
การเรียนรู้ของเครื่อง: ทุกสิ่งที่คุณควรรู้
เผยแพร่แล้ว: 2024-05-23การเรียนรู้ของเครื่อง (ML) ได้กลายเป็นหนึ่งในเทคโนโลยีที่สำคัญที่สุดในยุคของเราอย่างรวดเร็ว รองรับผลิตภัณฑ์ต่างๆ เช่น ChatGPT, คำแนะนำของ Netflix, รถยนต์ไร้คนขับ และตัวกรองสแปมอีเมล เพื่อช่วยให้คุณเข้าใจเทคโนโลยีที่แพร่หลายนี้ คู่มือนี้ครอบคลุมว่า ML คืออะไร (และไม่ใช่อะไร) ทำงานอย่างไร และผลกระทบของมัน
สารบัญ
- การเรียนรู้ของเครื่องคืออะไร?
- แมชชีนเลิร์นนิงทำงานอย่างไร
- ประเภทของการเรียนรู้ของเครื่อง
- การใช้งาน
- ข้อดี
- ข้อเสีย
- อนาคตของม.ล
- บทสรุป
การเรียนรู้ของเครื่องคืออะไร?
เพื่อทำความเข้าใจการเรียนรู้ของเครื่อง เราต้องเข้าใจปัญญาประดิษฐ์ (AI) ก่อน แม้ว่าทั้งสองจะใช้แทนกันได้ แต่ก็ไม่เหมือนกัน ปัญญาประดิษฐ์เป็นทั้งเป้าหมายและสาขาวิชา เป้าหมายคือการสร้างระบบคอมพิวเตอร์ที่มีความสามารถในการคิดและการใช้เหตุผลในระดับมนุษย์ (หรือแม้แต่เหนือมนุษย์) AI ยังประกอบด้วยวิธีการต่างๆ มากมายเพื่อไปถึงจุดนั้น การเรียนรู้ของเครื่องเป็นหนึ่งในวิธีการเหล่านี้ ทำให้เป็นส่วนหนึ่งของปัญญาประดิษฐ์
การเรียนรู้ของเครื่องมุ่งเน้นไปที่การใช้ข้อมูลและสถิติเพื่อแสวงหา AI โดยเฉพาะ เป้าหมายคือการสร้างระบบอัจฉริยะที่สามารถเรียนรู้โดยป้อนตัวอย่าง (ข้อมูล) มากมาย และไม่จำเป็นต้องตั้งโปรแกรมไว้อย่างชัดเจน ด้วยข้อมูลที่เพียงพอและอัลกอริธึมการเรียนรู้ที่ดี คอมพิวเตอร์จะเลือกรูปแบบในข้อมูลและปรับปรุงประสิทธิภาพ
ในทางตรงกันข้าม วิธีการที่ไม่ใช่ ML สำหรับ AI จะไม่ขึ้นอยู่กับข้อมูลและมีตรรกะแบบฮาร์ดโค้ดที่เขียนไว้ ตัวอย่างเช่น คุณสามารถสร้างบอต AI โอเอกซ์ที่มีประสิทธิภาพเหนือมนุษย์โดยเพียงแค่เขียนโค้ดในการเคลื่อนไหวที่เหมาะสมที่สุดทั้งหมด (มี เกมโอเอกซ์ที่เป็นไปได้ 255,168 เกม ดังนั้นอาจต้องใช้เวลาสักพัก แต่ก็ยังเป็นไปได้) เป็นไปไม่ได้เลยที่จะฮาร์ดโค้ดบอท AI หมากรุก มีเกมหมากรุกที่เป็นไปได้มากกว่าอะตอมในจักรวาล ML จะทำงานได้ดีขึ้นในกรณีเช่นนี้
คำถามที่สมเหตุสมผล ณ จุดนี้ก็คือ คอมพิวเตอร์จะปรับปรุงได้อย่างไรเมื่อคุณยกตัวอย่าง
แมชชีนเลิร์นนิงทำงานอย่างไร
