
ข้อมูลพื้นฐานเกี่ยวกับโครงข่ายประสาทเทียมที่เกิดซ้ำ: สิ่งที่คุณต้องรู้
เผยแพร่แล้ว: 2024-09-19เครือข่ายประสาทที่เกิดซ้ำ (RNN) เป็นวิธีการสำคัญในขอบเขตของการวิเคราะห์ข้อมูล การเรียนรู้ของเครื่อง (ML) และการเรียนรู้เชิงลึก บทความนี้มีจุดมุ่งหมายเพื่อสำรวจ RNN และให้รายละเอียดเกี่ยวกับฟังก์ชัน แอปพลิเคชัน ตลอดจนข้อดีและข้อเสียภายในบริบทที่กว้างขึ้นของการเรียนรู้เชิงลึก
สารบัญ
อาร์เอ็นเอ็นคืออะไร?
RNN ทำงานอย่างไร
ประเภทของ RNN
RNN กับหม้อแปลงและ CNN
การประยุกต์ใช้ RNN
ข้อดี
ข้อเสีย
โครงข่ายประสาทเทียมที่เกิดซ้ำคืออะไร?
โครงข่ายประสาทที่เกิดซ้ำคือโครงข่ายประสาทเชิงลึกที่สามารถประมวลผลข้อมูลตามลำดับโดยการรักษาหน่วยความจำภายใน ทำให้สามารถติดตามอินพุตในอดีตเพื่อสร้างเอาต์พุตได้ RNN เป็นองค์ประกอบพื้นฐานของการเรียนรู้เชิงลึกและเหมาะอย่างยิ่งสำหรับงานที่เกี่ยวข้องกับข้อมูลตามลำดับ
“การเกิดซ้ำ” ใน “โครงข่ายประสาทเทียมที่เกิดซ้ำ” หมายถึงวิธีที่โมเดลรวมข้อมูลจากอินพุตในอดีตเข้ากับอินพุตปัจจุบัน ข้อมูลจากอินพุตเก่าจะถูกจัดเก็บไว้ในหน่วยความจำภายในที่เรียกว่า "สถานะที่ซ่อนอยู่" มันเกิดขึ้นอีก โดยป้อนการคำนวณก่อนหน้านี้กลับเข้าไปในตัวมันเองเพื่อสร้างกระแสข้อมูลอย่างต่อเนื่อง
มาสาธิตด้วยตัวอย่าง: สมมติว่าเราต้องการใช้ RNN เพื่อตรวจจับความรู้สึก (ทั้งเชิงบวกหรือเชิงลบ) ของประโยค “เขากินพายอย่างมีความสุข” RNN จะประมวลผลคำheอัปเดตสถานะที่ซ่อนอยู่เพื่อรวมคำนั้น จากนั้นจึงไปกินรวมกับสิ่งที่เรียนรู้จากเขาและต่อ ๆ ไปในแต่ละคำจนกว่าประโยคจะเสร็จสิ้น หากมองจากมุมมอง มนุษย์ที่อ่านประโยคนี้จะปรับปรุงความเข้าใจในทุกคำ เมื่อพวกเขาอ่านและเข้าใจประโยคทั้งหมดแล้ว มนุษย์สามารถพูดได้ว่าประโยคนั้นเป็นเชิงบวกหรือเชิงลบ กระบวนการทำความเข้าใจของมนุษย์คือสิ่งที่สถานะที่ซ่อนอยู่พยายามประมาณ
