
Makine Öğreniminde Aşırı Uyum Nedir?
Yayınlanan: 2024-10-15Aşırı uyum, makine öğrenimi (ML) modellerini eğitirken ortaya çıkan yaygın bir sorundur. Bir modelin eğitim verilerinin ötesinde genelleme yapma yeteneğini olumsuz yönde etkileyerek gerçek dünya senaryolarında hatalı tahminlere yol açabilir. Bu makalede aşırı uyumun ne olduğunu, nasıl oluştuğunu, arkasındaki yaygın nedenleri ve bunu tespit edip önlemenin etkili yollarını inceleyeceğiz.
İçindekiler
- Aşırı uyum nedir?
- Aşırı uyum nasıl oluşur?
- Aşırı uyum ve yetersiz uyum
- Aşırı uyumun nedeni nedir?
- Aşırı uyum nasıl tespit edilir
- Aşırı uyumdan nasıl kaçınılır
- Aşırı uyum örnekleri
Aşırı uyum nedir?
Aşırı uyum, bir makine öğrenimi modelinin, eğitim verilerindeki temel kalıpları ve gürültüyü öğrenerek söz konusu belirli veri kümesinde aşırı uzmanlaşmasıdır. Eğitim verilerinin ayrıntılarına aşırı odaklanma, model yeni, görünmeyen verilere uygulandığında, üzerinde eğitim verildiği verilerin ötesinde genelleme yapamadığı için performansın düşmesine neden olur.
Aşırı uyum nasıl olur?
Aşırı uyum, bir modelin eğitim verilerindeki belirli ayrıntılardan ve gürültüden çok fazla şey öğrenmesi ve genelleme açısından anlamlı olmayan kalıplara karşı aşırı duyarlı hale gelmesi durumunda ortaya çıkar. Örneğin, geçmiş değerlendirmelere dayanarak çalışan performansını tahmin etmek için oluşturulmuş bir modeli düşünün. Model gereğinden fazla uyuyorsa, eski bir yöneticinin benzersiz derecelendirme stili veya geçmiş bir inceleme döngüsü sırasındaki belirli koşullar gibi genelleştirilemeyen belirli ayrıntılara çok fazla odaklanabilir. Performansa katkıda bulunan daha geniş, anlamlı faktörleri (beceri, deneyim veya proje sonuçları gibi) öğrenmek yerine model, bilgisini yeni çalışanlara uygulama veya değerlendirme kriterlerini geliştirme konusunda zorluk yaşayabilir. Bu, model eğitim setinden farklı verilere uygulandığında daha az doğru tahminlere yol açar.
Aşırı uyum ve yetersiz uyum
Aşırı uyumun aksine, yetersiz uyum, bir modelin verilerdeki temel kalıpları yakalayamayacak kadar basit olması durumunda ortaya çıkar. Sonuç olarak, hem eğitimde hem de yeni verilerde düşük performans göstererek doğru tahminlerde bulunamıyor.
Yetersiz uyum ve aşırı uyum arasındaki farkı görselleştirmek için, kişinin stres düzeyine göre atletik performansını tahmin etmeye çalıştığımızı hayal edin. Verileri çizebilir ve bu ilişkiyi tahmin etmeye çalışan üç modeli gösterebiliriz:

1 Yetersiz Uyum:İlk örnekte, model tahminlerde bulunmak için düz bir çizgi kullanırken, gerçek veriler bir eğriyi takip etmektedir. Model çok basit ve stres düzeyi ile atletik performans arasındaki ilişkinin karmaşıklığını yakalamakta başarısız oluyor. Sonuç olarak tahminler, eğitim verileri için bile çoğunlukla hatalıdır. Bu yetersiz.
2Optimum uyum:İkinci örnek, doğru dengeyi sağlayan bir modeli göstermektedir. Verilerdeki temel eğilimi aşırı karmaşık hale getirmeden yakalar. Bu model, yeni verilere iyi bir şekilde genelleme yapar çünkü eğitim verilerindeki her küçük varyasyona uymaya çalışmaz; yalnızca temel modele uymaya çalışır.
