางโครงข่ายประสาทเทียมสองเครือข่าย นั่นคือตัวกำเนิดและตัวแบ่งแยกเข้าด้วยกัน GAN ไม่ต้องการสถาปัตยกรรมโครงข่ายประสาทเทียมชนิดใดชนิดหนึ่งสำหรับส่วนประกอบทั้งสองอย่าง ตราบใดที่สถาปัตยกรรมที่เลือกมาเสริมซึ่งกันและกัน ตัวอย่างเช่น หากใช้ CNN เป็นตัวแยกแยะสำหรับการสร้างภาพ ตัวสร้างอาจเป็นโครงข่ายประสาทเทียมแบบ de-convolutional (deCNN) ซึ่งดำเนินการกระบวนการ CNN ในแบบย้อนกลับ แต่ละองค์ประกอบมีเป้าหมายที่แตกต่างกัน:
- เครื่องกำเนิด:เพื่อสร้างข้อมูลคุณภาพสูงจนผู้เลือกปฏิบัติถูกหลอกให้จำแนกว่าเป็นข้อมูลจริง
- ผู้แยกแยะ:เพื่อจำแนกตัวอย่างข้อมูลที่ระบุอย่างถูกต้องว่าเป็นของจริง (จากชุดข้อมูลการฝึกอบรม) หรือของปลอม (สร้างโดยเครื่องกำเนิด)
การแข่งขันครั้งนี้เป็นการนำเกมผลรวมเป็นศูนย์มาใช้ ซึ่งรางวัลที่มอบให้กับโมเดลหนึ่งจะเป็นการลงโทษสำหรับอีกโมเดลด้วย สำหรับเครื่องกำเนิดไฟฟ้า การหลอกผู้เลือกปฏิบัติได้สำเร็จส่งผลให้มีการอัปเดตโมเดลที่ช่วยเพิ่มความสามารถในการสร้างข้อมูลที่สมจริง ในทางกลับกัน เมื่อผู้เลือกปฏิบัติระบุข้อมูลปลอมได้อย่างถูกต้อง ก็จะได้รับการอัปเดตที่ปรับปรุงความสามารถในการตรวจจับ ในทางคณิตศาสตร์ ตัวแบ่งแยกมีเป้าหมายเพื่อลดข้อผิดพลาดในการจำแนกประเภทให้เหลือน้อยที่สุด ในขณะที่ตัวสร้างจะพยายามขยายให้สูงสุด
กระบวนการฝึกอบรม GAN
การฝึกอบรม GAN เกี่ยวข้องกับการสลับระหว่างตัวสร้างและผู้แยกแยะในช่วงหลายยุค Epochs เป็นการฝึกฝนที่สมบูรณ์สำหรับชุดข้อมูลทั้งหมด กระบวนการนี้จะดำเนินต่อไปจนกว่าเครื่องกำเนิดจะสร้างข้อมูลสังเคราะห์ที่หลอกลวงผู้เลือกปฏิบัติประมาณ 50% ของเวลา แม้ว่าทั้งสองรุ่นจะใช้อัลกอริธึมที่คล้ายกันสำหรับการประเมินและปรับปรุงประสิทธิภาพ แต่การอัปเดตจะเกิดขึ้นอย่างแยกจากกัน การอัปเดตเหล่านี้ดำเนินการโดยใช้วิธีการที่เรียกว่า backpropagation ซึ่งจะวัดข้อผิดพลาดของแต่ละรุ่นและปรับพารามิเตอร์เพื่อปรับปรุงประสิทธิภาพ อัลกอริธึมการปรับให้เหมาะสมจะปรับพารามิเตอร์ของแต่ละรุ่นอย่างอิสระ
