
Makine Öğreniminde Karar Ağacı Nedir?
Yayınlanan: 2024-08-14Karar ağaçları, bir veri analistinin makine öğrenimi araç setindeki en yaygın araçlardan biridir. Bu kılavuzda karar ağaçlarının ne olduğunu, nasıl oluşturulduğunu, çeşitli uygulamaları, faydalarını ve daha fazlasını öğreneceksiniz.
İçindekiler
- Karar ağacı nedir?
- Karar ağacı terminolojisi
- Karar ağacı türleri
- Karar ağaçları nasıl çalışır?
- Uygulamalar
- Avantajları
- Dezavantajları
Karar ağacı nedir?
Makine öğreniminde (ML), karar ağacı, bir akış şemasına veya karar şemasına benzeyen denetimli bir öğrenme algoritmasıdır. Diğer birçok denetimli öğrenme algoritmasının aksine karar ağaçları hem sınıflandırma hem de regresyon görevleri için kullanılabilir. Veri bilimcileri ve analistler, yeni veri kümelerini keşfederken sıklıkla karar ağaçlarını kullanır çünkü bunların oluşturulması ve yorumlanması kolaydır. Ayrıca karar ağaçları, daha karmaşık makine öğrenimi algoritmaları uygulanırken faydalı olabilecek önemli veri özelliklerinin belirlenmesine yardımcı olabilir.
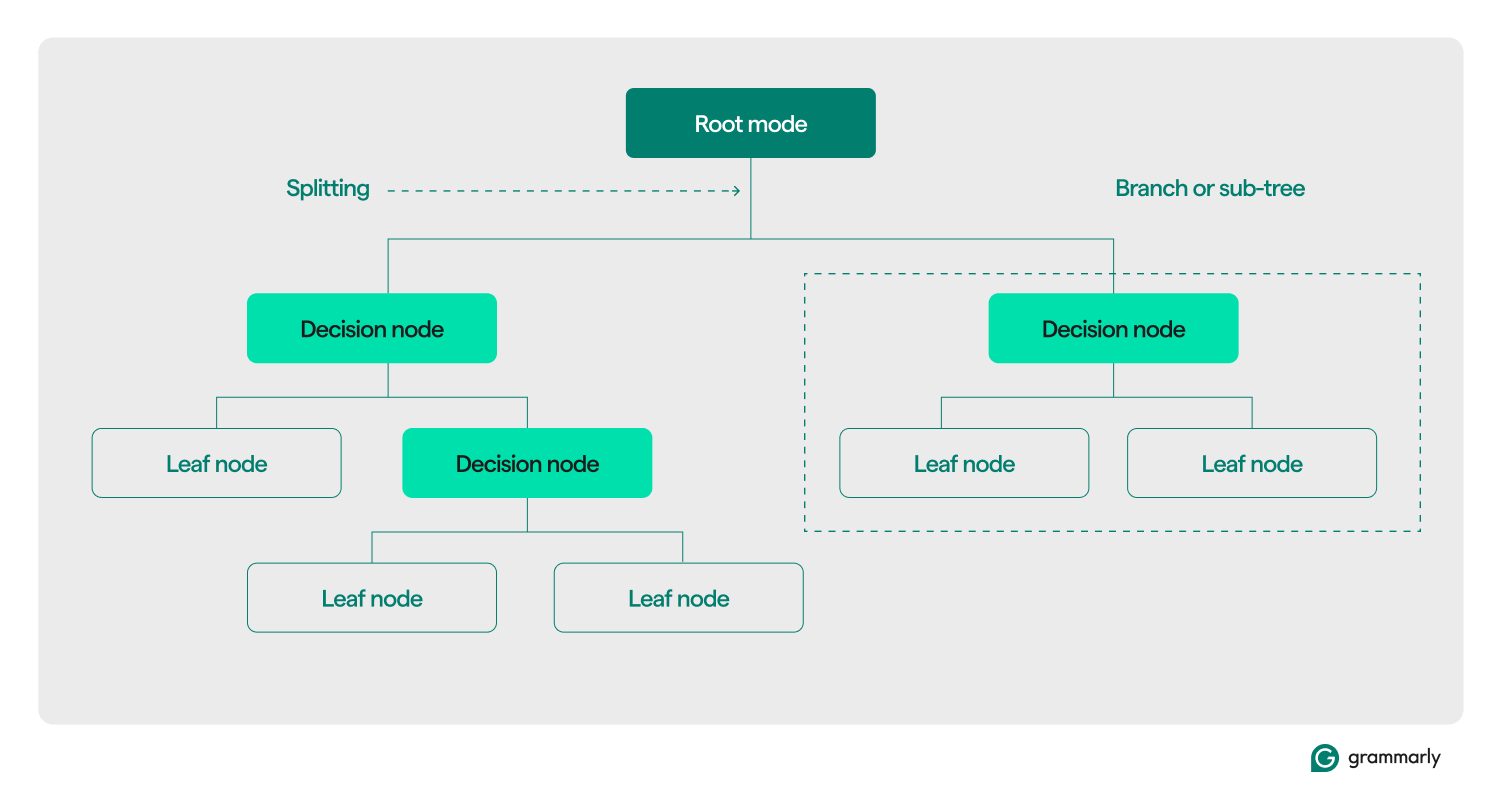
Karar ağacı terminolojisi
Yapısal olarak bir karar ağacı tipik olarak üç bileşenden oluşur: kök düğüm, yaprak düğümler ve karar (veya dahili) düğümler. Diğer alanlardaki akış şemaları veya ağaçlar gibi, bir ağaçtaki kararlar genellikle tek yönde (aşağı veya yukarı) hareket eder, kök düğümden başlar, bazı karar düğümlerinden geçer ve belirli bir yaprak düğümde biter. Her yaprak düğümü, eğitim verilerinin bir alt kümesini bir etikete bağlar. Ağaç, makine öğrenimi eğitimi ve optimizasyon süreci yoluyla birleştirilir ve oluşturulduktan sonra çeşitli veri kümelerine uygulanabilir.
