
Underfitting ใน Machine Learning คืออะไร?
เผยแพร่แล้ว: 2024-10-16การปรับให้เหมาะสมเป็นปัญหาทั่วไปที่พบในระหว่างการพัฒนาโมเดลแมชชีนเลิร์นนิง (ML) เกิดขึ้นเมื่อโมเดลไม่สามารถเรียนรู้จากข้อมูลการฝึกได้อย่างมีประสิทธิภาพ ส่งผลให้ประสิทธิภาพต่ำกว่ามาตรฐาน ในบทความนี้ เราจะสำรวจว่า underfitting คืออะไร เกิดขึ้นได้อย่างไร และกลยุทธ์ในการหลีกเลี่ยง
สารบัญ
- underfitting คืออะไร?
- Underfitting เกิดขึ้นได้อย่างไร
- ฟิตติ้งด้านล่างกับฟิตติ้งมากเกินไป
- สาเหตุทั่วไปของความไม่เหมาะสม
- วิธีตรวจจับ underfitting
- เทคนิคการป้องกันการสวมใส่น้อยเกินไป
- ตัวอย่างการปฏิบัติของ underfitting
underfitting คืออะไร?
Underfitting คือเมื่อโมเดลแมชชีนเลิร์นนิงไม่สามารถจับรูปแบบที่ซ่อนอยู่ในข้อมูลการฝึกได้ ส่งผลให้ทั้งข้อมูลการฝึกและการทดสอบมีประสิทธิภาพต่ำ เมื่อสิ่งนี้เกิดขึ้น หมายความว่าแบบจำลองนั้นเรียบง่ายเกินไป และไม่สามารถแสดงความสัมพันธ์ที่สำคัญที่สุดของข้อมูลได้ดี ด้วยเหตุนี้ โมเดลจึงพยายามดิ้นรนเพื่อคาดการณ์ข้อมูลทั้งหมดอย่างแม่นยำ ทั้งข้อมูลที่เห็นระหว่างการฝึกและข้อมูลใหม่ที่มองไม่เห็น
Underfitting เกิดขึ้นได้อย่างไร?
Underfitting เกิดขึ้นเมื่ออัลกอริธึมการเรียนรู้ของเครื่องสร้างแบบจำลองที่ไม่สามารถจับคุณสมบัติที่สำคัญที่สุดของข้อมูลการฝึกอบรมได้ โมเดลที่ล้มเหลวในลักษณะนี้ถือว่าง่ายเกินไป ตัวอย่างเช่น ลองจินตนาการว่าคุณกำลังใช้การถดถอยเชิงเส้นเพื่อคาดการณ์ยอดขายตามการใช้จ่ายทางการตลาด ข้อมูลประชากรของลูกค้า และฤดูกาล การถดถอยเชิงเส้นจะถือว่าความสัมพันธ์ระหว่างปัจจัยเหล่านี้กับยอดขายสามารถแสดงเป็นเส้นตรงผสมกันได้
แม้ว่าความสัมพันธ์ที่แท้จริงระหว่างการใช้จ่ายด้านการตลาดและการขายอาจเป็นเส้นโค้งหรือรวมถึงการโต้ตอบหลายอย่าง (เช่น ยอดขายที่เพิ่มขึ้นอย่างรวดเร็วในช่วงแรก จากนั้นจึงสูงขึ้น) โมเดลเชิงเส้นจะลดความซับซ้อนลงโดยการวาดเส้นตรง การลดความซับซ้อนนี้พลาดความแตกต่างที่สำคัญ ส่งผลให้การคาดการณ์และประสิทธิภาพโดยรวมไม่ดี
