
โครงข่ายประสาทเทียม: ทุกสิ่งที่คุณควรรู้
เผยแพร่แล้ว: 2024-06-26ในบทความนี้ เราจะเจาะลึกโลกของโครงข่ายประสาทเทียม สำรวจการทำงานภายใน ประเภท แอปพลิเคชัน และความท้าทายที่พวกเขาเผชิญ
สารบัญ
- โครงข่ายประสาทเทียมคืออะไร?
- โครงสร้างโครงข่ายประสาทเทียมเป็นอย่างไร
- โครงข่ายประสาทเทียมทำงานอย่างไร
- โครงข่ายประสาทเทียมสร้างคำตอบได้อย่างไร
- ประเภทของโครงข่ายประสาทเทียม
- การใช้งาน
- ความท้าทาย
- อนาคตของโครงข่ายประสาทเทียม
- บทสรุป
โครงข่ายประสาทเทียมคืออะไร?
โครงข่ายประสาทเทียมคือโมเดลการเรียนรู้เชิงลึกประเภทหนึ่งภายในขอบเขตที่กว้างกว่าของการเรียนรู้ของเครื่อง (ML) ที่จำลองสมองของมนุษย์ โดยจะประมวลผลข้อมูลผ่านโหนดหรือเซลล์ประสาทที่เชื่อมต่อถึงกันซึ่งจัดเรียงเป็นเลเยอร์ต่างๆ ได้แก่ อินพุต ซ่อน และเอาต์พุต แต่ละโหนดทำการคำนวณอย่างง่าย ซึ่งส่งผลให้โมเดลสามารถจดจำรูปแบบและคาดการณ์ได้
โครงข่ายประสาทเทียมการเรียนรู้เชิงลึกมีประสิทธิภาพโดยเฉพาะอย่างยิ่งในการจัดการงานที่ซับซ้อน เช่น การจดจำรูปภาพและคำพูด ซึ่งกลายเป็นองค์ประกอบสำคัญของแอปพลิเคชัน AI จำนวนมาก ความก้าวหน้าล่าสุดในสถาปัตยกรรมโครงข่ายประสาทเทียมและเทคนิคการฝึกอบรมได้เพิ่มขีดความสามารถของระบบ AI อย่างมาก
โครงสร้างโครงข่ายประสาทเทียมเป็นอย่างไร
ตามที่ระบุไว้ในชื่อ โมเดลโครงข่ายประสาทเทียมได้รับแรงบันดาลใจจากเซลล์ประสาท ซึ่งเป็นส่วนประกอบสำคัญของสมอง มนุษย์ที่โตเต็มวัยมีเซลล์ประสาทประมาณ 85 พันล้านเซลล์ประสาท แต่ละเซลล์เชื่อมต่อกับเซลล์ประสาทอีกประมาณ 1,000 เซลล์ เซลล์สมองหนึ่งสื่อสารกับอีกเซลล์หนึ่งโดยการส่งสารเคมีที่เรียกว่าสารสื่อประสาท หากเซลล์รับได้รับสารเคมีเหล่านี้เพียงพอ มันก็จะตื่นเต้นและส่งสารเคมีของตัวเองไปยังเซลล์อื่น
หน่วยพื้นฐานของสิ่งที่บางครั้งเรียกว่าโครงข่ายประสาทเทียม (ANN) คือโหนดซึ่งแทนที่จะเป็นเซลล์ กลับกลายเป็นฟังก์ชันทางคณิตศาสตร์ เช่นเดียวกับเซลล์ประสาท พวกมันสื่อสารกับโหนดอื่นหากได้รับอินพุตเพียงพอ