นี่คือการแสดงภาพสถาปัตยกรรม GAN ซึ่งแสดงให้เห็นการแข่งขันระหว่างตัวสร้างและผู้แยกแยะ:
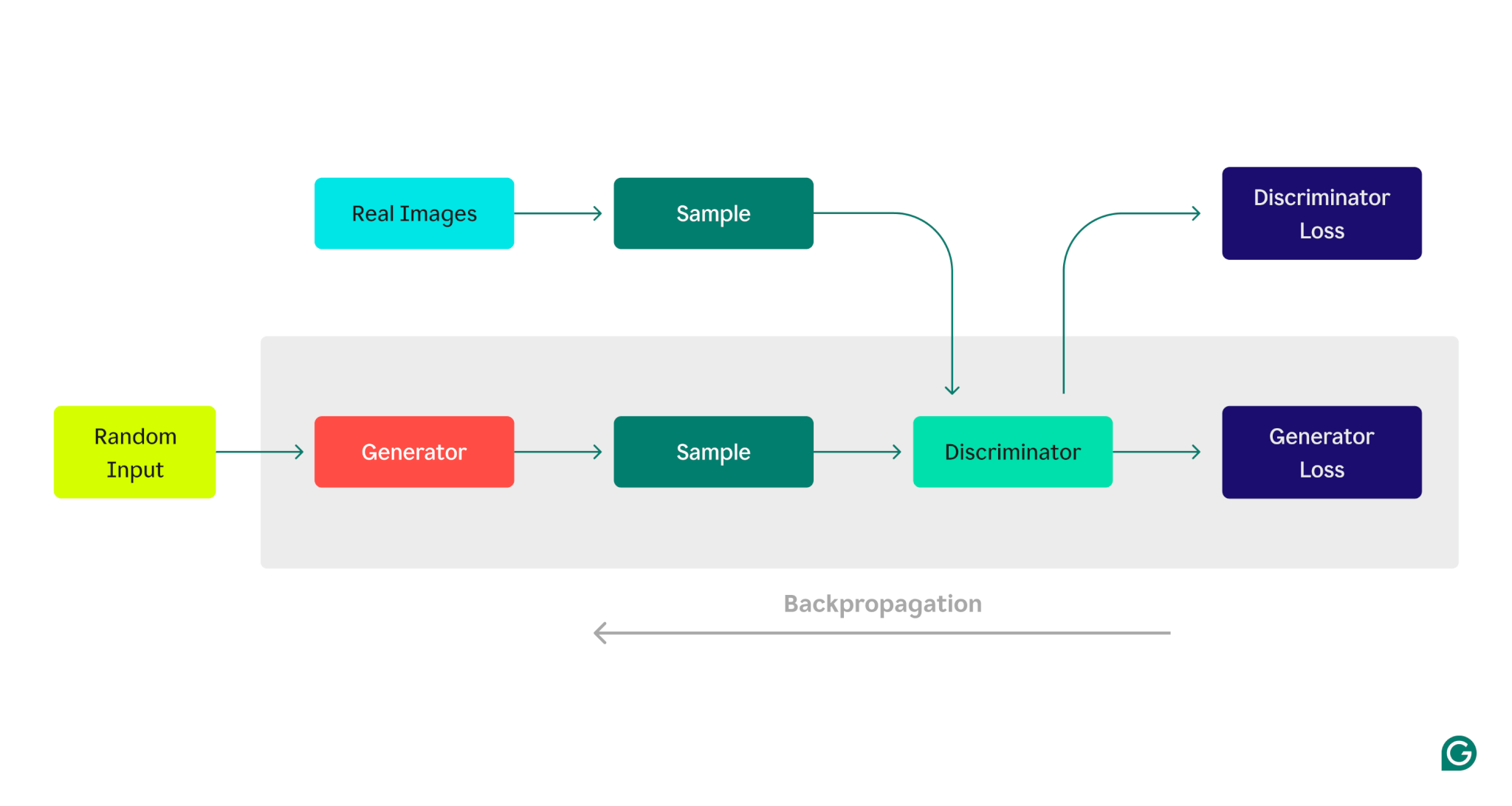
ขั้นตอนการฝึกอบรมเครื่องกำเนิดไฟฟ้า:
1 ตัวสร้างจะสร้างตัวอย่างข้อมูล โดยทั่วไปจะเริ่มต้นด้วยสัญญาณรบกวนแบบสุ่มเป็นอินพุต
2 ผู้แยกแยะจะจัดประเภทตัวอย่างเหล่านี้ว่าเป็นของจริง (จากชุดข้อมูลการฝึกอบรม) หรือของปลอม (สร้างโดยเครื่องกำเนิด)
3 ขึ้นอยู่กับการตอบสนองของผู้แยกแยะ พารามิเตอร์ตัวสร้างจะได้รับการอัปเดตโดยใช้การเผยแพร่กลับ
ขั้นตอนการฝึกอบรมผู้เลือกปฏิบัติ:
1 ข้อมูลปลอมถูกสร้างขึ้นโดยใช้สถานะปัจจุบันของเครื่องกำเนิด
2 ตัวอย่างที่สร้างขึ้นจะถูกจัดเตรียมให้กับผู้แยกแยะ พร้อมด้วยตัวอย่างจากชุดข้อมูลการฝึกอบรม
3 การใช้ backpropagation พารามิเตอร์ของ discriminator จะได้รับการอัปเดตตามประสิทธิภาพการจำแนกประเภท
กระบวนการฝึกอบรมซ้ำนี้ดำเนินต่อไป โดยพารามิเตอร์ของแต่ละรุ่นจะถูกปรับตามประสิทธิภาพ จนกว่าเครื่องกำเนิดจะสร้างข้อมูลที่ผู้แยกแยะไม่สามารถแยกความแตกต่างจากข้อมูลจริงได้อย่างน่าเชื่อถือ
ประเภทของ GAN
GAN ประเภทพิเศษอื่นๆ ได้รับการพัฒนาและปรับให้เหมาะสมสำหรับงานต่างๆ โดยใช้สถาปัตยกรรม GAN พื้นฐานที่มักเรียกกันว่า Vanilla GAN รูปแบบต่างๆ ที่พบบ่อยที่สุดบางส่วนได้อธิบายไว้ด้านล่าง แม้จะไม่ใช่รายการที่ครบถ้วนสมบูรณ์:
GAN แบบมีเงื่อนไข (cGAN)
GAN แบบมีเงื่อนไขหรือ cGAN ใช้ข้อมูลเพิ่มเติมที่เรียกว่าเงื่อนไข เพื่อเป็นแนวทางให้กับโมเดลในการสร้างข้อมูลประเภทเฉพาะเมื่อฝึกชุดข้อมูลทั่วไป เงื่อนไขอาจเป็นป้ายกำกับคลาส คำอธิบายแบบข้อความ หรือข้อมูลการจัดประเภทประเภทอื่น ตัวอย่างเช่น ลองจินตนาการว่าคุณต้องสร้างรูปภาพของแมววิเชียรมีสเท่านั้น แต่ชุดข้อมูลการฝึกของคุณมีรูปภาพของแมวทุกประเภท ใน cGAN คุณสามารถติดป้ายกำกับรูปภาพฝึกด้วยประเภทของแมวได้ และแบบจำลองก็สามารถใช้สิ่งนี้เพื่อเรียนรู้วิธีสร้างเฉพาะรูปภาพของแมววิเชียรมาศเท่านั้น