ในระบบ ML ใดๆ คุณต้องมีสามสิ่ง: ชุดข้อมูล โมเดล ML และอัลกอริธึมการฝึก ขั้นแรก คุณจะต้องส่งตัวอย่างจากชุดข้อมูล จากนั้นโมเดลจะคาดการณ์ผลลัพธ์ที่ถูกต้องสำหรับตัวอย่างนั้น หากโมเดลไม่ถูกต้อง คุณจะใช้อัลกอริธึมการฝึกอบรมเพื่อทำให้โมเดลมีแนวโน้มที่จะเหมาะกับตัวอย่างที่คล้ายกันในอนาคต คุณทำซ้ำขั้นตอนนี้จนกว่าข้อมูลจะหมดหรือคุณพอใจกับผลลัพธ์ เมื่อคุณเสร็จสิ้นกระบวนการนี้แล้ว คุณสามารถใช้แบบจำลองของคุณเพื่อคาดการณ์ข้อมูลในอนาคตได้
ตัวอย่างพื้นฐานของกระบวนการนี้คือการสอนคอมพิวเตอร์ให้จดจำตัวเลขที่เขียนด้วยลายมือเหมือนกับที่แสดงด้านล่าง
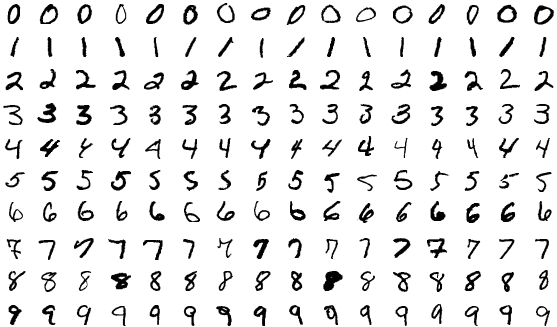
แหล่งที่มา
คุณรวบรวมรูปภาพหลักเป็นพันหรือหลายแสนรูป คุณเริ่มต้นด้วยโมเดล ML ที่ยังไม่เห็นตัวอย่างใดๆ คุณป้อนรูปภาพเข้าไปในโมเดลและขอให้คาดการณ์ว่าคิดว่าอยู่ในรูปภาพจำนวนเท่าใด มันจะคืนค่าตัวเลขระหว่างศูนย์ถึงเก้า เช่น หนึ่ง จากนั้น คุณจะบอกมันว่า “ตัวเลขนี้คือห้าจริงๆ ไม่ใช่หนึ่ง” อัลกอริธึมการฝึกอบรมจะอัปเดตโมเดล ดังนั้นจึงมีแนวโน้มที่จะตอบสนองมากขึ้นด้วยห้าครั้งในครั้งถัดไป คุณทำซ้ำขั้นตอนนี้กับรูปภาพ (เกือบ) ทั้งหมดที่มีอยู่ และตามหลักการแล้ว คุณจะมีโมเดลที่มีประสิทธิภาพดีซึ่งสามารถจดจำตัวเลขได้อย่างถูกต้องถึง 90% ของเวลาทั้งหมด ตอนนี้คุณสามารถใช้แบบจำลองนี้เพื่ออ่านตัวเลขหลายล้านหลักในขนาดได้เร็วกว่าที่มนุษย์สามารถทำได้ ในทางปฏิบัติ บริการไปรษณีย์ของสหรัฐอเมริกาใช้โมเดล ML เพื่ออ่านที่อยู่ที่เขียนด้วยลายมือถึง 98%
คุณอาจใช้เวลาเป็นเดือนหรือเป็นปีเพื่อวิเคราะห์รายละเอียดแม้แต่ส่วนเล็กๆ ของกระบวนการนี้ (ดูว่ามีอัลกอริธึมการเพิ่มประสิทธิภาพเวอร์ชันต่างๆ กี่เวอร์ชัน)
ประเภทของการเรียนรู้ของเครื่อง
จริงๆ แล้วมีวิธีการเรียนรู้ของเครื่องที่แตกต่างกันสี่ประเภท: แบบมีผู้ดูแล แบบไม่มีผู้ดูแล แบบกึ่งมีผู้ดูแล และแบบเสริมกำลัง ความแตกต่างที่สำคัญคือวิธีการติดป้ายกำกับข้อมูล (เช่น มีหรือไม่มีคำตอบที่ถูกต้อง)
การเรียนรู้แบบมีการดูแล
โมเดลการเรียนรู้แบบมีผู้สอนจะได้รับข้อมูลที่มีป้ายกำกับ (พร้อมคำตอบที่ถูกต้อง) ตัวอย่างของตัวเลขที่เขียนด้วยลายมือจัดอยู่ในหมวดหมู่นี้: เราสามารถบอกแบบจำลองได้ว่า "ห้าคือคำตอบที่ถูกต้อง" แบบจำลองนี้มีจุดมุ่งหมายเพื่อเรียนรู้การเชื่อมต่อที่ชัดเจนระหว่างอินพุตและเอาต์พุต โมเดลเหล่านี้สามารถส่งออกป้ายกำกับแยกกัน (เช่น ทำนาย "แมว" หรือ "สุนัข" ด้วยรูปสัตว์เลี้ยง) หรือตัวเลข (เช่น ราคาบ้านที่ทำนายตามจำนวนเตียง ห้องน้ำ ที่ตั้ง ฯลฯ) .