นั่นคือจุดสิ้นสุดของความคล้ายคลึงกัน โครงข่ายประสาทเทียมมีโครงสร้างที่ง่ายกว่าสมองมาก โดยมีเลเยอร์ที่กำหนดไว้อย่างประณีต ได้แก่ อินพุต ซ่อน และเอาท์พุต คอลเลกชันของเลเยอร์เหล่านี้เรียกว่าโมเดลพวกเขาเรียนรู้หรือฝึกฝนโดยพยายามซ้ำแล้วซ้ำเล่าเพื่อสร้างผลลัพธ์ที่ใกล้เคียงกับผลลัพธ์ที่ต้องการมากที่สุด (เพิ่มเติมเกี่ยวกับเรื่องนั้นในไม่กี่นาที)
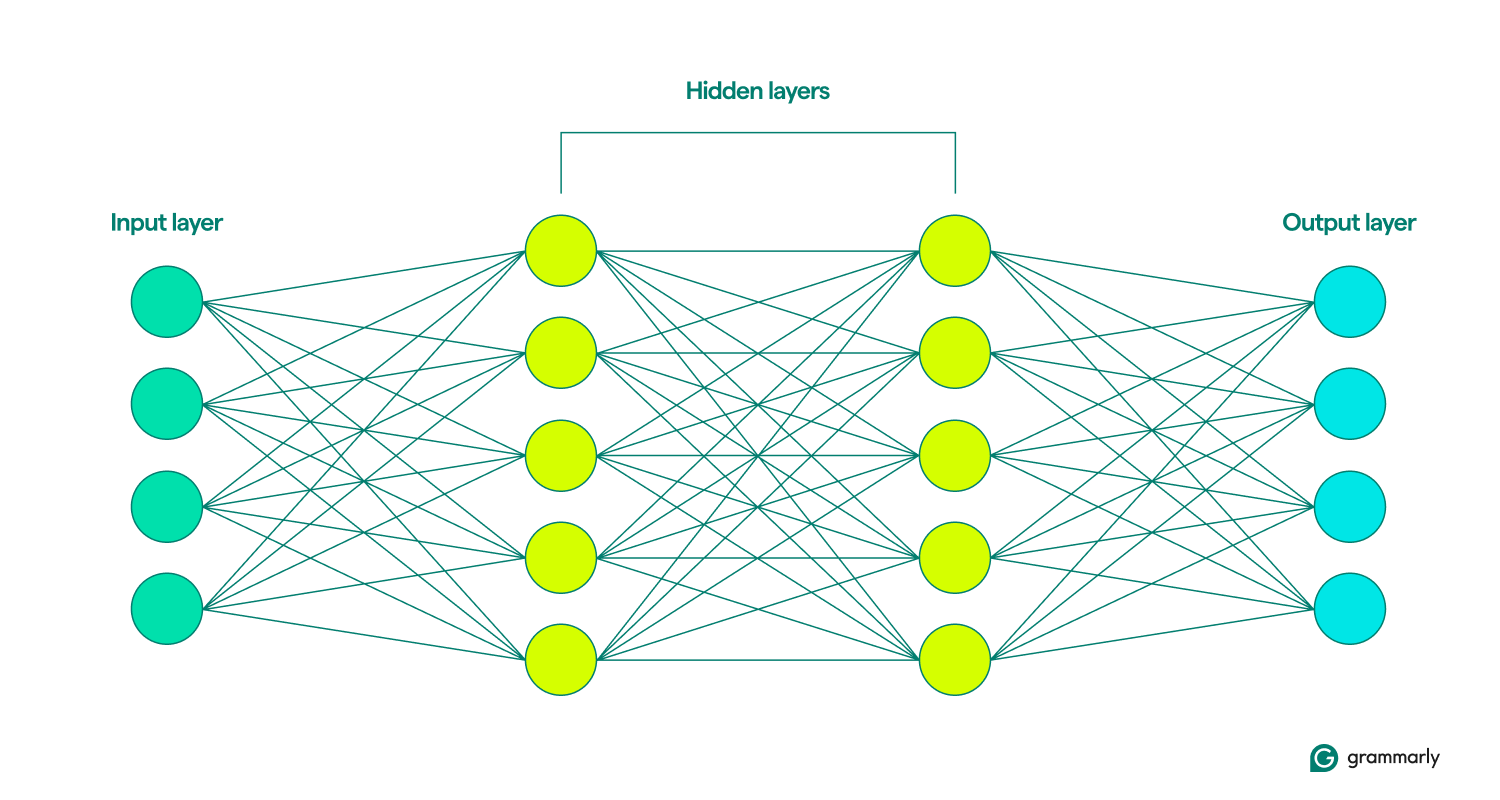
เลเยอร์อินพุตและเอาต์พุตค่อนข้างอธิบายได้ในตัว โครงข่ายประสาทเทียมส่วนใหญ่เกิดขึ้นในเลเยอร์ที่ซ่อนอยู่ เมื่อโหนดถูกเปิดใช้งานโดยอินพุตจากเลเยอร์ก่อนหน้า โหนดจะทำการคำนวณและตัดสินใจว่าจะส่งต่อเอาต์พุตไปยังโหนดในเลเยอร์ถัดไปหรือไม่ เลเยอร์เหล่านี้ได้รับการตั้งชื่อเช่นนี้เพราะผู้ใช้ปลายทางจะมองไม่เห็นการทำงานของพวกมัน แม้ว่าจะมีเทคนิคสำหรับวิศวกรในการดูว่าเกิดอะไรขึ้นในสิ่งที่เรียกว่าเลเยอร์ที่ซ่อนอยู่ก็ตาม
เมื่อโครงข่ายประสาทเทียมมีหลายเลเยอร์ที่ซ่อนอยู่ จะเรียกว่าเครือข่ายการเรียนรู้เชิงลึก โครงข่ายประสาทเทียมเชิงลึกสมัยใหม่มักมีหลายชั้น รวมถึงชั้นย่อยพิเศษที่ทำหน้าที่แตกต่างกันออกไป ตัวอย่างเช่น เลเยอร์ย่อยบางเลเยอร์เพิ่มความสามารถของเครือข่ายในการพิจารณาข้อมูลเชิงบริบทนอกเหนือจากอินพุตที่กำลังวิเคราะห์ทันที
โครงข่ายประสาทเทียมทำงานอย่างไร
ลองนึกถึงวิธีที่เด็กทารกเรียนรู้ พวกเขาลองบางอย่าง ล้มเหลว และลองอีกครั้งด้วยวิธีอื่น การวนซ้ำจะดำเนินต่อไปซ้ำแล้วซ้ำอีกจนกว่าพฤติกรรมเหล่านั้นจะสมบูรณ์แบบ นั่นเป็นวิธีที่โครงข่ายประสาทเทียมเรียนรู้ไม่มากก็น้อยเช่นกัน
ในช่วงเริ่มต้นของการฝึกอบรม โครงข่ายประสาทเทียมจะสุ่มเดา โหนดบนเลเยอร์อินพุตจะสุ่มตัดสินใจว่าโหนดใดในเลเยอร์แรกที่ซ่อนไว้เพื่อเปิดใช้งาน จากนั้นโหนดเหล่านั้นจะสุ่มเปิดใช้งานโหนดในเลเยอร์ถัดไป และต่อๆ ไป จนกว่ากระบวนการสุ่มนี้จะไปถึงเลเยอร์เอาท์พุต (โมเดลภาษาขนาดใหญ่ เช่น GPT-4 มีประมาณ 100 เลเยอร์ โดยมีโหนดหลายหมื่นหรือหลายแสนโหนดในแต่ละเลเยอร์)