RNN เป็นหนึ่งในโมเดลการเรียนรู้เชิงลึกพื้นฐาน พวกเขาทำงานได้ดีมากกับงานการประมวลผลภาษาธรรมชาติ (NLP) แม้ว่าหม้อแปลงจะเข้ามาแทนที่ก็ตาม หม้อแปลงไฟฟ้าเป็นสถาปัตยกรรมเครือข่ายประสาทขั้นสูงที่ปรับปรุงประสิทธิภาพของ RNN เช่น การประมวลผลข้อมูลแบบขนาน และสามารถค้นพบความสัมพันธ์ระหว่างคำที่อยู่ห่างไกลกันในข้อความต้นฉบับ (โดยใช้กลไกความสนใจ) อย่างไรก็ตาม RNN ยังคงมีประโยชน์สำหรับข้อมูลอนุกรมเวลาและสำหรับสถานการณ์ที่แบบจำลองที่เรียบง่ายกว่าก็เพียงพอแล้ว
RNN ทำงานอย่างไร
เพื่ออธิบายรายละเอียดวิธีการทำงานของ RNN ให้กลับไปที่งานตัวอย่างก่อนหน้านี้: จำแนกความรู้สึกของประโยค “เขากินพายอย่างมีความสุข”
เราเริ่มต้นด้วย RNN ที่ผ่านการฝึกอบรมซึ่งยอมรับการป้อนข้อความและส่งกลับเอาต์พุตไบนารี (1 แสดงถึงค่าบวกและ 0 แสดงถึงค่าลบ) ก่อนที่จะให้อินพุตแก่โมเดล สถานะที่ซ่อนอยู่จะเป็นสถานะทั่วไป ซึ่งเรียนรู้จากกระบวนการฝึกอบรม แต่ยังไม่เฉพาะเจาะจงกับอินพุต
คำแรกเขาถูกส่งผ่านไปยังโมเดล ภายใน RNN สถานะที่ซ่อนอยู่จะได้รับการอัปเดต (เป็นสถานะที่ซ่อนอยู่ h1) เพื่อรวมคำว่าHeจากนั้น คำว่าateจะถูกส่งผ่านไปยัง RNN และ h1 จะได้รับการอัปเดต (เป็น h2) เพื่อรวมคำใหม่นี้ไว้ด้วย กระบวนการนี้จะเกิดขึ้นซ้ำจนกว่าจะส่งคำสุดท้ายเข้าไป สถานะที่ซ่อนอยู่ (h4) ได้รับการอัปเดตเพื่อรวมคำสุดท้าย จากนั้นสถานะที่ซ่อนอยู่ที่อัปเดตจะถูกนำมาใช้เพื่อสร้าง 0 หรือ 1
ต่อไปนี้คือการแสดงภาพว่ากระบวนการ RNN ทำงานอย่างไร:
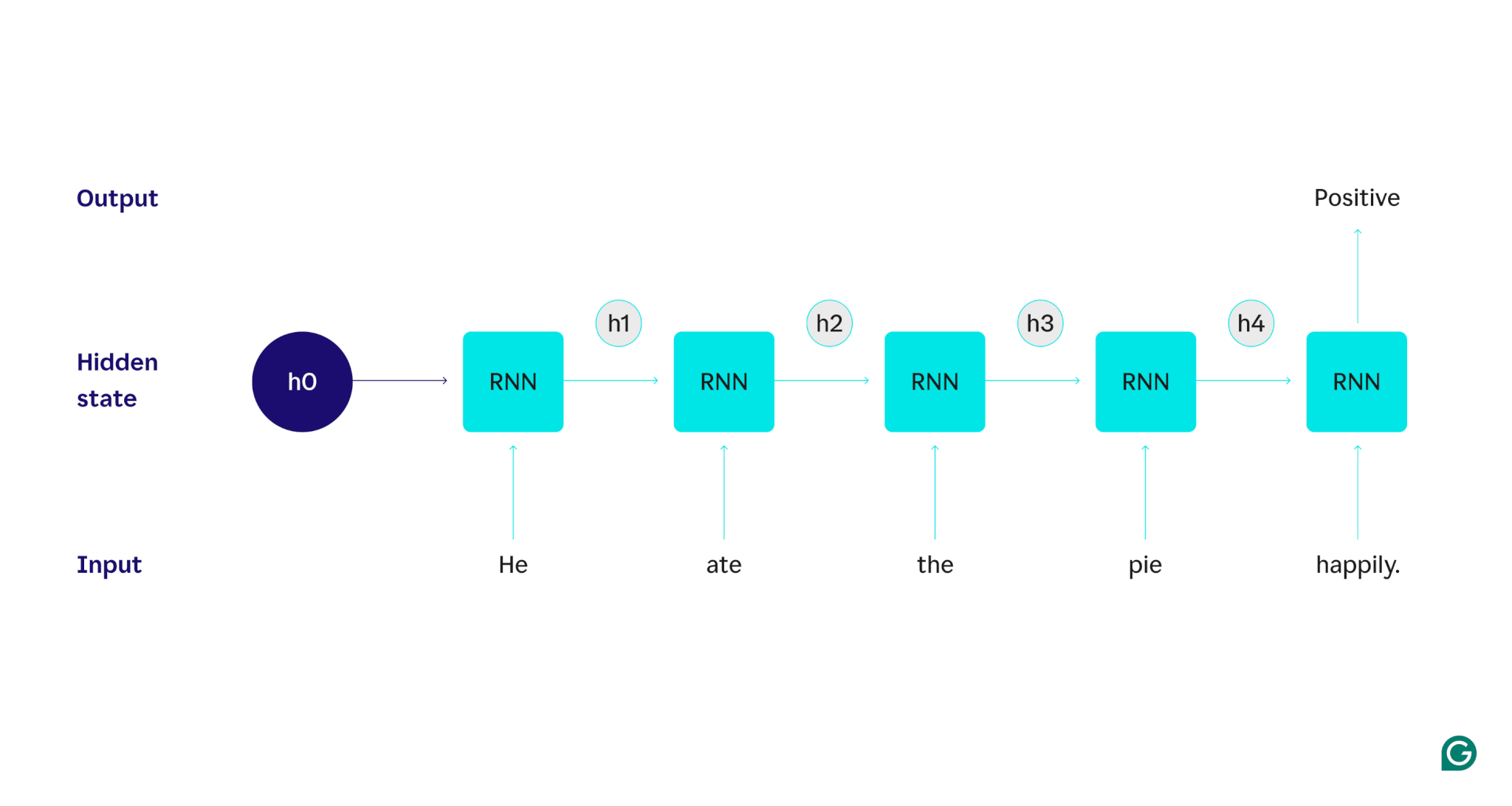
การเกิดขึ้นซ้ำนั้นเป็นหัวใจหลักของ RNN แต่มีข้อควรพิจารณาอื่นๆ อีกสองสามประการ:
- การฝังข้อความ:RNN ไม่สามารถประมวลผลข้อความได้โดยตรง เนื่องจากใช้งานได้กับการแสดงตัวเลขเท่านั้น ข้อความต้องถูกแปลงเป็นการฝังก่อนจึงจะสามารถประมวลผลโดย RNN ได้
- การสร้างเอาต์พุต:RNN จะสร้างเอาต์พุตในแต่ละขั้นตอน อย่างไรก็ตาม ผลลัพธ์อาจไม่แม่นยำมากนักจนกว่าข้อมูลต้นฉบับส่วนใหญ่จะได้รับการประมวลผล ตัวอย่างเช่น หลังจากประมวลผลเฉพาะส่วน "He ate" ของประโยคแล้ว RNN อาจไม่แน่ใจว่าสิ่งนี้แสดงถึงความรู้สึกเชิงบวกหรือเชิงลบ เพราะ "He ate" อาจมองว่าเป็นกลาง หลังจากประมวลผลประโยคเต็มแล้วเท่านั้น ผลลัพธ์ของ RNN จึงแม่นยำ
- การฝึกอบรม RNN:RNN จะต้องได้รับการฝึกอบรมเพื่อทำการวิเคราะห์ความรู้สึกอย่างถูกต้อง การฝึกอบรมเกี่ยวข้องกับการใช้ตัวอย่างที่มีป้ายกำกับมากมาย (เช่น "เขากินพายด้วยความโกรธ" ซึ่งระบุว่าเป็นเชิงลบ) เรียกใช้ตัวอย่างผ่าน RNN และปรับแบบจำลองตามระยะห่างจากการคาดการณ์ กระบวนการนี้จะตั้งค่าเริ่มต้นและกลไกการเปลี่ยนแปลงสำหรับสถานะที่ซ่อนอยู่ ช่วยให้ RNN เรียนรู้ว่าคำใดมีความสำคัญสำหรับการติดตามตลอดอินพุต
ประเภทของโครงข่ายประสาทเทียมที่เกิดซ้ำ
RNN มีหลายประเภท แต่ละประเภทมีโครงสร้างและการใช้งานที่แตกต่างกันไป RNN พื้นฐานแตกต่างกันไปตามขนาดของอินพุตและเอาต์พุต RNN ขั้นสูง เช่น เครือข่ายหน่วยความจำระยะสั้นระยะยาว (LSTM) กล่าวถึงข้อจำกัดบางประการของ RNN พื้นฐาน
RNN พื้นฐาน
RNN แบบหนึ่งต่อหนึ่ง:RNN นี้รับอินพุตที่มีความยาวหนึ่งและส่งกลับเอาต์พุตที่มีความยาวหนึ่ง ดังนั้นจึงไม่มีการเกิดซ้ำจริง ทำให้เป็นโครงข่ายประสาทเทียมมาตรฐานแทนที่จะเป็น RNN ตัวอย่างของ RNN แบบหนึ่งต่อหนึ่งจะเป็นตัวแยกประเภทรูปภาพ โดยที่อินพุตเป็นรูปภาพเดียวและเอาต์พุตเป็นป้ายกำกับ (เช่น "bird")