การเรียนรู้แบบไม่มีผู้ดูแล
โมเดลการเรียนรู้แบบไม่มีผู้ดูแลจะได้รับข้อมูลที่ไม่มีป้ายกำกับ (ไม่มีคำตอบที่ถูกต้อง) โมเดลเหล่านี้ระบุรูปแบบในข้อมูลอินพุตเพื่อจัดกลุ่มข้อมูลอย่างมีความหมาย ตัวอย่างเช่น เมื่อพิจารณารูปภาพแมวและสุนัขจำนวนมากโดยไม่มีคำตอบที่ถูกต้อง โมเดล ML ที่ไม่ได้รับการดูแลจะพิจารณาความเหมือนและความแตกต่างของรูปภาพเพื่อจัดกลุ่มรูปภาพสุนัขและแมวไว้ด้วยกัน การจัดกลุ่ม กฎการเชื่อมโยง และการลดขนาดเป็นวิธีการหลักใน ML ที่ไม่มีผู้ดูแล
การเรียนรู้แบบกึ่งมีผู้สอน
การเรียนรู้แบบกึ่งมีผู้สอนเป็นแนวทางการเรียนรู้ของเครื่องที่อยู่ระหว่างการเรียนรู้แบบมีผู้สอนและแบบไม่มีผู้ดูแล วิธีการนี้ให้ข้อมูลที่ไม่มีป้ายกำกับจำนวนมากและชุดข้อมูลที่มีป้ายกำกับจำนวนน้อยกว่าสำหรับการฝึกโมเดล ขั้นแรก แบบจำลองจะได้รับการฝึกเกี่ยวกับข้อมูลที่ติดป้ายกำกับ จากนั้นจะกำหนดป้ายกำกับให้กับข้อมูลที่ไม่มีป้ายกำกับโดยการเปรียบเทียบความคล้ายคลึงกับข้อมูลที่ติดป้ายกำกับ
การเรียนรู้แบบเสริมกำลัง
การเรียนรู้แบบเสริมกำลังไม่มีตัวอย่างและป้ายกำกับที่กำหนด แต่แบบจำลองจะได้รับสภาพแวดล้อม (เช่น เกมเป็นเกมทั่วไป) ฟังก์ชันการให้รางวัล และเป้าหมาย โมเดลเรียนรู้ที่จะบรรลุเป้าหมายด้วยการลองผิดลองถูก มันจะดำเนินการ และฟังก์ชันการให้รางวัลจะบอกว่าการดำเนินการช่วยให้บรรลุเป้าหมายที่ครอบคลุมหรือไม่ จากนั้นโมเดลจะอัปเดตตัวเองเพื่อดำเนินการดังกล่าวไม่มากก็น้อย โมเดลสามารถเรียนรู้ที่จะบรรลุเป้าหมายโดยการทำเช่นนี้หลายครั้ง
ตัวอย่างที่มีชื่อเสียงของรูปแบบการเรียนรู้แบบเสริมกำลังคือ AlphaGo Zero โมเดลนี้ได้รับการฝึกฝนให้ชนะเกม Go และได้รับสถานะเป็นกระดาน Go เท่านั้น จากนั้นมันก็เล่นเกมแข่งกับตัวเองนับล้านเกม โดยเรียนรู้เมื่อเวลาผ่านไปว่าท่าไหนให้ข้อได้เปรียบและท่าไหนไม่ได้ มันบรรลุประสิทธิภาพระดับเหนือมนุษย์ในการฝึกฝน 70 ชั่วโมง เหนือกว่าแชมป์โลก Go
การเรียนรู้ด้วยตนเอง
จริงๆ แล้วมีการเรียนรู้ของเครื่องประเภทที่ห้าที่มีความสำคัญเมื่อเร็วๆ นี้ ซึ่งก็คือการเรียนรู้แบบมีผู้ดูแลด้วยตนเอง โมเดลการเรียนรู้แบบกำกับดูแลตนเองจะได้รับข้อมูลที่ไม่มีป้ายกำกับ แต่เรียนรู้ที่จะสร้างป้ายกำกับจากข้อมูลนี้ สิ่งนี้รองรับโมเดล GPT ที่อยู่เบื้องหลัง ChatGPT ในระหว่างการฝึก GPT