
Tekrarlayan Sinir Ağı Temelleri: Bilmeniz Gerekenler
Yayınlanan: 2024-09-19Tekrarlayan sinir ağları (RNN'ler), veri analizi, makine öğrenimi (ML) ve derin öğrenme alanlarında temel yöntemlerdir. Bu makale, RNN'leri keşfetmeyi ve daha geniş derin öğrenme bağlamında işlevlerini, uygulamalarını, avantajlarını ve dezavantajlarını detaylandırmayı amaçlamaktadır.
İçindekiler
RNN nedir?
RNN'ler nasıl çalışır?
RNN Türleri
RNN'ler ve transformatörler ve CNN'ler
RNN'lerin uygulamaları
Avantajları
Dezavantajları
Tekrarlayan sinir ağı nedir?
Tekrarlayan bir sinir ağı, dahili bir hafızayı koruyarak sıralı verileri işleyebilen ve çıktı üretmek için geçmiş girdileri takip etmesine olanak tanıyan derin bir sinir ağıdır. RNN'ler derin öğrenmenin temel bir bileşenidir ve özellikle sıralı verileri içeren görevler için uygundur.
“Tekrarlayan sinir ağı”ndaki “tekrarlayan”, modelin geçmiş girdilerden gelen bilgileri mevcut girdilerle nasıl birleştirdiğini ifade eder. Eski girişlerden gelen bilgiler, "gizli durum" adı verilen bir tür dahili hafızada saklanır. Sürekli bir bilgi akışı oluşturmak için önceki hesaplamaları kendi içine besleyerek tekrarlanır.
Bir örnekle gösterelim: Diyelim ki, "O pastayı mutlu bir şekilde yedi." cümlesinin duygusunu (olumlu veya olumsuz) tespit etmek için bir RNN kullanmak istediğimizi varsayalım. RNN,hekelimesini işler, bu kelimeyi dahil etmek için gizli durumunu günceller ve ardındanate'yegeçer, bunuhe'denöğrendiği şeylerle birleştirir ve cümle bitene kadar her kelimeyle bu şekilde devam eder. Perspektife koymak gerekirse, bu cümleyi okuyan bir insan, her kelimeyle anlayışını güncelleyecektir. Cümlenin tamamını okuyup anladıktan sonra insan, cümlenin olumlu ya da olumsuz olduğunu söyleyebilir. Bu insani anlama süreci, gizli durumun yaklaşmaya çalıştığı şeydir.
RNN'ler temel derin öğrenme modellerinden biridir. Transformatörler onların yerini almış olsa da, doğal dil işleme (NLP) görevlerinde çok iyi iş çıkardılar. Transformatörler, örneğin verileri paralel olarak işleyerek ve kaynak metinde birbirlerinden çok uzakta olan kelimeler arasındaki ilişkileri keşfederek (dikkat mekanizmalarını kullanarak) RNN performansını artıran gelişmiş sinir ağı mimarileridir. Ancak RNN'ler zaman serisi verileri ve daha basit modellerin yeterli olduğu durumlar için hala kullanışlıdır.
RNN'ler nasıl çalışır?
RNN'lerin nasıl çalıştığını ayrıntılı olarak anlatmak için önceki örnek göreve dönelim: "Pastayı mutlu bir şekilde yedi." cümlesinin duygusunu sınıflandırın.
Metin girişlerini kabul eden ve ikili bir çıktı döndüren (1 pozitifi ve 0 negatifi temsil eden) eğitimli bir RNN ile başlıyoruz. Modele girdi verilmeden önce gizli durum geneldir; eğitim sürecinden öğrenilmiştir ancak henüz girdiye özel değildir.
İlk kelime olanHemodele aktarılır. RNN'nin içinde, gizli durumu daha sonraHekelimesini içerecek şekilde güncellenir (gizli durum h1'e). Daha sonra,atekelimesi RNN'ye iletilir ve h1, bu yeni kelimeyi içerecek şekilde güncellenir (h2'ye). Bu işlem, son kelime aktarılana kadar yinelenir. Gizli durum (h4), son kelimeyi içerecek şekilde güncellenir. Daha sonra güncellenen gizli durum, 0 veya 1 değerini oluşturmak için kullanılır.