İşte terminolojinin geri kalanına daha derin bir bakış:
- Kök düğüm:Karar ağacının veriler hakkında soracağı bir dizi sorudan ilkini tutan düğüm. Düğüm en az bir (ancak genellikle iki veya daha fazla) karar veya yaprak düğüme bağlanacaktır.
- Karar düğümleri (veya dahili düğümler):Soruları içeren ek düğümler. Bir karar düğümü, veriyle ilgili tam olarak bir soru içerecek ve yanıta göre veri akışını alt öğelerinden birine yönlendirecektir.
- Çocuklar:Bir kök veya karar düğümünün işaret ettiği bir veya daha fazla düğüm. Verileri analiz ederken karar verme sürecinin alabileceği sonraki seçeneklerin bir listesini temsil ederler.
- Yaprak düğümler (veya terminal düğümler):Karar sürecinin tamamlandığını gösteren düğümlerdir. Karar süreci bir yaprak düğüme ulaştığında, yaprak düğümdeki değer(ler)i çıktı olarak döndürecektir.
- Etiket (sınıf, kategori):Genellikle, bir yaprak düğüm tarafından bazı eğitim verileriyle ilişkilendirilen bir dize. Örneğin bir yaprak, "Memnun müşteri" etiketini, karar ağacı makine öğrenimi eğitim algoritmasının sunulduğu bir dizi belirli müşteriyle ilişkilendirebilir.
- Dal (veya alt ağaç):Ağacın herhangi bir noktasındaki bir karar düğümünden, tüm çocukları ve onların çocukları ile birlikte yaprak düğümlerine kadar oluşan düğümler kümesidir.
