
Evrişimsel Sinir Ağı Temelleri: Bilmeniz Gerekenler
Yayınlanan: 2024-09-10Evrişimli sinir ağları (CNN'ler), veri analizi ve makine öğreniminde (ML) temel araçlardır. Bu kılavuz, CNN'lerin nasıl çalıştığını, diğer sinir ağlarından nasıl farklı olduklarını, uygulamalarını ve kullanımlarıyla ilgili avantaj ve dezavantajları açıklamaktadır.
İçindekiler
- CNN nedir?
- CNN'ler nasıl çalışır?
- CNN'ler ve RNN'ler ve transformatörler
- CNN'lerin uygulamaları
- Avantajları
- Dezavantajları
Evrişimli sinir ağı nedir?
Evrişimli sinir ağı (CNN), mekansal verileri işlemek ve analiz etmek için tasarlanmış, derin öğrenmenin ayrılmaz bir parçası olan bir sinir ağıdır. Giriş içindeki önemli özellikleri otomatik olarak tespit etmek ve öğrenmek için filtreli evrişimli katmanlar kullanır, bu da onu özellikle görüntü ve video tanıma gibi görevlerde etkili kılar.
Bu tanımı biraz açalım. Uzamsal veriler, parçaların konumları aracılığıyla birbirleriyle ilişkili olduğu verilerdir. Görseller buna en iyi örnektir.
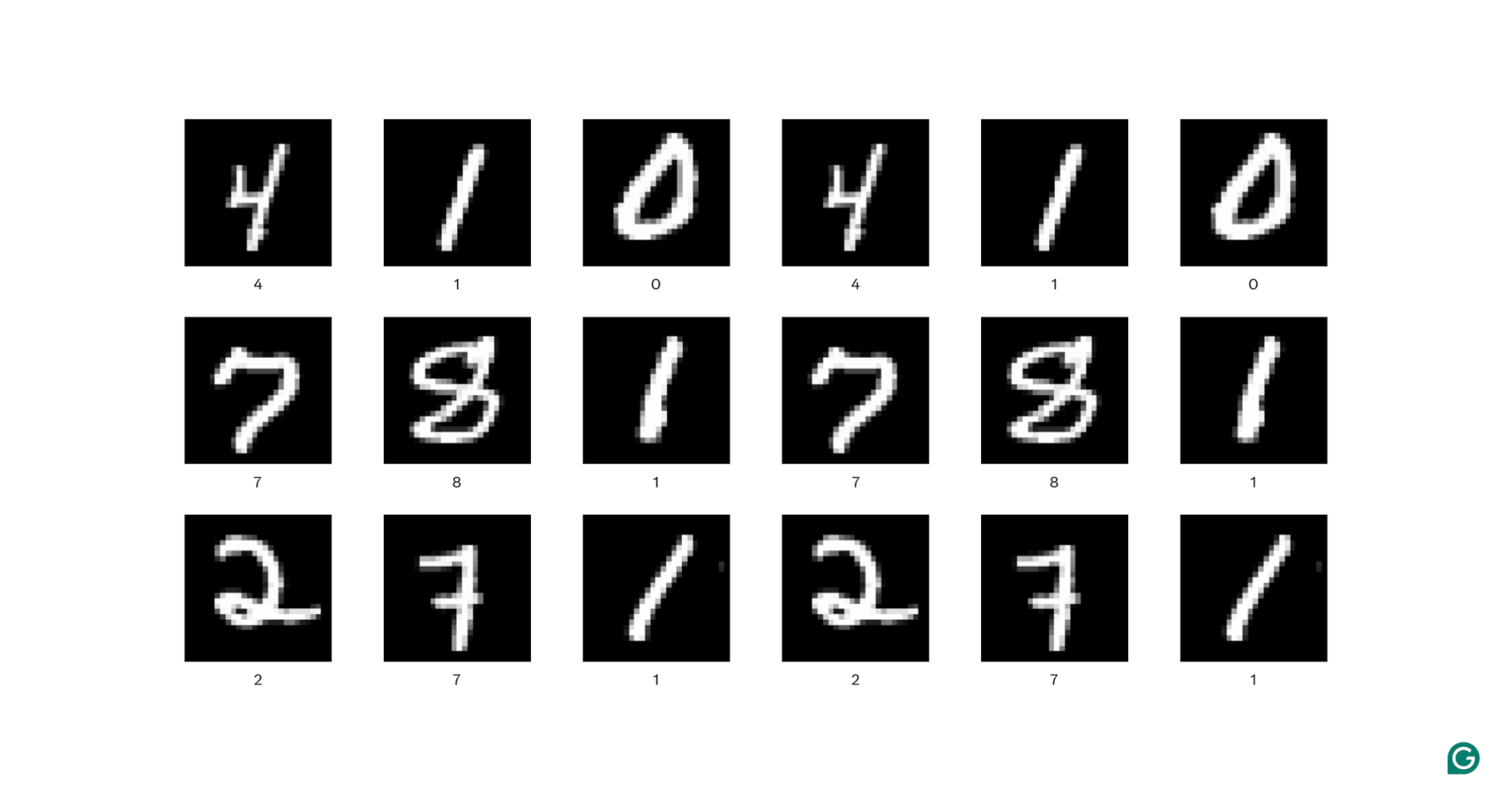
Yukarıdaki görsellerin her birinde, her bir beyaz piksel, kendisini çevreleyen her bir beyaz piksele bağlıdır: Rakamı oluştururlar. Piksel konumları aynı zamanda izleyiciye rakamın görüntü içinde nerede bulunduğunu da söyler.

