
ป่าสุ่มในการเรียนรู้ของเครื่อง: สิ่งที่พวกเขาทำงานและวิธีการทำงานของพวกเขา
เผยแพร่แล้ว: 2025-02-03ป่าสุ่มเป็นเทคนิคที่ทรงพลังและหลากหลายในการเรียนรู้ของเครื่อง (ML) คู่มือนี้จะช่วยให้คุณเข้าใจป่าแบบสุ่มวิธีการทำงานและแอปพลิเคชันผลประโยชน์และความท้าทายของพวกเขา
สารบัญ
- ป่าสุ่มคืออะไร?
- ต้นไม้ตัดสินใจกับป่าสุ่ม: อะไรคือความแตกต่าง?
- ป่าสุ่มทำงานอย่างไร
- การใช้งานจริงของป่าสุ่ม
- ข้อดีของป่าสุ่ม
- ข้อเสียของป่าสุ่ม
ป่าสุ่มคืออะไร?
ป่าสุ่มเป็นอัลกอริทึมการเรียนรู้ของเครื่องจักรที่ใช้ต้นไม้ตัดสินใจหลายต้นเพื่อทำการคาดการณ์ มันเป็นวิธีการเรียนรู้ที่ได้รับการดูแลที่ออกแบบมาสำหรับงานการจำแนกและการถดถอย ด้วยการรวมเอาท์พุทของต้นไม้หลายต้นป่าแบบสุ่มช่วยเพิ่มความแม่นยำลดการเกินพิกัดและให้การคาดการณ์ที่มั่นคงมากขึ้นเมื่อเทียบกับต้นไม้ตัดสินใจครั้งเดียว
ต้นไม้ตัดสินใจกับป่าสุ่ม: อะไรคือความแตกต่าง?
แม้ว่าป่าแบบสุ่มจะถูกสร้างขึ้นบนต้นไม้ตัดสินใจอัลกอริทึมทั้งสองนั้นแตกต่างกันอย่างมีนัยสำคัญในโครงสร้างและการใช้งาน:
ต้นไม้ตัดสินใจ
แผนผังการตัดสินใจประกอบด้วยสามองค์ประกอบหลัก: โหนดรูทโหนดการตัดสินใจ (โหนดภายใน) และโหนดใบไม้ เช่นเดียวกับผังงานกระบวนการตัดสินใจเริ่มต้นที่โหนดรูทไหลผ่านโหนดการตัดสินใจตามเงื่อนไขและสิ้นสุดที่โหนดใบไม้ที่แสดงผลลัพธ์ ในขณะที่ต้นไม้ตัดสินใจนั้นง่ายต่อการตีความและกำหนดแนวความคิดพวกเขายังมีแนวโน้มที่จะ overfitting โดยเฉพาะอย่างยิ่งกับชุดข้อมูลที่ซับซ้อนหรือมีเสียงดัง
ป่าสุ่ม
ป่าสุ่มเป็นชุดของต้นไม้ตัดสินใจที่รวมเอาท์พุทของพวกเขาสำหรับการคาดการณ์ที่ดีขึ้น ต้นไม้แต่ละต้นได้รับการฝึกฝนในตัวอย่าง bootstrap ที่ไม่ซ้ำกัน (ชุดย่อยตัวอย่างแบบสุ่มของชุดข้อมูลต้นฉบับที่มีการแทนที่) และประเมินการแยกการตัดสินใจโดยใช้ชุดย่อยที่เลือกแบบสุ่มของคุณสมบัติในแต่ละโหนด วิธีการนี้ที่รู้จักกันในชื่อการใส่ถุงฟีเจอร์แนะนำความหลากหลายระหว่างต้นไม้ โดยการรวมการคาดการณ์ - การลงคะแนนเสียงส่วนใหญ่สำหรับการจำแนกประเภทหรือค่าเฉลี่ยสำหรับการถดถอย - ป่าไม้สุ่มให้ผลลัพธ์ที่แม่นยำและมั่นคงกว่าต้นไม้ตัดสินใจครั้งเดียวในวงดนตรี