ปัญหานี้พบได้ทั่วไปในโมเดล ML จำนวนมากซึ่งมีอคติสูง (สมมติฐานที่เข้มงวด) ขัดขวางไม่ให้โมเดลเรียนรู้รูปแบบที่จำเป็น ส่งผลให้ทำงานได้ไม่ดีทั้งกับข้อมูลการฝึกอบรมและการทดสอบ โดยทั่วไปจะเห็นการ underfitting เมื่อแบบจำลองง่ายเกินไปที่จะแสดงถึงความซับซ้อนที่แท้จริงของข้อมูล
ฟิตติ้งด้านล่างกับฟิตติ้งมากเกินไป
ใน ML การปรับด้านล่างและการปรับมากเกินไปเป็นปัญหาทั่วไปที่อาจส่งผลเสียต่อความสามารถของแบบจำลองในการคาดการณ์ที่แม่นยำ การทำความเข้าใจความแตกต่างระหว่างทั้งสองเป็นสิ่งสำคัญสำหรับการสร้างแบบจำลองที่สามารถสรุปข้อมูลใหม่ได้ดี
- Underfittingเกิดขึ้นเมื่อโมเดลเรียบง่ายเกินไปและไม่สามารถจับรูปแบบที่สำคัญในข้อมูลได้ สิ่งนี้นำไปสู่การคาดการณ์ที่ไม่ถูกต้องสำหรับทั้งข้อมูลการฝึกอบรมและข้อมูลใหม่
- การปรับมากเกินไปเกิดขึ้นเมื่อแบบจำลองมีความซับซ้อนมากเกินไป ไม่เพียงแต่การปรับรูปแบบที่แท้จริงเท่านั้น แต่ยังรวมถึงสัญญาณรบกวนในข้อมูลการฝึกด้วย ซึ่งทำให้โมเดลทำงานได้ดีในชุดการฝึกแต่ทำได้ไม่ดีกับข้อมูลใหม่ที่มองไม่เห็น
เพื่ออธิบายแนวคิดเหล่านี้ได้ดีขึ้น ให้พิจารณาแบบจำลองที่คาดการณ์ประสิทธิภาพของกีฬาตามระดับความเครียด จุดสีน้ำเงินในแผนภูมิแสดงถึงจุดข้อมูลจากชุดการฝึก ในขณะที่เส้นแสดงการคาดการณ์ของแบบจำลองหลังจากได้รับการฝึกกับข้อมูลนั้น 
1 การปรับด้านล่าง:ในกรณีนี้ โมเดลจะใช้เส้นตรงธรรมดาเพื่อคาดการณ์ประสิทธิภาพ แม้ว่าความสัมพันธ์จริงจะโค้งก็ตาม เนื่องจากเส้นไม่พอดีกับข้อมูล โมเดลจึงเรียบง่ายเกินไปและไม่สามารถจับรูปแบบที่สำคัญได้ ส่งผลให้เกิดการคาดการณ์ที่ไม่ดี นี่เป็นสิ่งที่ไม่เหมาะสม โดยที่โมเดลไม่สามารถเรียนรู้คุณสมบัติที่มีประโยชน์ที่สุดของข้อมูลได้