RNN แบบหนึ่งต่อกลุ่ม:RNN นี้รับอินพุตที่มีความยาวหนึ่งและส่งกลับเอาต์พุตแบบหลายส่วน ตัวอย่างเช่น ในงานบรรยายภาพ ข้อมูลเข้าคือภาพเดียว และผลลัพธ์คือลำดับของคำที่อธิบายภาพ (เช่น "นกข้ามแม่น้ำในวันที่แดดจ้า")
RNN หลายต่อหนึ่ง:RNN นี้รับอินพุตหลายส่วน (เช่น ประโยค ชุดรูปภาพ หรือข้อมูลอนุกรมเวลา) และส่งกลับเอาต์พุตที่มีความยาวหนึ่งรายการ ตัวอย่างเช่น ตัวแยกประเภทความรู้สึกของประโยค (เช่นเดียวกับที่เราพูดถึง) โดยที่อินพุตเป็นประโยคและเอาต์พุตเป็นป้ายกำกับความรู้สึกเดียว (ไม่ว่าจะเป็นเชิงบวกหรือเชิงลบ)
RNN แบบหลายต่อกลุ่ม:RNN นี้รับอินพุตแบบหลายส่วนและส่งกลับเอาต์พุตแบบหลายส่วน ตัวอย่างคือโมเดลการรู้จำเสียง โดยที่อินพุตคือชุดของรูปคลื่นเสียง และเอาต์พุตคือลำดับของคำที่แสดงถึงเนื้อหาที่พูด
RNN ขั้นสูง: หน่วยความจำระยะสั้นระยะยาว (LSTM)
เครือข่ายหน่วยความจำระยะสั้นแบบยาวได้รับการออกแบบมาเพื่อแก้ไขปัญหาที่สำคัญกับ RNN มาตรฐาน: เครือข่ายจะลืมข้อมูลเมื่ออินพุตยาว ใน RNN มาตรฐาน สถานะที่ซ่อนอยู่จะมีน้ำหนักอย่างมากต่อส่วนล่าสุดของอินพุต ในการป้อนข้อมูลที่มีความยาวหลายพันคำ RNN จะลืมรายละเอียดที่สำคัญจากประโยคเปิด LSTM มีสถาปัตยกรรมพิเศษเพื่อแก้ไขปัญหาการลืมนี้ พวกเขามีโมดูลที่เลือกและเลือกข้อมูลที่จะจดจำและลืมอย่างชัดเจน ข้อมูลล่าสุดแต่ไร้ประโยชน์จะถูกลืม ในขณะที่ข้อมูลเก่าแต่เกี่ยวข้องจะถูกเก็บไว้ ด้วยเหตุนี้ LSTM จึงพบเห็นได้ทั่วไปมากกว่า RNN มาตรฐานอย่างมาก โดยจะทำงานได้ดีกว่าในงานที่ซับซ้อนหรืองานยาวเท่านั้น อย่างไรก็ตาม สิ่งเหล่านี้ไม่ได้สมบูรณ์แบบเนื่องจากพวกเขายังคงเลือกที่จะลืมสิ่งของต่างๆ

RNN กับหม้อแปลงและ CNN
โมเดลการเรียนรู้เชิงลึกทั่วไปอีกสองโมเดลคือโครงข่ายประสาทเทียม (CNN) และหม้อแปลงไฟฟ้า พวกเขาแตกต่างกันอย่างไร?