3Aşırı Uyum:Son örnekte model, eğitim verilerine uyum sağlamak için oldukça karmaşık, dalgalı bir eğri kullanıyor. Bu eğri, eğitim verileri için oldukça doğru olsa da, aynı zamanda gerçek ilişkiyi temsil etmeyen rastgele gürültüyü ve aykırı değerleri de yakalar. Bu model aşırı uyumludur çünkü eğitim verilerine o kadar hassas bir şekilde ayarlanmıştır ki, muhtemelen yeni, görünmeyen veriler üzerinde kötü tahminler yapması muhtemeldir.
Aşırı uyumun yaygın nedenleri
Artık aşırı uyumun ne olduğunu ve neden oluştuğunu bildiğimize göre, bazı yaygın nedenleri daha ayrıntılı olarak inceleyelim:
- Yetersiz eğitim verisi
- Yanlış, hatalı veya ilgisiz veriler
- Büyük ağırlıklar
- Aşırı antrenman
- Model mimarisi çok karmaşık
Yetersiz eğitim verisi
Eğitim veri kümeniz çok küçükse modelin gerçek dünyada karşılaşacağı senaryolardan yalnızca bazılarını temsil edebilir. Eğitim sırasında model verilere iyi uyum sağlayabilir. Ancak diğer veriler üzerinde test ettiğinizde önemli yanlışlıklar görebilirsiniz. Küçük veri seti, modelin görünmeyen durumlara genelleme yapma yeteneğini sınırlayarak aşırı uyum eğilimine neden olur.
Yanlış, hatalı veya ilgisiz veriler
Eğitim veri kümeniz büyük olsa bile hatalar içerebilir. Bu hatalar, katılımcıların anketlerde yanlış bilgi vermesi veya hatalı sensör okumaları gibi çeşitli kaynaklardan kaynaklanabilir. Model bu yanlışlıklardan ders almaya çalışırsa, altta yatan gerçek ilişkileri yansıtmayan kalıplara uyum sağlayacak ve bu da aşırı uyuma yol açacaktır.
Büyük ağırlıklar
Makine öğrenimi modellerinde ağırlıklar, tahminler yapılırken verilerdeki belirli özelliklere atanan önemi temsil eden sayısal değerlerdir. Ağırlıklar orantısız bir şekilde büyüdüğünde model aşırı sığabilir ve verilerdeki gürültü de dahil olmak üzere belirli özelliklere aşırı duyarlı hale gelebilir. Bunun nedeni, modelin belirli özelliklere fazla bağımlı hale gelmesi ve bunun da yeni verilere genelleme yapma becerisine zarar vermesidir.
Aşırı antrenman
Algoritma, eğitim sırasında verileri gruplar halinde işler, her bir grup için hatayı hesaplar ve doğruluğunu artırmak için modelin ağırlıklarını ayarlar.
Eğitime mümkün olduğu kadar uzun süre devam etmek iyi bir fikir mi? Tam olarak değil! Aynı veriler üzerinde uzun süreli eğitim, modelin belirli veri noktalarını ezberlemesine neden olabilir ve aşırı uyumun özü olan yeni veya görünmeyen verilere genelleme yeteneğini sınırlayabilir. Bu tür aşırı uyum, erken durdurma teknikleri kullanılarak veya eğitim sırasında bir doğrulama kümesinde modelin performansının izlenmesiyle azaltılabilir. Bunun nasıl çalıştığını makalenin ilerleyen kısımlarında ele alacağız.
Model mimarisi çok karmaşık
Bir makine öğrenimi modelinin mimarisi, katmanlarının ve nöronlarının nasıl yapılandırıldığını ve bilgiyi işlemek için nasıl etkileşime girdiklerini ifade eder.

Daha karmaşık mimariler, eğitim verilerindeki ayrıntılı modelleri yakalayabilir. Bununla birlikte, model aynı zamanda yeni veriler üzerinde doğru tahminlere katkıda bulunmayan gürültüyü veya ilgisiz ayrıntıları yakalamayı da öğrenebileceğinden, bu karmaşıklık aşırı uyum olasılığını artırır. Mimariyi basitleştirmek veya düzenlileştirme tekniklerini kullanmak, aşırı uyum riskinin azaltılmasına yardımcı olabilir.