2 ความพอดีที่เหมาะสมที่สุด:ในกรณีนี้ โมเดลจะพอดีกับส่วนโค้งของข้อมูลอย่างเหมาะสมเพียงพอ โดยจะจับแนวโน้มที่ซ่อนอยู่โดยไม่ไวต่อจุดข้อมูลหรือสัญญาณรบกวนที่เฉพาะเจาะจงมากเกินไป นี่คือสถานการณ์ที่ต้องการ โดยที่โมเดลสามารถสรุปภาพรวมได้ดีพอสมควร และสามารถคาดการณ์ข้อมูลใหม่ที่คล้ายคลึงกันได้อย่างแม่นยำ อย่างไรก็ตาม ลักษณะทั่วไปยังคงเป็นเรื่องที่ท้าทายเมื่อต้องเผชิญกับชุดข้อมูลที่แตกต่างกันหรือซับซ้อนมากขึ้น
3 การติดตั้งมากเกินไป:ในสถานการณ์การติดตั้งมากเกินไป แบบจำลองจะติดตามจุดข้อมูลเกือบทุกจุดอย่างใกล้ชิด รวมถึงสัญญาณรบกวนและความผันผวนแบบสุ่มในข้อมูลการฝึก แม้ว่าแบบจำลองจะทำงานได้ดีมากในชุดการฝึก แต่ก็มีความจำเพาะเจาะจงกับข้อมูลการฝึกมากเกินไป และจะมีประสิทธิภาพน้อยลงเมื่อคาดการณ์ข้อมูลใหม่ เป็นการยากที่จะสรุปและมีแนวโน้มที่จะคาดการณ์ที่ไม่ถูกต้องเมื่อนำไปใช้กับสถานการณ์ที่มองไม่เห็น
สาเหตุทั่วไปของความไม่เหมาะสม
มีสาเหตุหลายประการที่ทำให้อุปกรณ์ไม่พอดี สี่ประการที่พบบ่อยที่สุดคือ:
- สถาปัตยกรรมแบบจำลองนั้นง่ายเกินไป
- การเลือกคุณสมบัติที่ไม่ดี
- ข้อมูลการฝึกอบรมไม่เพียงพอ
- การฝึกอบรมไม่เพียงพอ
มาเจาะลึกสิ่งเหล่านี้อีกสักหน่อยเพื่อทำความเข้าใจพวกเขา
สถาปัตยกรรมแบบจำลองนั้นง่ายเกินไป
สถาปัตยกรรมโมเดลหมายถึงการผสมผสานระหว่างอัลกอริธึมที่ใช้ในการฝึกโมเดลและโครงสร้างของโมเดล หากสถาปัตยกรรมเรียบง่ายเกินไป อาจมีปัญหาในการจับคุณสมบัติระดับสูงของข้อมูลการฝึก ซึ่งนำไปสู่การคาดการณ์ที่ไม่ถูกต้อง
ตัวอย่างเช่น หากแบบจำลองพยายามใช้เส้นตรงเส้นเดียวในการสร้างแบบจำลองข้อมูลที่เป็นไปตามรูปแบบโค้ง โมเดลนั้นจะมีความพอดีสม่ำเสมอ เนื่องจากเส้นตรงไม่สามารถแสดงความสัมพันธ์ระดับสูงในข้อมูลโค้งได้อย่างแม่นยำ ทำให้สถาปัตยกรรมของแบบจำลองไม่เพียงพอสำหรับงาน
การเลือกคุณสมบัติไม่ดี