GAN แบบหมุนลึก (DCGAN)
GAN แบบ Deep Convolutional หรือ DCGAN ได้รับการปรับให้เหมาะสมสำหรับการสร้างภาพ ใน DCGAN ตัวสร้างจะเป็นเครือข่ายประสาทเทียมแบบฝังลึก (deCNN) และผู้แยกแยะคือ Deep CNN CNN เหมาะกว่าสำหรับการทำงานกับและสร้างภาพเนื่องจากความสามารถในการจับลำดับชั้นและรูปแบบเชิงพื้นที่ ตัวสร้างใน DCGAN ใช้เลเยอร์การสุ่มตัวอย่างและการย้ายตำแหน่งเพื่อสร้างภาพคุณภาพสูงกว่าเพอร์เซปตรอนแบบหลายชั้น (โครงข่ายประสาทเทียมธรรมดาที่ตัดสินใจโดยการชั่งน้ำหนักคุณสมบัติอินพุต) สามารถสร้างได้ ในทำนองเดียวกัน ผู้เลือกปฏิบัติใช้เลเยอร์แบบหมุนวนเพื่อแยกคุณลักษณะต่างๆ จากตัวอย่างภาพ และจำแนกประเภทได้อย่างแม่นยำว่าเป็นของจริงหรือของปลอม
CycleGAN
CycleGAN เป็น GAN ประเภทหนึ่งที่ออกแบบมาเพื่อสร้างรูปภาพประเภทหนึ่งจากอีกประเภทหนึ่ง ตัวอย่างเช่น CycleGAN สามารถเปลี่ยนรูปภาพของเมาส์ให้เป็นหนู หรือสุนัขให้เป็นโคโยตี้ได้ CycleGAN สามารถทำการแปลภาพเป็นภาพได้โดยไม่ต้องฝึกอบรมชุดข้อมูลที่จับคู่ ซึ่งก็คือชุดข้อมูลที่มีทั้งภาพพื้นฐานและการแปลงที่ต้องการ ความสามารถนี้สามารถทำได้โดยการใช้เครื่องกำเนิดไฟฟ้าสองตัวและเครื่องแยกแยะสองตัวแทนที่จะเป็นคู่เดียวที่ vanilla GAN ใช้ ใน CycleGAN ตัวสร้างตัวหนึ่งจะแปลงรูปภาพจากรูปภาพพื้นฐานไปเป็นเวอร์ชันที่แปลงแล้ว ในขณะที่ตัวสร้างอีกตัวหนึ่งจะทำการแปลงในทิศทางตรงกันข้าม ในทำนองเดียวกัน ผู้เลือกปฏิบัติแต่ละคนจะตรวจสอบประเภทรูปภาพเฉพาะเพื่อดูว่าเป็นของจริงหรือของปลอม จากนั้น CycleGAN จะใช้การตรวจสอบความสอดคล้องเพื่อให้แน่ใจว่าการแปลงรูปภาพเป็นรูปแบบอื่นและย้อนกลับจะให้ผลลัพธ์เป็นรูปภาพต้นฉบับ
การประยุกต์ใช้ GAN