Aşırı uyum nasıl tespit edilir
Aşırı uyumun tespit edilmesi zor olabilir çünkü eğitim sırasında aşırı uyum olsa bile her şey yolunda gidiyormuş gibi görünebilir. Modelin ne sıklıkta hatalı olduğunun bir ölçüsü olan kayıp (veya hata) oranı, aşırı uyum senaryosunda bile azalmaya devam edecektir. Peki aşırı uyumun meydana gelip gelmediğini nasıl bilebiliriz? Güvenilir bir teste ihtiyacımız var.
Etkili yöntemlerden biri, kayıp adı verilen bir ölçüyü izleyen bir grafik olan bir öğrenme eğrisi kullanmaktır. Kayıp, modelin yaptığı hatanın büyüklüğünü temsil eder. Ancak kaybı yalnızca eğitim verileri için takip etmiyoruz; doğrulama verileri adı verilen, görünmeyen verilerdeki kaybı da ölçüyoruz. Bu nedenle öğrenme eğrisinde genellikle iki çizgi bulunur: eğitim kaybı ve doğrulama kaybı.
Eğitim kaybı beklendiği gibi azalmaya devam ediyor ancak doğrulama kaybı artıyorsa bu aşırı uyum anlamına gelir. Başka bir deyişle, model eğitim verilerine aşırı derecede özelleşiyor ve yeni, görünmeyen verilere genelleme yapmakta zorlanıyor. Öğrenme eğrisi şöyle görünebilir:
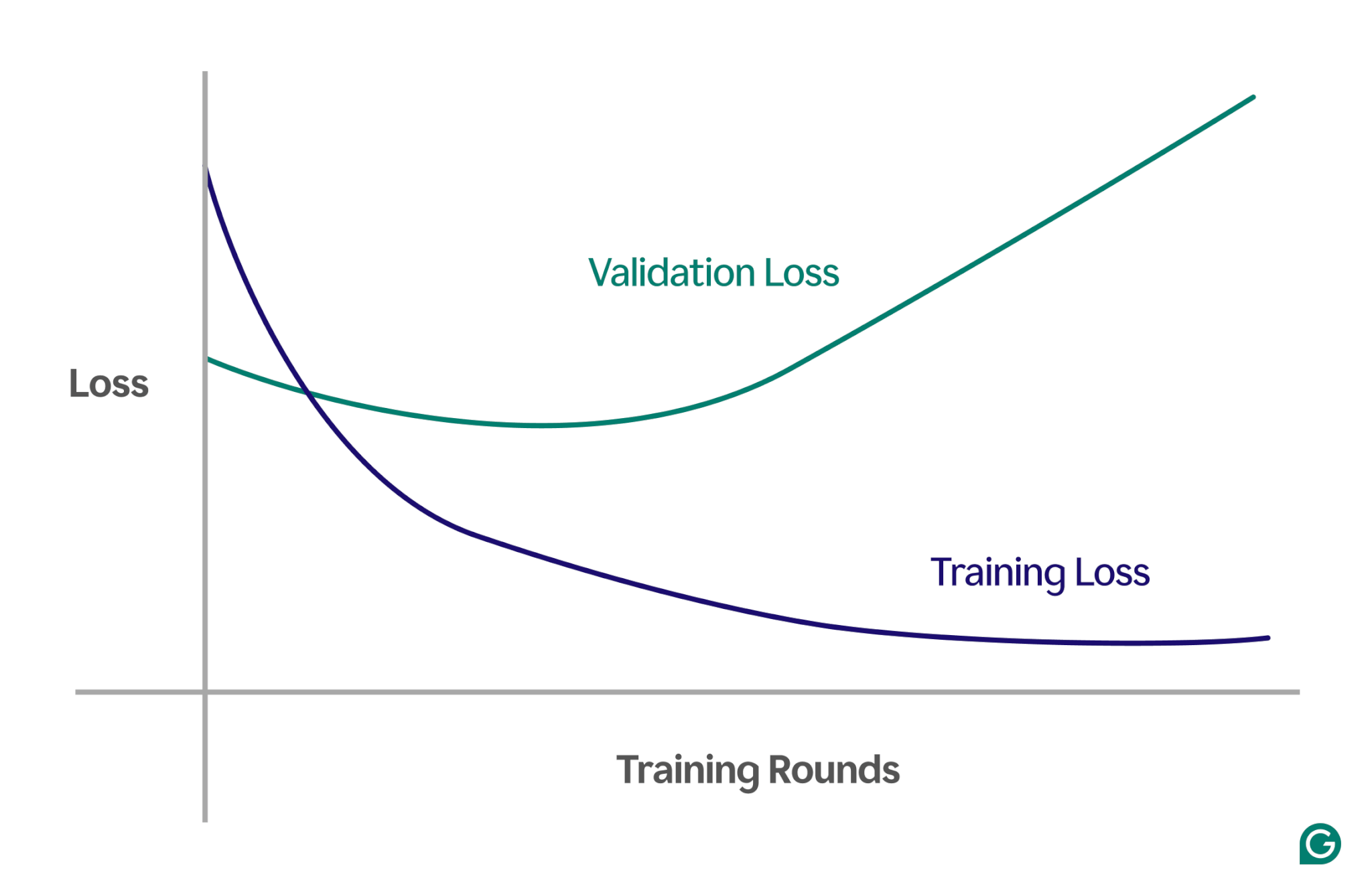
Bu senaryoda, model eğitim sırasında gelişirken, görünmeyen verilerde düşük performans gösterir. Bu muhtemelen aşırı uyumun meydana geldiği anlamına gelir.
Aşırı uyumdan nasıl kaçınılır
Aşırı uyum çeşitli teknikler kullanılarak giderilebilir. İşte en yaygın yöntemlerden bazıları:
Model boyutunu küçültün