การเลือกคุณสมบัติเกี่ยวข้องกับการเลือกตัวแปรที่เหมาะสมสำหรับโมเดล ML ในระหว่างการฝึก ตัวอย่างเช่น คุณอาจขอให้อัลกอริทึม ML ดูปีเกิด สีตา อายุ หรือทั้งสามอย่างของบุคคลนั้น เมื่อคาดการณ์ว่าบุคคลนั้นจะกดปุ่มซื้อบนเว็บไซต์อีคอมเมิร์ซหรือไม่
หากมีคุณลักษณะมากเกินไป หรือคุณลักษณะที่เลือกไม่สัมพันธ์กับตัวแปรเป้าหมายมากนัก โมเดลก็จะมีข้อมูลที่เกี่ยวข้องไม่เพียงพอที่จะคาดการณ์ได้อย่างแม่นยำ สีตาอาจไม่เกี่ยวข้องกับการแปลง และอายุจะรวบรวมข้อมูลเดียวกันกับปีเกิด
ข้อมูลการฝึกอบรมไม่เพียงพอ
เมื่อมีจุดข้อมูลน้อยเกินไป โมเดลอาจไม่เหมาะสมเนื่องจากข้อมูลไม่ได้รวบรวมคุณสมบัติที่สำคัญที่สุดของปัญหา สิ่งนี้สามารถเกิดขึ้นได้เนื่องจากขาดข้อมูลหรือเนื่องจากอคติในการสุ่มตัวอย่าง โดยที่แหล่งข้อมูลบางแหล่งถูกแยกออกหรือแสดงน้อยเกินไป ส่งผลให้โมเดลไม่สามารถเรียนรู้รูปแบบที่สำคัญได้

การฝึกอบรมไม่เพียงพอ
การฝึกอบรมโมเดล ML เกี่ยวข้องกับการปรับพารามิเตอร์ภายใน (น้ำหนัก) ตามความแตกต่างระหว่างการคาดการณ์และผลลัพธ์จริง ยิ่งมีการฝึกซ้ำแบบจำลองมากเท่าใด แบบจำลองก็จะสามารถปรับให้เหมาะกับข้อมูลได้ดียิ่งขึ้นเท่านั้น หากโมเดลได้รับการฝึกฝนด้วยการวนซ้ำน้อยเกินไป โมเดลนั้นอาจไม่มีโอกาสเพียงพอที่จะเรียนรู้จากข้อมูล ซึ่งนำไปสู่ความเหมาะสมน้อยเกินไป
วิธีตรวจจับ underfitting
วิธีหนึ่งในการตรวจสอบการติดตั้งด้านล่างคือการวิเคราะห์กราฟการเรียนรู้ ซึ่งจะพล็อตประสิทธิภาพของแบบจำลอง (โดยทั่วไปคือการสูญเสียหรือข้อผิดพลาด) เทียบกับจำนวนครั้งของการฝึกซ้ำ เส้นโค้งการเรียนรู้แสดงให้เห็นว่าแบบจำลองปรับปรุงอย่างไร (หรือล้มเหลวในการปรับปรุง) เมื่อเวลาผ่านไปทั้งในชุดข้อมูลการฝึกอบรมและการตรวจสอบความถูกต้อง
การสูญเสียคือขนาดของข้อผิดพลาดของแบบจำลองสำหรับชุดข้อมูลที่กำหนด การสูญเสียการฝึกอบรมจะวัดสิ่งนี้สำหรับข้อมูลการฝึกอบรมและการสูญเสียการตรวจสอบสำหรับข้อมูลการตรวจสอบ ข้อมูลการตรวจสอบเป็นชุดข้อมูลแยกต่างหากที่ใช้ในการทดสอบประสิทธิภาพของแบบจำลอง โดยปกติแล้วจะเกิดจากการสุ่มแยกชุดข้อมูลขนาดใหญ่ออกเป็นข้อมูลการฝึกอบรมและการตรวจสอบความถูกต้อง