แบบจำลองนี้มีจุดมุ่งหมายเพื่อทำนายคำถัดไปจากสตริงอินพุตของคำ เช่น ประโยค “The cat sat on the mat” GPT จะได้รับ "The" และขอให้คาดเดาคำถัดไป มันทำการทำนาย (เช่น “สุนัข”) แต่เนื่องจากมีประโยคดั้งเดิม จึงรู้ว่าคำตอบที่ถูกต้องคืออะไร: “แมว” จากนั้น GPT จะให้คำว่า "แมว" และขอให้ทายคำถัดไป และอื่นๆ การทำเช่นนี้จะทำให้สามารถเรียนรู้รูปแบบทางสถิติระหว่างคำต่างๆ และอื่นๆ อีกมากมาย
การประยุกต์ใช้การเรียนรู้ของเครื่อง
ปัญหาหรืออุตสาหกรรมใดๆ ที่มีข้อมูลจำนวนมากสามารถใช้ ML ได้ อุตสาหกรรมจำนวนมากได้เห็นผลลัพธ์ที่ไม่ธรรมดาจากการทำเช่นนั้น และมีกรณีการใช้งานเพิ่มมากขึ้นอย่างต่อเนื่อง ต่อไปนี้เป็นกรณีการใช้งานทั่วไปของ ML:
การเขียน
โมเดล ML ขับเคลื่อนผลิตภัณฑ์การเขียน AI เชิงสร้างสรรค์ เช่น Grammarly ด้วยการฝึกฝนการเขียนที่ยอดเยี่ยมจำนวนมาก Grammarly สามารถสร้างแบบร่างสำหรับคุณ ช่วยคุณเขียนใหม่และขัดเกลา และระดมความคิดร่วมกับคุณ ทั้งหมดนี้อยู่ในโทนและสไตล์ที่คุณต้องการ

การรู้จำเสียง
Siri, Alexa และเวอร์ชันเสียงของ ChatGPT ล้วนขึ้นอยู่กับรุ่น ML โมเดลเหล่านี้ได้รับการฝึกอบรมเกี่ยวกับตัวอย่างเสียงมากมาย พร้อมด้วยสำเนาเสียงที่ถูกต้อง ด้วยตัวอย่างเหล่านี้ โมเดลสามารถเปลี่ยนคำพูดให้เป็นข้อความได้ หากไม่มี ML ปัญหานี้คงจะยากลำบากมากเพราะทุกคนมีวิธีการพูดและการออกเสียงที่แตกต่างกัน เป็นไปไม่ได้ที่จะแจกแจงความเป็นไปได้ทั้งหมด
ข้อแนะนำ
เบื้องหลังฟีดของคุณบน TikTok, Netflix, Instagram และ Amazon คือโมเดลการแนะนำ ML โมเดลเหล่านี้ได้รับการฝึกอบรมเกี่ยวกับตัวอย่างการตั้งค่าต่างๆ มากมาย (เช่น คนเช่นคุณชอบภาพยนตร์เรื่องนี้มากกว่าภาพยนตร์เรื่องนั้น ผลิตภัณฑ์นี้มากกว่าผลิตภัณฑ์นั้น) เพื่อแสดงรายการและเนื้อหาที่คุณต้องการดู เมื่อเวลาผ่านไป โมเดลต่างๆ ยังสามารถรวมการตั้งค่าเฉพาะของคุณเพื่อสร้างฟีดที่ดึงดูดคุณโดยเฉพาะ
การตรวจจับการฉ้อโกง
ธนาคารใช้โมเดล ML เพื่อตรวจจับการฉ้อโกงบัตรเครดิต ผู้ให้บริการอีเมลใช้โมเดล ML เพื่อตรวจจับและเปลี่ยนเส้นทางอีเมลขยะ โมเดล ML การฉ้อโกงมีตัวอย่างข้อมูลฉ้อโกงมากมาย จากนั้นโมเดลเหล่านี้จะเรียนรู้รูปแบบระหว่างข้อมูลเพื่อระบุการฉ้อโกงในอนาคต
รถยนต์ที่ขับเคลื่อนด้วยตนเอง