Özellikler görüntüde mevcut olan niteliklerdir. Bu nitelikler, hafif eğimli bir kenardan, bir burun veya gözün varlığına ve gözler, ağızlar ve burunların bileşimine kadar herhangi bir şey olabilir. Daha da önemlisi, özellikler daha basit özelliklerden oluşabilir (örneğin, bir göz birkaç kavisli kenardan ve merkezi bir karanlık noktadan oluşur).
Filtreler, modelin görüntüdeki bu özellikleri tespit eden kısmıdır. Her filtre, görüntünün tamamı boyunca belirli bir özelliği (örneğin, soldan sağa doğru bir kenar kıvrımı) arar.
Son olarak, evrişimli sinir ağındaki “evrişimli”, bir filtrenin görüntüye nasıl uygulandığını ifade eder. Bunu bir sonraki bölümde açıklayacağız.
CNN'ler, nesne algılama ve görüntü bölümleme gibi çeşitli görüntü görevlerinde güçlü performans göstermiştir. Bir CNN modeli (AlexNet), 2012 yılında derin öğrenmenin yükselişinde önemli bir rol oynadı.
CNN'ler nasıl çalışır?
Bir görüntüde hangi sayının (0-9) olduğunu belirleme örneğini kullanarak bir CNN'nin genel mimarisini inceleyelim.
Görüntüyü modele beslemeden önce görüntünün sayısal bir temsile (veya kodlamaya) dönüştürülmesi gerekir. Siyah beyaz görüntüler için her piksele bir sayı atanır: Tamamen beyazsa 255, tamamen siyahsa 0 (bazen 1 ve 0'a normalleştirilir). Renkli görüntüler için her piksele üç sayı atanır: biri, içerdiği kırmızı, yeşil ve maviyi gösterir; RGB değeri olarak bilinir. Yani 256×256 piksellik (65.536 pikselli) bir görüntünün siyah-beyaz kodlamasında 65.536 değeri ve renk kodlamasında 196.608 değeri olacaktır.