เมื่อพิจารณาถึงความสุ่มทั้งหมด โมเดลจะเปรียบเทียบผลลัพธ์—ซึ่งอาจแย่มาก—และหาคำตอบว่ามันผิดแค่ไหน จากนั้นจะปรับการเชื่อมต่อของแต่ละโหนดกับโหนดอื่นๆ โดยเปลี่ยนแนวโน้มที่จะเปิดใช้งานตามอินพุตที่กำหนดไม่มากก็น้อย โดยจะทำเช่นนี้ซ้ำๆ จนกระทั่งผลลัพธ์ใกล้เคียงกับคำตอบที่ต้องการ
แล้วโครงข่ายประสาทเทียมรู้ได้อย่างไรว่าพวกเขากำลังทำอะไรอยู่? แมชชีนเลิร์นนิงสามารถแบ่งได้เป็นแนวทางต่างๆ รวมถึงการเรียนรู้แบบมีผู้ดูแลและแบบไม่มีผู้ดูแล ในการเรียนรู้แบบมีผู้สอน โมเดลจะได้รับการฝึกเกี่ยวกับข้อมูลที่มีป้ายกำกับหรือคำตอบที่ชัดเจน เช่น รูปภาพที่จับคู่กับข้อความอธิบาย อย่างไรก็ตาม การเรียนรู้แบบไม่มีผู้ดูแลเกี่ยวข้องกับการจัดเตรียมโมเดลด้วยข้อมูลที่ไม่มีป้ายกำกับ เพื่อให้สามารถระบุรูปแบบและความสัมพันธ์ได้อย่างอิสระ
สิ่งเสริมทั่วไปสำหรับการฝึกอบรมนี้คือการเรียนรู้แบบเสริมกำลัง ซึ่งแบบจำลองจะปรับปรุงเพื่อตอบสนองต่อคำติชม บ่อยครั้งที่ผู้ประเมินที่เป็นมนุษย์เป็นผู้ให้ข้อมูลนี้ (หากคุณเคยคลิกยกนิ้วโป้งหรือยกนิ้วโป้งลงให้กับคำแนะนำของคอมพิวเตอร์ แสดงว่าคุณมีส่วนช่วยในการเรียนรู้แบบเสริมกำลัง) ถึงกระนั้น ก็มีวิธีต่างๆ สำหรับโมเดลในการเรียนรู้ซ้ำๆ อย่างอิสระเช่นกัน
การคิดว่าเอาต์พุตของโครงข่ายประสาทเทียมเป็นการทำนายนั้นมีความแม่นยำและให้คำแนะนำได้ ไม่ว่าจะเป็นการประเมินความน่าเชื่อถือทางเครดิตหรือการสร้างเพลง โมเดล AI จะทำงานโดยการคาดเดาว่าสิ่งไหนน่าจะถูกต้องที่สุด AI เชิงสร้างสรรค์ เช่น ChatGPT ยกระดับการคาดการณ์ไปอีกขั้น มันทำงานตามลำดับ โดยคาดเดาว่าอะไรจะเกิดขึ้นหลังจากผลลัพธ์ที่เพิ่งสร้างเสร็จ (เราจะอธิบายสาเหตุที่ทำให้เกิดปัญหาในภายหลัง)
โครงข่ายประสาทเทียมสร้างคำตอบได้อย่างไร
เมื่อเครือข่ายได้รับการฝึกอบรมแล้ว เครือข่ายจะประมวลผลข้อมูลที่เห็นเพื่อคาดการณ์การตอบสนองที่ถูกต้องอย่างไร เมื่อคุณพิมพ์ข้อความเตือนเช่น “บอกฉันเกี่ยวกับนางฟ้า” ลงในอินเทอร์เฟซ ChatGPT ChatGPT จะตัดสินใจว่าจะตอบสนองอย่างไร