รถยนต์ที่ขับเคลื่อนด้วยตนเองใช้ ML เพื่อตีความและนำทางไปตามถนน ML ช่วยให้รถระบุคนเดินเท้าและเลนถนน ทำนายการเคลื่อนไหวของรถคันอื่น และตัดสินใจการกระทำต่อไป (เช่น เร่งความเร็ว สลับเลน ฯลฯ) รถยนต์ที่ขับเคลื่อนด้วยตนเองได้รับความเชี่ยวชาญโดยการฝึกอบรมตัวอย่างนับพันล้านตัวอย่างโดยใช้วิธี ML เหล่านี้
ข้อดีของการเรียนรู้ของเครื่อง
เมื่อทำได้ดี ML ก็สามารถเปลี่ยนแปลงได้ โดยทั่วไป โมเดล ML สามารถทำให้กระบวนการถูกลง ดีขึ้น หรือทั้งสองอย่างได้
ประสิทธิภาพด้านต้นทุนแรงงาน
โมเดล ML ที่ผ่านการฝึกอบรมสามารถจำลองการทำงานของผู้เชี่ยวชาญได้ในราคาเพียงเล็กน้อย ตัวอย่างเช่น นายหน้าผู้เชี่ยวชาญที่เป็นมนุษย์มีสัญชาตญาณที่ดีเมื่อพูดถึงเรื่องราคาบ้าน แต่นั่นอาจต้องใช้เวลาหลายปีในการฝึกอบรม นายหน้าผู้เชี่ยวชาญ (และผู้เชี่ยวชาญทุกประเภท) ก็มีค่าใช้จ่ายในการจ้างเช่นกัน อย่างไรก็ตาม โมเดล ML ที่ได้รับการฝึกอบรมจากตัวอย่างหลายล้านตัวอย่างอาจเข้าใกล้ประสิทธิภาพการทำงานของนายหน้าผู้เชี่ยวชาญได้มากขึ้น โมเดลดังกล่าวสามารถฝึกได้ภายในเวลาไม่กี่วัน และจะใช้น้อยกว่ามากเมื่อฝึกแล้ว นายหน้าที่มีประสบการณ์น้อยก็สามารถใช้โมเดลเหล่านี้เพื่อทำงานได้มากขึ้นโดยใช้เวลาน้อยลง
ประสิทธิภาพด้านเวลา
โมเดล ML ไม่ได้ถูกจำกัดด้วยเวลาเช่นเดียวกับมนุษย์ AlphaGo Zero เล่นเกม Go4.9 ล้านเกมในการฝึกซ้อมสามวัน การดำเนินการนี้ต้องใช้เวลาหลายปีหรือหลายสิบปีจึงจะสำเร็จ เนื่องจากความสามารถในการปรับขนาดนี้ โมเดลจึงสามารถสำรวจการเคลื่อนไหวและตำแหน่งของ Go ได้หลากหลาย ซึ่งนำไปสู่ประสิทธิภาพเหนือมนุษย์ โมเดล ML สามารถเลือกรูปแบบที่ผู้เชี่ยวชาญพลาดได้ AlphaGo Zero ยังพบและใช้ท่าที่มนุษย์ไม่ได้เล่นด้วยซ้ำ นี่ไม่ได้หมายความว่าผู้เชี่ยวชาญจะไม่มีคุณค่าอีกต่อไป ผู้เชี่ยวชาญด้าน Go พัฒนาขึ้นมากโดยใช้โมเดลอย่าง AlphaGo เพื่อลองใช้กลยุทธ์ใหม่ๆ
ข้อเสียของการเรียนรู้ของเครื่อง
แน่นอนว่าการใช้โมเดล ML ก็มีข้อเสียเช่นกัน กล่าวคือ การฝึกอบรมมีราคาแพง และไม่สามารถอธิบายผลลัพธ์ได้ง่าย
การฝึกอบรมที่มีราคาแพง
การฝึกอบรม ML อาจมีราคาแพง ตัวอย่างเช่น AlphaGo Zero มีค่าใช้จ่ายในการพัฒนา 25 ล้านดอลลาร์ และ GPT-4 มีค่าใช้จ่ายมากกว่า 100 ล้านดอลลาร์ในการพัฒนา ต้นทุนหลักในการพัฒนาโมเดล ML คือการติดป้ายกำกับข้อมูล ค่าใช้จ่ายด้านฮาร์ดแวร์ และเงินเดือนพนักงาน