ในกรณีของการประกอบส่วนล่าง คุณจะสังเกตเห็นรูปแบบหลักๆ ดังต่อไปนี้:
- การสูญเสียการฝึกสูง:หากการสูญเสียการฝึกของแบบจำลองยังคงอยู่ในระดับสูงและเป็นเส้นตรงในช่วงต้นของกระบวนการ แสดงว่าแบบจำลองไม่ได้เรียนรู้จากข้อมูลการฝึก นี่เป็นสัญญาณที่ชัดเจนของการปรับให้เหมาะสม เนื่องจากแบบจำลองนี้ง่ายเกินไปที่จะปรับให้เข้ากับความซับซ้อนของข้อมูล
- การสูญเสียการฝึกอบรมและการตรวจสอบที่คล้ายกัน:หากการสูญเสียทั้งการฝึกอบรมและการตรวจสอบความถูกต้องสูงและยังคงอยู่ใกล้กันตลอดกระบวนการฝึกอบรม นั่นหมายความว่าโมเดลมีประสิทธิภาพต่ำกว่าชุดข้อมูลทั้งสอง สิ่งนี้บ่งชี้ว่าแบบจำลองไม่ได้รวบรวมข้อมูลจากข้อมูลเพียงพอที่จะทำการคาดการณ์ได้อย่างแม่นยำ ซึ่งชี้ไปที่ความไม่เหมาะสม
ด้านล่างนี้คือแผนภูมิตัวอย่างที่แสดงเส้นโค้งการเรียนรู้ในสถานการณ์ที่ไม่เหมาะสม:
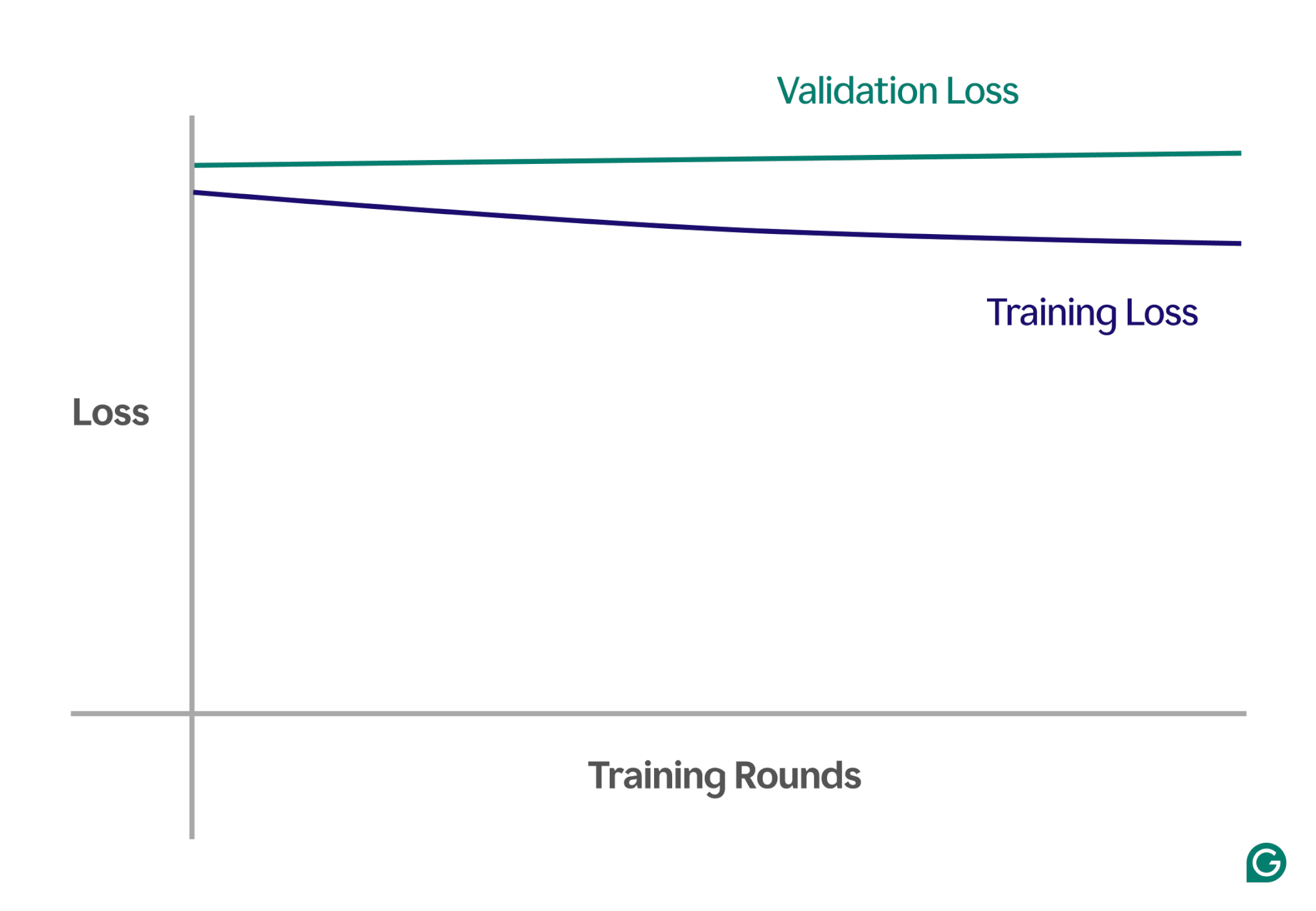
ในการแสดงภาพนี้ การติดตั้งด้านล่างนั้นสังเกตได้ง่าย:
- ในแบบจำลองที่เหมาะสม การสูญเสียการฝึกจะลดลงอย่างมาก ในขณะที่การสูญเสียการตรวจสอบความถูกต้องเป็นไปตามรูปแบบที่คล้ายกัน และจะมีเสถียรภาพในที่สุด
- ในโมเดลที่ไม่ได้รับการติดตั้ง ทั้งการสูญเสียการฝึกอบรมและการตรวจสอบจะเริ่มต้นสูงและคงอยู่ในระดับสูง โดยไม่มีการปรับปรุงที่สำคัญใดๆ
ด้วยการสังเกตแนวโน้มเหล่านี้ คุณสามารถระบุได้อย่างรวดเร็วว่าแบบจำลองนั้นง่ายเกินไปหรือไม่ และจำเป็นต้องปรับเปลี่ยนเพื่อเพิ่มความซับซ้อนหรือไม่
เทคนิคการป้องกันการสวมใส่น้อยเกินไป
หากคุณพบว่ามีการติดตั้งไม่เพียงพอ มีกลยุทธ์หลายประการที่คุณสามารถใช้เพื่อปรับปรุงประสิทธิภาพของแบบจำลอง:
- ข้อมูลการฝึกอบรมเพิ่มเติม:หากเป็นไปได้ ให้รับข้อมูลการฝึกอบรมเพิ่มเติม ข้อมูลเพิ่มเติมจะทำให้โมเดลมีโอกาสเพิ่มเติมในการเรียนรู้รูปแบบ โดยที่ข้อมูลมีคุณภาพสูงและเกี่ยวข้องกับปัญหาที่เกิดขึ้น