RNN sürecinin nasıl çalıştığının görsel bir temsili aşağıda verilmiştir:
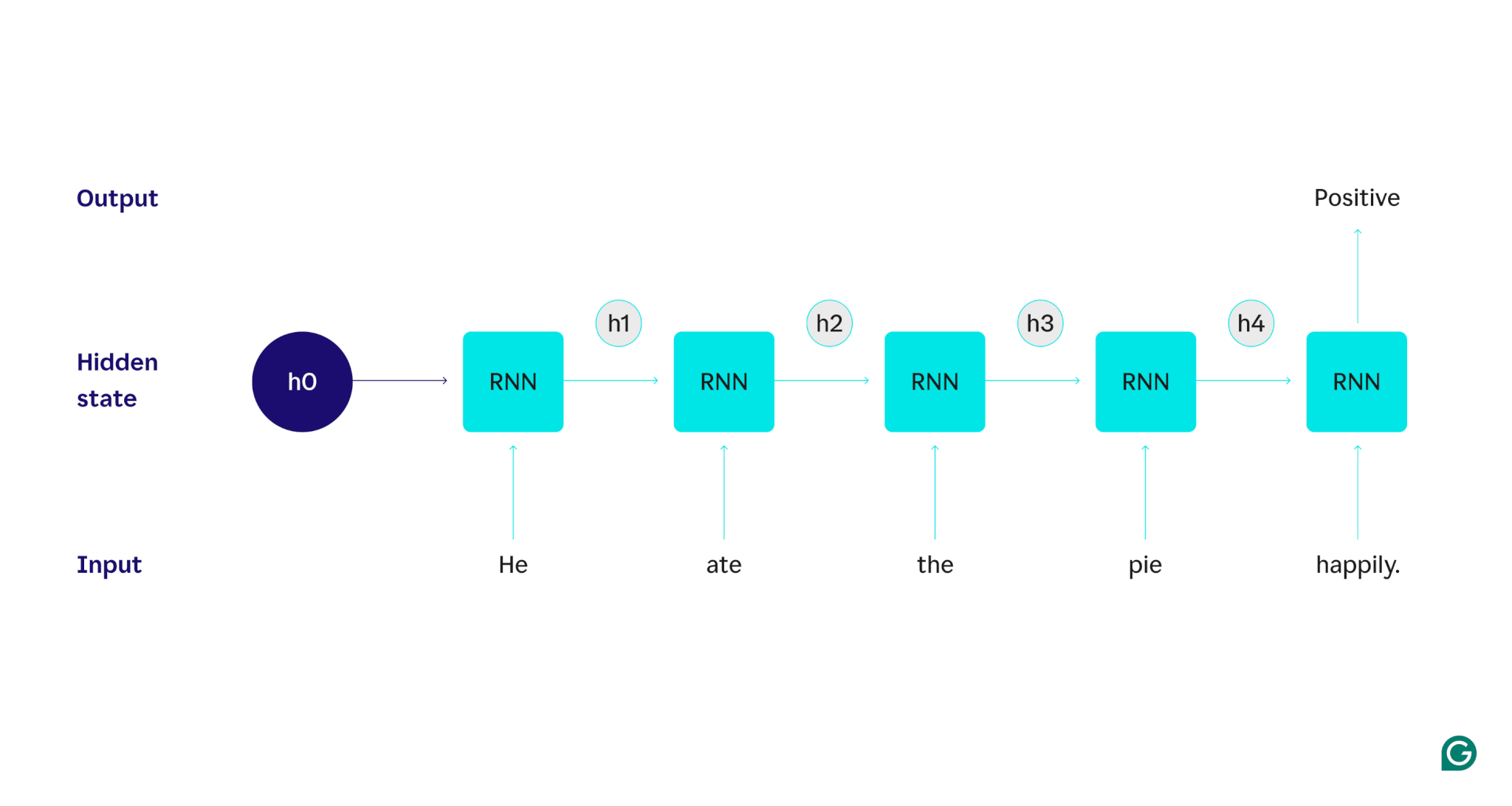
Bu yineleme RNN'nin özüdür, ancak dikkate alınması gereken birkaç nokta daha vardır:
- Metin gömme:RNN, yalnızca sayısal gösterimler üzerinde çalıştığı için metni doğrudan işleyemez. Metnin bir RNN tarafından işlenebilmesi için önce yerleştirmelere dönüştürülmesi gerekir.
- Çıkış üretimi:Her adımda RNN tarafından bir çıkış üretilecektir. Ancak kaynak verilerin çoğu işlenene kadar çıktı çok doğru olmayabilir. Örneğin, cümlenin yalnızca "Yedi" kısmını işledikten sonra, RNN bunun olumlu mu yoksa olumsuz bir duyguyu mu temsil ettiği konusunda kararsız olabilir - "Yedi" tarafsız görünebilir. Ancak cümlenin tamamı işlendikten sonra RNN'nin çıktısı doğru olacaktır.