RNN กับหม้อแปลง
ทั้ง RNN และหม้อแปลงถูกใช้อย่างมากใน NLP อย่างไรก็ตาม มีความแตกต่างกันอย่างมากในด้านสถาปัตยกรรมและวิธีการประมวลผลอินพุต
สถาปัตยกรรมและการประมวลผล
- RNN:RNN ประมวลผลอินพุตตามลำดับ ครั้งละหนึ่งคำ โดยคงสถานะที่ซ่อนอยู่ซึ่งนำข้อมูลจากคำก่อนหน้า ลักษณะที่เป็นลำดับนี้หมายความว่า RNN สามารถต่อสู้กับการพึ่งพาในระยะยาวได้เนื่องจากการลืม ซึ่งข้อมูลก่อนหน้านี้อาจสูญหายได้เมื่อลำดับดำเนินไป
- Transformers:Transformers ใช้กลไกที่เรียกว่า "ความสนใจ" เพื่อประมวลผลอินพุต ต่างจาก RNN ตรงที่หม้อแปลงจะมองลำดับทั้งหมดพร้อมกัน โดยเปรียบเทียบแต่ละคำกับคำอื่นๆ แนวทางนี้ช่วยขจัดปัญหาการลืม เนื่องจากแต่ละคำสามารถเข้าถึงบริบทอินพุตทั้งหมดได้โดยตรง หม้อแปลงไฟฟ้าได้แสดงให้เห็นประสิทธิภาพที่เหนือกว่าในงานต่างๆ เช่น การสร้างข้อความและการวิเคราะห์ความรู้สึก เนื่องจากความสามารถนี้
การทำให้ขนานกัน
- RNN:ลักษณะตามลำดับของ RNN หมายความว่าโมเดลจะต้องประมวลผลอินพุตส่วนหนึ่งให้เสร็จสิ้นก่อนที่จะไปยังส่วนถัดไป ขั้นตอนนี้ใช้เวลานานมาก เนื่องจากแต่ละขั้นตอนจะขึ้นอยู่กับขั้นตอนก่อนหน้า
- หม้อแปลงไฟฟ้า:หม้อแปลงไฟฟ้าประมวลผลทุกส่วนของอินพุตพร้อมกัน เนื่องจากสถาปัตยกรรมไม่ได้ขึ้นอยู่กับสถานะที่ซ่อนอยู่ตามลำดับ ทำให้สามารถขนานกันและมีประสิทธิภาพมากขึ้น ตัวอย่างเช่น หากการประมวลผลประโยคใช้เวลา 5 วินาทีต่อคำ RNN จะใช้เวลา 25 วินาทีสำหรับประโยคที่มี 5 คำ ในขณะที่หม้อแปลงไฟฟ้าจะใช้เวลาเพียง 5 วินาทีเท่านั้น
ผลกระทบในทางปฏิบัติ
เนื่องจากข้อดีเหล่านี้ หม้อแปลงไฟฟ้าจึงถูกนำมาใช้กันอย่างแพร่หลายในอุตสาหกรรม อย่างไรก็ตาม RNN โดยเฉพาะเครือข่ายหน่วยความจำระยะสั้น (LSTM) ระยะยาว ยังคงมีประสิทธิภาพสำหรับงานที่ง่ายกว่าหรือเมื่อต้องรับมือกับลำดับที่สั้นกว่า LSTM มักถูกใช้เป็นโมดูลจัดเก็บข้อมูลหน่วยความจำที่สำคัญในสถาปัตยกรรมแมชชีนเลิร์นนิงขนาดใหญ่
RNN กับ CNN
โดยพื้นฐานแล้ว CNN นั้นแตกต่างจาก RNN ในแง่ของข้อมูลที่จัดการและกลไกการดำเนินงาน
ชนิดข้อมูล
- RNN:RNN ได้รับการออกแบบมาสำหรับข้อมูลตามลำดับ เช่น ข้อความหรืออนุกรมเวลา โดยที่ลำดับของจุดข้อมูลมีความสำคัญ
- CNN:CNN ใช้สำหรับข้อมูลเชิงพื้นที่เป็นหลัก เช่น รูปภาพ โดยเน้นที่ความสัมพันธ์ระหว่างจุดข้อมูลที่อยู่ติดกัน (เช่น สี ความเข้ม และคุณสมบัติอื่นๆ ของพิกเซลในรูปภาพจะสัมพันธ์อย่างใกล้ชิดกับคุณสมบัติของจุดข้อมูลอื่นๆ ที่อยู่ใกล้เคียง พิกเซล)