- ขยายการเลือกคุณสมบัติ:เพิ่มคุณสมบัติโมเดลที่เกี่ยวข้องมากขึ้นไปยังคุณสมบัติโมเดล เลือกคุณลักษณะที่มีความสัมพันธ์ที่ดีกับตัวแปรเป้าหมาย ทำให้โมเดลมีโอกาสมากขึ้นในการจับภาพรูปแบบที่สำคัญที่พลาดไปก่อนหน้านี้
- เพิ่มพลังทางสถาปัตยกรรม:ในโมเดลที่ใช้โครงข่ายประสาทเทียม คุณสามารถปรับโครงสร้างสถาปัตยกรรมโดยการเปลี่ยนจำนวนน้ำหนัก เลเยอร์ หรือไฮเปอร์พารามิเตอร์อื่นๆ ซึ่งจะช่วยให้โมเดลมีความยืดหยุ่นมากขึ้นและค้นหารูปแบบระดับสูงในข้อมูลได้ง่ายขึ้น
- เลือกรุ่นอื่น:บางครั้ง แม้หลังจากปรับไฮเปอร์พารามิเตอร์แล้ว โมเดลเฉพาะอาจไม่เหมาะกับงาน การทดสอบอัลกอริธึมโมเดลหลายแบบสามารถช่วยค้นหาโมเดลที่เหมาะสมยิ่งขึ้นและปรับปรุงประสิทธิภาพได้
ตัวอย่างการปฏิบัติของ underfitting
เพื่อแสดงให้เห็นถึงผลกระทบของการปรับให้เหมาะสม เรามาดูตัวอย่างจากโลกแห่งความเป็นจริงในโดเมนต่างๆ ที่แบบจำลองไม่สามารถจับความซับซ้อนของข้อมูลได้ ซึ่งนำไปสู่การคาดการณ์ที่ไม่ถูกต้อง
การทำนายราคาบ้าน
การจะทำนายราคาบ้านได้อย่างแม่นยำนั้น คุณจะต้องพิจารณาปัจจัยหลายประการ เช่น ที่ตั้ง ขนาด ประเภทบ้าน สภาพ และจำนวนห้องนอน
หากคุณใช้คุณสมบัติน้อยเกินไป เช่น ขนาดและประเภทของบ้าน โมเดลจะไม่สามารถเข้าถึงข้อมูลที่สำคัญได้ ตัวอย่างเช่น โมเดลอาจถือว่าสตูดิโอขนาดเล็กมีราคาไม่แพง โดยไม่รู้ว่าตั้งอยู่ในเมย์แฟร์ ลอนดอน ซึ่งเป็นพื้นที่ที่ราคาทรัพย์สินสูง สิ่งนี้นำไปสู่การทำนายที่ไม่ดี
เพื่อแก้ไขปัญหานี้ นักวิทยาศาสตร์ข้อมูลจะต้องแน่ใจว่าได้เลือกคุณสมบัติที่เหมาะสม ซึ่งเกี่ยวข้องกับการรวมคุณสมบัติที่เกี่ยวข้องทั้งหมด ยกเว้นคุณสมบัติที่ไม่เกี่ยวข้อง และการใช้ข้อมูลการฝึกอบรมที่แม่นยำ
การรู้จำเสียง