เนื่องจากสถาปัตยกรรมที่โดดเด่น GAN จึงถูกนำไปใช้กับกรณีการใช้งานเชิงนวัตกรรมที่หลากหลาย แม้ว่าประสิทธิภาพจะขึ้นอยู่กับงานเฉพาะและคุณภาพของข้อมูลเป็นอย่างสูง แอปพลิเคชั่นที่ทรงพลังบางตัว ได้แก่ การสร้างข้อความเป็นรูปภาพ การเพิ่มข้อมูล และการสร้างและจัดการวิดีโอ
การสร้างข้อความเป็นรูปภาพ
GAN สามารถสร้างภาพจากคำอธิบายที่เป็นข้อความ แอปพลิเคชั่นนี้มีคุณค่าในอุตสาหกรรมสร้างสรรค์ ช่วยให้ผู้เขียนและนักออกแบบเห็นภาพฉากและตัวละครที่อธิบายไว้ในข้อความ แม้ว่า GAN มักจะถูกใช้สำหรับงานดังกล่าว แต่โมเดล AI เชิงสร้างสรรค์อื่นๆ เช่น DALL-E ของ OpenAI จะใช้สถาปัตยกรรมที่ใช้หม้อแปลงไฟฟ้าเพื่อให้ได้ผลลัพธ์ที่คล้ายคลึงกัน
การเพิ่มข้อมูล
GAN มีประโยชน์สำหรับการเพิ่มข้อมูล เนื่องจากสามารถสร้างข้อมูลสังเคราะห์ที่คล้ายกับข้อมูลการฝึกจริง แม้ว่าระดับความแม่นยำและความสมจริงอาจแตกต่างกันไปขึ้นอยู่กับกรณีการใช้งานเฉพาะและการฝึกโมเดล ความสามารถนี้มีประโยชน์อย่างยิ่งในการเรียนรู้ของเครื่องเพื่อขยายชุดข้อมูลที่จำกัดและเพิ่มประสิทธิภาพของโมเดล นอกจากนี้ GAN ยังเสนอโซลูชันสำหรับการรักษาความเป็นส่วนตัวของข้อมูล ในสาขาที่ละเอียดอ่อน เช่น การดูแลสุขภาพและการเงิน GAN สามารถสร้างข้อมูลสังเคราะห์ที่รักษาคุณสมบัติทางสถิติของชุดข้อมูลดั้งเดิมโดยไม่กระทบต่อข้อมูลที่ละเอียดอ่อน
การสร้างและการจัดการวิดีโอ
GAN ได้แสดงให้เห็นอย่างชัดเจนในงานสร้างและการจัดการวิดีโอบางอย่าง ตัวอย่างเช่น GAN สามารถใช้เพื่อสร้างเฟรมในอนาคตจากลำดับวิดีโอเริ่มต้น ซึ่งช่วยในการใช้งานต่างๆ เช่น การทำนายการเคลื่อนไหวของคนเดินเท้า หรือการคาดการณ์อันตรายบนท้องถนนสำหรับยานพาหนะที่เป็นอิสระ อย่างไรก็ตาม แอปพลิเคชันเหล่านี้ยังอยู่ภายใต้การวิจัยและพัฒนาเชิงรุก GAN ยังสามารถใช้เพื่อสร้างเนื้อหาวิดีโอสังเคราะห์ที่สมบูรณ์และปรับปรุงวิดีโอด้วยเอฟเฟกต์พิเศษที่สมจริง
ข้อดีของ GAN
GAN มีข้อดีที่แตกต่างกันหลายประการ รวมถึงความสามารถในการสร้างข้อมูลสังเคราะห์ที่สมจริง เรียนรู้จากข้อมูลที่ไม่ได้จับคู่ และดำเนินการฝึกอบรมแบบไม่มีผู้ดูแล