Model daha sonra görüntüyü üç tür katman aracılığıyla işler:
1 Evrişimsel katman:Bu katman, girişine filtreler uygular. Her filtre, tanımlanmış boyuttaki (örn. 3×3) sayılardan oluşan bir ızgaradır. Bu ızgara, sol üst köşeden başlayarak görüntünün üzerine yerleştirilmiştir; 1-3. sütunlardaki 1-3. satırlardaki piksel değerleri kullanılacaktır. Bu piksel değerleri filtredeki değerlerle çarpılır ve toplanır. Bu toplam daha sonra filtre çıktı ızgarasının 1. satırının 1. sütununa yerleştirilir. Daha sonra filtre bir piksel sağa kayar ve görüntüdeki tüm satır ve sütunları kaplayana kadar işlemi tekrarlar. Filtre, bir seferde bir pikseli kaydırarak görüntünün herhangi bir yerindeki özellikleri bulabilir; bu, çeviri değişmezliği olarak bilinen bir özelliktir. Her filtre kendi çıktı ızgarasını oluşturur ve bu daha sonra bir sonraki katmana gönderilir.
2 Havuzlama katmanı: Bu katman, evrişim katmanından gelen özellik bilgilerini özetler. Evrişim katmanı, girişinden daha büyük bir çıktı döndürür (her filtre, girişle yaklaşık olarak aynı boyutta bir özellik haritası döndürür ve birden fazla filtre vardır). Havuzlama katmanı her özellik haritasını alır ve ona başka bir ızgara uygular. Bu ızgara, içindeki değerlerin ortalamasını veya maksimumunu alır ve çıktısını verir. Ancak bu ızgara her seferinde bir piksel hareket etmiyor; bir sonraki piksel yamasına atlayacaktır. Örneğin, 3x3'lük bir havuzlama ızgarası ilk önce 1-3. satırlardaki ve 1-3. sütunlardaki pikseller üzerinde çalışacaktır. Daha sonra aynı satırda kalacak ancak 4-6. sütunlara geçecektir. İlk satır grubundaki (1-3) tüm sütunları kapladıktan sonra, 4-6. satırlara inecek ve bu sütunlarla ilgilenecektir. Bu, çıktıdaki satır ve sütun sayısını etkili bir şekilde azaltır. Havuzlama katmanı karmaşıklığın azaltılmasına yardımcı olur, modeli gürültüye ve küçük değişikliklere karşı daha dayanıklı hale getirir ve modelin en önemli özelliklere odaklanmasına yardımcı olur.
3 Tamamen bağlantılı katman: Evrişim ve havuzlama katmanlarının birçok turundan sonra, son özellik haritaları, ilgilendiğimiz çıktıyı (örneğin, görüntünün belirli bir sayı olma olasılığı) döndüren, tamamen bağlı bir sinir ağı katmanına aktarılır. Özellik haritaları düzleştirilmeli (bir özellik haritasının her satırı bir uzun satırda birleştirilmelidir) ve daha sonra birleştirilmelidir (her uzun özellik haritası satırı bir mega satırda birleştirilmelidir).
Aşağıda, her katmanın giriş görüntüsünü nasıl işlediğini ve nihai çıktıya nasıl katkıda bulunduğunu gösteren, CNN mimarisinin görsel bir temsili bulunmaktadır:

Süreçle ilgili birkaç ek not:
- Her ardışık evrişim katmanı daha yüksek seviyeli özellikler bulur. İlk evrişimli katman kenarları, noktaları veya basit desenleri algılar. Bir sonraki evrişimli katman, birinci evrişimli katmanın havuzlanmış çıktısını girdi olarak alır ve burun veya göz gibi daha yüksek seviyeli özellikler oluşturan daha düşük seviyeli özelliklerin bileşimlerini tespit etmesini sağlar.