Çoğu model mimarisi, katman sayısını, katman boyutlarını ve hiperparametreler olarak bilinen diğer parametreleri değiştirerek ağırlık sayısını ayarlamanıza olanak tanır. Modelin karmaşıklığı fazla uyum sağlamaya neden oluyorsa boyutunun küçültülmesi yardımcı olabilir. Katmanların veya nöronların sayısını azaltarak modeli basitleştirmek, modelin eğitim verilerini ezberleme fırsatının azalması nedeniyle aşırı uyum riskini azaltabilir.
Modeli düzenli hale getirin
Düzenleme, büyük ağırlıkları engellemek için modelin değiştirilmesini içerir. Bir yaklaşım, kayıp fonksiyonunu, hatayı ölçecek ve ağırlıkların boyutunu içerecek şekilde ayarlamaktır.
Düzenlileştirme ile eğitim algoritması, modele açık bir avantaj sağlamadığı sürece büyük ağırlıkların olasılığını azaltarak hem hatayı hem de ağırlıkların boyutunu en aza indirir. Bu, modeli daha genel tutarak aşırı uyumun önlenmesine yardımcı olur.
Daha fazla eğitim verisi ekleyin
Eğitim veri kümesinin boyutunun artırılması, aşırı uyumun önlenmesine de yardımcı olabilir. Daha fazla veri olduğunda modelin veri kümesindeki gürültüden veya yanlışlıklardan etkilenme olasılığı azalır. Modeli daha çeşitli örneklere maruz bırakmak, bireysel veri noktalarını ezberlemeye ve bunun yerine daha geniş kalıpları öğrenmeye daha az eğilimli hale getirecektir.
Boyut azaltmayı uygula
Bazen veriler birbiriyle ilişkili özellikler (veya boyutlar) içerebilir, bu da birçok özelliğin bir şekilde ilişkili olduğu anlamına gelir. Makine öğrenimi modelleri, boyutları bağımsız olarak ele alır; bu nedenle, özellikler ilişkilendirilirse model bunlara çok fazla odaklanabilir ve bu da aşırı uyuma yol açabilir.