- Budama:Genellikle ağacı küçültmek ve çıktıları daha hızlı döndürmesine yardımcı olmak için ağaç üzerinde gerçekleştirilen bir optimizasyon işlemi. Budama genellikle, ML eğitim süreci ağacı oluşturduktan sonra düğümlerin veya dalların algoritmik olarak kaldırılmasını içeren "budama sonrası" anlamına gelir. “Ön budama”, eğitim sırasında bir karar ağacının ne kadar derin veya büyük büyüyebileceği konusunda keyfi bir sınır belirlemek anlamına gelir. Her iki süreç de karar ağacı için genellikle maksimum derinlik veya yükseklikle ölçülen maksimum karmaşıklığı zorunlu kılar. Daha az yaygın olan optimizasyonlar arasında maksimum karar düğümü veya yaprak düğüm sayısının sınırlandırılması yer alır.
- Bölme:Eğitim sırasında bir karar ağacı üzerinde gerçekleştirilen temel dönüşüm adımı. Bir kök veya karar düğümünün iki veya daha fazla alt düğüme bölünmesini içerir.
- Sınıflandırma:Hangisinin (sabit ve ayrı bir sınıf, kategori veya etiket listesinden) bir veri parçasına uygulanma olasılığı en yüksek olduğunu bulmaya çalışan bir ML algoritması. "Uçuş rezervasyonu için haftanın hangi günü en iyisidir?" gibi soruları yanıtlamaya çalışabilir. Aşağıda sınıflandırma hakkında daha fazla bilgi bulabilirsiniz.
- Regresyon:Her zaman sınırları olmayabilecek sürekli bir değeri tahmin etmeye çalışan bir ML algoritması. "Önümüzdeki Salı günü kaç kişinin uçuş rezervasyonu yapması muhtemel?" gibi soruları yanıtlamaya (veya yanıtı tahmin etmeye) çalışabilir. Bir sonraki bölümde regresyon ağaçları hakkında daha fazla konuşacağız.
Karar ağacı türleri
Karar ağaçları tipik olarak iki kategoriye ayrılır: sınıflandırma ağaçları ve regresyon ağaçları. Sınıflandırmaya, regresyona veya her iki kullanım durumuna uygulanacak belirli bir ağaç oluşturulabilir. Çoğu modern karar ağacı, her iki görev türünü de gerçekleştirebilen CART (Sınıflandırma ve Regresyon Ağaçları) algoritmasını kullanır.
Sınıflandırma ağaçları
Karar ağacının en yaygın türü olan sınıflandırma ağaçları, bir sınıflandırma problemini çözmeye çalışır. Bir soruya verilen olası yanıtlar listesinden (çoğunlukla "evet" veya "hayır" kadar basit), bir sınıflandırma ağacı, kendisine sunulan verilerle ilgili bazı sorular sorduktan sonra en olası yanıtı seçecektir. Genellikle ikili ağaçlar olarak uygulanırlar, yani her karar düğümünün tam olarak iki çocuğu vardır.
Sınıflandırma ağaçları, "Bu müşteri memnun mu?" gibi çoktan seçmeli soruları yanıtlamaya çalışabilir. veya "Bu müşterinin hangi fiziksel mağazayı ziyaret etmesi muhtemeldir?" veya “Yarın golf sahasına gitmek için güzel bir gün olacak mı?”
Bir sınıflandırma ağacının kalitesini ölçmenin en yaygın iki yöntemi bilgi kazancına ve entropiye dayanır:
- Bilgi kazanımı:Bir cevaba ulaşmadan önce daha az soru sorduğunda ağacın verimliliği artar. Bilgi kazanımı, her karar düğümünde bir veri parçası hakkında ne kadar daha fazla bilginin öğrenildiğini değerlendirerek bir ağacın bir cevaba ne kadar "hızlı" ulaşabileceğini ölçer. Ağaçta en önemli ve faydalı soruların ilk önce sorulup sorulmadığını değerlendirir.
- Entropi:Karar ağacı etiketleri için doğruluk çok önemlidir. Entropi metrikleri bu doğruluğu ağacın ürettiği etiketleri değerlendirerek ölçer. Rastgele bir veri parçasının ne sıklıkta yanlış etiketle sonuçlandığını ve aynı etiketi alan tüm eğitim verileri parçaları arasındaki benzerliği değerlendirirler.