ป่าสุ่มทำงานอย่างไร
ป่าไม้สุ่มทำงานโดยการรวมต้นไม้ตัดสินใจหลายต้นเพื่อสร้างแบบจำลองการทำนายที่แข็งแกร่งและแม่นยำ
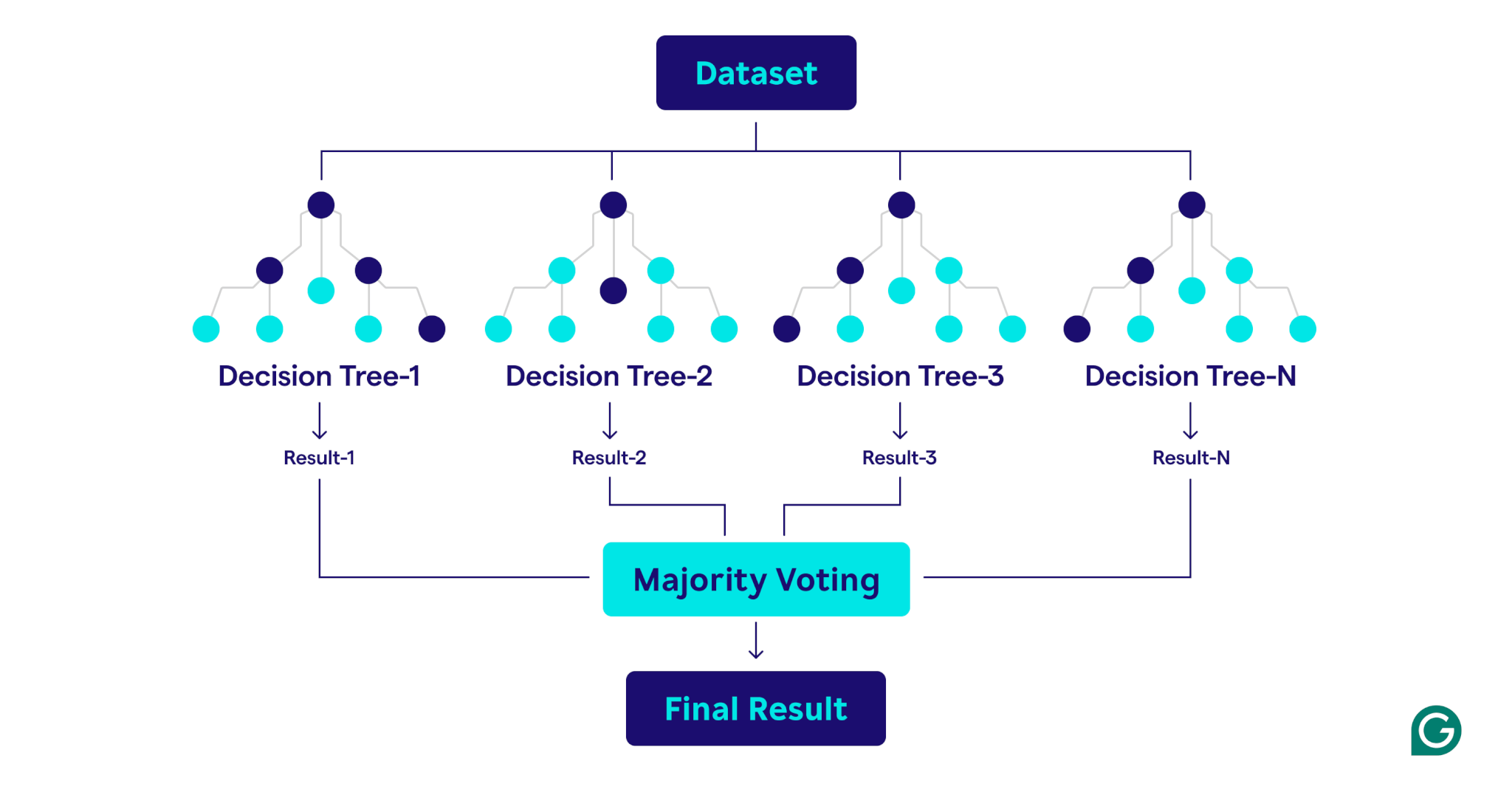
นี่คือคำอธิบายทีละขั้นตอนของกระบวนการ:
1. การตั้งค่า hyperparameters
ขั้นตอนแรกคือการกำหนดพารามิเตอร์ของโมเดล เหล่านี้รวมถึง:
- จำนวนต้นไม้:กำหนดขนาดของป่า
- ความลึกสูงสุดสำหรับต้นไม้แต่ละต้น:ควบคุมความลึกของแผนผังการตัดสินใจแต่ละต้นสามารถเติบโตได้
- จำนวนคุณสมบัติที่พิจารณาในแต่ละแยก:จำกัด จำนวนคุณสมบัติที่ประเมินเมื่อสร้างการแยก
ไฮเปอร์พารามิเตอร์เหล่านี้ช่วยให้การปรับความซับซ้อนของโมเดลและประสิทธิภาพการเพิ่มประสิทธิภาพสำหรับชุดข้อมูลเฉพาะ
2. การสุ่มตัวอย่าง bootstrap
เมื่อตั้งค่าพารามิเตอร์ hyperparameters กระบวนการฝึกอบรมจะเริ่มต้นด้วยการสุ่มตัวอย่าง bootstrap สิ่งนี้เกี่ยวข้องกับ:
- จุดข้อมูลจากชุดข้อมูลต้นฉบับจะถูกสุ่มเลือกเพื่อสร้างชุดข้อมูลการฝึกอบรม (ตัวอย่าง bootstrap) สำหรับแต่ละแผนผังการตัดสินใจ
- โดยทั่วไปแล้วตัวอย่าง bootstrap จะประมาณสองในสามของขนาดของชุดข้อมูลต้นฉบับโดยมีจุดข้อมูลบางจุดซ้ำและอื่น ๆ ยกเว้น
- ส่วนที่สามที่เหลือของจุดข้อมูลที่ไม่รวมอยู่ในตัวอย่าง bootstrap เรียกว่าข้อมูลนอก (OOB)
3. การสร้างต้นไม้ตัดสินใจ
แผนผังการตัดสินใจแต่ละครั้งในป่าสุ่มได้รับการฝึกฝนในตัวอย่าง bootstrap ที่สอดคล้องกันโดยใช้กระบวนการที่ไม่ซ้ำกัน:
- การบรรจุถุงฟีเจอร์:ในแต่ละการแยกส่วนย่อยของคุณสมบัติจะถูกเลือกเพื่อให้มั่นใจถึงความหลากหลายระหว่างต้นไม้
- การแยกโหนด:คุณสมบัติที่ดีที่สุดจากชุดย่อยใช้เพื่อแยกโหนด:
- สำหรับงานการจำแนกประเภทเกณฑ์เช่น Gini Impurity (การวัดความถี่ขององค์ประกอบที่เลือกแบบสุ่มจะถูกจัดประเภทไม่ถูกต้องหากมีการติดฉลากแบบสุ่มตามการกระจายของป้ายกำกับชั้นเรียนในโหนด) วัดว่าการแยกชั้นเรียน