Temel bileşen analizi (PCA) gibi istatistiksel teknikler bu korelasyonları azaltabilir. PCA, boyut sayısını azaltarak ve korelasyonları kaldırarak verileri basitleştirir ve aşırı uyum olasılığını azaltır. En alakalı özelliklere odaklanıldığında model, yeni verilere genelleme yapma konusunda daha iyi hale gelir.
Aşırı uyumun pratik örnekleri
Aşırı uyumu daha iyi anlamak için, farklı alanlarda aşırı uyumun yanıltıcı sonuçlara yol açabileceği bazı pratik örnekleri inceleyelim.
Görüntü sınıflandırması
Görüntü sınıflandırıcıları, görüntülerdeki nesneleri (örneğin, bir resmin kuş mu yoksa köpek mi içerdiğini) tanımak için tasarlanmıştır.
Diğer ayrıntılar bu resimlerde tespit etmeye çalıştığınız şeyle ilişkili olabilir. Örneğin, köpek fotoğraflarının arka planında sıklıkla çimen bulunurken, kuş fotoğraflarının arka planında genellikle gökyüzü veya ağaç tepeleri bulunabilir.
Tüm eğitim görüntüleri bu tutarlı arka plan ayrıntılarına sahipse makine öğrenimi modeli, hayvanın gerçek özelliklerine odaklanmak yerine hayvanı tanımak için arka plana güvenmeye başlayabilir. Sonuç olarak, modelden çimlere tünemiş bir kuş görüntüsünü sınıflandırması istendiğinde, arka plan bilgisine aşırı uyduğundan dolayı onu yanlışlıkla bir köpek olarak sınıflandırabilir. Bu, eğitim verilerine aşırı uyum durumudur.
Finansal modelleme
Diyelim ki boş zamanlarınızda hisse senedi ticareti yapıyorsunuz ve belirli anahtar kelimeler için Google aramalarındaki trendlere göre fiyat hareketlerini tahmin etmenin mümkün olduğuna inanıyorsunuz. Binlerce kelimeye ait Google Trendler verilerini kullanarak bir makine öğrenimi modeli kuruyorsunuz.
Çok fazla kelime olduğundan, bazılarının hisse senedi fiyatlarınızla tamamen şans eseri bir korelasyon göstermesi muhtemeldir. Model, bu tesadüfi korelasyonlara fazla uyum sağlayabilir ve kelimelerin hisse senedi fiyatlarının öngörücüleri olmaması nedeniyle gelecekteki veriler hakkında zayıf tahminlerde bulunabilir.
Finansal uygulamalara yönelik modeller oluştururken verilerdeki ilişkilerin teorik temelini anlamak önemlidir. Dikkatli bir özellik seçimi olmadan büyük veri kümelerinin bir modele beslenmesi, özellikle model, eğitim verilerinde tamamen şans eseri var olan sahte korelasyonları tanımladığında aşırı uyum riskini artırabilir.
Spor batıl inancı
Her ne kadar makine öğrenimiyle tam olarak ilgili olmasa da, sporla ilgili batıl inançlar aşırı uyum kavramını örnekleyebilir; özellikle de sonuçlar, sonuçla mantıksal olarak hiçbir bağlantısı olmayan verilere bağlandığında.
UEFA Euro 2008 futbol şampiyonası ve 2010 FIFA Dünya Kupası sırasında, Paul adlı bir ahtapotun, Almanya'nın dahil olduğu maç sonuçlarını tahmin etmek için kullanıldığı biliniyor. Paul 2008'de altı tahminden dördünü, 2010'da ise yedi tahminin tamamını doğru çıkardı.
Yalnızca Paul'un geçmiş tahminlerinin "eğitim verilerini" dikkate alırsanız, Paul'un seçimleriyle uyumlu olan bir modelin, sonuçları çok iyi tahmin ettiği görülecektir. Ancak ahtapotun seçimleri maç sonuçlarının güvenilir olmayan tahminleri olduğundan, bu model gelecekteki oyunlara iyi bir şekilde genelleştirilemez.