- RNN'nin Eğitimi:RNN'nin duyarlılık analizini doğru bir şekilde gerçekleştirebilmesi için eğitilmesi gerekir. Eğitim, birçok etiketli örneğin kullanılmasını (örneğin, olumsuz olarak etiketlenmiş "Pastayı öfkeyle yedi"), bunların RNN'de çalıştırılmasını ve tahminlerinin ne kadar uzak olduğuna göre modelin ayarlanmasını içerir. Bu işlem, gizli durum için varsayılan değeri ve değişim mekanizmasını ayarlayarak RNN'nin giriş boyunca izleme için hangi kelimelerin önemli olduğunu öğrenmesine olanak tanır.
Tekrarlayan sinir ağlarının türleri
Her biri yapı ve uygulama açısından farklılık gösteren birkaç farklı RNN türü vardır. Temel RNN'ler çoğunlukla giriş ve çıkışlarının boyutunda farklılık gösterir. Uzun kısa süreli bellek (LSTM) ağları gibi gelişmiş RNN'ler, temel RNN'lerin bazı sınırlamalarına hitap eder.
Temel RNN'ler
Bire bir RNN:Bu RNN, bir uzunlukta bir girdi alır ve bir uzunlukta bir çıktı döndürür. Bu nedenle gerçekte hiçbir yineleme olmuyor, bu da onu bir RNN yerine standart bir sinir ağı haline getiriyor. Bire bir RNN örneği, girdinin tek bir görüntü ve çıktının bir etiket (örneğin, "kuş") olduğu bir görüntü sınıflandırıcı olabilir.
Bire çok RNN:Bu RNN, bir uzunlukta bir girdi alır ve çok parçalı bir çıktı döndürür. Örneğin, bir görüntüye altyazı ekleme görevinde, girdi bir görüntüdür ve çıktı, görüntüyü tanımlayan bir dizi kelimedir (örneğin, "Güneşli bir günde bir kuş nehrin üzerinden geçiyor").
Çoktan bire RNN:Bu RNN, çok parçalı bir girişi (örneğin bir cümle, bir dizi görüntü veya zaman serisi verisi) alır ve bir uzunlukta bir çıktı döndürür. Örneğin, girdinin bir cümle olduğu ve çıktının tek bir duyarlılık etiketi olduğu (olumlu veya olumsuz) bir cümle duyarlılığı sınıflandırıcısı (tartıştığımız gibi).
Çoktan çoğa RNN:Bu RNN, çok parçalı bir girdi alır ve çok parçalı bir çıktı döndürür. Bunun bir örneği, girişin bir dizi ses dalga formu ve çıkışın konuşulan içeriği temsil eden bir dizi kelime olduğu bir konuşma tanıma modelidir.
Gelişmiş RNN: Uzun kısa süreli bellek (LSTM)
Uzun kısa süreli bellek ağları, standart RNN'lerle ilgili önemli bir sorunu çözmek için tasarlanmıştır: Uzun girişler nedeniyle bilgileri unuturlar. Standart RNN'lerde, gizli durum, girişin son bölümlerine karşı büyük ölçüde ağırlıklandırılmıştır. Binlerce kelime uzunluğundaki bir girdide RNN, açılış cümlelerindeki önemli ayrıntıları unutacaktır. LSTM'ler bu unutma problemini aşmak için özel bir mimariye sahiptir. Hangi bilgilerin açıkça hatırlanıp unutulacağını seçen modülleri var. Böylece güncel fakat işe yaramaz bilgiler unutulacak, eski fakat konuyla ilgili bilgiler ise muhafaza edilecektir. Sonuç olarak LSTM'ler standart RNN'lerden çok daha yaygındır; karmaşık veya uzun görevlerde daha iyi performans gösterirler. Ancak yine de eşyaları unutmayı seçtikleri için mükemmel değiller.
RNN'ler ve transformatörler ve CNN'ler
Diğer iki yaygın derin öğrenme modeli, evrişimli sinir ağları (CNN'ler) ve transformatörlerdir. Nasıl farklılar?

RNN'ler ve transformatörler
NLP'de hem RNN'ler hem de transformatörler yoğun olarak kullanılmaktadır. Bununla birlikte, mimarileri ve girdi işleme yaklaşımları bakımından önemli ölçüde farklılık gösterirler.