- สำหรับงานการถดถอยเทคนิคต่าง ๆ เช่นการลดความแปรปรวน (วิธีการที่วัดจำนวนโหนดที่แยกความแปรปรวนของค่าเป้าหมายมากเพียงใดซึ่งนำไปสู่การคาดการณ์ที่แม่นยำยิ่งขึ้น) ประเมินว่าการแยกข้อผิดพลาดลดลง
- ต้นไม้เติบโตขึ้นเรื่อย ๆ จนกว่าจะตรงกับเงื่อนไขการหยุดเช่นความลึกสูงสุดหรือจำนวนจุดข้อมูลขั้นต่ำต่อโหนด
4. การประเมินประสิทธิภาพ
เมื่อต้นไม้แต่ละต้นถูกสร้างขึ้นประสิทธิภาพของโมเดลจะถูกประเมินโดยใช้ข้อมูล OOB:
- การประมาณข้อผิดพลาด OOB ให้การวัดประสิทธิภาพของแบบจำลองที่ไม่เอนเอียงซึ่งไม่จำเป็นต้องใช้ชุดข้อมูลการตรวจสอบแยกต่างหาก
- โดยการรวมการทำนายจากต้นไม้ทุกต้นป่าสุ่มบรรลุความแม่นยำที่ดีขึ้นและลดการล้นเกินเมื่อเทียบกับต้นไม้การตัดสินใจของแต่ละบุคคล

การใช้งานจริงของป่าสุ่ม
เช่นเดียวกับต้นไม้ตัดสินใจที่พวกเขาสร้างขึ้นสามารถนำป่าสุ่มไปใช้กับปัญหาการจำแนกและการถดถอยในหลากหลายภาคส่วนเช่นการดูแลสุขภาพและการเงิน
จำแนกเงื่อนไขผู้ป่วย
ในการดูแลสุขภาพป่าสุ่มใช้เพื่อจำแนกเงื่อนไขของผู้ป่วยตามข้อมูลเช่นประวัติทางการแพทย์ข้อมูลประชากรและผลการทดสอบ ตัวอย่างเช่นในการทำนายว่าผู้ป่วยมีแนวโน้มที่จะพัฒนาเงื่อนไขเฉพาะเช่นโรคเบาหวานต้นไม้ตัดสินใจแต่ละครั้งจัดประเภทผู้ป่วยว่ามีความเสี่ยงหรือไม่ขึ้นอยู่กับข้อมูลที่เกี่ยวข้อง วิธีการนี้หมายความว่าป่าแบบสุ่มเหมาะอย่างยิ่งสำหรับชุดข้อมูลที่ซับซ้อนและมีคุณสมบัติที่พบในการดูแลสุขภาพ
การทำนายค่าเริ่มต้นของเงินกู้
ธนาคารและสถาบันการเงินที่สำคัญใช้ป่าสุ่มอย่างกว้างขวางเพื่อกำหนดคุณสมบัติของสินเชื่อและเข้าใจความเสี่ยงได้ดีขึ้น รูปแบบใช้ปัจจัยเช่นรายได้และคะแนนเครดิตเพื่อกำหนดความเสี่ยง เนื่องจากความเสี่ยงถูกวัดเป็นค่าตัวเลขอย่างต่อเนื่องป่าสุ่มจึงทำการถดถอยแทนการจำแนกประเภท แผนผังการตัดสินใจแต่ละครั้งได้รับการฝึกฝนเกี่ยวกับตัวอย่าง bootstrap ที่แตกต่างกันเล็กน้อยส่งออกคะแนนความเสี่ยงที่คาดการณ์ไว้ จากนั้นป่าสุ่มเฉลี่ยเฉลี่ยการคาดการณ์ของแต่ละบุคคลส่งผลให้การประเมินความเสี่ยงแบบองค์รวมที่แข็งแกร่ง