ขั้นตอนแรกคือให้เลเยอร์อินพุตของโครงข่ายประสาทเทียมแบ่งคำสั่งของคุณออกเป็นข้อมูลชิ้นเล็กๆ ที่เรียกว่าโทเค็นสำหรับเครือข่ายการจดจำรูปภาพ โทเค็นอาจเป็นพิกเซล สำหรับเครือข่ายที่ใช้การประมวลผลภาษาธรรมชาติ (NLP) เช่น ChatGPT โดยทั่วไปโทเค็นจะเป็นคำ ส่วนหนึ่งของคำ หรือวลีที่สั้นมาก
เมื่อเครือข่ายได้ลงทะเบียนโทเค็นในอินพุตแล้ว ข้อมูลนั้นจะถูกส่งผ่านเลเยอร์ที่ซ่อนอยู่ที่ได้รับการฝึกก่อนหน้านี้ โหนดที่ส่งผ่านจากเลเยอร์หนึ่งไปยังเลเยอร์ถัดไปจะวิเคราะห์ส่วนที่ใหญ่ขึ้นและใหญ่ขึ้นของอินพุต ด้วยวิธีนี้ เครือข่าย NLP จึงสามารถตีความทั้งประโยคหรือย่อหน้าได้ในที่สุด ไม่ใช่แค่คำหรือตัวอักษร
ตอนนี้เครือข่ายสามารถเริ่มสร้างการตอบสนองได้ ซึ่งทำหน้าที่เป็นชุดการคาดการณ์แบบคำต่อคำเกี่ยวกับสิ่งที่จะเกิดขึ้นต่อไปโดยพิจารณาจากทุกสิ่งที่ได้รับการฝึกฝนมา
พิจารณาข้อความที่ว่า “เล่าเรื่องนางฟ้าให้ฉันฟังหน่อย” ในการสร้างการตอบสนอง โครงข่ายประสาทเทียมจะวิเคราะห์พรอมต์เพื่อทำนายคำแรกที่น่าจะเป็นไปได้มากที่สุด ตัวอย่างเช่น อาจกำหนดได้ว่ามีโอกาส 80% ที่ "The" จะเป็นตัวเลือกที่ดีที่สุด โอกาส 10% สำหรับ "A" และโอกาส 10% สำหรับ "ครั้งเดียว" จากนั้นจะสุ่มเลือกตัวเลข: หากตัวเลขอยู่ระหว่าง 1 ถึง 8 ระบบจะเลือก “The”; ถ้าเป็น 9 ก็เลือก "A"; และถ้าเป็น 10 ก็จะเลือก "ครั้งเดียว" สมมติว่าตัวเลขสุ่มคือ 4 ซึ่งตรงกับ "The" จากนั้นเครือข่ายจะอัปเดตข้อความแจ้งว่า “เล่าเรื่องเกี่ยวกับนางฟ้าให้ฉันฟังหน่อยสิ The” และทำซ้ำขั้นตอนเพื่อทำนายคำถัดไปที่ตามหลัง “The” วงจรนี้จะดำเนินต่อไป โดยมีการคาดเดาคำศัพท์ใหม่แต่ละครั้งตามข้อความแจ้งที่อัปเดต จนกว่าจะสร้างเรื่องราวที่สมบูรณ์
เครือข่ายที่ต่างกันจะทำให้การคาดการณ์นี้แตกต่างออกไป ตัวอย่างเช่น โมเดลการจดจำรูปภาพอาจพยายามคาดเดาว่าควรติดป้ายกำกับใดให้กับรูปภาพสุนัข และพิจารณาว่ามีความเป็นไปได้ 70% ที่ป้ายกำกับที่ถูกต้องคือ "chocolate Lab" 20% สำหรับ "English Spaniel" และ 10% สำหรับ “โกลเด้น รีทรีฟเวอร์” ในกรณีของการจำแนกประเภท โดยทั่วไป เครือข่ายจะเลือกตัวเลือกที่มีแนวโน้มมากที่สุดมากกว่าการคาดเดาความน่าจะเป็น