Mimarlık ve işleme
- RNN'ler:RNN'ler, önceki sözcüklerden bilgi taşıyan gizli bir durumu koruyarak girişi her seferinde bir sözcük olmak üzere sırayla işler. Bu sıralı yapı, RNN'lerin bu unutma nedeniyle uzun vadeli bağımlılıklarla mücadele edebileceği anlamına gelir; dizi ilerledikçe daha önceki bilgiler kaybolabilir.
- Transformatörler:Transformatörler girdiyi işlemek için “dikkat” adı verilen bir mekanizma kullanır. RNN'lerden farklı olarak transformatörler, her kelimeyi diğer tüm kelimelerle karşılaştırarak tüm diziye aynı anda bakar. Bu yaklaşım, her kelimenin girdi bağlamının tamamına doğrudan erişimi olduğundan unutma sorununu ortadan kaldırır. Transformers, bu yeteneği sayesinde metin oluşturma ve duygu analizi gibi görevlerde üstün performans göstermiştir.
Paralelleştirme
- RNN'ler:RNN'lerin sıralı yapısı, modelin bir sonraki aşamaya geçmeden önce girdinin bir bölümünü işlemeyi tamamlaması gerektiği anlamına gelir. Her adım bir öncekine bağlı olduğundan bu çok zaman alıcıdır.
- Transformatörler:Transformatörler, mimarileri sıralı bir gizli duruma dayanmadığından girdinin tüm bölümlerini aynı anda işler. Bu onları çok daha paralelleştirilebilir ve verimli hale getirir. Örneğin, bir cümlenin işlenmesi kelime başına 5 saniye sürüyorsa, bir RNN 5 kelimelik bir cümle için 25 saniye sürerken, bir dönüştürücü yalnızca 5 saniye sürer.
Pratik çıkarımlar
Bu avantajlarından dolayı transformatörler endüstride daha yaygın olarak kullanılmaktadır. Ancak RNN'ler, özellikle de uzun kısa süreli bellek (LSTM) ağları, daha basit görevler için veya daha kısa dizilerle uğraşırken hala etkili olabilir. LSTM'ler genellikle büyük makine öğrenimi mimarilerinde kritik bellek depolama modülleri olarak kullanılır.
RNN'ler ve CNN'ler
CNN'ler, işledikleri veriler ve operasyonel mekanizmaları açısından RNN'lerden temel olarak farklıdır.
Veri türü
- RNN'ler:RNN'ler, veri noktalarının sırasının önemli olduğu metin veya zaman serileri gibi sıralı veriler için tasarlanmıştır.
- CNN'ler:CNN'ler öncelikli olarak görüntüler gibi mekansal veriler için kullanılır; burada odak noktası bitişik veri noktaları arasındaki ilişkilerdir (örneğin, bir görüntüdeki bir pikselin rengi, yoğunluğu ve diğer özellikleri yakındaki diğer piksellerin özellikleriyle yakından ilişkilidir). piksel).
Operasyon
- RNN'ler:RNN'ler tüm dizinin hafızasını korur, bu da onları bağlam ve dizinin önemli olduğu görevlere uygun hale getirir.
- CNN'ler:CNN'ler, girişin yerel bölgelerine (örneğin, komşu pikseller) evrişimli katmanlar aracılığıyla bakarak çalışır. Bu, onları görüntü işlemede son derece etkili kılar ancak uzun vadeli bağımlılıkların daha önemli olabileceği sıralı veriler için daha az etkilidir.
Giriş uzunluğu
- RNN'ler:RNN'ler, değişken uzunluktaki giriş dizilerini daha az tanımlanmış bir yapıya sahip olarak işleyebilir, bu da onları farklı sıralı veri türleri için esnek hale getirir.
- CNN'ler:CNN'ler genellikle sabit boyutlu girişler gerektirir; bu, değişken uzunluklu dizilerin işlenmesinde bir sınırlama olabilir.
RNN'lerin uygulamaları
RNN'ler sıralı verileri etkili bir şekilde işleyebilme yeteneklerinden dolayı çeşitli alanlarda yaygın olarak kullanılmaktadır.
Doğal dil işleme
Dil oldukça sıralı bir veri biçimi olduğundan RNN'ler dil görevlerinde iyi performans gösterir. RNN'ler metin oluşturma, duygu analizi, çeviri ve özetleme gibi görevlerde mükemmeldir. PyTorch gibi kütüphanelerle, birisi bir RNN ve birkaç gigabaytlık metin örneği kullanarak basit bir sohbet robotu oluşturabilir.