การทำนายการสูญเสียของลูกค้า
ในการตลาดป่าสุ่มมักใช้เพื่อทำนายความเป็นไปได้ของลูกค้าที่หยุดการใช้ผลิตภัณฑ์หรือบริการ สิ่งนี้เกี่ยวข้องกับการวิเคราะห์รูปแบบพฤติกรรมของลูกค้าเช่นความถี่ในการซื้อและการโต้ตอบกับการบริการลูกค้า ด้วยการระบุรูปแบบเหล่านี้ป่าแบบสุ่มสามารถจำแนกลูกค้าที่เสี่ยงต่อการออกไปได้ ด้วยข้อมูลเชิงลึกเหล่านี้ บริษัท สามารถดำเนินการตามขั้นตอนเชิงรุกและขับเคลื่อนด้วยข้อมูลเพื่อรักษาลูกค้าเช่นเสนอโปรแกรมความภักดีหรือโปรโมชั่นเป้าหมาย
ทำนายราคาอสังหาริมทรัพย์
ป่าสุ่มสามารถใช้ในการทำนายราคาอสังหาริมทรัพย์ซึ่งเป็นงานการถดถอย เพื่อให้การทำนายสุ่มป่าใช้ข้อมูลทางประวัติศาสตร์ซึ่งรวมถึงปัจจัยต่าง ๆ เช่นที่ตั้งทางภูมิศาสตร์วิดีโอสแควร์และยอดขายล่าสุดในพื้นที่ กระบวนการเฉลี่ยของป่าแบบสุ่มส่งผลให้มีการทำนายราคาที่เชื่อถือได้และมีเสถียรภาพมากกว่าของแผนผังการตัดสินใจของแต่ละบุคคลซึ่งมีประโยชน์ในตลาดอสังหาริมทรัพย์ที่มีความผันผวนสูง
ข้อดีของป่าสุ่ม
ป่าไม้สุ่มมีข้อได้เปรียบมากมายรวมถึงความแม่นยำความทนทานความเก่งกาจและความสามารถในการประเมินความสำคัญของคุณลักษณะ
ความแม่นยำและความทนทาน
ป่าไม้สุ่มมีความแม่นยำและแข็งแกร่งกว่าต้นไม้ตัดสินใจของแต่ละบุคคล นี่คือความสำเร็จโดยการรวมเอาท์พุทของต้นไม้ตัดสินใจหลายต้นที่ได้รับการฝึกฝนเกี่ยวกับตัวอย่าง bootstrap ที่แตกต่างกันของชุดข้อมูลต้นฉบับ ความหลากหลายที่เกิดขึ้นหมายความว่าป่าไม้สุ่มมีแนวโน้มที่จะเกินกว่าต้นไม้ตัดสินใจได้น้อยกว่า วิธีการทั้งหมดนี้หมายความว่าป่าสุ่มดีในการจัดการข้อมูลที่มีเสียงดังแม้ในชุดข้อมูลที่ซับซ้อน
ความอเนกประสงค์
เช่นเดียวกับต้นไม้ตัดสินใจที่พวกเขาสร้างขึ้นป่าไม้สุ่มมีความหลากหลายสูง พวกเขาสามารถจัดการทั้งงานการถดถอยและการจำแนกประเภททำให้ใช้งานได้กับปัญหาที่หลากหลาย ป่าสุ่มยังทำงานได้ดีกับชุดข้อมูลขนาดใหญ่ที่อุดมไปด้วยคุณสมบัติและสามารถจัดการข้อมูลตัวเลขและข้อมูลเชิงหมวดหมู่ได้
มีความสำคัญ