การสร้างข้อมูลสังเคราะห์คุณภาพสูง
สถาปัตยกรรมของ GAN ช่วยให้พวกเขาสร้างข้อมูลสังเคราะห์ที่สามารถประมาณข้อมูลจริงในแอปพลิเคชันต่างๆ เช่น การเพิ่มข้อมูลและการสร้างวิดีโอ แม้ว่าคุณภาพและความแม่นยำของข้อมูลนี้อาจขึ้นอยู่กับเงื่อนไขการฝึกอบรมและพารามิเตอร์โมเดลอย่างมาก ตัวอย่างเช่น DCGAN ซึ่งใช้ CNN เพื่อการประมวลผลภาพที่เหมาะสมที่สุด สามารถสร้างภาพที่สมจริงได้อย่างดีเยี่ยม
สามารถเรียนรู้จากข้อมูลที่ไม่ได้จับคู่ได้
ไม่เหมือนกับโมเดล ML บางรุ่น GAN สามารถเรียนรู้จากชุดข้อมูลโดยไม่ต้องมีตัวอย่างอินพุตและเอาต์พุตที่จับคู่กัน ความยืดหยุ่นนี้ทำให้สามารถใช้ GAN ในงานต่างๆ มากมายที่ข้อมูลที่จับคู่มีน้อยหรือไม่พร้อมใช้งาน ตัวอย่างเช่น ในงานแปลจากภาพเป็นภาพ โมเดลแบบดั้งเดิมมักต้องการชุดข้อมูลของภาพและการแปลงสำหรับการฝึกอบรม ในทางตรงกันข้าม GAN สามารถใช้ประโยชน์จากชุดข้อมูลที่เป็นไปได้ที่หลากหลายมากขึ้นสำหรับการฝึกอบรม
การเรียนรู้แบบไม่มีผู้ดูแล
GAN เป็นวิธีการเรียนรู้ของเครื่องที่ไม่ได้รับการดูแล ซึ่งหมายความว่าสามารถฝึกอบรมเกี่ยวกับข้อมูลที่ไม่มีป้ายกำกับโดยไม่มีคำแนะนำที่ชัดเจน นี่เป็นข้อได้เปรียบอย่างยิ่งเนื่องจากการติดฉลากข้อมูลเป็นกระบวนการที่ใช้เวลานานและมีค่าใช้จ่ายสูง ความสามารถของ GAN ในการเรียนรู้จากข้อมูลที่ไม่มีป้ายกำกับทำให้มีประโยชน์สำหรับแอปพลิเคชันที่ข้อมูลที่ติดป้ายกำกับมีจำนวนจำกัดหรือรับได้ยาก GAN ยังสามารถปรับให้เข้ากับการเรียนรู้แบบกึ่งมีผู้ดูแลและแบบมีผู้สอนได้ ทำให้สามารถใช้ข้อมูลที่ติดป้ายกำกับได้
ข้อเสียของ GAN
แม้ว่า GAN จะเป็นเครื่องมืออันทรงพลังในการเรียนรู้ของเครื่อง แต่สถาปัตยกรรมของ GAN ก็สร้างชุดข้อเสียที่มีเอกลักษณ์เฉพาะตัว ข้อเสียเหล่านี้รวมถึงความไวต่อไฮเปอร์พารามิเตอร์ ต้นทุนการคำนวณสูง ความล้มเหลวในการลู่เข้า และปรากฏการณ์ที่เรียกว่าการล่มสลายของโหมด