โมเดล ML ที่ได้รับการดูแลที่ดีเยี่ยมจำเป็นต้องมีตัวอย่างที่มีป้ายกำกับหลายล้านตัวอย่าง ซึ่งแต่ละตัวอย่างจะต้องมีป้ายกำกับโดยมนุษย์ เมื่อรวบรวมป้ายกำกับทั้งหมดแล้ว จำเป็นต้องใช้ฮาร์ดแวร์พิเศษเพื่อฝึกโมเดล หน่วยประมวลผลกราฟิก (GPU) และหน่วยประมวลผลเทนเซอร์ (TPU) เป็นมาตรฐานสำหรับฮาร์ดแวร์ ML และอาจมีราคาสูงในการเช่าหรือซื้อ GPU มีราคาระหว่างหลายพันถึงหลายหมื่นดอลลาร์ในการซื้อ
สุดท้ายนี้ การพัฒนาโมเดล ML ที่ยอดเยี่ยมจำเป็นต้องจ้างนักวิจัยหรือวิศวกรด้านการเรียนรู้ของเครื่องซึ่งสามารถเรียกร้องเงินเดือนสูงเนื่องจากทักษะและความเชี่ยวชาญของพวกเขา
ความชัดเจนในการตัดสินใจมีจำกัด
สำหรับโมเดล ML หลายรุ่น ยังไม่ชัดเจนว่าเหตุใดจึงให้ผลลัพธ์ตามที่ต้องการ AlphaGo Zero ไม่สามารถอธิบายเหตุผลที่อยู่เบื้องหลังการตัดสินใจได้ มันรู้ว่าการเคลื่อนไหวจะใช้ได้ในสถานการณ์เฉพาะ แต่ไม่ใช่เพราะเหตุใดสิ่งนี้อาจมีผลกระทบที่สำคัญเมื่อใช้โมเดล ML ในสถานการณ์ประจำวัน โมเดล ML ที่ใช้ในการดูแลสุขภาพอาจให้ผลลัพธ์ที่ไม่ถูกต้องหรือเอนเอียง และเราอาจไม่ทราบเพราะเหตุผลที่อยู่เบื้องหลังผลลัพธ์นั้นไม่ชัดเจน โดยทั่วไปแล้ว อคติเป็นปัญหาอย่างมากกับโมเดล ML และการขาดความสามารถในการอธิบายทำให้ยากต่อการจัดการปัญหา ปัญหาเหล่านี้มีผลกับโมเดลการเรียนรู้เชิงลึกโดยเฉพาะ โมเดลการเรียนรู้เชิงลึกคือโมเดล ML ที่ใช้โครงข่ายประสาทเทียมหลายชั้นเพื่อประมวลผลอินพุต พวกเขาสามารถจัดการข้อมูลและคำถามที่ซับซ้อนมากขึ้นได้
ในทางกลับกัน โมเดล ML ที่ "ตื้น" ที่เรียบง่ายกว่า (เช่น แผนผังการตัดสินใจและแบบจำลองการถดถอย) จะไม่ประสบกับข้อเสียเดียวกัน พวกเขายังคงต้องการข้อมูลจำนวนมาก แต่มีราคาถูกในการฝึกอบรมอย่างอื่น นอกจากนี้ยังอธิบายได้ง่ายกว่าอีกด้วย ข้อเสียคือโมเดลดังกล่าวสามารถถูกจำกัดในด้านอรรถประโยชน์ แอปพลิเคชันขั้นสูงเช่น GPT ต้องใช้โมเดลที่ซับซ้อนมากขึ้น
อนาคตของการเรียนรู้ของเครื่อง
โมเดล ML ที่ใช้ Transformer ได้รับความนิยมอย่างมากในช่วงไม่กี่ปีที่ผ่านมา นี่คือประเภทโมเดล ML เฉพาะที่ขับเคลื่อน GPT (T ใน GPT), Grammarly และ Claude AI โมเดล ML แบบกระจายซึ่งขับเคลื่อนผลิตภัณฑ์สร้างภาพ เช่น DALL-E และ Midjourney ก็ได้รับความสนใจเช่นกัน