- Model eğitim gerektirir. Eğitim sırasında, bir görüntü tüm katmanlardan (ilk başta rastgele ağırlıklarla) geçirilir ve çıktı oluşturulur. Çıktı ile gerçek cevap arasındaki fark, ağırlıkları biraz ayarlamak için kullanılır, böylece modelin gelecekte doğru cevap verme olasılığı artar. Bu, eğitim algoritmasının her model ağırlığının nihai cevaba ne kadar katkıda bulunduğunu hesapladığı (kısmi türevleri kullanarak) ve bunu doğru cevaba doğru hafifçe hareket ettirdiği gradyan inişiyle yapılır. Havuzlama katmanının herhangi bir ağırlığı yoktur, dolayısıyla eğitim sürecinden etkilenmez.
- CNN'ler yalnızca eğitim aldıkları görsellerle aynı boyuttaki görseller üzerinde çalışabilir. Bir model 256x256 piksellik görüntüler üzerinde eğitilmişse, daha büyük olan herhangi bir görüntünün alt örneklenmesi ve daha küçük olan herhangi bir görüntünün ise üst örneklenmesi gerekecektir.

CNN'ler ve RNN'ler ve transformatörler
Evrişimli sinir ağlarından sıklıkla tekrarlayan sinir ağları (RNN'ler) ve transformatörlerle birlikte bahsedilir. Peki bunlar nasıl farklılık gösteriyor?
CNN'ler ve RNN'ler
RNN'ler ve CNN'ler farklı alanlarda çalışır. RNN'ler metin gibi sıralı veriler için en uygun olanıdır, CNN'ler ise görüntüler gibi mekansal verilerde mükemmeldir. RNN'ler, bir sonraki bölümü bağlamsallaştırmak için bir girdinin daha önce görülen bölümlerini takip eden bir bellek modülüne sahiptir. Buna karşılık, CNN'ler girdinin bazı kısımlarını yakın komşularına bakarak bağlamsallaştırır. CNN'ler bir bellek modülüne sahip olmadıkları için metin görevleri için pek uygun değiller: Son kelimeye ulaştıklarında cümledeki ilk kelimeyi unutuyorlar.
CNN'ler ve transformatörler
Transformatörler ayrıca sıralı görevler için de yoğun olarak kullanılır. Yeni girdiyi bağlamsallaştırmak için girdinin herhangi bir bölümünü kullanabilirler, bu da onları doğal dil işleme (NLP) görevleri için popüler hale getirir. Ancak son zamanlarda görüntü transformatörleri şeklinde transformatörler de görüntülere uygulanmıştır. Bu modeller bir görüntüyü alır, parçalara ayırır, dikkati (transformatör mimarilerindeki temel mekanizma) yamalar üzerinde çalıştırır ve ardından görüntüyü sınıflandırır. Görüntü transformatörleri, büyük veri kümelerinde CNN'lerden daha iyi performans gösterebilir, ancak CNN'lerin doğasında bulunan çeviri değişmezliğinden yoksundurlar. CNN'lerdeki çeviri değişmezliği, modelin nesneleri görüntüdeki konumlarına bakılmaksızın tanımasına olanak tanır ve bu da CNN'leri, özelliklerin mekansal ilişkisinin önemli olduğu görevler için oldukça etkili kılar.
CNN uygulamaları
CNN'ler, çeviri değişmezliği ve mekansal özellikleri nedeniyle sıklıkla görüntülerle birlikte kullanılır. Ancak akıllı işlemeyle CNN'ler diğer alanlarda da çalışabilir (genellikle bunları önce resimlere dönüştürerek).
Görüntü sınıflandırması
Görüntü sınıflandırması CNN'lerin birincil kullanımıdır. İyi eğitimli, büyük CNN'ler milyonlarca farklı nesneyi tanıyabilir ve kendilerine verilen hemen hemen her görüntü üzerinde çalışabilir. Transformatörlerin yükselişine rağmen, CNN'lerin hesaplama verimliliği onları uygulanabilir bir seçenek haline getiriyor.