ประเภทของโครงข่ายประสาทเทียม
ต่อไปนี้เป็นภาพรวมของโครงข่ายประสาทเทียมประเภทต่างๆ และวิธีการทำงาน

- โครงข่ายประสาทเทียมแบบป้อนไปข้างหน้า (FNN):ในโมเดลเหล่านี้ ข้อมูลจะไหลไปในทิศทางเดียว: จากเลเยอร์อินพุต ผ่านเลเยอร์ที่ซ่อนอยู่ และสุดท้ายไปยังเลเยอร์เอาท์พุต ประเภทแบบจำลองนี้เหมาะที่สุดสำหรับงานคาดการณ์ที่ง่ายกว่า เช่น การตรวจจับการฉ้อโกงบัตรเครดิต
- โครงข่ายประสาทเทียมที่เกิดซ้ำ (RNN):ตรงกันข้ามกับ FNN ตรงที่ RNN จะพิจารณาอินพุตก่อนหน้าเมื่อสร้างการคาดการณ์ สิ่งนี้ทำให้เหมาะสมกับงานการประมวลผลภาษาเนื่องจากการสิ้นสุดประโยคที่สร้างขึ้นเพื่อตอบสนองต่อการแจ้งเตือนนั้นขึ้นอยู่กับว่าประโยคเริ่มต้นอย่างไร
- เครือข่ายหน่วยความจำระยะสั้นระยะยาว (LSTM):LSTM เลือกลืมข้อมูล ซึ่งช่วยให้ทำงานได้อย่างมีประสิทธิภาพมากขึ้น นี่เป็นสิ่งสำคัญสำหรับการประมวลผลข้อความจำนวนมาก ตัวอย่างเช่น การอัปเกรดการแปลด้วยเครื่องประสาทของ Google Translate ในปี 2559 อาศัย LSTM
- เครือข่ายประสาทเทียม (CNN):CNN ทำงานได้ดีที่สุดเมื่อประมวลผลภาพ พวกเขาใช้เลเยอร์แบบหมุนวนเพื่อสแกนภาพทั้งหมดและมองหาคุณสมบัติต่างๆ เช่น เส้นหรือรูปร่าง ซึ่งช่วยให้ CNN สามารถพิจารณาตำแหน่งเชิงพื้นที่ เช่น การกำหนดว่าวัตถุอยู่ที่ครึ่งบนหรือล่างของภาพ และยังช่วยระบุรูปร่างหรือประเภทของวัตถุโดยไม่คำนึงถึงตำแหน่งของวัตถุ
- เครือข่ายปฏิปักษ์ทั่วไป (GAN):GAN มักใช้เพื่อสร้างภาพใหม่ตามคำอธิบายหรือภาพที่มีอยู่ มีโครงสร้างเป็นการแข่งขันระหว่างสองโครงข่ายประสาทเทียม: เครือข่ายตัวสร้างซึ่งพยายามหลอกเครือข่ายผู้เลือกปฏิบัติให้เชื่อว่าอินพุตปลอมมีจริง
- หม้อแปลงไฟฟ้าและเครือข่ายความสนใจ:หม้อแปลงไฟฟ้ามีหน้าที่รับผิดชอบในการเพิ่มความสามารถด้าน AI ในปัจจุบัน โมเดลเหล่านี้รวมเอาสปอตไลต์ที่ตั้งใจไว้ซึ่งช่วยให้พวกเขาสามารถกรองอินพุตเพื่อเน้นไปที่องค์ประกอบที่สำคัญที่สุด และดูว่าองค์ประกอบเหล่านั้นเกี่ยวข้องกันอย่างไร แม้จะข้ามหน้าข้อความก็ตาม Transformers ยังสามารถฝึกฝนข้อมูลจำนวนมหาศาลได้ ดังนั้นโมเดลเช่น ChatGPT และ Gemini จึงเรียกว่าโมเดลภาษาขนาดใหญ่ (LLM)