ความไวของไฮเปอร์พารามิเตอร์
GAN มีความอ่อนไหวต่อไฮเปอร์พารามิเตอร์ ซึ่งเป็นพารามิเตอร์ที่ตั้งค่าก่อนการฝึกและไม่ได้เรียนรู้จากข้อมูล ตัวอย่างได้แก่ สถาปัตยกรรมเครือข่ายและจำนวนตัวอย่างการฝึกอบรมที่ใช้ในการวนซ้ำครั้งเดียว การเปลี่ยนแปลงเล็กน้อยในพารามิเตอร์เหล่านี้อาจส่งผลกระทบอย่างมากต่อกระบวนการฝึกอบรมและเอาท์พุตของโมเดล ซึ่งจำเป็นต้องมีการปรับแต่งอย่างละเอียดสำหรับการใช้งานจริง
ต้นทุนการคำนวณสูง
เนื่องจากสถาปัตยกรรมที่ซับซ้อน กระบวนการฝึกอบรมแบบวนซ้ำ และความไวของไฮเปอร์พารามิเตอร์ GAN จึงมีค่าใช้จ่ายในการคำนวณสูง การฝึกอบรม GAN ให้ประสบความสำเร็จต้องใช้ฮาร์ดแวร์เฉพาะทางและมีราคาแพง รวมถึงเวลาที่สำคัญ ซึ่งอาจเป็นอุปสรรคสำหรับหลายองค์กรที่ต้องการใช้ GAN
ความล้มเหลวในการบรรจบกัน
วิศวกรและนักวิจัยสามารถใช้เวลาจำนวนมากในการทดลองกับการกำหนดค่าการฝึกอบรมก่อนที่จะถึงอัตราที่ยอมรับได้ ซึ่งผลลัพธ์ของแบบจำลองจะมีเสถียรภาพและแม่นยำ หรือที่เรียกว่าอัตราการลู่เข้า การบรรจบกันใน GAN อาจทำได้ยากมากและอาจอยู่ได้ไม่นานนัก ความล้มเหลวในการบรรจบกันคือเมื่อผู้แยกแยะไม่สามารถตัดสินใจได้อย่างเพียงพอระหว่างข้อมูลจริงและข้อมูลปลอม ส่งผลให้มีความแม่นยำประมาณ 50% เนื่องจากยังไม่ได้รับความสามารถในการระบุข้อมูลจริง ซึ่งแตกต่างจากความสมดุลที่ตั้งใจไว้ระหว่างการฝึกอบรมที่ประสบความสำเร็จ GAN บางตัวอาจไม่ถึงจุดบรรจบกันและอาจต้องมีการวิเคราะห์เฉพาะทางเพื่อซ่อมแซม
โหมดล่มสลาย
GAN มีแนวโน้มที่จะเกิดปัญหาที่เรียกว่าการล่มสลายของโหมด โดยที่ตัวสร้างจะสร้างเอาต์พุตในช่วงที่จำกัด และไม่สามารถสะท้อนถึงความหลากหลายของการกระจายข้อมูลในโลกแห่งความเป็นจริง ปัญหานี้เกิดขึ้นจากสถาปัตยกรรม GAN เนื่องจากตัวสร้างมุ่งเน้นไปที่การผลิตข้อมูลที่สามารถหลอกผู้เลือกปฏิบัติมากเกินไป และนำไปสู่การสร้างตัวอย่างที่คล้ายกัน