Ağaç kalitesinin daha gelişmiş ölçümleri arasındagini indeksi,kazanç oranı,ki-kare değerlendirmelerive varyans azaltımına yönelik çeşitli ölçümler yer alır.
Regresyon ağaçları
Regresyon ağaçları tipik olarak ileri istatistiksel analiz için regresyon analizinde veya sürekli, potansiyel olarak sınırsız bir aralıktaki verileri tahmin etmek için kullanılır. Bir dizi sürekli seçenek verildiğinde (örneğin, gerçek sayı ölçeğinde sıfırdan sonsuza kadar), regresyon ağacı, bir dizi soru sorduktan sonra belirli bir veri parçası için en olası eşleşmeyi tahmin etmeye çalışır. Her soru potansiyel cevap aralığını daraltır. Örneğin, kredi puanlarını, bir iş kolundan elde edilen geliri veya bir pazarlama videosundaki etkileşim sayısını tahmin etmek için bir regresyon ağacı kullanılabilir.
Regresyon ağaçlarının doğruluğu genellikleortalama karesel hataveyaortalama mutlak hatagibi ölçümler kullanılarak değerlendirilir; bu ölçümler, belirli bir tahmin grubunun gerçek değerlerle karşılaştırıldığında ne kadar uzakta olduğunu hesaplar.
Karar ağaçları nasıl çalışır?
Denetimli öğrenmeye bir örnek olarak karar ağaçları, eğitim için iyi biçimlendirilmiş verilere dayanır. Kaynak veriler genellikle modelin tahmin etmeyi veya sınıflandırmayı öğrenmesi gereken değerlerin bir listesini içerir. Her değerin ekli bir etiketi ve ilişkili özelliklerin bir listesi bulunmalıdır; bu özellikler, modelin etiketle ilişkilendirmeyi öğrenmesi gereken özelliklerdir.

İnşaat veya eğitim
Eğitim süreci sırasında, karar ağacındaki karar düğümleri, bir veya daha fazla eğitim algoritmasına göre yinelemeli olarak daha spesifik düğümlere bölünür. Sürecin insan düzeyindeki bir açıklaması şöyle görünebilir:
- Tüm eğitim setine bağlıkök düğümle başlayın.
- Kök düğümü bölme:İstatistiksel bir yaklaşım kullanarak, veri özelliklerinden birine dayalı olarak kök düğüme bir karar atayın ve eğitim verilerini, köke alt öğeler olarak bağlanan en az iki ayrı yaprak düğüme dağıtın.
- İkinci adımı çocukların her birine yinelemeli olarak uygulayınve onları yaprak düğümlerden karar düğümlerine dönüştürün. Belirli bir sınıra ulaşıldığında (örneğin, ağacın yüksekliği/derinliği, her düğümdeki her bir yapraktaki çocukların kalitesinin bir ölçüsü, vb.) veya verileriniz tükendiğinde (örneğin, her bir yaprak veri içeriyorsa) durun tam olarak bir etiketle ilgili noktalar).
Her düğümde hangi özelliklerin dikkate alınacağına ilişkin karar, sınıflandırma, regresyon ve birleşik sınıflandırma ve regresyon kullanım durumlarına göre farklılık gösterir. Her senaryo için seçilebilecek birçok algoritma vardır. Tipik algoritmalar şunları içerir:
- ID3 (sınıflandırma):Entropiyi ve bilgi kazanımını optimize eder
- C4.5 (sınıflandırma):Bilgi kazanımına normalleştirme ekleyen ID3'ün daha karmaşık bir versiyonu
- CART (sınıflandırma/regresyon): “Sınıflandırma ve regresyon ağacı”; sonuç kümelerinde minimum safsızlık için optimizasyon yapan açgözlü bir algoritma
- CHAID (sınıflandırma/regresyon): “Ki-kare otomatik etkileşim tespiti”; entropi ve bilgi kazancı yerine ki-kare ölçümlerini kullanır
- MARS (sınıflandırma/regresyon): Doğrusal olmayan durumları yakalamak için parçalı doğrusal yaklaşımlar kullanır
Yaygın bir eğitim rejimi rastgele ormandır. Rastgele orman veya rastgele karar ormanı, birçok ilgili karar ağacını oluşturan bir sistemdir. Bir ağacın birden fazla versiyonu, eğitim algoritmalarının kombinasyonları kullanılarak paralel olarak eğitilebilir. Ağaç kalitesinin çeşitli ölçümlerine dayanarak, bu ağaçların bir alt kümesi bir cevap üretmek için kullanılacaktır. Sınıflandırma kullanım durumları için, en fazla ağaç sayısına göre seçilen sınıf cevap olarak döndürülür. Regresyon kullanım durumları için yanıt, genellikle bireysel ağaçların ortalaması veya ortalama tahmini olarak toplanır.