การประยุกต์ใช้โครงข่ายประสาทเทียม
มีมากเกินไปที่จะแสดงรายการ ดังนั้นนี่คือวิธีต่างๆ ในการใช้โครงข่ายประสาทเทียมในปัจจุบัน โดยเน้นที่ภาษาธรรมชาติ
ความช่วยเหลือด้านการเขียน:Transformers ได้เปลี่ยนแปลงวิธีที่คอมพิวเตอร์ช่วยให้ผู้คนเขียนได้ดีขึ้น เครื่องมือการเขียนของ AI เช่น ไวยากรณ์ เสนอการเขียนประโยคและย่อหน้าใหม่เพื่อปรับปรุงน้ำเสียงและความชัดเจน ประเภทโมเดลนี้ยังได้ปรับปรุงความเร็วและความแม่นยำของคำแนะนำทางไวยากรณ์พื้นฐานอีกด้วย เรียนรู้เพิ่มเติมเกี่ยวกับวิธีที่ Grammarly ใช้ AI
การสร้างเนื้อหา:หากคุณเคยใช้ ChatGPT หรือ DALL-E คุณจะได้พบประสบการณ์ AI เชิงสร้างสรรค์โดยตรง Transformers ได้ปฏิวัติความสามารถของคอมพิวเตอร์ในการสร้างสื่อที่โดนใจมนุษย์ ตั้งแต่นิทานก่อนนอนไปจนถึงการเรนเดอร์สถาปัตยกรรมที่สมจริงเกินจริง
การรู้จำคำพูด:คอมพิวเตอร์เริ่มดีขึ้นทุกวันในการจดจำคำพูดของมนุษย์ ด้วยเทคโนโลยีใหม่ๆ ที่ช่วยให้พวกเขาสามารถพิจารณาบริบทได้มากขึ้น โมเดลมีความแม่นยำมากขึ้นในการจดจำสิ่งที่ผู้พูดตั้งใจจะพูด แม้ว่าเสียงเพียงอย่างเดียวอาจมีการตีความได้หลายอย่างก็ตาม
การวินิจฉัยและการวิจัยทางการแพทย์:โครงข่ายประสาทเทียมมีความเป็นเลิศในการตรวจจับรูปแบบและการจำแนกประเภท ซึ่งมีการใช้กันมากขึ้นเพื่อช่วยให้นักวิจัยและผู้ให้บริการด้านสุขภาพเข้าใจและจัดการกับโรค ตัวอย่างเช่น เรามี AI ต้องขอบคุณส่วนหนึ่งสำหรับการพัฒนาวัคซีนป้องกันโควิด-19 อย่างรวดเร็ว
ความท้าทายและข้อจำกัดของโครงข่ายประสาทเทียม
ต่อไปนี้เป็นข้อมูลสรุปเกี่ยวกับปัญหาบางส่วนที่เกิดขึ้นจากโครงข่ายประสาทเทียม แต่ไม่ใช่ทั้งหมด
อคติ:โครงข่ายประสาทเทียมสามารถเรียนรู้ได้จากสิ่งที่ได้รับการบอกกล่าวเท่านั้น หากมีการเปิดเผยเนื้อหาที่เหยียดเพศหรือเหยียดเชื้อชาติ ผลลัพธ์ก็มีแนวโน้มที่จะเหยียดเพศหรือเหยียดเชื้อชาติเช่นกัน สิ่งนี้สามารถเกิดขึ้นได้ในการแปลจากภาษาที่ไม่ระบุเพศเป็นภาษาที่มีการระบุเพศ โดยที่ทัศนคติแบบเหมารวมยังคงมีอยู่โดยไม่มีการระบุเพศอย่างชัดเจน