แนวโน้มนี้ดูเหมือนจะไม่มีการเปลี่ยนแปลงในเร็ว ๆ นี้ บริษัท ML มุ่งเน้นไปที่การเพิ่มขนาดของโมเดล ซึ่งเป็นโมเดลที่ใหญ่ขึ้นซึ่งมีความสามารถที่ดีกว่าและมีชุดข้อมูลที่ใหญ่ขึ้นสำหรับฝึกฝนพวกเขา GPT-4 มีจำนวนพารามิเตอร์โมเดล 10 เท่าของ GPT-3 เป็นต้น เรามีแนวโน้มที่จะเห็นอุตสาหกรรมจำนวนมากขึ้นใช้ generative AI ในผลิตภัณฑ์ของตนเพื่อสร้างประสบการณ์ส่วนบุคคลให้กับผู้ใช้
วิทยาการหุ่นยนต์ก็กำลังร้อนแรงเช่นกัน นักวิจัยใช้ ML เพื่อสร้างหุ่นยนต์ที่สามารถเคลื่อนย้ายและใช้วัตถุเช่นมนุษย์ได้ หุ่นยนต์เหล่านี้สามารถทดลองในสภาพแวดล้อมของตน และใช้การเรียนรู้แบบเสริมกำลังเพื่อปรับตัวและบรรลุเป้าหมายได้อย่างรวดเร็ว เช่น วิธีเตะลูกฟุตบอล
อย่างไรก็ตาม เนื่องจากโมเดล ML มีประสิทธิภาพและแพร่หลายมากขึ้น จึงมีความกังวลเกี่ยวกับผลกระทบที่อาจเกิดขึ้นต่อสังคม ประเด็นต่างๆ เช่น อคติ ความเป็นส่วนตัว และการโยกย้ายงาน กำลังเป็นที่ถกเถียงกันอย่างถึงพริกถึงขิง และมีการตระหนักรู้มากขึ้นถึงความจำเป็นในการมีแนวปฏิบัติด้านจริยธรรมและแนวปฏิบัติในการพัฒนาอย่างมีความรับผิดชอบ
บทสรุป
การเรียนรู้ของเครื่องเป็นส่วนย่อยของ AI โดยมีเป้าหมายที่ชัดเจนในการสร้างระบบอัจฉริยะโดยปล่อยให้พวกเขาเรียนรู้จากข้อมูล การเรียนรู้แบบมีผู้ดูแล แบบไม่มีผู้ดูแล กึ่งมีผู้ดูแล และการเรียนรู้แบบเสริมกำลังเป็นประเภทหลักของ ML (พร้อมกับการเรียนรู้แบบมีผู้ดูแลด้วยตนเอง) ML เป็นหัวใจสำคัญของผลิตภัณฑ์ใหม่ๆ มากมายที่เปิดตัวในปัจจุบัน เช่น ChatGPT รถยนต์ไร้คนขับ และคำแนะนำของ Netflix อาจมีราคาถูกกว่าหรือดีกว่าประสิทธิภาพของมนุษย์ แต่ในขณะเดียวกัน ก็มีราคาแพงในช่วงแรก และอธิบายและควบคุมได้น้อยกว่า ML ก็มีแนวโน้มที่จะได้รับความนิยมเพิ่มมากขึ้นในอีกไม่กี่ปีข้างหน้า
ML มีความซับซ้อนมากมาย และโอกาสในการเรียนรู้และมีส่วนร่วมในสาขานี้ก็กำลังขยายออกไป โดยเฉพาะอย่างยิ่ง คำแนะนำของ Grammarly เกี่ยวกับ AI, การเรียนรู้เชิงลึก และ ChatGPT สามารถช่วยให้คุณเรียนรู้เพิ่มเติมเกี่ยวกับส่วนสำคัญอื่นๆ ของสาขานี้ นอกเหนือจากนั้น การเจาะลึกรายละเอียดของ ML (เช่น วิธีการรวบรวมข้อมูล จริงๆ แล้วโมเดลมีลักษณะอย่างไร และอัลกอริธึมที่อยู่เบื้องหลัง "การเรียนรู้") สามารถช่วยให้คุณรวมเข้ากับงานของคุณได้อย่างมีประสิทธิภาพ
เนื่องจาก ML เติบโตอย่างต่อเนื่อง และด้วยความคาดหวังว่าจะเข้าถึงเกือบทุกอุตสาหกรรม ตอนนี้จึงถึงเวลาเริ่มต้นการเดินทาง ML ของคุณแล้ว!