Karar ağaçlarını değerlendirme ve kullanma
Bir karar ağacı oluşturulduktan sonra yeni verileri sınıflandırabilir veya belirli bir kullanım durumu için değerleri tahmin edebilir. Ağaç performansına ilişkin metrikleri tutmak ve bunları doğruluğu ve hata sıklığını değerlendirmek için kullanmak önemlidir. Model beklenen performanstan çok saparsa, onu yeni verilerle yeniden eğitmenin veya bu kullanım senaryosuna uygulanacak başka makine öğrenimi sistemleri bulmanın zamanı gelmiş olabilir.
Karar ağaçlarının makine öğreniminde uygulamaları
Karar ağaçları çeşitli alanlarda geniş bir uygulama alanına sahiptir. Çok yönlülüğünü göstermek için bazı örnekler:
Bilgilendirilmiş kişisel karar verme
Bir kişi, örneğin ziyaret ettiği restoranlar hakkındaki verileri takip edebilir. Seyahat süresi, bekleme süresi, sunulan mutfak, çalışma saatleri, ortalama değerlendirme puanı, maliyet ve en son ziyaret gibi ilgili ayrıntıların yanı sıra bireyin o restorana yaptığı ziyarete ilişkin memnuniyet puanı da takip edilebilir. Yeni bir restoranın olası memnuniyet puanını tahmin etmek için bu veriler üzerinde bir karar ağacı eğitilebilir.
Müşteri davranışına ilişkin olasılıkları hesaplayın
Müşteri destek sistemleri, müşteri memnuniyetini tahmin etmek veya sınıflandırmak için karar ağaçlarını kullanabilir. Bir karar ağacı, müşterinin destek ekibiyle iletişime geçip geçmediği veya tekrar satın alma işlemi yapıp yapmadığı veya bir uygulama içinde gerçekleştirilen eylemlere dayalı olarak çeşitli faktörlere dayalı olarak müşteri memnuniyetini tahmin edecek şekilde eğitilebilir. Ayrıca memnuniyet anketlerinden veya diğer müşteri geri bildirimlerinden elde edilen sonuçları da içerebilir.
İş kararlarının bilgilendirilmesine yardımcı olun
Zengin geçmiş veri içeren belirli iş kararları için bir karar ağacı, sonraki adımlara ilişkin tahminler veya tahminler sağlayabilir. Örneğin, müşterileri hakkında demografik ve coğrafi bilgiler toplayan bir işletme, hangi yeni coğrafi konumların karlı olabileceğini veya kaçınılması gerektiğini değerlendirmek için bir karar ağacını eğitebilir. Karar ağaçları, müşterileri gruplandırırken ayrı ayrı dikkate alınacak yaş aralıklarının belirlenmesi gibi mevcut demografik veriler için en iyi sınıflandırma sınırlarının belirlenmesine de yardımcı olabilir.
Gelişmiş makine öğrenimi ve diğer kullanım durumları için özellik seçimi
Karar ağacı yapıları insanlar tarafından okunabilir ve anlaşılabilir niteliktedir. Bir ağaç oluşturulduktan sonra, hangi özelliklerin veri kümesiyle en alakalı olduğunu ve hangi sırayla olduğunu belirlemek mümkündür. Bu bilgi, daha karmaşık makine öğrenimi sistemlerinin veya karar algoritmalarının geliştirilmesine rehberlik edebilir. Örneğin, bir işletme karar ağacından müşterilerin bir ürünün maliyetini her şeyden önce önceliklendirdiğini öğrenirse, bu içgörü üzerine daha karmaşık makine öğrenimi sistemlerine odaklanabilir veya daha incelikli özellikleri keşfederken maliyeti göz ardı edebilir.