Konuşma tanıma
Konuşma tanıma, özünde dildir ve dolayısıyla oldukça sıralıdır. Bu görev için çoktan çoğa RNN kullanılabilir. Her adımda, RNN önceki gizli durumu ve dalga biçimini alır ve dalga biçimiyle ilişkili sözcüğün çıktısını verir (o noktaya kadar cümlenin bağlamına göre).
Müzik üretimi
Müzik de oldukça sıralıdır. Bir şarkının önceki vuruşları gelecekteki vuruşları güçlü bir şekilde etkiler. Çoktan çoğa bir RNN, girdi olarak birkaç başlangıç vuruşunu alabilir ve ardından kullanıcının istediği şekilde ek vuruşlar oluşturabilir. Alternatif olarak, "melodik caz" gibi bir metin girişi alabilir ve melodik caz ritimlerinin en iyi yaklaşımını üretebilir.
RNN'lerin avantajları
Her ne kadar RNN'ler artık fiili NLP modeli olmasa da, birkaç faktörden dolayı hala bazı kullanımları var.
İyi sıralı performans
RNN'ler, özellikle LSTM'ler sıralı verilerde iyi performans gösterir. LSTM'ler, özel bellek mimarisiyle uzun ve karmaşık sıralı girişleri yönetebilir. Örneğin Google Translate, transformatörler çağından önce bir LSTM modeli üzerinde çalışıyordu. LSTM'ler, transformatör tabanlı ağlar daha gelişmiş mimariler oluşturmak üzere birleştirildiğinde stratejik bellek modülleri eklemek için kullanılabilir.
Daha küçük, daha basit modeller
RNN'ler genellikle transformatörlerden daha az model parametresine sahiptir. Transformatörlerdeki dikkat ve ileri besleme katmanlarının etkili bir şekilde çalışması için daha fazla parametre gerekir. RNN'ler daha az sayıda çalıştırma ve veri örneğiyle eğitilerek daha basit kullanım durumları için daha verimli hale getirilebilir. Bu, hala yeterince performanslı olan daha küçük, daha ucuz ve daha verimli modellerin ortaya çıkmasına neden olur.
RNN'lerin dezavantajları
RNN'lerin gözden düşmesinin bir nedeni var: Transformatörler, daha büyük boyutlarına ve eğitim süreçlerine rağmen, RNN'lerle aynı kusurlara sahip değil.
Sınırlı hafıza
Standart RNN'lerdeki gizli durum, son girdileri büyük ölçüde ön yargılı hale getirerek uzun vadeli bağımlılıkların korunmasını zorlaştırır. Uzun girdili görevler RNN'ler ile aynı performansı göstermez. LSTM'ler bu sorunu çözmeyi hedeflerken, yalnızca hafifletiyor ve tamamen çözmüyorlar. Birçok yapay zeka görevi uzun girdilerin işlenmesini gerektirir ve bu da sınırlı belleği önemli bir dezavantaj haline getirir.
Paralelleştirilemez
RNN modelinin her çalıştırması, önceki çalıştırmanın çıktısına, özellikle de güncellenen gizli duruma bağlıdır. Sonuç olarak, modelin tamamı, bir girdinin her bir parçası için sırayla işlenmelidir. Bunun aksine, transformatörler ve CNN'ler tüm girişi aynı anda işleyebilir. Bu, birden fazla GPU arasında paralel işleme olanak tanıyarak hesaplamayı önemli ölçüde hızlandırır. RNN'lerin paralelleştirilebilirlik eksikliği, daha yavaş eğitime, daha yavaş çıktı üretimine ve öğrenilebilecek maksimum veri miktarının daha düşük olmasına yol açar.
Degrade sorunları
Geri yayılım sürecinin her giriş adımından (zaman içinde geri yayılım) geçmesi gerektiğinden RNN'leri eğitmek zor olabilir. Çok sayıda zaman adımı nedeniyle, her model parametresinin nasıl ayarlanması gerektiğini gösteren gradyanlar bozulabilir ve etkisiz hale gelebilir. Degradeler kaybolarak başarısız olabilir; bu, çok küçük hale geldikleri ve modelin bunları öğrenmek için artık kullanamayacağı anlamına gelir veya patlayarak degradeler çok büyür ve model, güncellemelerini aşarak modeli kullanılamaz hale getirir. Bu sorunları dengelemek zordur.