การติดตั้งมากเกินไป:โมเดลที่ได้รับการฝึกอย่างไม่เหมาะสมสามารถอ่านข้อมูลที่ได้รับมากเกินไป และประสบปัญหากับอินพุตใหม่ ตัวอย่างเช่น ซอฟต์แวร์จดจำใบหน้าที่ได้รับการฝึกฝนเป็นส่วนใหญ่สำหรับคนบางกลุ่มชาติพันธุ์อาจทำงานได้ไม่ดีกับใบหน้าจากเชื้อชาติอื่น หรือตัวกรองสแปมอาจพลาดเมลขยะหลากหลายรูปแบบ เนื่องจากเน้นไปที่รูปแบบที่เคยเห็นมาก่อนมากเกินไป
อาการประสาทหลอน:AI เจนเนอเรชั่นในปัจจุบันส่วนใหญ่ใช้ความน่าจะเป็นในการเลือกสิ่งที่จะผลิต แทนที่จะเลือกตัวเลือกที่อยู่ในอันดับต้นๆ เสมอไป แนวทางนี้ช่วยให้มีความคิดสร้างสรรค์มากขึ้นและสร้างข้อความที่ดูเป็นธรรมชาติมากขึ้น แต่ก็สามารถนำไปสู่การสร้างข้อความที่เป็นเท็จได้เช่นกัน (นี่คือเหตุผลว่าทำไม LLM ถึงบางครั้งคณิตศาสตร์พื้นฐานผิด) น่าเสียดายที่ภาพหลอนเหล่านี้ตรวจพบได้ยาก เว้นแต่คุณจะรู้ดีขึ้นหรือตรวจสอบข้อเท็จจริงกับแหล่งข้อมูลอื่น
การตีความ:มักเป็นไปไม่ได้ที่จะทราบแน่ชัดว่าโครงข่ายประสาทเทียมทำนายได้อย่างไร แม้ว่าสิ่งนี้อาจทำให้หงุดหงิดจากมุมมองของคนที่พยายามปรับปรุงโมเดล แต่ก็อาจส่งผลตามมาเช่นกัน เนื่องจาก AI พึ่งพามากขึ้นในการตัดสินใจที่ส่งผลกระทบอย่างมากต่อชีวิตของผู้คน โมเดลบางรุ่นที่ใช้ในปัจจุบันไม่ได้ขึ้นอยู่กับโครงข่ายประสาทเทียมอย่างแม่นยำ เนื่องจากผู้สร้างต้องการตรวจสอบและทำความเข้าใจทุกขั้นตอนของกระบวนการ
ทรัพย์สินทางปัญญา:หลายคนเชื่อว่า LLM ละเมิดลิขสิทธิ์โดยการรวมงานเขียนและงานศิลปะอื่นๆ โดยไม่ได้รับอนุญาต แม้ว่าโมเดลเหล่านี้มักจะไม่ทำซ้ำผลงานที่มีลิขสิทธิ์โดยตรง แต่โมเดลเหล่านี้สร้างภาพหรือถ้อยคำที่อาจได้มาจากศิลปินคนใดคนหนึ่ง หรือแม้แต่สร้างผลงานในรูปแบบที่โดดเด่นของศิลปินเมื่อได้รับแจ้ง