การดำเนินการ
- RNN:RNN จะรักษาหน่วยความจำของลำดับทั้งหมด ทำให้เหมาะสำหรับงานที่บริบทและลำดับมีความสำคัญ
- CNN:CNN ทำงานโดยดูที่บริเวณท้องถิ่นของอินพุต (เช่น พิกเซลข้างเคียง) ผ่านเลเยอร์แบบหมุนวน ทำให้มีประสิทธิภาพในการประมวลผลภาพสูง แต่มีประสิทธิภาพน้อยกว่าสำหรับข้อมูลตามลำดับ ซึ่งการพึ่งพาในระยะยาวอาจมีความสำคัญมากกว่า
ความยาวอินพุต
- RNN:RNN สามารถจัดการลำดับอินพุตที่มีความยาวผันแปรได้ด้วยโครงสร้างที่กำหนดน้อยกว่า ทำให้มีความยืดหยุ่นสำหรับประเภทข้อมูลตามลำดับที่แตกต่างกัน
- CNN:โดยทั่วไปแล้ว CNN ต้องการอินพุตที่มีขนาดคงที่ ซึ่งอาจเป็นข้อจำกัดในการจัดการลำดับที่มีความยาวผันแปรได้
การประยุกต์ใช้ RNN
RNN ถูกนำมาใช้กันอย่างแพร่หลายในด้านต่างๆ เนื่องจากความสามารถในการจัดการข้อมูลตามลำดับได้อย่างมีประสิทธิภาพ
การประมวลผลภาษาธรรมชาติ
ภาษาเป็นรูปแบบของข้อมูลที่เรียงลำดับกันสูง ดังนั้น RNN จึงทำงานได้ดีในงานด้านภาษา RNN เป็นเลิศในงานต่างๆ เช่น การสร้างข้อความ การวิเคราะห์ความรู้สึก การแปล และการสรุป ด้วยไลบรารีอย่าง PyTorch ผู้ใช้สามารถสร้างแชทบอตแบบง่ายๆ โดยใช้ RNN และตัวอย่างข้อความขนาดสองสามกิกะไบต์
การรู้จำเสียง
การรู้จำเสียงเป็นภาษาหลักและมีความต่อเนื่องสูงเช่นกัน สามารถใช้ RNN แบบกลุ่มต่อกลุ่มสำหรับงานนี้ ในแต่ละขั้นตอน RNN จะใช้สถานะที่ซ่อนอยู่ก่อนหน้าและรูปคลื่น โดยส่งออกคำที่เกี่ยวข้องกับรูปคลื่น (ขึ้นอยู่กับบริบทของประโยคจนถึงจุดนั้น)
ยุคแห่งดนตรี
ดนตรีก็มีความต่อเนื่องสูงเช่นกัน จังหวะก่อนหน้าในเพลงมีอิทธิพลอย่างมากต่อจังหวะในอนาคต RNN แบบกลุ่มต่อกลุ่มอาจใช้จังหวะเริ่มต้นสองสามจังหวะเป็นอินพุต จากนั้นจึงสร้างจังหวะเพิ่มเติมตามที่ผู้ใช้ต้องการ หรืออาจป้อนข้อความ เช่น "เมโลดิกแจ๊ส" และส่งเอาต์พุตการประมาณจังหวะแจ๊สไพเราะที่ดีที่สุด
ข้อดีของ RNN
แม้ว่า RNN จะไม่ใช่โมเดล NLP โดยพฤตินัยอีกต่อไป แต่ก็ยังมีประโยชน์บางประการเนื่องจากปัจจัยบางประการ
ประสิทธิภาพตามลำดับที่ดี
RNN โดยเฉพาะ LSTM ทำงานได้ดีกับข้อมูลตามลำดับ LSTM ซึ่งมีสถาปัตยกรรมหน่วยความจำเฉพาะทาง สามารถจัดการอินพุตตามลำดับที่ยาวและซับซ้อนได้ ตัวอย่างเช่น Google Translate เคยทำงานบนโมเดล LSTM ก่อนยุคของหม้อแปลงไฟฟ้า สามารถใช้ LSTM เพื่อเพิ่มโมดูลหน่วยความจำเชิงกลยุทธ์ได้เมื่อรวมเครือข่ายที่ใช้หม้อแปลงไฟฟ้าเข้าด้วยกันเพื่อสร้างสถาปัตยกรรมขั้นสูงขึ้น