ป่าไม้สุ่มมีความสามารถในตัวเพื่อประเมินความสำคัญของคุณสมบัติเฉพาะ ในฐานะที่เป็นส่วนหนึ่งของกระบวนการฝึกอบรมป่าสุ่มจะส่งออกคะแนนที่วัดจำนวนความแม่นยำของการเปลี่ยนแปลงของแบบจำลองหากคุณลักษณะเฉพาะถูกลบออก ด้วยการหาค่าเฉลี่ยคะแนนสำหรับแต่ละคุณสมบัติป่าสุ่มสามารถให้การวัดเชิงปริมาณของความสำคัญคุณลักษณะ คุณสมบัติที่สำคัญน้อยกว่านั้นสามารถลบออกเพื่อสร้างต้นไม้และป่าที่มีประสิทธิภาพมากขึ้น
ข้อเสียของป่าสุ่ม
ในขณะที่ป่าไม้สุ่มเสนอประโยชน์มากมายพวกเขายากที่จะตีความและมีค่าใช้จ่ายสูงกว่าการฝึกอบรมมากกว่าต้นไม้ตัดสินใจเดียวและพวกเขาอาจส่งออกการคาดการณ์ช้ากว่ารุ่นอื่น ๆ
ความซับซ้อน
ในขณะที่ป่าไม้สุ่มและต้นไม้ตัดสินใจมีเหมือนกันมากป่าสุ่มนั้นยากต่อการตีความและมองเห็น ความซับซ้อนนี้เกิดขึ้นเนื่องจากป่าไม้สุ่มใช้ต้นไม้ตัดสินใจหลายร้อยหรือหลายพันต้น ธรรมชาติ“ กล่องดำ” ของป่าสุ่มเป็นข้อเสียเปรียบอย่างจริงจังเมื่อความสามารถในการอธิบายแบบจำลองเป็นข้อกำหนด
ค่าคำนวณ
การฝึกอบรมต้นไม้ตัดสินใจหลายร้อยหรือหลายพันครั้งต้องใช้พลังการประมวลผลและความทรงจำมากกว่าการฝึกอบรมแผนการตัดสินใจครั้งเดียว เมื่อมีการเกี่ยวข้องกับชุดข้อมูลขนาดใหญ่ค่าใช้จ่ายในการคำนวณอาจสูงขึ้น ความต้องการทรัพยากรขนาดใหญ่นี้อาจส่งผลให้ต้นทุนทางการเงินสูงขึ้นและเวลาฝึกอบรมที่ยาวนานขึ้น เป็นผลให้ป่าสุ่มอาจไม่สามารถใช้งานได้ในสถานการณ์เช่นการคำนวณขอบซึ่งทั้งพลังการคำนวณและหน่วยความจำขาดแคลน อย่างไรก็ตามป่าแบบสุ่มสามารถขนานกันซึ่งสามารถช่วยลดค่าใช้จ่ายในการคำนวณ
เวลาทำนายช้าลง
กระบวนการทำนายของป่าสุ่มเกี่ยวข้องกับการสำรวจต้นไม้ทุกต้นในป่าและรวมเอาท์พุทของพวกเขาซึ่งช้ากว่าการใช้แบบจำลองเดียวโดยเนื้อแท้ กระบวนการนี้อาจส่งผลให้เวลาในการทำนายช้ากว่าแบบจำลองที่ง่ายกว่าเช่นการถดถอยโลจิสติกหรือเครือข่ายประสาทโดยเฉพาะอย่างยิ่งสำหรับป่าขนาดใหญ่ที่มีต้นไม้ลึก สำหรับกรณีการใช้งานที่เวลามีสาระสำคัญเช่นการซื้อขายความถี่สูงหรือยานพาหนะอิสระความล่าช้านี้สามารถห้ามได้