การใช้พลังงาน:การฝึกอบรมและการใช้งานโมเดลหม้อแปลงทั้งหมดนี้ใช้พลังงานจำนวนมหาศาล ในความเป็นจริง ภายในไม่กี่ปี AI อาจใช้พลังงานได้มากเท่ากับสวีเดนหรืออาร์เจนตินา สิ่งนี้เน้นย้ำถึงความสำคัญที่เพิ่มขึ้นในการพิจารณาแหล่งพลังงานและประสิทธิภาพในการพัฒนา AI
อนาคตของโครงข่ายประสาทเทียม
การทำนายอนาคตของ AI เป็นเรื่องยากอย่างฉาวโฉ่ ในปี 1970 นักวิจัยด้าน AI ชั้นนำคนหนึ่งคาดการณ์ว่า “ภายในสามถึงแปดปี เราจะมีเครื่องจักรที่มีความฉลาดโดยทั่วไปของมนุษย์โดยเฉลี่ย” (เรายังไม่ใกล้เคียงกับปัญญาประดิษฐ์ทั่วไป (AGI) มากนัก อย่างน้อยคนส่วนใหญ่ก็ไม่คิดเช่นนั้น)
อย่างไรก็ตาม เราสามารถชี้ให้เห็นแนวโน้มบางประการที่ต้องระวังได้ โมเดลที่มีประสิทธิภาพมากขึ้นจะลดการใช้พลังงานและเรียกใช้โครงข่ายประสาทเทียมที่มีประสิทธิภาพมากขึ้นบนอุปกรณ์เช่นสมาร์ทโฟนโดยตรง เทคนิคการฝึกแบบใหม่ช่วยให้คาดการณ์ได้มีประโยชน์มากขึ้นโดยใช้ข้อมูลการฝึกน้อยลง ความก้าวหน้าด้านการตีความอาจเพิ่มความไว้วางใจและปูทางใหม่สำหรับการปรับปรุงเอาต์พุตของโครงข่ายประสาทเทียม ในที่สุด การรวมคอมพิวเตอร์ควอนตัมและโครงข่ายประสาทเทียมอาจนำไปสู่นวัตกรรมที่เราทำได้เพียงแค่จินตนาการเท่านั้น
บทสรุป
โครงข่ายประสาทเทียมที่ได้รับแรงบันดาลใจจากโครงสร้างและการทำงานของสมองมนุษย์ ถือเป็นพื้นฐานของปัญญาประดิษฐ์สมัยใหม่ พวกเขาเป็นเลิศในงานการจดจำรูปแบบและการทำนาย ซึ่งเป็นรากฐานของแอปพลิเคชัน AI มากมายในปัจจุบัน ตั้งแต่การรู้จำรูปภาพและคำพูดไปจนถึงการประมวลผลภาษาธรรมชาติ ด้วยความก้าวหน้าทางสถาปัตยกรรมและเทคนิคการฝึกอบรม โครงข่ายประสาทเทียมยังคงขับเคลื่อนการปรับปรุงขีดความสามารถของ AI อย่างมีนัยสำคัญ
แม้จะมีศักยภาพ แต่โครงข่ายประสาทเทียมก็เผชิญกับความท้าทาย เช่น อคติ การติดตั้งมากเกินไป และการใช้พลังงานสูง การแก้ไขปัญหาเหล่านี้ถือเป็นสิ่งสำคัญเนื่องจาก AI มีการพัฒนาอย่างต่อเนื่อง เมื่อมองไปข้างหน้า นวัตกรรมในด้านประสิทธิภาพของโมเดล การตีความได้ และการบูรณาการกับคอมพิวเตอร์ควอนตัม สัญญาว่าจะขยายความเป็นไปได้ของโครงข่ายประสาทเทียม ซึ่งอาจนำไปสู่การใช้งานที่เปลี่ยนแปลงมากยิ่งขึ้น