เทคโนโลยีการจดจำเสียงเริ่มแพร่หลายมากขึ้นในชีวิตประจำวัน ตัวอย่างเช่น ผู้ช่วยสมาร์ทโฟน สายด่วนบริการลูกค้า และเทคโนโลยีช่วยเหลือสำหรับผู้พิการ ต่างก็ใช้การรู้จำเสียง เมื่อฝึกโมเดลเหล่านี้ จะใช้ข้อมูลจากตัวอย่างคำพูดและการตีความที่ถูกต้อง
ในการจดจำคำพูด โมเดลจะแปลงคลื่นเสียงที่ไมโครโฟนจับไว้เป็นข้อมูล หากเราทำให้สิ่งนี้ง่ายขึ้นโดยระบุเฉพาะความถี่และระดับเสียงที่โดดเด่นในช่วงเวลาที่กำหนด เราจะลดปริมาณข้อมูลที่โมเดลต้องประมวลผล
อย่างไรก็ตาม วิธีการนี้จะตัดข้อมูลที่จำเป็นออกไปเพื่อทำความเข้าใจคำพูดอย่างถ่องแท้ ข้อมูลกลายเป็นเรื่องง่ายเกินไปที่จะจับความซับซ้อนของคำพูดของมนุษย์ เช่น ความแปรผันของน้ำเสียง ระดับเสียงสูงต่ำ และสำเนียง
ผลที่ตามมาก็คือโมเดลจะมีความพอดี และมีปัญหาในการจดจำแม้แต่คำสั่งคำพื้นฐาน ไม่ต้องพูดถึงการเติมประโยคให้สมบูรณ์ แม้ว่าแบบจำลองจะซับซ้อนเพียงพอ แต่การขาดข้อมูลที่ครอบคลุมก็นำไปสู่การปรับให้เหมาะสม
การจำแนกประเภทภาพ
ตัวแยกประเภทรูปภาพได้รับการออกแบบเพื่อใช้รูปภาพเป็นอินพุตและเอาต์พุตคำเพื่ออธิบาย สมมติว่าคุณกำลังสร้างแบบจำลองเพื่อตรวจสอบว่ารูปภาพมีลูกบอลหรือไม่ คุณฝึกโมเดลโดยใช้รูปภาพลูกบอลและวัตถุอื่นๆ ที่มีป้ายกำกับ
หากคุณใช้โครงข่ายประสาทเทียมสองชั้นแบบธรรมดาโดยไม่ตั้งใจ แทนที่จะเป็นแบบจำลองที่เหมาะสมกว่า เช่น โครงข่ายประสาทเทียมแบบหมุนวน (CNN) โมเดลนั้นจะประสบปัญหา เครือข่ายสองชั้นทำให้ภาพเรียบเป็นชั้นเดียว ทำให้สูญเสียข้อมูลเชิงพื้นที่ที่สำคัญ นอกจากนี้ เนื่องจากมีเพียงสองชั้น โมเดลจึงขาดความสามารถในการระบุคุณลักษณะที่ซับซ้อน
สิ่งนี้นำไปสู่การ underfitting เนื่องจากแบบจำลองจะไม่สามารถคาดการณ์ได้อย่างแม่นยำ แม้แต่ในข้อมูลการฝึกก็ตาม CNN แก้ไขปัญหานี้ด้วยการรักษาโครงสร้างเชิงพื้นที่ของภาพ และใช้เลเยอร์แบบหมุนวนพร้อมตัวกรองที่เรียนรู้โดยอัตโนมัติเพื่อตรวจจับคุณสมบัติที่สำคัญ เช่น ขอบและรูปร่างในเลเยอร์แรกๆ และวัตถุที่ซับซ้อนมากขึ้นในเลเยอร์ต่อๆ ไป