ML'de karar ağaçlarının avantajları
Karar ağaçları, onları makine öğrenimi uygulamalarında popüler bir seçim haline getiren birçok önemli avantaj sunar. İşte bazı önemli faydalar:
Hızlı ve kolay inşa edilir
Karar ağaçları en olgun ve en iyi anlaşılan makine öğrenimi algoritmalarından biridir. Özellikle karmaşık hesaplamalara dayanmazlar ve hızlı ve kolay bir şekilde oluşturulabilirler. Gerekli bilgiler hazır olduğu sürece karar ağacı, bir soruna makine öğrenimi çözümleri düşünülürken atılacak kolay bir ilk adımdır.
İnsanların anlaması kolay
Karar ağaçlarından elde edilen çıktıların okunması ve yorumlanması özellikle kolaydır. Bir karar ağacının grafiksel gösterimi ileri düzey istatistik anlayışına bağlı değildir. Bu nedenle karar ağaçları ve bunların temsilleri, daha karmaşık analizlerin sonuçlarını yorumlamak, açıklamak ve desteklemek için kullanılabilir. Karar ağaçları, belirli bir veri kümesinin bazı üst düzey özelliklerini bulma ve vurgulama konusunda mükemmeldir.
Minimum veri işleme gerekli
Karar ağaçları, eksik veriler veya aykırı değerlerin dahil olduğu veriler üzerine de aynı kolaylıkla oluşturulabilir. İlginç özelliklerle süslenmiş veriler göz önüne alındığında, karar ağacı algoritmaları, önceden işlenmemiş verilerle beslenirse diğer makine öğrenimi algoritmaları kadar etkilenmeme eğilimindedir.
ML'de karar ağaçlarının dezavantajları
Karar ağaçları birçok fayda sunarken aynı zamanda bazı dezavantajlara da sahiptir:
Fazla takılmaya duyarlı
Karar ağaçları, bir modelin eğitim verilerindeki gürültüyü ve ayrıntıları öğrenmesiyle ortaya çıkan ve yeni veriler üzerindeki performansını düşüren aşırı uyum sorununa eğilimlidir. Örneğin, eğitim verileri eksik veya seyrekse, verilerdeki küçük değişiklikler önemli ölçüde farklı ağaç yapıları üretebilir. Budama veya maksimum derinliği ayarlama gibi gelişmiş teknikler ağaç davranışını iyileştirebilir. Uygulamada karar ağaçlarının sıklıkla yeni bilgilerle güncellenmesi gerekir ve bu da onların yapısını önemli ölçüde değiştirebilir.
Zayıf ölçeklenebilirlik
Karar ağaçları, gereğinden fazla uyum sağlama eğilimlerinin yanı sıra, önemli ölçüde daha fazla veri gerektiren daha gelişmiş problemlerle de mücadele eder. Diğer algoritmalarla karşılaştırıldığında veri hacimleri büyüdükçe karar ağaçlarının eğitim süresi de hızla artıyor. Tespit edilmesi gereken önemli yüksek düzey özelliklere sahip olabilecek daha büyük veri kümeleri için karar ağaçları pek uygun değildir.
Regresyon veya sürekli kullanım durumları için o kadar etkili değil
Karar ağaçları karmaşık veri dağılımlarını çok iyi öğrenemez. Özellik uzayını anlaşılması kolay ancak matematiksel olarak basit çizgiler boyunca bölerler. Aykırı değerlerin ilgili olduğu karmaşık problemler, regresyon ve sürekli kullanım durumları için bu genellikle diğer makine öğrenimi modelleri ve tekniklerine göre çok daha düşük performans anlamına gelir.