รุ่นที่เล็กกว่าและเรียบง่ายกว่า
RNN มักจะมีพารามิเตอร์โมเดลน้อยกว่าหม้อแปลง ชั้นความสนใจและฟีดไปข้างหน้าในหม้อแปลงต้องการพารามิเตอร์เพิ่มเติมเพื่อให้ทำงานได้อย่างมีประสิทธิภาพ สามารถฝึก RNN ได้โดยใช้ตัวอย่างการรันและข้อมูลที่น้อยลง ทำให้มีประสิทธิภาพมากขึ้นสำหรับกรณีการใช้งานที่ง่ายขึ้น ส่งผลให้ได้โมเดลที่มีขนาดเล็กลง ราคาไม่แพง และมีประสิทธิภาพมากขึ้นโดยที่ยังคงมีประสิทธิภาพเพียงพอ
ข้อเสียของ RNN
RNN ไม่ได้รับความนิยมด้วยเหตุผล: Transformers แม้จะมีขนาดที่ใหญ่กว่าและกระบวนการฝึกอบรม แต่ก็ไม่มีข้อบกพร่องเช่นเดียวกับ RNN
หน่วยความจำมีจำกัด
สถานะที่ซ่อนอยู่ใน RNN มาตรฐานทำให้อินพุตล่าสุดมีอคติอย่างมาก ทำให้ยากต่อการรักษาการขึ้นต่อกันในระยะยาว งานที่มีอินพุตยาวทำงานได้ไม่ดีกับ RNN แม้ว่า LSTM มีเป้าหมายที่จะแก้ไขปัญหานี้ แต่ก็เพียงบรรเทาและไม่ได้แก้ไขทั้งหมดเท่านั้น งาน AI จำนวนมากจำเป็นต้องจัดการกับอินพุตที่ยาว ทำให้หน่วยความจำที่จำกัดกลายเป็นข้อเสียเปรียบที่สำคัญ
ขนานกันไม่ได้
การรันโมเดล RNN แต่ละครั้งจะขึ้นอยู่กับเอาท์พุตของการรันครั้งก่อน โดยเฉพาะสถานะที่ซ่อนอยู่ที่อัปเดต ด้วยเหตุนี้ โมเดลทั้งหมดจึงต้องได้รับการประมวลผลตามลำดับสำหรับแต่ละส่วนของอินพุต ในทางตรงกันข้าม หม้อแปลงและ CNN สามารถประมวลผลอินพุตทั้งหมดพร้อมกันได้ ซึ่งช่วยให้สามารถประมวลผลแบบขนานกับ GPU หลายตัวได้ ทำให้การคำนวณเร็วขึ้นอย่างมาก การขาดความสามารถในการขนานกันของ RNN ส่งผลให้การฝึกอบรมช้าลง การสร้างเอาต์พุตช้าลง และข้อมูลจำนวนสูงสุดที่สามารถเรียนรู้ได้ลดลง
ปัญหาการไล่ระดับสี
การฝึกอบรม RNN อาจเป็นเรื่องที่ท้าทาย เนื่องจากกระบวนการ backpropagation ต้องผ่านแต่ละขั้นตอนการป้อนข้อมูล (backpropagation ตามเวลา) เนื่องจากต้องใช้เวลาหลายขั้นตอน การไล่ระดับสีซึ่งบ่งชี้ว่าควรปรับพารามิเตอร์แต่ละโมเดลอย่างไร อาจลดลงและไม่มีประสิทธิภาพ การไล่ระดับสีอาจล้มเหลวได้โดยการหายไป ซึ่งหมายความว่าพวกมันจะเล็กมากและโมเดลจะไม่สามารถใช้มันเพื่อเรียนรู้หรือโดยการระเบิดได้อีกต่อไป โดยที่การไล่ระดับสีจะมีขนาดใหญ่มากและโมเดลเกินการอัปเดต ทำให้โมเดลใช้งานไม่ได้ การสร้างสมดุลให้กับปัญหาเหล่านี้เป็นเรื่องยาก