Konuşma tanıma
Kaydedilen ses, sesin görsel temsili olan spektrogramlar aracılığıyla mekansal verilere dönüştürülebilir. Bir CNN, bir spektrogramı girdi olarak alabilir ve farklı dalga formlarını farklı kelimelerle eşleştirmeyi öğrenebilir. Benzer şekilde, bir CNN müzik ritimlerini ve örneklerini tanıyabilir.
Görüntü segmentasyonu
Görüntü segmentasyonu, bir görüntüdeki farklı nesnelerin etrafındaki sınırların tanımlanmasını ve çizilmesini içerir. CNN'ler, çeşitli nesneleri tanımadaki güçlü performanslarından dolayı bu görev için popülerdir. Bir görüntü bölümlendirildikten sonra içeriğini daha iyi anlayabiliriz. Örneğin başka bir derin öğrenme modeli, bölümleri analiz edip şu sahneyi tanımlayabilir: “İki kişi bir parkta yürüyor. Sağlarında bir elektrik direği, önlerinde ise bir araba var.” Tıp alanında, görüntü segmentasyonu, taramalarda tümörleri normal hücrelerden ayırt edebilir. Otonom araçlar için şerit işaretlerini, yol işaretlerini ve diğer araçları tanımlayabilir.
CNN'lerin avantajları
CNN'ler endüstride çeşitli nedenlerden dolayı yaygın olarak kullanılmaktadır.
Güçlü görüntü performansı
Mevcut görüntü verilerinin bolluğu nedeniyle, çeşitli görüntü türlerinde iyi performans gösteren modellere ihtiyaç duyulmaktadır. CNN'ler bu amaç için çok uygundur. Çeviri değişmezliği ve daha küçük olanlardan daha büyük özellikler oluşturma yetenekleri, bir görüntüdeki özellikleri tespit etmelerine olanak tanır. Temel bir CNN her türlü görüntü verisine uygulanabildiğinden, farklı görüntü türleri için farklı mimarilere gerek yoktur.
Manuel özellik mühendisliği yok
CNN'lerden önce, en iyi performans gösteren görüntü modelleri önemli ölçüde manuel çaba gerektiriyordu. Etki alanı uzmanlarının, çeşitli görüntüler için esneklikten yoksun, zaman alıcı bir süreç olan belirli özellik türlerini (örneğin, kenarlara yönelik filtreler) tespit etmek için modüller oluşturması gerekiyordu. Her görüntü kümesinin kendi özellik kümesine ihtiyacı vardı. Buna karşılık, ilk ünlü CNN (AlexNet), 20.000 görüntü türünü otomatik olarak kategorize ederek manuel özellik mühendisliği ihtiyacını azalttı.
CNN'lerin dezavantajları
Elbette CNN'leri kullanmanın bazı ödünleri var.
Birçok hiperparametre
Bir CNN'nin eğitimi birçok hiper parametrenin seçilmesini içerir. Herhangi bir sinir ağında olduğu gibi katman sayısı, parti boyutu ve öğrenme oranı gibi hiper parametreler vardır. Ek olarak, her filtre kendi hiperparametre kümesini gerektirir: filtre boyutu (örneğin, 3×3, 5×5) ve adım (her adımdan sonra hareket edecek piksel sayısı). Hiperparametreler eğitim süreci sırasında kolayca ayarlanamaz. Bunun yerine, farklı hiperparametre kümeleriyle (örneğin, A kümesi ve B kümesi) birden çok modeli eğitmeniz ve en iyi seçimleri belirlemek için performanslarını karşılaştırmanız gerekir.
Giriş boyutuna duyarlılık
Her CNN, belirli bir boyuttaki (örneğin, 256x256 piksel) bir görüntüyü kabul edecek şekilde eğitilir. İşlemek istediğiniz birçok görüntü bu boyutla eşleşmeyebilir. Bu sorunu çözmek için görsellerinizi büyütebilir veya küçültebilirsiniz. Ancak bu yeniden boyutlandırma, değerli bilgilerin kaybına yol açabilir ve modelin performansını düşürebilir.